51c大模型~合集16
我自己的原文哦~ https://blog.51cto.com/whaosoft/12472413
#FBI-LLM
FBI-LLM低比特基础大语言模型来了,首个完全从头训练的二值化语言模型
论文一作Liqun Ma目前是MBZUAI机器学习系的博士生,导师为Zhiqiang Shen助理教授,同时也是该论文的最后作者,其在加入MBZUAI之前为CMU博士后,研究领域主要为机器学习,基础大模型等等。Liqun的主要研究方向为高效的大模型预训练和微调,他本科毕业于天津大学。论文二作Mingjie Sun目前为CMU计算机系在读博士,导师为Zico Kolter教授。
自回归训练方式已经成为了大语言模型(LLMs)训练的标准模式, 今天介绍一篇来自阿联酋世界第一所人工智能大学MBZUAI的VILA实验室和CMU计算机系合作的论文,题为《FBI-LLM: Scaling Up Fully Binarized LLMs from Scratch via Autoregressive Distillation》,该论文首次提出了采用自回归蒸馏的优化方式从头训练二值化的大语言模型,性能可以匹配或者接近FP16或者BF16训练的LLMs,同时效果远超之前所有二值化大语言模型将近十个点。目前该工作的训练代码,数据和模型权重已全部开源。
- 文:https://arxiv.org/abs/2407.07093
- 代码:https://github.com/LiqunMa/FBI-LLM
核心结论和贡献
- 相比之前的二值化大语言模型,这是第一个从头开始训练,不使用任何预训练参数的二值化大语言模型。
- 训练过程仅仅使用自回归蒸馏损失,没有加入其他损失函数。
- 该工作是一个全量二值化模型,而不是之前一些方法采用的局部二值化或者三值化大模型。
背景介绍
最近几年受益于巨大的参数规模和海量的训练语料,基于Transformer的大型语言模型(LLMs),如ChatGPT和LLaMA系列,在特定领域知识的生成和复杂推理任务中都表现出色的性能。
此外,LLMs的能力随着参数规模的扩大而继续增强,给人们在通往AGI的道路上以无限遐想。然而,巨大的参数规模导致了模型需要巨大的存储和计算需求,这大大限制了LLMs的广泛应用和发展。量化技术通过将32位参数映射到更小的位数,有效地缓解了这些限制,该技术可以显著减少存储需求,并在推理过程中提升了计算速度和能源效率。
作为量化的极端情况,模型二值化仅用{-1, 1}来表示每个参数。它最大限度地实现了压缩和推理效率,但代价是牺牲一定程度的准确性。以往维持二值化LLMs性能的研究包括如何保留模型中重要参数或使用接近一位(部分二值化或者三值化)的表达方式来表示每个参数。
虽然这些方法展现出了不错的性能和潜力,但它们在存储和效率方面仍有优化的空间,并且额外的全精度参数或采用非2的幂来表示参数编码在适配特定硬件时会产生额外的开销。某些全二值化LLMs的研究基于最小化层级

编辑
损失的优化目标,或使用预训练的全精度LLM在其基础上继续训练,然后用少量训练数据进行二值化模型参数纠正,这些方法面临如下几个问题:
- 之前某些方法借助预训练的全精度模型参数来减少训练计算量和优化步骤, 然而二值化过程会极大地压缩原始模型的参数空间,损害全精度模型中存储的知识,因此依然需要足够的训练数据来让二值化模型重新学习这些知识并适应二值化参数的模式;
- 从现有预训练模型中衍生二值化模型 (使用预训练权重) 的方案不允许选择不同的参数规模或词汇表大小,从而限制了模型结构的灵活性和实际应用。
本文作者提出了一种从头开始训练的全二值化LLMs(FBI-LLM)。为了实现从头开始稳定地训练二值化LLMs,文章提出了一种基于全精度教师模型的自回归蒸馏的新型训练模式。具体来说,在训练过程中,作者逐步从全精度教师模型中生成蒸馏使用的软标签,并采用基于自回归蒸馏的方案来匹配教师模型在每个token位置的预测概率。
通过这种简单直接的自回归蒸馏损失,可以成功地从随机初始化中训练二值化LLMs。由于该方法相比一般LLM训练的改动主要集中在损失函数上,FBI-LLM可以轻松地融入现有的LLM预训练过程。此外,这种方法中的二值化操作与模型训练是分离的,因此任何增强LLM训练效率或者性能的技术都可以直接应用于本文提出的FBI-LLM。
作者对框架FBI-LLM的有效性进行了详细评估,训练了从130M、1.3B到7B规模的不同模型。作者使用广泛使用的Transformer架构进行LLMs的训练,结果表明从头开始训练全二值化的LLMs是完全可行的,其性能与全精度模型相比只有很小的差距。
与其他基准线方法相比,训练过程在困惑度和多个下游任务上表现更为出色。这些结果表明自回归蒸馏是训练二值化LLMs的关键,此外,通过对预训练更加深入的研究(如权重翻转比和梯度范数)的分析表明,从全精度LLMs继承权重与从头开始训练二值化LLMs之间没有显著差异。
本文的贡献可以总结如下:首先,该论文首次证明可以成功地从头开始训练具有二值权重的LLMs;其次,本文提出了一种新的蒸馏损失函数,以稳定二值化LLMs的训练,其采用自回归蒸馏来匹配教师模型的概率分布;第三,本文进行了广泛的实验和分析,以更好地理解所提出的方法的有效性。
下面介绍一下文章具体细节。
模型结构

编辑
模型结构主要基于LLaMA的结构。如上左图,首先是LLM 模块,其中包含使用可学习的α和β组成的 FBI-Linear层。右图为自回归蒸馏和模型训练相关过程。具体而言,由于在LLM 中,大多数参数都位于线性模块中。FBI-LM 将除causal head以外的所有线性模块替换为 FBI-linear层。由于causal head直接影响每个步骤中的输出token分布,因此对其参数进行二值化将显著影响模型输出的准确性,因此本文选择保留其精度。
此外,LLM 的另外两个核心模块(embedding和Layer Norm)中的参数也需要保持全精确。这是因为embedding模块包含有关所有标记的语义信息,并且作为模型输入的第一层,需要用来确定文本的初始表示形式。另一方面,Layer Norm 直接缩放激活值,二值化其参数将显著降低每层激活值的语义表达能力,之前其他关于LLM二值化的工作和研究也选择采用类似的设置和做法。
模型训练:自回归蒸馏(Autoregressive Distillation)
给定一个训练语料

编辑
,标准的自回归语言模型的目标函数是最大化如下似然函数:

编辑
其中k表示上下文窗口的大小,条件概率p通过参数为θ的神经网络建模。不同于一般的自回归语言模型,本文使用自回归蒸馏训练 FBI-LLM。在训练过程中,一个全精度预训练 LLM 被用作教师模型,二值化目标模型作为学生模型。假设每个训练数据实例由输入token序列x^1,…x^m组成,教师模型对下一个标记的预测概率可以表示为:

编辑
其中

编辑
表示最后一层 transformer 模块的激活,

编辑
表示用于预测下一个token概率的线性输出层的参数。
学生模型与教师模型输出之间的交叉熵被计算为每一步预测下一个token时的最终损失函数。它可以表示为:

编辑
其中n表示输入标记的数量。

编辑
表示教师模型预测的第i步词汇表上的标记分布,而

编辑
是学生模型的相应预测分布。
训练数据
本文使用的训练数据集跟一般的LLM训练相似,包含 Refined-Web 、StarCoder 和 RedPajama-v1的混合数据集,总共包含 1.26T tokens。
实验结果
如下图所示,首先是对现有的二值化 LLM 和 FBI-LLM 在 Wikitext2 的困惑度 (Perplexity) 比较。与其他二值化 LLM 相比,FBI-LLM 在相同规模大小的模型上获得相似或更低的困惑程度。

编辑
其次是在下游任务上的性能表现,如下表所示,由于 130M 大小的FBI-LLM没有对应的基准模型,本文将 130M 模型与之前 700M 规模的 BitNetb1.58 进行比较。尽管模型规模相差五倍,权重量化程度也存在较大的差异,但FBI的模型在 BoolQA 和 OpenbookQA 上的表现仍然优于 BitNet b1.58。
对于 1.3B 规模的二值化模型,FBI-LLM 在大多数下游任务和困惑度中都取得了最佳性能,甚至接近或超过了某些 7B 规模的二值化模型(如 BiLLM-LLaMA2-7B)的性能。与相同规模的全精度模型相比, FBI-LLM 1.3B 在下游任务中可以达到其 87% 的性能。在 7B 规模中,FBI模型依然显著优于之前几乎所有的基准线模型,具体来说,FBI-LLM相比之前最好的方法平均提升了将近十个点。

编辑
此外,由于计算资源的限制,FBI-LLM 7B当前汇报的结果并不是最终结果。作者只使用了整个 数据集的 8.6%(31 个块)。下图展示了FBI-LLM-7B训练过程中下游任务准确率和困惑度的变化。显然,从目前的训练进度来看,FBI-LLM-7B的性能将持续提高,更进一步的训练可能会得到更好的效果。

编辑
模型分析和可视化
二值化大模型是 从头开始训练还是从预训练的 LLM 接着训练?
直观地说,从预训练的 LLM 继续训练可以让二值化模型从全精度原始模型中继承知识,从而可能比从头开始训练获得更好的结果。为了论证这一假设,本文进行了全面的消融和分析实验,以记录和比较模型在两种不同训练模式下的行为。
从下图 (a) 中可以观察到,在训练初期,两种训练方式的 FF ratio 趋势基本保持一致。在整个训练过程中,两种方法的 FF ratio 都处于相似的大小上,并且数值相对较小。该结果表明,两种不同的参数初始化方法对二值化优化过程的影响没有显著差异。下图 (b) 展示了两种训练模式下的训练损失变化。在训练的初始阶段,两种方法的训练损失基本相同,表明模型的训练损失不会显著受初始化方法的影响。
虽然从头开始训练的损失在中间阶段比继续训练的损失略高,但过一段时间后,从头开始训练的损失再次与接着训练的损失相当,甚至变得比继续训练的损失更为稳定。值得注意的是,在大约第 1000 步时,如图 (a) 所示,当从预训练的 LLM 继续训练时,FF ratio 开始出现明显的波动。同样,在图 (b) 所示的第 1700 步左右,训练损失也遇到了类似的问题。
这些发现挑战了之前相关工作的一些假设,即从预训练的 LLM权重开始训练二值化大模型将赋予二值化LLM继承之前预训练的知识,从而提高性能。然而,本文结果和分析暗示了二值化LLM对参数初始化的方式不敏感,或者说随机参数初始化反而更好。对于原因,本文推测二值化和全精度LLM采用不同的参数组合和配置来编码语义,这导致其参数空间模式存在实质性差异。为了适应这种模式,通过从预训练的 LLM 继续训练来优化二值化的过程可能需要更大幅度的参数数值调整和变换,从而破坏预训练参数模式结构,继而破坏其中保存的知识。这个理论可以部分地解释为什么在训练期间与从头开始训练相比,继续预训练的权重反而让二值化LLM变得更不稳定。

编辑
训练的稳定性分析
二值化和全精度LLM训练在之前一些工作中都被发现表现出不稳定的训练行为。 FBI-LLM 也有类似的问题,具体表现为在训练 1.3B 和 7B FBI-LLM 时训练损失突然激增,有时在此之后继续训练模型也无法收敛。本文采用类似于 PaLM的解决方案:如果损失值不再趋于收敛,模型将恢复到前一个检查点,并跳过触发不稳定损失的数据块以继续训练。使用此方法,模型在相同的训练步骤中不再遇到问题。根据该论文的观察,从头开始训练 7B FBI 模型大约有 6% 的概率导致出现损失峰值。对于 1.3B 模型,由于其模型能力较低,训练更加不稳定,损失峰值的出现概率约为 15%。这与在全精度 LLM 中看到的预训练行为相似,而尖峰的概率明显更高,这可能与二值化参数的有限表达能力有关。为了解决这个问题,FBI跳过了发生损失峰值且没法通过后续训练恢复的数据块。
存储效率分析

编辑
上表显示了不同规模的FBI-LLM与相同结构的全精度LLaMA相比所需的理论存储空间,同时还详细给出了 FBI-LLM 引入的附加参数(α 和 β)的比例。表中的比较表明,FBI-LLM可以实现高压缩比,大大减轻了LLMs的存储负担。尽管 FBI-LLM 引入的用于缩放和移动的额外参数需要保留全精确,但它们的比例相比整个模型很小,因此其对存储的影响可以忽略不计。
生成结果示例

编辑
如上图所示,尽管 FBI-LLM 的生成质量无法完全匹配全精度 LLM模型,但 FBI-LLM 仍然可以生成流畅且有意义的内容。与具有更高参数位宽的BitNet b1.58模型相比,FBI-LLM对提示的理解更好,并且在一些生成的示例中包含了更多的知识。这表明FBI-LLMs具有更强的生成能力,并包含足够的知识。此外,FBI-LLM展示了进一步扩大模型规模从而达到更高智力水平的二值化模型的潜力,这种类型的大模型 (二值化大模型) 对部署的硬件需求也更加友好。
模型配置和训练细节
具体的模型配置和训练细节如下所示:

编辑
更多细节欢迎阅读文论原文。
#英特尔13/14代酷睿桌面CPU崩溃后续
损坏不可逆?不会召回
真就要「AMD Yes」了。
最近一段时间,部分使用英特尔第 13/14 代酷睿台式机处理器的游戏玩家遇到了一些麻烦。他们反馈称,这些处理器在运行虚拟引擎(Unreal Engine)游戏时会出现崩溃。
比如使用了虚拟引擎 5.3 的《泰坦之路》(Path of Titans),它的开发商 Alderon Games 提供了弹出窗口,以警告可能的游戏崩溃。从下图可以看到,游戏由于英特尔酷睿 i7 13700K 处理器而意外终止。
这并不是这些处理器第一次出现问题。澳大利亚游戏视觉特效工作室 ModelFarm 内部人员报告称,英特尔酷睿 i9 13900K 和 14900K 故障率达到了 50%左右,因此考虑改用 AMD 锐龙 9 9950X,以实现稳定的生产环境。
几天前,英特尔针对第 13/14 代酷睿处理器的使用反馈发表了一项声明,指出不稳定主要是由运行电压过高导致。
通过对因不稳定问题而退回的英特尔第 13/14 代酷睿台式机处理器的分析,我们确定:过高的运行电压导致部分第 13/14 代台式机处理器出现不稳定问题。过高的运行电压源于微代码算法,导致向处理器发送了错误的电压请求。
英特尔将提供一个微代码补丁,来修复电压过高的问题。我们还将继续验证,以确保解决第 13/14 代酷睿台式机处理器的不稳定情况。我们目前计划在 8 月中旬完成全面验证后,向合作伙伴发送此补丁。
英特尔致力于为客户解决这个问题。任何目前在第 13/14 代酷睿台式机处理器上遇到不稳定问题的客户,都可以获得进一步的帮助。
不过昨日,外媒 The Verge 称,如果用户的第 13/14 代酷睿处理器已经崩溃,英特尔提供的补丁显然无法修复它,损坏是永久的。
另一家外媒 Tom’s Hardware 援引不愿透露姓名的知情人士的说法,英特尔相关处理器的任何性能下降都是不可逆的。
当 The Verge 向英特尔发言人验证这一说法时,并没有得到否认。他们表示补丁将从一开始就能阻止这种情况发生。但是,如果出现问题的 CPU 已经损坏,最好的选择是更换它,而不是调整 BIOS 设置来尝试缓解这些问题。
此外,电压过高不是部分芯片出现故障的唯一原因。英特尔社区经理 Lex Hoyos 透露称,一些不稳定报告可以追溯到去年出现的氧化制造问题,该问题没有指定修复日期。
这就让用户格外关心后续的一些补救措施,比如英特尔会召回这些芯片吗?是否会影响移动笔记本 CPU 呢?The Verge 就这些问题向英特尔征询答案。
英特尔表示,他们既不会对相关处理器进行召回,也不会在验证更新期间停止销售,但声称会对用户提供「必要的支持」。此外,受到影响的不仅仅是 13/14 代 K 系列,还可能影响默认 65W TDP 的非 K 版本。
英特尔还将继续分析,以确保移动笔记本 CPU 不会出现 13/14 代桌面处理器相同的不稳定问题。
最后,英特尔对 The Verge 表示,用户无需担心无形的性能衰减。如果用户目前没有遇到相关问题,那么 8 月中旬提供的补丁也会对使用中的相关处理器起到有效的预防作用。
参考链接:
#AI在数学竞赛中展现「超凡智慧」
陶哲轩点评谷歌AlphaProof, 人工智能在数学推理中不断前进。
在奥数问题面前,AI 的「智商」往往不太够用。
不过,这已经是过去式了。谷歌 DeepMind 用 AI 做出了今年国际数学奥林匹克竞赛 IMO 的真题,并且距拿金牌仅一步之遥。对于 AI 来说,奥数不再是问题了。
IMO 2024 中六个问题的每一个问题满分为 7 分,总分最高 42 分。DeepMind 的系统最终得分为 28 分,意味着解决的 4 个问题都获得了满分 —— 相当于银牌类别的最高分。
DeepMind 文章连接:https://deepmind.google/discover/blog/ai-solves-imo-problems-at-silver-medal-level/
常用 AI 辅助证明的数学家陶哲轩近期正处在出差的忙碌中,对问题求解引擎 AlphaProof 和 AlphaGeometry2 还未完全消化。但他在自己的博客上对 DeepMind 的 AI 系统参加 IMO 竞赛这件事表达了自己的看法。
陶哲轩谈到,这是一项非常伟大的工作, 再次改变了我们对哪些基准挑战可以通过 AI 辅助或完全自主的方法实现的期望。
例如,IMO 级别的几何问题现在对于专用的 AI 工具来说已基本解决。现在看来,通过强化学习过程可以找到形式化证明的 IMO 问题至少在某种程度上可以被 AI 攻克。虽然目前每个问题需要相当大的计算量,并且在形式化方面需要人类的帮助。
在陶哲轩看来,这种方法还有一些「buff 加成」,它能使形式化数学更容易自动化,这反过来可能会促进包含形式化成分的数学研究方法。如果更公开地共享由此产生的形式证明数据库,它可能是一个有用的资源。
这种方法(更多地基于强化学习而非大型语言模型,有点类似 AlphaGo 的精神,且强调整体方法)非常聪明,事后来看很有道理。正如「AI 效应」所言,一旦解释清楚,它不会给人一种展示人类智能的感觉;但它仍然是我们 AI 辅助问题解决工具集能力的扩展。
「AI 效应」是指当人工智能技术取得进展或解决问题时,人们往往会认为这些成就并不是真正的人工智能或者不具备真正的智能。换句话说,一旦某项技术被理解或普及,它就不再被认为是智能的。这种现象表明,人们对 “智能” 的定义和期望会随着技术的进步而不断提高。
本月月初,陶哲轩在自己的博客中发布 AI 数学奥林匹克竞赛(AIMO 进步奖)的初步成绩已公布的消息。其中,获得第一名的是 Numina 的团队。
他在最新博客中表示,DeepMind 的这些新工具无法与最近赢得 AIMO 进步奖的 NuminaMath 模型直接比较。NuminaMath 模型完全自动化且资源效率高出数个数量级,并且采用了完全不同的方法(使用大型语言模型生成 Python 代码,以蛮力解决区域竞赛级别的数值答案问题)。这个模型也是完全开源的。这也是非常不错的工作,展示了尝试使用 AI 来辅助或自动化数学问题解决过程的不同部分的多维挑战。
其实 DeepMind 在数学推理方面有着不懈的努力。在今年年初,它的人工智能算法就已经在数学奥林匹克竞赛(IMO)上取得了重大成绩突破。论文《Solving olympiad geometry without human demonstrations》向世人介绍了 AlphaGeometry,还登上了国际权威期刊《自然》杂志。专家表示,这是人工智能朝着具有人类推理能力方向迈进的重要一步。
论文链接:https://www.nature.com/articles/s41586-023-06747-5
未来 DeepMind 还将带给我们怎样的惊喜,我们拭目以待。
参考链接:
https://mathstodon.xyz/@tao/112850716240504978
#DeRTa
「越狱」事件频发,如何教会大模型「迷途知返」而不是「将错就错」?
论文的第一作者是香港中文大学(深圳)数据科学学院二年级博士生袁尤良,指导老师为香港中文大学(深圳)数据科学学院的贺品嘉教授和腾讯 AI Lab 的涂兆鹏博士。该工作是袁尤良在腾讯AI Lab实习时完成。贺品嘉团队的研究重点是软件工程、大模型、AI for SE、可信人工智能。
大型语言模型(LLM)展现出了令人印象深刻的智能水平。因此,确保其安全性显得至关重要。已有研究提出了各种策略,以使 LLM 与人类伦理道德对齐。然而,当前的先进模型例如 GPT-4 和 LLaMA3-70b-Instruct 仍然容易受到越狱攻击,并被用于恶意用途。
为什么哪怕经过了大量的安全对齐,这些模型依然容易被越狱?应该如何进一步把安全对齐做深(deep)?
围绕这两个问题,香港中文大学(深圳)贺品嘉团队和腾讯AI Lab实验室联合提出了 Decoupled Refusal Training (DeRTa),一个简单新颖的安全微调方法,可以赋予大语言模型「迷途知返」的能力,从而在不影响模型有用性(helpfulness)的同时,大幅提升其安全性(safety)。
- 论文标题:Refuse Whenever You Feel Unsafe: Improving Safety in LLMs via Decoupled Refusal Training
- 论文地址:https://arxiv.org/abs/2407.09121
- 开源代码:https://github.com/RobustNLP/DeRTa
研究者发现,安全微调数据中存在拒绝位置偏差(refusal position bias),即模型表示拒绝回答的行为,总是出现在回复的开头,这可能阻碍了模型在后续位置处保持安全的能力。为了验证这一猜测,研究者使用越狱样本测试 LLaMA3-8B 和 LLaMA3-70B,结果显示几乎所有(99.5%)被模型成功拒绝的越狱样本,拒绝性单词(如 Sorry)都出现在前五个单词中。一旦开头没有被拒绝,模型将很难在后续位置表现出安全的行为。
方法
为了解决这一问题,该论文提出了解耦拒绝训练(DeRTa)。DeRTa 包括两个新颖的设计:
- 带有有害前缀的最大似然估计(MLE):将一段随机长度的有害回复(harmful response)添加到安全回复的开头,可以训练 LLMs 在任何位置拒绝回复,而不仅仅是在开始处。此外,添加有害前缀提供了额外的上下文,显著提高了 LLM 识别和避免不安全内容的能力。
- 强化过渡优化(RTO):虽然加入有害前缀可以帮助模型从有害状态过渡到安全状态,但每个训练样本仅提供单次过渡,可能不足以使 LLM 有效识别和阻止潜在威胁。为了应对这一问题,研究者引入了一个辅助训练目标 RTO,让模型在有害序列的任意位置,都预测下一个单词为「Sorry」,从而在有害回复序列中的每个位置都学习一次从有害到安全的过渡。

编辑
上述设计确保了模型防御机制的全面增强,允许模型学会「迷途知返」的行为。
该方法的设计,在推特上也引起了一定的讨论。

编辑
主要实验
为了验证方法的效果,研究者在两个知名的模型家族 LLaMA3 (8B & 70B) 和 Mistral (7B & 8×7B) 上进行了实验,涵盖六种不同的越狱攻击方式。结果显示:
- DeRTa 显著提升了安全性,同时不会降低有用性。
- DeRTa 可以进一步提升 LLaMA3-70B-Instruct 的安全性。

编辑
分析实验
为了提供更多有价值的见解,研究者主要基于 LLaMA3-70B,对 DeRTa 的工作原理进行了更细致的分析,包括:
1. 案例研究,DeRTa 如何影响拒绝性单词位置分布
2. 消融实验,DeRTa 中两种策略的作用大小
3. 分析实验一,与 DPO 进行比较,探究训练数据中的有害回复所发挥的作用
4. 分析实验二,DeRTa 在不同模型尺寸的适用性
首先,论文给出的示例具体地展示了 DeRTa 模型的「迷途知返」能力:即使在已经输出了一部分不安全文本的情况下,模型也能有效过渡到安全状态。此外,作者给出了在不同的方法下,模型输出的拒绝性单词的位置分布。可以看出,使用了 RTO 的模型,可以在显著靠后的位置,仍然具有保持安全的能力。

编辑
在消融实验中,实验结果显示,仅仅使用有害前缀策略不足以应对各种形式的攻击。例如,该策略对于防御 CodeAttack 这类较为复杂的攻击几乎没有帮助。该攻击通过让模型补全代码来越狱,模型在前面位置的回复中,会进行无恶意的代码补全,到一定位置处,模型将会开始一边补全代码一边生成恶意回复。
对于有害前缀策略的这些不足,RTO 可以有效弥补,从而使模型展现出很高的安全性,这说明 RTO 对于加强(赋予)模型在任何位置拒绝的能力至关重要。

编辑
RTO 的成功很自然带来一个问题:模型安全性的提升,是否可以归功于训练中整合了有害回复,而不是建模了 token 级别的安全过渡?为了回答这一问题,作者将 DeRTa 与 DPO 进行了比较。该实验进一步验证了,DeRTa 带来的安全性提升并不是简单地利用了有害回复的信息,而是得益于其对 token 级别安全过渡的直接建模。

编辑
此外,该论文也展示了在不同尺寸的模型上的表现,包括 LLaMA3 (8B & 70B) 和 Mistral (7B & 8×7B),结果显示该方法对不同大小的模型均有很好的效果。
结语
大模型安全依然任重道远。如何突破表面对齐,将安全做深入是一件很有挑战的事情。研究者在此给出了一些探索和思考,希望可以为这一方面的研究,提供一些有价值的见解和基线方法。
#达摩院气象大模型成功通关
这个夏天,天气版「山东卷」考验电网
2024 年是极端天气事件高发的一年。
3 月,江西南昌持续遭遇强对流天气,大树被连根拔起,民宅玻璃被吹落;9 月,上海的小伙伴在一周之内迎来了两次台风,高呼「活久见」。十一假期之前,内蒙古呼伦贝尔突降暴雪,前去「赏秋」的游客被打得措手不及。

编辑
而且,Nature 子刊的一篇文章显示,在未来的 20 年,这种极端天气有迅速加强的趋势。

编辑
其实,对「风云突变」的威力,有些行业早就深有感受,甚至是深受其苦。电网就是这样一个场景。无论是从发电端还是用电端来看,天气的剧烈变化都会直接影响电力供需平衡,给电网运行带来意想不到的挑战。
好在,AI 正在上岗天气预报员,带给电力系统高频更新的专属天气预报。
在国网山东电力调控中心,一个名叫「八观」的气象大模型已经运行了好几个月,以每小时公里级的精准度成功预测了多次极端天气,帮助电网平稳度过了一个「旱涝急转」的夏天。
从数据来看,它的准确率明显高于基线系统。

编辑
这位优秀的 AI 天气预报员是什么来头?在 11 月 6 日北京举行的达摩院决策智能产品发布会上,相关谜底被揭开。
当电网遭遇「风云突变」
今天夏天,家住山东的朋友或许都感受到了天气的反常:先是高温持续、旱情严峻;紧接着旱涝急转、暴雨频发。
我们想象一下小学应用数学题里一边注水一边放水的泳池。电网就像这个泳池,一边在发电,一边在用电,而且「水位」要始终保持平衡。
但天气一变,平静的「水面」要不起波澜就难了。
先说用电侧。最直观的,下雨前天气闷热,更多的居民会选择开空调。温度每升高一度,对应的用电量,专业上叫做「负荷」就会相应增加。但如果雨下下来,天气一凉爽,用电负荷就会骤降。

编辑
偏偏今年夏天山东降雨特别多,是有数据统计以来第二多的。8 月 25 日至 28 日,山东的气温就因为降水出现大幅度波动,电网负荷总量在 3 日之内下降了 20%。
要知道,电网在高负荷状态下需要维持充足的电力供应以避免停电风险,而突如其来的需求减少可能导致电力过剩,引发电压不稳定、频率波动等问题。
再说发电侧。和传统的火力发电不同,风电、光伏「看天吃饭」,发电功率随天气变化而波动。尤其这类新能源发电装置多是分布式的,受区域天气影响很大。新能源装机、并网规模不断攀升,给电网注入了更多随机性、波动性和间歇性因素。
这样一来,天气一变,电网就会两头承压。要是来不及制定合理的调度策略,牵一发而动全身,就有可能调度失衡。
据统计,我国新能源装机占比已经超过 40%。要保证大规模的分布式光伏和风电安全稳定地接入电网,高频、高精度的区域天气预报变得尤为关键。

编辑
「八观」气象大模型的落地之路
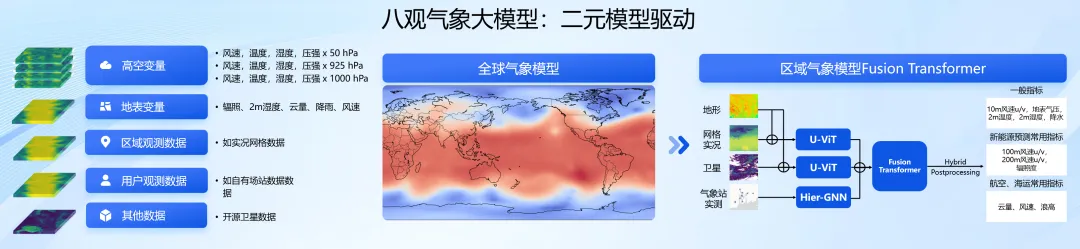
运行在国网山东电力调控中心的「八观」是由阿里巴巴达摩院决策智能实验室开发的一个气象大模型。这也是八观上岗的第一份「工作」。根据这份工作的需求,它不仅需要提供天气预报,更要帮助电力系统在气象数据基础上,提供新能源发电功率预测和用电负荷预测。为此,八观进行了多个方面的技术创新。

编辑
首先,它采取了「全球 - 区域」协同的预测策略,在模型层面和数据层面取长补短。
在「八观」之前,很多研究机构都基于欧洲气象局的 ERA5 再分析数据训练,推出了所谓的「全球气象大模型」。但全球气象大模型距离真正的落地还存在 gap。
ERA5 的数据质量很高,但时空分辨率只有 0.25(25 公里 X25 公里的网格 ),无法满足包括电力系统在内的很多行业用户的实际需求。
为此,达摩院训练了两个气象大模型 —— 一个全球大模型和一个区域大模型。全球大模型作为底座模型,学习大气运动在时空上的宏观规律,区域大模型则纳入了包括场站数据、气象实况、开源卫星图像、开源地形在内的多源多模态数据。这些数据与描述天气特征的物理模型约束相互融合,共同对次网格尺度的局部微气象过程进行精细化建模。
具体来说,达摩院研发人员通过对不同空间分辨率但对应相同实际地域的各种数据嵌入表征的对齐,让全球模型表征和区域模型表征在各层中相互交互,将其预测精度最高提升至 1 公里 * 1 公里 * 1 小时。
编辑
另一个创新点体现在架构的选择上。
在气象大模型架构方面,不同于 Swin Transformer、GNN 等架构,达摩院率先采用孪生掩码自编码器(MAE)。此类架构的原理是随机掩盖输入数据,然后训练 AI 去重建这些被掩盖的部分。比如,可在时间上取 2 个点(6 小时前和 6 小时后),在空间上将地球划分为多个小区域,掩盖(mask)一些区域。模型通过学习 6 小时前的气象数据和 6 个小时后没有被掩盖的区域来重建 6 小时后的掩盖区域,从而学习隐藏在高波动的天气数据下的鲁棒特征表示,实现对天气的精准把握。
这种架构不仅能为天气预报提供可靠的基础模型,还能支持更长时段的次季节(42 天)预测,而且能够充分考虑更多的数据(如海洋数据)。

编辑
最后,「八观」还对风速、辐照度等新能源重点指标进行了优化。
在这些技术创新的加持下,「八观」气象大模型在山东经受住了考验,在前面提到的 8 月 25 日至 8 月 28 日的剧烈变化中,将下游新能源发电功率、电力负荷预测准确率分别提升至 96.5% 和 98.1%,有效帮助电力系统作出及时、准确的调度决策。
相比起传统的数值天气预报计算量庞大,需要配置机房,AI 气象大模型部署便捷,可快速推广。
据介绍,在地处大江畔的另一光伏和风电重点发展地区,八观也交出了一份优秀的答卷,将分布式光伏功率预测月平均准确率提升了 1.4%,风电功率预测月平均准确率提升了 5.5% 。

编辑
达摩院决策智能实验室:不止研究 AI
自古以来,预测天气一直是一项充满挑战的任务。我们的祖先细致地观察自然界的种种迹象,例如云彩的形态与色泽、风的来向与力度、动物的行为习性、植物的生长态势等,试图破译天气变化。
进入现代,人们开始进行气象学与物理学、数学、计算机科学等学科的交叉研究,任何一个单独的学科都无法担此重任。
「八观」气象大模型背后的达摩院决策智能实验室就是这样一支具有很强学科交叉背景的团队,更结合了对产业的深刻理解。
在过去的几年里,他们在时序预测等方面积累了丰富的经验,构建了包括时序预测、时序异常检测以及对应原子算法的完整时序数据分析框架,近 3 年来,在 AI 顶级会议和期刊上发表 30 多篇论文。他们用 AI 预测新能源发电功率的成果,也在今年入选了联合国 AI for Good(人工智能向善)案例集。
未来,八观将持续向着「更懂产业的气象预报」这一目标发力。团队还计划将模型的应用范围扩展到民航、体育赛事、农业等多个领域,与这些领域共同迎战风云变幻。
参考链接:
https://www.chinawater.com.cn/df/sd/202410/t20241010_1057216.html
#英特尔在数据中心市场输给了AMD
史上第一次
然而两家都远远落后于英伟达。
在消费级芯片市场形势逆转之前,服务器芯片的市场已经先喊出 AMD yes 了。
史上第一次,AMD 从数据中心处理器市场中获得的利润超越了英特尔。
近二十多年来,英特尔一直是数据中心 CPU 市场无可争议的领导者,其提供的 Xeon 处理器为全世界大多数的服务器提供动力。另一方面,仅在七八年前,AMD 的处理器还只能占据个位数的市场份额。
如今情况已发生了巨大变化。虽然英特尔的 Xeon CPU 仍然为大多数服务器提供动力,但越来越多的新服务器,特别是高端设备已经趋向于选用 AMD 的 EPYC 处理器。正如近日独立研究机构 SemiAnalysis 所指出的,AMD 的数据中心业务部门现在的销量已经超过了英特尔的数据中心和 AI 业务。

编辑
上周四,各家美国科技公司陆续发布三季度财报,AMD 报告其数据中心收入增长 122%,游戏收入下降 69%。公司 2024 年第三季度营业额为 68 亿美元,同比增长 18%。其中,AMD 的数据中心部门收入在第三季度达到 35.49 亿美元,这显示出 AMD 在半导体市场的竞争力不断提升,能够持续扩大业务规模并获得更多的市场份额。
而英特尔在第三季度的产品总收入为 122 亿美元,同比减少 2%,其中至强处理器、Gaudi 加速器为主的数据中心和 AI 集团的收益在 本季度为 33 亿美元,同比增长 9%。就在两年前,英特尔的 DCAI 集团每季度的收入为 50 亿至 60 亿美元。
在新一代产品中,AMD 的 EPYC 处理器相对于英特尔的 Xeon CPU 取得了竞争优势,英特尔不得不以大幅折扣出售其服务器芯片,这降低了该公司的收入和利润率。
今年 9 月,英特尔推出了新一代旗舰产品 128 核的 Xeon 6980P「Granite Rapids」处理器,售价高达 17800 美元,是该公司有史以来最昂贵的标准 CPU(也是最贵的 X86 CPU)。

编辑
Xeon 6980P 拥有 128 个高性能内核和 256 个线程,时钟速度为 2.0 GHz,L3 缓存为 504MB。
相比之下,AMD 最昂贵的 96 核 EPYC 6979P 处理器售价为 11805 美元。
从历史上看,英特尔的处理器定价并没有像 AMD 的多线程版本那样高。这一转变可能表明英特尔采取了新的定价策略,力图将自己定位为高端选择,但这也可能是制造新一代 CPU 生产流程的高成本所致。
外媒 tomsHardware 认为,如果市场对英特尔 Xeon 6900 系列处理器的需求仍然很高,并且该公司能够大量供应这些 CPU,那么英特尔的数据中心收入可能会重回正轨,并超过 AMD 的数据中心销售额。然而,英特尔仍然需要提高其 Granite Rapids 产品的产量。
最后,英特尔和 AMD 的竞争之上,还有一个英伟达。
虽然英特尔和 AMD 现在每季度通过销售数据中心 CPU 赚取约 30-35 亿美元,但英伟达从其数据中心 GPU 和网络芯片中赚取的收入比这两家要高得多,英伟达提供的芯片是使 AI 处理器(GPU)在数据中心协同工作所必需的。
事实上,在 2025 财年第二季度,英伟达网络产品的销售额总计 36.68 亿美元,这还是在英伟达在 InfiniBand 网络市场逐渐减速的情况下实现的。
与此同时,英伟达计算 GPU 的销售额在 2025 财年第二季度达到了 226.04 亿美元,远远超过英特尔和 AMD 数据中心硬件的总销售额。总体而言,英伟达在今年上半年销售了价值近 420 亿美元的 AI 和 HPC GPU,下半年的销售额很可能会更高。
参考内容:
https://x.com/SKundojjala/status/1853041284157682063
#Hunyuan-Large
腾讯混元又来开源,一出手就是最大MoE大模型
随着人工智能技术的快速发展,大型语言模型(LLMs)在自然语言处理、计算机视觉和科学任务等领域取得了显著进展。然而,随着模型规模的扩大,如何在保持高性能的同时优化资源消耗成为关键挑战。为了应对这一挑战,腾讯混元团队率先采用混合专家(MoE)模型架构,最新发布的 Hunyuan-Large(Hunyuan-MoE-A52B)模型,是目前业界已经开源的基于 Transformer 的最大 MoE 模型,拥有 389B 总参数和 52B 激活参数。
本次腾讯混元 - Large 共计开源三款模型:Hunyuan-A52B-Pretrain,Hunyuan-A52B-Instruct 和 Hunyuan-A52B-FP8,可支持企业及开发者精调、部署等不同场景的使用需求,可在 HuggingFace、Github 等技术社区直接下载,免费可商用。通过技术优化,腾讯混元 Large 适配开源框架的精调和部署,具有较强的实用性。腾讯云 TI 平台和高性能应用服务 HAI 也同步开放接入,为模型的精调、API 调用及私有化部署提供一站式服务。
- 开源官网:https://llm.hunyuan.tencent.com/
- github(开源模型工具包):https://github.com/Tencent/Hunyuan-Large
- huggingface(模型下载):https://huggingface.co/tencent/Hunyuan-Large/tree/main
- huggingface demo 地址:https://huggingface.co/spaces/tencent/Hunyuan-Large
- 技术报告:https://arxiv.org/abs/2411.02265
Hunyuan-Large 整体模型效果
公开测评结果显示,腾讯混元 Large 在 CMMLU、MMLU、CEval、MATH 等多学科综合评测集以及中英文 NLP 任务、代码和数学等 9 大维度全面领先,超过 Llama3.1、Mixtral 等一流的开源大模型。

编辑
技术创新点
MoE (Mixture of Experts),也即混合专家模型,MoE 模型的每一层都包含多个并行的同构专家,一次 token 的前向计算只会激活部分专家。MoE 模型的每一层会采用路由算法,决定了 token 会被哪些专家处理。MoE 是一种稀疏的网络结构,具有比激活总参数量同等大小稠密模型更优越的性能,而推理成本却远低于总参数量相同的稠密模型。
得益于 MoE (Mixture of Experts) 结构的优越性,混元 Large 可以在保证模型推理速度的同时,显著提升模型的参数量进而提升模型性能。
1、路由和训练策略
- 共享专家路由策略
腾讯混元 Large 的专家层中,设置一个共享专家来捕获所有 token 所需的共同知识,还设置了 16 个需要路由的专家,模型将每个 token 路由给其激活得分最高的专家来动态学习特定领域的知识,并通过随机补偿的路由保障训练稳定性。共享专家负责处理共享的通用能力和知识,特殊专家负责处理任务相关的特殊能力,动态激活的专家,利用稀疏的神经网络来高效率的进行推理。
- 回收路由策略
路由策略,即把 token 分发给 MoE 中各个专家的策略,是 MoE 模型中至关重要的部分。好的路由策略可以有效地激活每个专家的能力,使得每个专家保持相对均衡的负载,同时提升模型的训练稳定性和收敛速度。业界常用的路由策略是 Top-K 路由,也就是将各个 token 按照其和专家的激活得分路由给各个专家。但是这种路由方式难以保障 token 在各个专家间平均分配,而那些超过专家负载的 token 则会被直接扔掉,不参与专家层的计算。这样会导致部分处理 token 较少的专家训练不稳定。
针对这一问题,腾讯混元 Large 在传统 Top-K 路由的基础上进一步提出了随机补偿的路由方式。

编辑
- 专家特定学习率适配策略
在 Hunyuan-A52B 中,共享专家和路由专家在每个迭代里面专家处理的 token 数有很大差异,这将导致每个专家实际的 batchsize 并不相同(共享专家的 batchsize 是其他专家的 16 倍),根据学习率与 Batch size 的缩放原则,为不同(共享 / 特殊)专家适配不同的最佳学习率,以提高模型的训练效率。

编辑
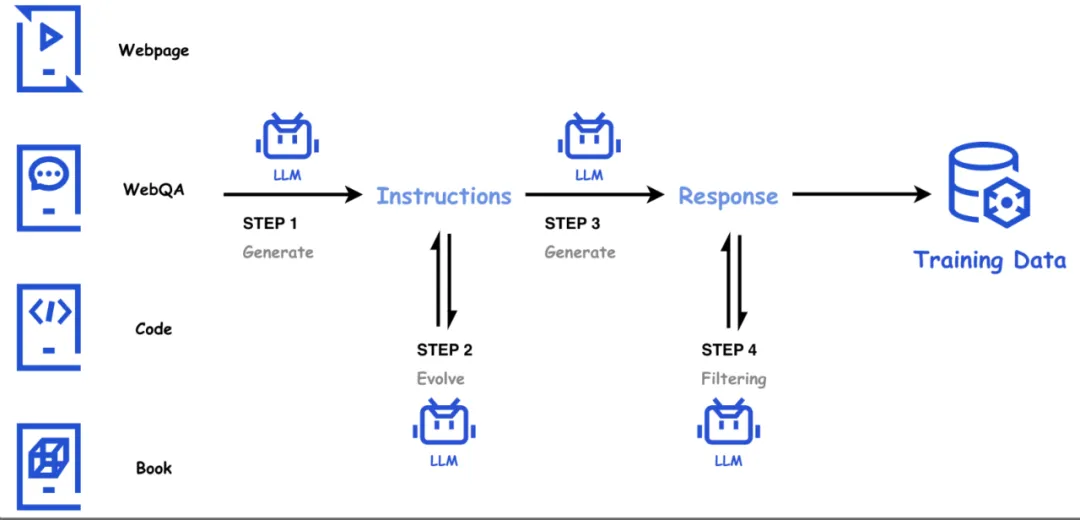
- 高质量的合成数据
大语言模型的成功与高质量的训练数据密不可分。公开网页数据通常质量参差不齐,高质量通常难以获取;在天然文本语料库的基础上,腾讯混元团队在天然文本语料库的基础上,利用混元内部系列大语言模型,构建大量的高质量、多样性、高难度合成数据,并通过模型驱动的自动化方法评价、筛选和持续维护数据质量,形成一条完整数据获取、筛选、优化、质检和合成的自动化数据链路。
编辑
在数学领域,网页数据中很难找到大量优质的思维链 (CoT) 数据。腾讯混元 Large 从网页中挖掘构建大规模题库,并利用它作为种子来合成数学问答,从而保证了多样性;同时我们利用一致性模型和评价模型来维护数据的质量,从而得到大量优质且多样的数学数据。通过加入数学合成数据显著提高了模型的数学能力。
在代码领域中,自然代码很多质量较差,而且包含类似代码解释的代码 - 文本映射的数据很稀缺。因此,腾讯混元 Large 使用大量天然代码库中的代码片段作为种子,合成了大量包含丰富的文本 - 代码映射的高质量代码训练数据,加入后大幅提升了模型的代码生成能力。
针对通用网页中低资源、高教育价值的数据,腾讯混元 Large 使用合成的方式对数据做变换、增广,构建了大量且多样的、不同形式、不同风格、高质量的合成数据,提升了模型通用领域的效果。
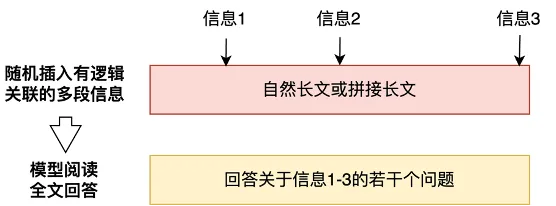
2、长文能力优化
采用高效的超长文 Attention 训练和退火策略。通过将长文和正常文本混合训练,逐步多阶段引入自动化构建的海量长文合成数据,每阶段仅需少量长文数据,即可获得较好的模型长文泛化和外推能力。
编辑
腾讯混元 Large 模型专项提升的长文能力已经应用到腾讯 AI 助手腾讯元宝上,最大支持 256K 上下文,相当于一本《三国演义》或英文原版的《哈利・波特》全集的长度,可以一次性处理上传最多 10 个文档,并能够一次性解析多个微信公众号链接、网址,让腾讯元宝具备独有的深度解析能力。
3、推理加速优化
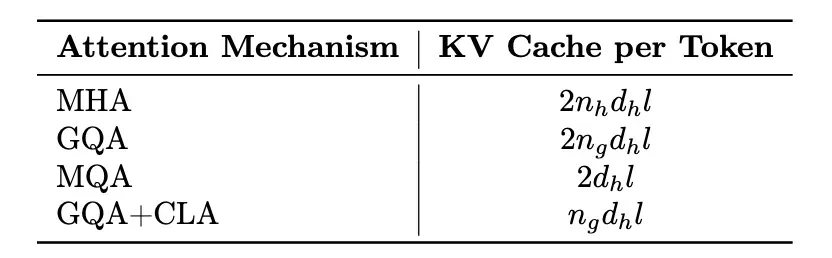
随着 LLM 处理序列逐渐增长,Key-Value Cache 占用内存过大的问题日益突出,为推理成本和速度带来了挑战。
为了提高推理效率,腾讯混元团队使用 Grouped-Query Attention(GQA)和 Cross-Layer Attention (CLA) 两种策略,对 KV Cache 进行了压缩。同时引入量化技术,进一步提升压缩比。

编辑
通过 GQA+CLA 的引入,我们将 Hunyuan-A52B 模型的 head 数从 80 压缩到 8,并通过 CLA 每两层共用 KV 激活值,最终将模型的 KV Cache 压缩为 MHA 的 5%,大幅提升推理性能。下面是不同策略的 KV Cache 对比。
编辑
4、Postrain 优化
- SFT 训练
腾讯混元团队在预训练模型的基础上使用超过百万量级的 SFT 数据进行精调训练,这些精调数据包含了数学、代码、逻辑、文本创作、文本理解、知识问答、角色扮演、工具使用等多种类别。为了保证进入 SFT 训练的数据质量,我们构建了一套完整的基于规则和模型判别的数据质检 Pipeline,用于发现数据中常见的 markdown 格式错误、数据截断、数据重复、数据乱码问题。此外,为了自动化地从大规模指令数据中筛选高质量的 SFT 数据,我们基于 Hunyuan-70B 模型训练了一个 Critique 模型,该模型可以对指令数据进行 4 档打分,一方面可以自动化过滤低质数据,另一方面在自进化迭代过程中可以有效提升被选 response 的质量。
我们使用 32k 长度进行 SFT 训练,另外在训练过程中为了防止过拟合,我们开启了 0.1 的 attention dropout 和 0.2 的 hidden dropout;我们发现相比 Dense 模型,MoE 架构的模型通过开启合理的 dropout,能有效提升下游任务评测的效果。另外为了更高效的利用大规模指令数据,我们对指令数据进行了质量分级,通过从粗到精的分阶段训练,有效提升了模型效果。
- RLHF 训练
为了使模型能够生成与人类偏好接近的回答,我们进一步使用直接偏好优化(DPO)对齐算法对 SFT 模型进行强化训练。与离线 DPO 算法不同的是,我们在强化学习二阶段采用的是在线强化 pipeline,这一框架里集成了使用固定 pair 数据的离线 DPO 策略,和使用训练过程中更新的策略模型迭代式采样的在线强化策略。具体来说,每一轮模型只使用少量数据进行采样训练,训练完一轮之后的模型会对新的一批数据采样出多个回答,然后利用奖励模型(RM)打分,排序出最好的回答和最差的回答来构建偏好对。
为了进一步增强强化学习阶段的训练稳定性,我们随机筛选了一定比例的SFT数据用于计算 sft loss,由于这部分数据在 SFT 阶段已经学过,DPO 阶段加 sft loss 是为了保持模型的语言能力,且系数较小。此外,为了提升 dpo pair 数据里面的好答案的生成概率,防止 DPO 通过同时降低好坏答案的概率的方式来走捷径,我们也考虑加入好答案的 chosen loss 。通过以上策略的有效结合,我们的模型在 RLHF 训练后各项效果得到了明显的提升。

编辑
5、训练和精调
腾讯混元 Large 模型由腾讯全链路自研,其训练和推理均基于腾讯 Angel 机器学习平台。
针对 MoE 模型 All2all 通信效率问题,Angel 训练加速框架(AngelPTM)实现了 Expert 计算和通信层次 overlap 优化、MOE 算子融合优化以及低精度训练优化等,性能是 DeepSpeed 开源框架的 2.6 倍。
腾讯混元 Large 模型配套开源的 Angel 推理加速框架(AngelHCF-vLLM)由腾讯 Angel 机器学习平台和腾讯云智能联合研发。在 vLLM 开源框架的基础上适配了混元 Large 模型,持续通过叠加 NF4 和 FP8 的量化以及并行解码优化,在最大限度保障精度的条件下,节省 50% 以上显存,相比于 BF16 吞吐提升 1 倍以上。除此之外,Angel 推理加速框架也支持 TensorRT-LLM backend,推理性能在当前基础上进一步提升 30%,目前已在腾讯内部广泛使用,也会在近期推出对应的开源版本。
#A Systematic Survey on Large Language Models for Algorithm Design
调研180多篇论文,这篇综述终于把大模型做算法设计理清了
本文第一作者柳斐(https://feiliu36.github.io/ )是香港城市大学计算机科学系博士生,师从张青富教授。研究领域为计算智能,自动算法设计,组合优化等。姚一鸣,郭平,杨致远,赵哲和林熙来自香港城市大学张青富教授团队。陆智超为香港城市大学计算机科学系助理教授。王振坤为南方科技大学系统设计与智能制造学院助理教授。童夏良和袁明轩来自华为诺亚方舟实验室。
- 论文标题:A Systematic Survey on Large Language Models for Algorithm Design
- 论文地址:https://arxiv.org/abs/2410.14716
算法设计(AD)对于各个领域的问题求解至关重要。大语言模型(LLMs)的出现显著增强了算法设计的自动化和创新,提供了新的视角和有效的解决方案。在过去的三年里,LLMs 被整合到 AD(LLM4AD)中取得了显著进展,在优化、机器学习、数学推理和科学发现等各个领域获得广泛研究和应用。鉴于这一领域的快速发展和广泛应用,进行系统性的回顾和总结既及时又必要。本文对 LLM4AD 的研究进行了系统性回顾。首先,我们概述和总结了现有研究。然后,我们沿着四个维度,包括 LLMs 的作用、搜索技术、提示策略和应用,提出了一个系统性分类和现有研究的回顾,讨论了使用 LLMs 的潜力和成就。最后,我们探讨当前的挑战,并提出了几个未解问题和未来研究的方向。
1. 引言
算法在解决各个领域的问题中发挥着至关重要的作用,包括工业、经济、医疗和工程等领域。传统的手工设计算法的方法繁琐且耗时,需要广泛的专业知识和大量的努力。因此,人们越来越关注在算法设计中采用机器学习和计算智能技术以自动化和增强算法开发过程。
近年来,大型语言模型(LLMs)已经成为生成人工智能领域的重大突破。LLMs 以其庞大的模型规模、巨大的训练数据和在语言理解、数学推理、代码生成等各个研究领域中有着出色的表现。在过去的三年里,大型语言模型用于算法设计(LLM4AD)已经成为一个新兴的研究领域,有望增强甚至重塑算法的构思、优化和实施方式。LLMs 的强大功能和适应性展示了其在改进和转变算法设计过程中的潜力,包括启发式生成、代码优化,甚至创造针对特定问题的新算法。这种方法不仅减少了设计阶段所需的人力,还提高了算法设计过程的创新性和效率。
尽管 LLM4AD 领域正在受到广泛研究和应用,但在这一新兴领域仍然缺乏系统性综述。本文旨在通过提供一个最新的多维度的系统综述来填补这一空白,全面展示 LLMs 在算法设计中的应用现状、主要挑战和未来研究方向。本文有助于深入探讨 LLMs 在增强算法设计方面的潜力,并为这一令人兴奋的领域的未来创新打下坚实基础。我们希望这将成为对该领域感兴趣的研究人员的有益资源,并为经验丰富的研究者提供一个系统性的综述。本文的贡献如下:
- LLM4AD 的系统综述:我们首次对过去三年中发表的 180 多篇高度相关的研究论文进行了系统综述,探讨了使用 LLMs 进行算法设计的发展。
- LLM4AD 的多维度分类:我们引入了一个多维度分类法,将 LLM4AD 的作品和功能分为四个不同的维度:1)LLMs 在算法设计中使用的四种范式,概述了这些模型如何为算法设计做出贡献或增强算法设计;2)搜索方法,探讨了 LLMs 用于导航和优化算法设计中搜索空间的各种方法;3)提示词设计,研究了如何使用不同的提示策略;以及 4)应用领域,确定 LLMs 正在应用于解决的不同领域。
- LLM4AD 的挑战和未来方向:我们不仅仅是对现有文献进行总结,而是对当前关于算法设计中大型语言模型(LLMs)研究的局限性进行了批判性分析。此外,我们提出了潜在的未来研究方向,包括开发领域特定的 LLMs、探索多模态 LLMs、促进人与 LLM 的互动、使用 LLMs 进行算法评估和理解 LLM 行为、推进全自动算法设计,以及为系统评估 LLM 在算法设计中的表现进行基准测试。这一讨论旨在激发新的方法并促进该领域的进一步发展。
2. 大模型用于算法设计概览
本文旨在对新兴领域 “大语言模型用于算法设计”(LLM4AD)中现有研究工作进行系统的梳理和分类。我们并不打算涵盖所有关于大型语言模型(LLMs)和算法的文献。我们的调查范围如下所述:1)“大语言模型” 一词指的是规模足够大的语言模型。这些模型通常采用 Transformer 架构,并以自回归方式运行。使用较小模型进行算法设计的研究,如传统的基于模型和机器学习辅助的算法,不在考虑范围内。虽然精确定义 “大型” 模型具有挑战性,但大多数前沿的大型语言模型包含超过十亿个参数。使用其他大型模型缺乏语言处理能力的研究,如纯视觉模型,不在考虑范围内。然而,包括语言处理的多模态大型语言模型则在我们的调查范围之内。2)“算法” 一词指的是一组设计用来解决问题的数学指令或规则,特别是当由计算机执行时。这个广泛的定义包括传统的数学算法、大多数启发式方法,以及可以被解释为算法的某些策略。
我们介绍了论文收集和扫描的详细流程,包括四个阶段:
- 第一阶段 数据提取和收集:我们通过谷歌学术、科学网和 Scopus 收集相关论文。我们的搜索逻辑是标题必须包含以下两组词语中至少一组的任意组合:“LLM”、“LLMs”、“大型语言模型”、“算法”、“启发式”、“搜索”、“优化”、“优化器”、“设计”、“方法”(例如,LLM 和优化,LLMs 和算法)。在移除重复的论文后,截至 2024 年 7 月 1 日,我们共收集到 850 篇论文。
- 第二阶段 摘要筛选:我们检查每篇论文的标题和摘要,以有效排除不相关的论文。排除的标准包括这些论文不是英文的,不是用于算法设计的,没有使用大型语言模型的。扫描后,剩余 260 篇论文。
- 第三阶段 全文筛选:我们彻底审查每篇论文,排除缺乏相关内容的论文。扫描后,剩余 160 篇论文。
- 第四阶段补充:根据对该领域的了解,我们手动添加了一些相关的工作,以避免遗漏任何重要的贡献。在整合了额外的论文后,我们最终得到了 180 多篇论文。我们将首先介绍 LLM4AD 论文列表的概览,然后提出一个分类法来系统地回顾进展。除了组织好的论文列表之外,我们还纳入了 2024 年 7 月 1 日之后发布的一些重要出版物。
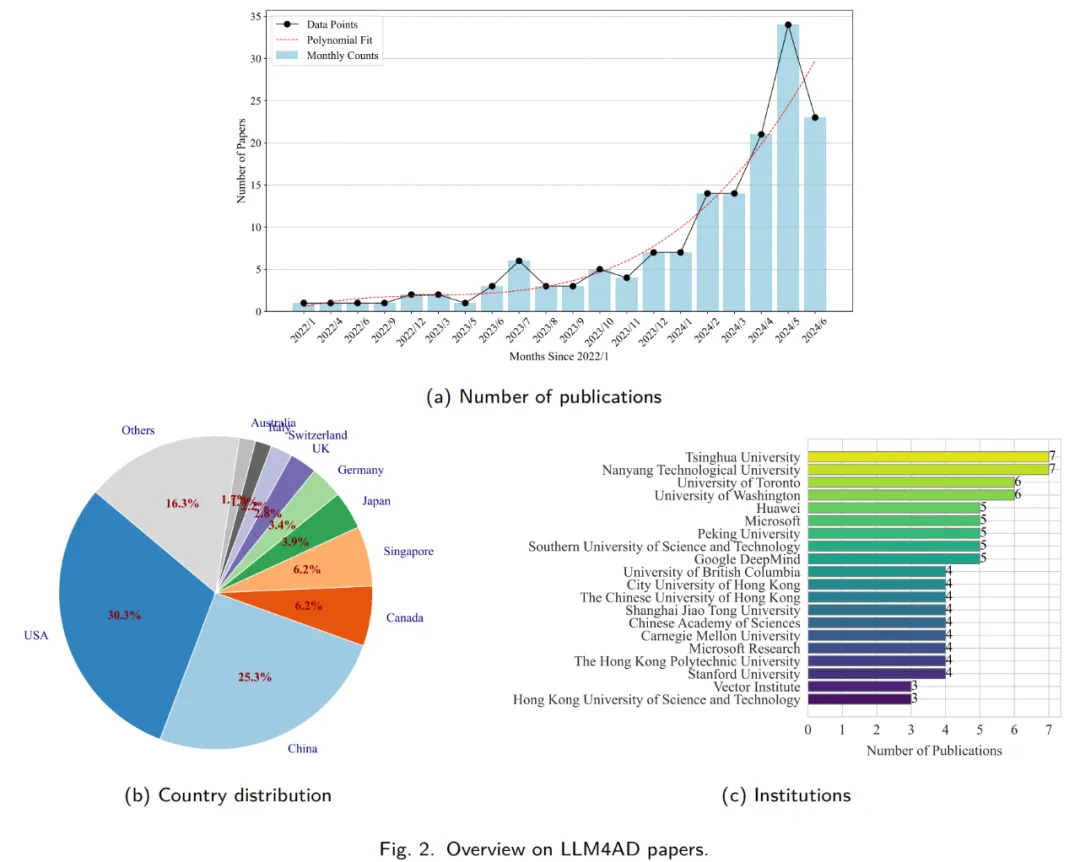
图中展示了随时间变化的论文发表数量趋势,时间线以月份表示。图表显示,与 LLM4AD 相关的研究活动显著增加,特别是注意到大多数研究是在近一年进行的。这表明 LLM4AD 是一个新兴领域,随着来自不同领域的学者意识到其巨大潜力,我们预计在不久的将来研究产出将显著增加。
图中还显示了在 LLM4AD 出版物中领先的机构及其所在国家。美国领先,紧随其后的是中国,这两个国家单独占据了 50%的出版物。接下来的八个国家,包括新加坡、加拿大和日本,共同贡献了总出版物的三分之一。发表最多论文的研究机构包括清华大学、南洋理工大学和多伦多大学等知名大学,以及华为、微软和谷歌等大型公司。这种分布强调了研究主题的广泛兴趣和它们在现实世界中的实际应用的重大相关性。
我们从所有审查过的论文的标题和摘要中生成了词云,每个词至少出现五次。它展示了前 80 个关键词,这些词被组织成四个颜色编码的簇,分别是 “语言”、“GPT”、“搜索和优化” 以及 “科学发现”。还突出显示了几个关键词,如 “进化”、“策略”、“优化器” 和 “代理”。
编辑

编辑
3. 大模型用于算法设计的四种范式
LLM4AD 论文按照大模型的结合方法可以分为四个范式:1)大模型作为优化算子(LLMaO)、2)大模型用于结果预测(LLMaP)、3)大模型用以特征提取(LLMaE)、4)大模型用来算法设计(LLMaD)。
- LLMaO 把 LLMs 用作算法框架内的黑盒优化器。将 LLMs 整合到优化任务中,充分利用它们理解和生成复杂模式和解决方案的能力,以及在提示工程中的良好灵活性。然而,由于它们的黑盒性质,它们通常缺乏可解释性,并在面对大规模问题时面临挑战。
- LLMaP 使用 LLMs 作为代理模型,预测结果或响应,功能上大体可以分为分类或回归两类。与其他基于模型的预测器(如高斯过程和传统神经网络)相比,1) LLMs 能够基于其在庞大数据集上接受的训练,处理和生成类人响应。这种能力使它们能够理解和解释数据中的复杂模式,适用于传统建模技术可能因数据的复杂性和复杂表示而难以应对的任务。2) 预训练的 LLMs 可以显著减少与训练高保真模型相比所需的计算负载和时间。
- LLMaE 利用 LLMs 挖掘和提取目标问题和(或)算法中的嵌入特征或特定知识,然后在解决新问题中利用这些特征。这一过程利用了 LLMs 的独特和强大的能力,如文本和代码理解,使它们能够识别数据中可能通过传统特征提取方法无法处理或理解的模式和关系。
- LLMaD 直接创建算法或特定组件。这种范式充分利用了 LLMs 的语言处理、代码生成和推理能力。LLMs 通过生成启发式算法、编写代码片段或设计函数,进一步推动了算法设计自动化,显著加速算法设计过程,减少人力劳动,并可能为算法开发带来创造性和更好的设计。这是单靠传统算法设计方法难以实现的。

编辑
4. 大模型用于算法设计中的搜索方法
目前的经验表明,单独采用大模型来进行算法设计往往难以应对特定的复杂算法设计任务。通过搜索方法的框架下调用大模型能够显著提升算法设计效率和效果。我们综述了目前在 LLM4AD 中采用的搜索方法,并将其大致分为四类:1)基于采样的方法,2)单点迭代的搜索方法,3)基于种群的搜索方法和 4)基于不确定性的搜索方法。详细的介绍和讨论可以在原文中查看。
5. 大模型用于算法设计中的提示词设计
图中展示了文献中使用的领域或预训练语言模型(LLMs)的百分比。其中,超过 80%的研究选择使用未经特定微调的预训练模型,大约 10%的研究在领域数据集上对预训练模型进行了微调,其中只有 4.4%的模型是在特定问题上从头开始训练的。图中还展示了最常使用的 LLMs。在 LLM4AD 的论文中,GPT-4 和 GPT-3.5 是使用最多的 LLMs,总共占了大约 50%。Llama-2 是最常用的开源 LLM。一旦我们拥有了预训练的 LLMs,提示工程对于有效整合 LLMs 到算法设计中非常重要。我们讨论了 LLM4AD 论文中使用的主要提示工程方法的应用情况,包括零样本、少样本、思维链、一致性和反思。

编辑
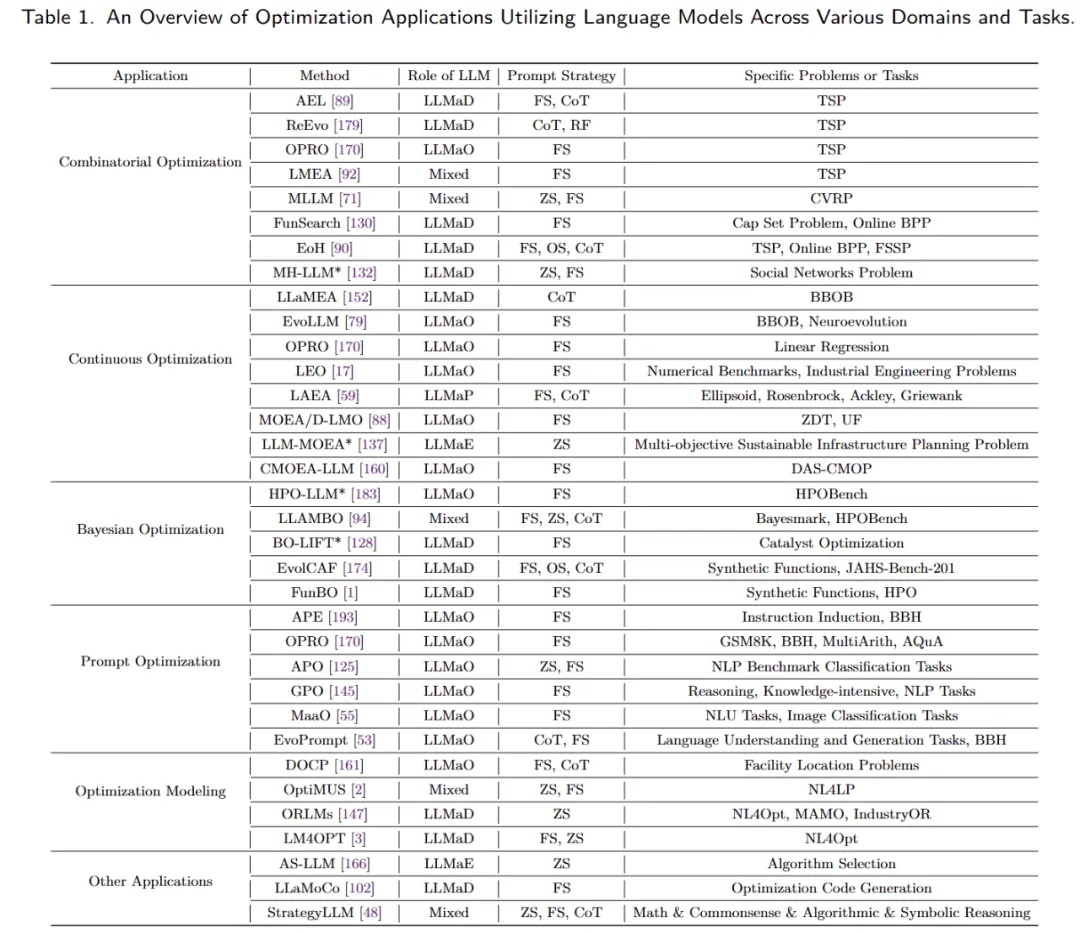
6. 大模型用于算法设计的应用领域
我们整理了四个主要的应用领域:1)优化,2)机器学习,3)科学发现,4)工业。其主要工作按照应用类别、方法、大模型结合范式、提示词策略和具体应用问题进行了分类罗列。具体介绍可以在全文中查看。
编辑

编辑

编辑
7. 未来发展方向
- 算法设计大模型 与使用通用的预训练 LLMs 不同,研究如何专门训练 LLM 以自动设计算法是值得的。在开发领域特定 LLM 时可以探索以下几个方面:1)训练领域 LLM 成本高且资源消耗大。借助领域数据和知识可以减小特定应用的算法 LLM 的规模。2)算法设计生成和收集领域数据存在挑战。与通用代码生成或语言处理任务不同,没有专门用于算法设计的大型且格式化的数据。3)与其学习一个文本和代码生成模型,如何学习算法开发思想和算法推理能力仍是一个未探索的问题。
- 多模态 LLM 现有的 LLM4AD 工作主要集中在利用 LLM 的文本理解和生成能力,无论是在语言、代码还是统计方面。与传统的基于模型的优化相比,LLM 的一个优势是它们能像人类一样处理多模态信息,这一点很少被研究。已经有一些尝试展示了在算法设计中融入多模态信息的优势,预计将开发更多利用多模态 LLM 的方法和应用。
- 人类 - 大模型交互 需要进一步研究 LLM 与人类专家在算法设计中的互动。例如,在 LLMaD 工作中,LLM 可以被视为智能代理,使人类专家可以介入并接管生成、修改和评估算法等任务。研究如何促进 LLM 与人类专家之间高效且富有成效的合作将是有价值的。可以为此目的使用群体智能中的思想和技术。
- 基于 LLM 的算法评估 LLM 在算法评估中可能是有帮助的。已经进行了一些尝试来自动评估算法和评估算法设计。例如,已有工作利用基础模型自动生成定义下一个可学习任务的代码,通过生成环境和奖励函数,能够为算法评估创建各种模拟学习任务。我们期待更多关于基于 LLM 的算法评估的研究。
- 理解 LLM 的行为 在大多数研究中,LLM 作为一个黑盒模型运作。解释 LLM 的行为不仅能丰富我们对 LLM 行为的理解,还有助于那些直接请求 LLM 困难或成本高昂的情况。已经有一些尝试来近似和理解 LLM 在解决方案生成中的上下文学习行为。例如,已有人设计了一个白盒线性算子来近似 LLM 在多目标进化优化中的结果。尽管有这些初步尝试,如何解释 LLM 的行为在许多算法设计案例中仍是一个开放的问题,包括启发式生成和想法探索。
- 全自动算法设计 全自动算法设计面临两个主要挑战:1) 生成新的算法思想;2) 创建复杂、冗长的代码。虽然一些研究已经探讨了新思想的生成,但完整的算法设计(而不仅是启发式组件),包括启发式组件和详细的代码实现,仍然是一个挑战。现有应用通常专注于自动化预定义算法框架内的组件,而不是从头开始创建新算法。未来的研究需要解决这些复杂性,以推进全自动算法设计领域的发展。
- LLM4AD 的标准测试集和平台 标准测试集能促进进行公平、标准化和便捷的比较。虽然我们很高兴见证了多样化的研究工作和应用的出现,但仍然缺乏对基于 LLM 的算法设计的系统和科学的标准评估手段。未来,预计会有更多的基准测试出现,它们将在推进 LLM4AD 方面发挥关键作用。
8. 总结
本文提供了一份最新的关于大语言模型在算法设计中应用(LLM4AD)的系统性综述。通过系统回顾这一新兴研究领域的主要贡献文献,本文不仅突出了 LLM 在算法设计中的当前状态和发展,还引入了一个全新的多维分类体系,分类了 LLM 的结合范式、搜索方法、提示词方法和应用场景。这一分类体系为学术界和工业界的研究人员提供了一个框架,帮助他们理解和使用 LLM 进行算法设计。我们还讨论了该领域当前面临的限制和挑战并提出和探讨未来研究方向来激发和指引后续研究。
展望未来, LLM 与算法设计的交叉具有革命性地改变算法设计和应用方式的巨大潜力。LLM 在算法设计过程中的应用有助于极大的提高自动化程度并可能促进产生更高效、更有效和更具创造性的算法,以更好解决各个领域的复杂问题。我们希望本文能够有助于理解这一潜力,并促进 LLM4AD 这一有前景的研究领域的发展。
#90后上海女生,成美国数学大奖首位女性华人得主
由陶哲轩担任评委的2024年美国塞勒姆奖,由华人女数学家王艺霖和阿根廷数学家Miguel Walsh获得!来自上外附中的91年上海女生王艺霖,成为塞勒姆奖首位女性华人得主。
最近,美国塞勒姆奖(Salem Prize)公布了2024年度获奖人——华人女数学家王艺霖和阿根廷数学家Miguel Walsh!
王艺霖是自陶哲轩(2000年)和詹大鹏(2011年)后的第三位获得该奖的华人,也是首位女性华人得主。
塞勒姆奖给王艺霖的颁奖词是——
王艺霖因在复分析、概率论和数学物理之间建立了深层次的新联系,特别是在Teichmuller理论和Schramm-Loewner演化理论方面的贡献,而荣获塞勒姆奖。
Miguel Walsh是布宜诺斯艾利斯大学数学系教授。
给Miguel Walsh的颁奖词是——
Miguel Walsh因其在遍历理论、解析数论及多项式方法的贡献而获得萨勒姆奖,其中包括非传统遍历平均的收敛定理、乘法函数局部傅里叶均匀性的界限,以及对多样式上有理点的界限。
担任这届评委的陶哲轩,也在第一时间转发了此消息,并表示祝贺。
王艺霖讲解数学的视频,在Youtube和B站上就大受欢迎。
首位女性华人得主王艺霖
塞勒姆奖由普林斯顿高等研究院管理,每年颁发给在调和分析及相关领域做出杰出贡献的年轻数学家。
该奖项以法国数学家拉斐尔·萨勒姆命名,以纪念他作为20世纪伟大分析学家的遗产。
而塞勒姆奖的历届得主中,也有多位获得了菲尔兹奖。
陶哲轩表示,「王艺霖揭示了许多新的特征和方法来研究Schramm-Loewner演化,这推动了复平面中许多重要的随机结构。我个人非常期待看到她的工作将来如何推动这一领域的发展。」
在博士论文中,王艺霖引入了一个称为Loewner能量的概念,用于量化简单平面曲线的圆度。
论文地址:https://arxiv.org/abs/1601.05297
直观上,Loewner能量能测量曲线偏离完美圆形的程度。
利用这一概念,王艺霖研究了一类独特的随机平面曲线,称为Schramm-Loewner演化(SLE),该曲线模拟了二维临界格子模型和共形场论(CFT)中的界面。
Loewner能量的引入,使得王艺霖能够将SLE与泰希米勒理论和双曲几何联系起来。
尤其重要的是,她发现SLE环测度的作用与通用泰希米勒空间的Kähler势相一致——这是一个包含黎曼曲面泰希米勒空间作为复子流形的无限维复流形,其中Kähler结构的研究最初受到弦理论的启发。
她与Fredrik Viklund合作,基于SLE和更广泛的随机共形几何的结果,证明了关于通用泰希米勒空间的新结果。
论文地址:https://arxiv.org/abs/1903.08525
Fredrik Viklund这样回忆看到王艺霖论文时的感受——
当王艺霖的第一篇论文出现在我桌上时,我立刻对此感到兴奋,并很快开始探索关于Loewner能量的问题。
后来在一个研讨会上,她解释了她在我熟悉的SLE领域和我不熟悉的泰希米勒理论之间新发现的联系。这些联系美丽、引人入胜,甚至带有神秘色彩。我知道,这就是我想要追求的方向。
随后,王艺霖和Viklund开始了一场「紧张而富有成效的合作」。
「第一篇论文很快就完成了,但第二篇需要更艰苦的工作。在她强烈的审美感引导下,王艺霖希望两人不仅要取得最佳结果,还要实现最优雅的证明。最终,我们的工作得到了回报,完成了或许是我最满意的论文,」Viklund这样表示。
论文地址:https://arxiv.org/abs/2012.05771
在这篇论文中,两人对Loewner-Kufarev能量和Loewner-Kufarev等式进行了研究。
随后,王艺霖在与Martin Bridgeman、Kenneth Bromberg和Franco Vargas Pallete合作的最近一篇预印本论文中,将Loewner能量与双曲三维流形的重整化体积联系起来。
论文地址:https://arxiv.org/abs/2311.18767
这种联系暗示了 Loewner 能量的全息原理,令人联想到由胡安·马尔丁·马尔达塞纳(Juan Martín Maldacena)提出的弦理论中对应的AdS3/CFT2猜想。
让我们期待,王艺霖在未来利用概率方法,在随机共形几何的背景下建立更广泛的全息对应关系。
IHES所长Emmanuel Ullmo也对王艺霖表示了祝贺:「除了出色的研究成果外,王艺霖还是研究所非常活跃的成员,是IHES科学活动的推动力。她完美体现了我们在IHES所培养的合作与跨学科精神。」
个人简介
王艺霖1991年出生于中国上海,中学毕业于上海外国语大学附属外国语学校。
中学毕业后,她前往里昂Parc高中,就读数理预科班。
2011年,她考入巴黎高等师范学院,并先后获得了巴黎第六大学基础数学硕士学位和巴黎第十一大学概率与统计硕士学位。
2015年,她前往瑞士苏黎世理工学院读博,师从2006年菲尔兹奖得主Wendelin Werner。
2019年博士毕业后,她又前往美国麻省理工学院,在那里获得了C.L.E. Moore讲师职位。
随后,她成为美国国家数学科学研究所(MSRI)的Strauch博士后研究员。
2022年6月,她加入法国高等科学研究所(IHES)担任助理教授,成为由西蒙斯基金会资助的IHES首位享有盛誉的助理教授职位的持有者。IHES招人要求极高,已经有多位菲尔兹奖得主。
2025年7月,她将加盟母校苏黎世联邦理工学院任副教授。
她的研究处于复分析和概率论的交叉领域,主要关注旨在揭示随机保形几何、几何函数论和Teichmüller理论之间联系的主题。动机来自于数学物理。
她大部分时间都在研究Loewner能量、Schramm-Loewner演化、高斯自由场、Weil-Petersson Teichmüller空间、拉普拉斯算子的行列式、布朗环测度、双曲空间等。
目前,她是《伦敦数学学会公报》和《伦敦数学学会期刊》的编辑。
另一位获奖者:Miguel Walsh
Miguel Nicolás Walsh是一位阿根廷数学家,主要研究数论和遍历理论。
Walsh出生于阿根廷布宜诺斯艾利斯,2010年在布宜诺斯艾利斯大学获得本科学位,并于2012年在同一所学校获得博士学位。
他还曾是伯克利数学科学研究所的成员、加州大学洛杉矶分校纯粹与应用数学研究所的高级研究员,以及普林斯顿高等研究院的冯·诺依曼研究员。
Walsh曾获得克雷研究奖学金(Clay Research Fellowship),并曾任牛津大学默顿学院(Merton College)的研究员。他目前是布宜诺斯艾利斯大学的数学教授。
他于2013年获得MCA奖。2014年因对数学的贡献获得ICTP拉马努金奖(Ramanujan Prize),至今他是这两个奖项的最年轻得主。
2017年6月,Walsh受邀在2018年巴西里约热内卢的国际数学家大会上展示其研究成果。2021年,他被选为美洲数学大会(Mathematical Congress of the Americas)的全体大会报告人。
2024年,他在迈阿密举行的数学波会议(Mathematical Waves Conference)上获得美洲数学科学研究所(Institute of the Mathematical Sciences of America)首届IMSA奖。同年,他还获得拉丁美洲和加勒比数学联盟(Mathematical Union of Latin America and the Caribbean)的UMALCA奖。
菲尔兹奖得主的摇篮:塞勒姆奖
塞勒姆奖设立于1968年,以纪念拉斐尔·塞勒姆(Raphaël Salem,1898-1963)而命名。
塞勒姆是一位数学家,以深入研究傅里叶级数与数论之间的联系以及率先将概率方法应用于这些领域而闻名。
他在法国调和分析的发展中发挥了重要作用。尤其是他在1963年出版的《Algebraic Numbers and Fourier Analysis》和《Ensembles Parfaits et Séries Trigonométriques》的书籍,以及他与Zygmund共同撰写的关于随机三角级数的论文(Acta Math. 91 (1954), 245–301)都具有很大的影响力。
该奖由普林斯顿高等研究院数学学院颁发。萨勒姆奖被视为极具声望的奖项,许多菲尔兹奖得主曾经获得过此奖。1968年至今,总共有56位获奖者,其中诞生了10位菲尔兹奖得主。
参考资料:
https://www.ias.edu/math/activities/salem-prize
https://www.ias.edu/math/2024-salem-prize-winners
https://www.ihes.fr/en/salem-prize-wang/
https://yilwang.weebly.com/
https://mathstodon.xyz/@tao/113365176960404250
原文地址:https://blog.csdn.net/weixin_49587977/article/details/143572698
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!