时序数据库-03-opentsdb-分布式时序数据库
时序数据库系列
时序数据库-05-TDengine 是一款开源、高性能、云原生的时序数据库 (Time-Series Database, TSDB)
时序数据库-05-TDengine Time-Series Database, TSDB
时序数据库-05-TDengine windows11 WSL 安装实战笔记 docker
时序数据库-06-01-vm VictoriaMetrics 快速、经济高效的监控解决方案和时间序列数据库
时序数据库-06-02-vm VictoriaMetrics install on docker 安装 vm
时序数据库-06-03-vm VictoriaMetrics java 整合
时序数据库-06-04-vm VictoriaMetrics storage 存储原理简介
时序数据库-06-05-vm VictoriaMetrics cluster 集群原理
时序数据库-06-06-vm VictoriaMetrics cluster 集群访问方式
Opentsdb
Opentsdb 是一个可扩展的时序数据库。
在不丢失数据粒度的情况下存储和服务大量的时序数据。
特性
存储
数据会被精确地按您提供的内容存储
支持毫秒级精度写入
可永久保留原始数据
扩展
运行在 Hadoop 和 HBase 上
每秒可扩展至百万级写入量
通过增加节点来增加容量
读取
可以从 GUI 生成图表
可以从 HTTP API 提取数据
可以选择开源前端
工作原理
OpenTSDB如何工作?
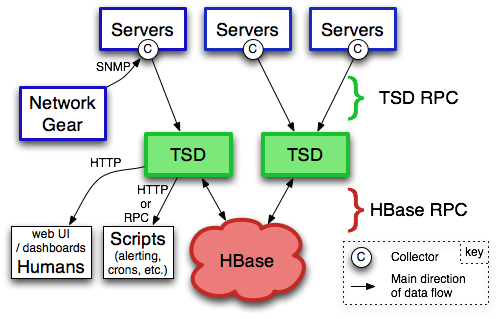
OpenTSDB由时间序列守护进程(TSD)和一组命令行实用程序组成。
与OpenTSDB的交互主要通过运行一个或多个TSD来实现。 每个TSD都是独立的。
没有主服务器,没有共享状态,因此您可以根据需要运行任意数量的TSD来处理您向其投入的任何负载。
每个TSD使用开源数据库HBase或托管的Google Bigtable服务来存储和检索时间序列数据。
数据模式经过高度优化,可快速聚合相似的时间序列,从而最大限度地减少存储空间。 、 TSD的用户永远不需要直接访问底层商店。
您可以通过简单的telnet风格协议,HTTP API或简单的内置GUI与TSD进行通信。
所有通信都发生在同一个端口上(TSD通过查看它收到的前几个字节来确定客户端的协议)。
写作
使用OpenTSDB的第一步是将时间序列数据发送到TSD。存在许多工具将来自各种源的数据提取到OpenTSDB中。如果找不到满足需求的工具,则可能需要编写从系统中收集数据的脚本(例如,通过从Linux上的/ proc读取有趣的指标,通过SNMP从网络设备收集计数器,或者从您的应用程序,通过JMX,例如Java应用程序),并定期将数据点推送到其中一个TSD。
StumbleUpon编写了一个名为tcollector的Python框架,用于从Linux 2.6,Apache的HTTPd,MySQL,HBase,memcached,Varnish等中收集数千个指标。这个低影响力的框架包括许多有用的收藏家,社区不断提供更多。支持OpenTSDB的替代框架包括Collectd,Statsd和Coda Hale指标发射器。
在OpenTSDB中,时间序列数据点包括:
度量标准名称。
UNIX时间戳(自Epoch以来的秒或毫秒)。
值(64位整数或单精度浮点值),JSON格式化事件或直方图/摘要。
一组标记(键值对),用于描述该点所属的时间序列。
标签允许您从不同的源或相关实体中分离出类似的数据点,因此您可以轻松地单独或成组地绘制它们。
标签的一个常见用例包括使用生成它的机器的名称以及机器所属的集群或池的名称来注释数据点。这使您可以轻松地制作仪表板,以便在每个服务器的基础上显示服务状态,以及显示跨逻辑服务器池的聚合状态的仪表板。
mysql.bytes_received 1287333217 327810227706 schema=foo host=db1
mysql.bytes_sent 1287333217 6604859181710 schema=foo host=db1
mysql.bytes_received 1287333232 327812421706 schema=foo host=db1
mysql.bytes_sent 1287333232 6604901075387 schema=foo host=db1
mysql.bytes_received 1287333321 340899533915 schema=foo host=db2
mysql.bytes_sent 1287333321 5506469130707 schema=foo host=db2此示例包含属于4个不同时间序列的6个数据点。
度量标准和标记的每个不同组合构成不同的时间序列。
所有4个时间序列都是针对 mysql.bytes_received 或 mysql.bytes_sent 这两个指标之一。
数据点必须至少有一个标记,并且度量标准的每个时间序列应具有相同数量的标记。 不建议每个数据点具有超过6-7个标签,因为与存储新数据点相关的成本很快就会超过该点之外的标签数量。
使用上面示例中的标记,可以轻松创建图形和仪表板,以在每个主机和/或每个模式的基础上显示MySQL的网络活动。
OpenTSDB 2.0的新功能是能够存储非数字注释以及用于跟踪元数据,质量指标或其他类型信息的数据点。
读
时间序列数据通常以折线图的格式消耗。
因此,OpenTSDB提供了一个内置的简单用户界面,用于选择一个或多个指标和标签,以生成图形作为图像。
或者,可以使用HTTP API将OpenTSDB绑定到外部系统,例如监视框架,仪表板,统计包或自动化工具。
查看社区为使用OpenTSDB提供的工具的资源页面。
拓展阅读
个人感受
分布式 database 解决了原来 database 的在数据量不足时问题。
核心技术还是索引+分布式+高可用保证+分布式事物。
技术是非常多的,永远也学不完,但是思想却是简单的。
参考资料
原文地址:https://blog.csdn.net/ryo1060732496/article/details/140562024
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!