浅析扩散模型与图像生成【应用篇】(七)——Prompt-to-Prpmpt
7. Prompt-to-Prompt Image Editing with Cross Attention Control
本文提出一种利用交叉注意力机制实现文本驱动的图像编辑方法,可以对生成图像中的对象进行替换,整体改变图像的风格,或改变某个词对生成图像的影响程度,如下图所示。

之前的文本驱动的图像生成方法很难对图像的内容进行精细地编辑,哪怕只改变了一点文本提示的内容都可能让生成的结果发生非常大的改变,而无法保留原有的内容和结构。为了保留图像整体的结构,只对特定目标进行修改,有些方法通过让使用者给出要修改对象的掩码,引导算法只针对掩码的内容进行修改。但这种方式不仅非常麻烦,而且无法对整体风格进行编辑。因此作者希望提出一种只需修改文本提示内容,就可以直接编辑生成图像,且保持原本生成结果的内容和结构特征。
作者发现在交叉注意力层建立了文本提示和图像像素之间的联系,通过在生成过程中插入或者修改交叉注意力层就可以实现对对应像素点的修改。实现的过程如下
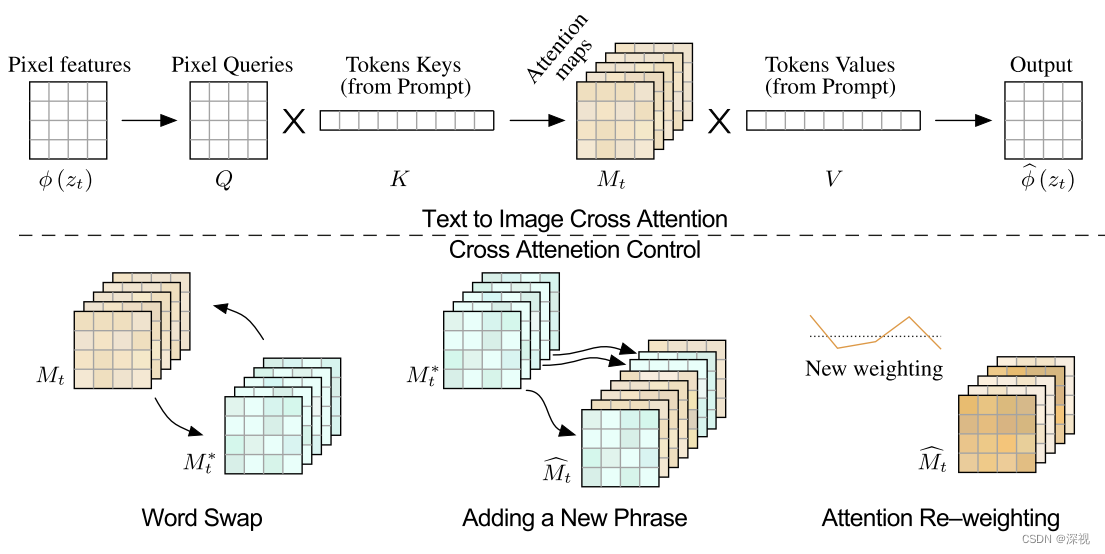
首先,我们先回顾一下文本驱动的图像生成过程中,交叉注意力层是如何工作的。包含噪声的图像
z
t
z_t
zt其对应的特征图
ϕ
(
z
t
)
\phi(z_t)
ϕ(zt),经过一个线性层映射为一个query矩阵
Q
=
ℓ
Q
(
ϕ
(
z
t
)
)
Q=\ell_{Q}(\phi(z_t))
Q=ℓQ(ϕ(zt)),而文本提示
P
\mathcal{P}
P的特征向量
ψ
(
P
)
\psi(\mathcal{P})
ψ(P)被分别映射为key和value矩阵,
K
=
ℓ
K
(
ψ
(
P
)
)
K =\ell_K(\psi(\mathcal{P}))
K=ℓK(ψ(P))和
V
=
ℓ
V
(
ψ
(
P
)
)
V =\ell_V(\psi(\mathcal{P}))
V=ℓV(ψ(P))。则注意力图为
M
=
Softmax
(
Q
K
T
d
)
M=\operatorname{Softmax}\left(\frac{Q K^{T}}{\sqrt{d}}\right)
M=Softmax(dQKT)其中的元素
M
i
j
M_{ij}
Mij表示第
j
j
j个token对于第
i
i
i个像素的权重值。交叉注意力层的输出为
ϕ
^
(
z
t
)
=
M
V
\hat{\phi}(z_t)=MV
ϕ^(zt)=MV,其被用于更新
ϕ
(
z
t
)
\phi(z_t)
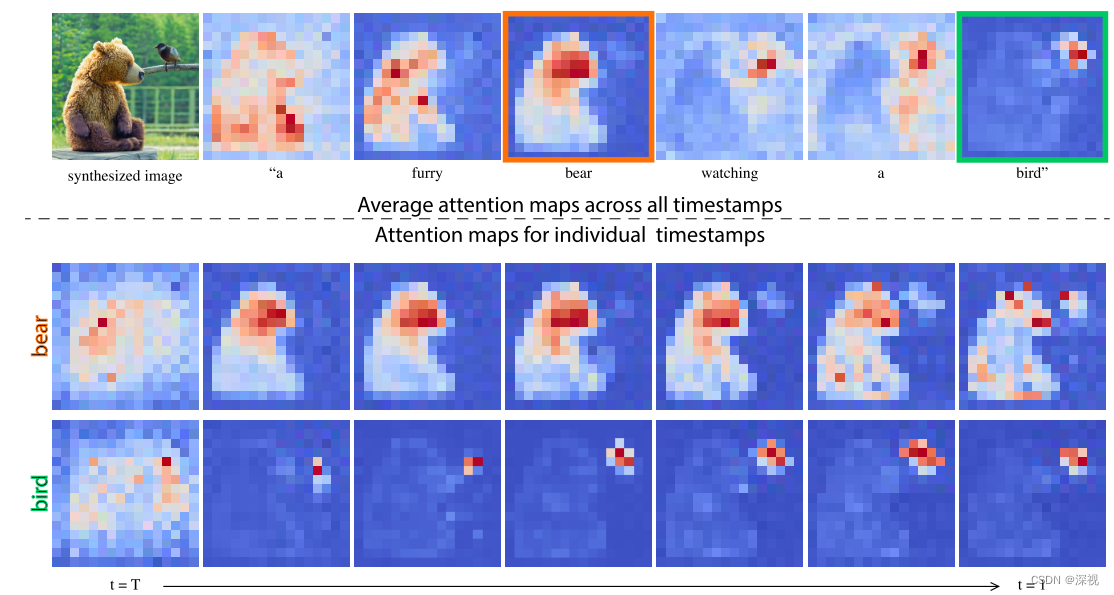
ϕ(zt)。注意力层中每个单词和图像像素之间的对应关系如下图所示,可见即便在生成过程的早期阶段,单词和对应的像素之间已经具备较为明确的匹配关系。因此通过修改交叉注意力层就能够针对性的改变生成图像的内容。
假设原本的文本提示
P
\mathcal{P}
P生成的图像为
I
\mathcal{I}
I,其对应的注意力图
M
M
M中包含着生成结果的主要内容信息。在根据修改后的文本提示
P
∗
\mathcal{P}^*
P∗对图像进行编辑时,通过将
M
M
M插入到生成过程中,则可以保证修改后的生成结果
I
∗
\mathcal{I}^*
I∗能够保留原有结果的主要内容。整个算法流程如下图所示

其中
D
M
(
z
t
,
P
,
t
,
s
)
DM\left(z_{t}, \mathcal{P}, t, s\right)
DM(zt,P,t,s)表示根据噪声图
z
t
z_t
zt,文本提示
P
\mathcal{P}
P,时刻
t
t
t和随机数种子
s
s
s进行单步反向去噪生成
x
t
−
1
x_{t-1}
xt−1的过程。
M
t
M_t
Mt和
M
t
∗
M_t^*
Mt∗分别表示原始文本和修改后文本对应的注意力图,对二者进行编辑可以得到
M
t
^
\hat{M_t}
Mt^,使用其取代
M
t
∗
M_t^*
Mt∗再进行反向去噪即可生成编辑后的图像。不同的修改方式对应了不同的编辑方法,下面将详细的介绍对注意力层进行编辑的方法
E
d
i
t
(
M
t
,
M
t
∗
,
t
)
Edit(M_t,M_t^*,t)
Edit(Mt,Mt∗,t)。
1. 更换单词(Word Swap)
对于更改生成文本中某个单词的修改方式,如把“dog”换成“cat”。可以在某个生成步骤
τ
\tau
τ之后,直接用
M
t
∗
M_t^*
Mt∗取代
M
t
M_t
Mt,如下式所示
Edit
(
M
t
,
M
t
∗
,
t
)
:
=
{
M
t
∗
if
t
<
τ
M
t
otherwise.
\operatorname{Edit}\left(M_{t}, M_{t}^{*}, t\right):=\left\{\begin{array}{ll} M_{t}^{*} & \text { if } t<\tau \\ M_{t} & \text { otherwise. } \end{array}\right.
Edit(Mt,Mt∗,t):={Mt∗Mt if t<τ otherwise. 正如我们前面所提到的,在生成过程的前几步就已经确定了生成对象的主要内容,因此可以先用原本的注意力图
M
t
M_t
Mt进行一定次数的迭代,
t
=
T
→
τ
t=T\rightarrow\tau
t=T→τ。然后再用修改后的注意力图
M
t
∗
M_t^*
Mt∗取代
M
t
M_t
Mt,从而对在保留原本生成结果主体内容不变的基础上,根据更改的单词进行具体内容的修改。如下图所示,随着
τ
\tau
τ取值的不断变大,也就是越早使用
M
t
∗
M_t^*
Mt∗替换
M
t
M_t
Mt(图中越靠近右边的部分),则生成的对象就越能更多的保留原本生成的内容,而如果完全不加入原本的注意力图
M
t
M_t
Mt,则修改后的生成结果和原本生成结果之间基本没有任何联系。

2. 添加新的短语(Adding a New Phrase)
这也是一个非常常见的修改方式,就在原本文字提示的基础上增加一些描述性的或限制性的短语。为了保留原本的生成对象,作者采用一种匹配的方式来计算修改后的文字提示
P
∗
\mathcal{P}^*
P∗所生成的token和原本的文字提示
P
\mathcal{P}
P所生成的token之间的对应关系。
A
(
j
)
=
k
A(j)=k
A(j)=k,就表示
P
∗
\mathcal{P}^*
P∗的第
j
j
j个token与
P
\mathcal{P}
P的第
k
k
k个token相对应。若
A
(
j
)
=
N
o
n
e
A(j)=None
A(j)=None,则表示这个token是新添加的,在
P
\mathcal{P}
P中没有与之对应的token。在生成过程中,对于新添加的token就使用修改后的
(
M
t
∗
)
i
,
j
(M_t^*)_{i,j}
(Mt∗)i,j来引导生成;否则,使用原本注意力图
M
t
M_t
Mt中匹配的token
A
(
j
)
A(j)
A(j)所对应的元素
(
M
t
)
i
,
A
(
j
)
(M_t)_{i,A(j)}
(Mt)i,A(j)来引导生成,
(
Edit
(
M
t
,
M
t
∗
,
t
)
)
i
,
j
:
=
{
(
M
t
∗
)
i
,
j
if
A
(
j
)
=
None
(
M
t
)
i
,
A
(
j
)
otherwise.
\left(\operatorname{Edit}\left(M_{t}, M_{t}^{*}, t\right)\right)_{i, j}:=\left\{\begin{array}{ll} \left(M_{t}^{*}\right)_{i, j} & \text { if } A(j)=\text { None } \\ \left(M_{t}\right)_{i, A(j)} & \text { otherwise. } \end{array}\right.
(Edit(Mt,Mt∗,t))i,j:={(Mt∗)i,j(Mt)i,A(j) if A(j)= None otherwise. 简单来说,就是如果某个token在原本的描述中是存在的就直接用它对应的注意力值,如果是新添加的token那么则使用修改后的注意力值。这种修改方式既可以对图像中局部的某个对象做修改,也可以对整幅图像的整体风格做编辑,如下图所示

3. 对注意力重新加权(Attention Re–weighting)
这也是一个常用的编辑方式,就是加强或减弱文字提示中的某个描述词的程度,比如说让雪变更大一些或更小一些。作者通过引入一个权重值
c
∈
[
−
2
,
2
]
c\in[-2,2]
c∈[−2,2]来对注意力图中某个描述词对应的token进行重新加权,从而修改其影响程度,如下式
(
Edit
(
M
t
,
M
t
∗
,
t
)
)
i
,
j
:
=
{
c
⋅
(
M
t
)
i
,
j
if
j
=
j
∗
(
M
t
)
i
,
j
otherwise.
\left(\operatorname{Edit}\left(M_{t}, M_{t}^{*}, t\right)\right)_{i, j}:=\left\{\begin{array}{ll} c \cdot\left(M_{t}\right)_{i, j} & \text { if } j=j^{*} \\ \left(M_{t}\right)_{i, j} & \text { otherwise. } \end{array}\right.
(Edit(Mt,Mt∗,t))i,j:={c⋅(Mt)i,j(Mt)i,j if j=j∗ otherwise. 这个方式也是非常的直观和简单,权重值
c
c
c为正数时则加强其效果,且数值越大加强的越多;反之,权重为负数时则减弱其效果,数值越小减弱的越明显,如下图所示。

通过上述的介绍,我们看到虽然作者提出的方法都非常简单,但其实现的效果确实非常显著。但是值得注意的是这里的编辑对象都是通过文本生成的图像,也就是对生成结果的“二次创作”,那么这个方法能不能对真实拍摄的图像进行编辑呢?答案是可以的,实现的方法就是作者先用DDIM对真实拍摄的图像进行一次重建,也就是先不断地添加噪声使其变成一个随机噪声图,然后再逐步去噪使其恢复原图。在去噪的过程中就可以使用上述的方法进行编辑了,如下图所示
这里有个问题如果真是图像没有对应的文字描述怎么办呢?大概可以用一些图像描述算法来生成对应的文本

原文地址:https://blog.csdn.net/qq_36104364/article/details/136515373
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!