ElasticSearch之Ingest Pipeline和Painless Script
写在前面
如果是我们需要在写入文档或者是返回文档时,进行修改字段值,或者增加字段等操作时,就可以考虑使用ingest pipeline和painless script。如下的需求:

1:ingest pipeline
在es 5中引入了一种新的节点类型ingest node,ingest node具备对数据预处理的能力,使用的就是ingest pipeline。ingest pipeline可以拦截index或者时bulk的请求,对数据处理后重新返回回去,最终保存通过ingest pipeline处理后的数据,如下图:
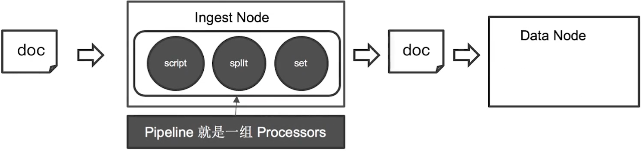
通过一组processor来处理数据,可以使用内置的processor,也可以使用插件的方式来自定义processor,其中内置的processor列表如下:


另外es提供了simulate的API来模拟ingest pipeline的执行效果:
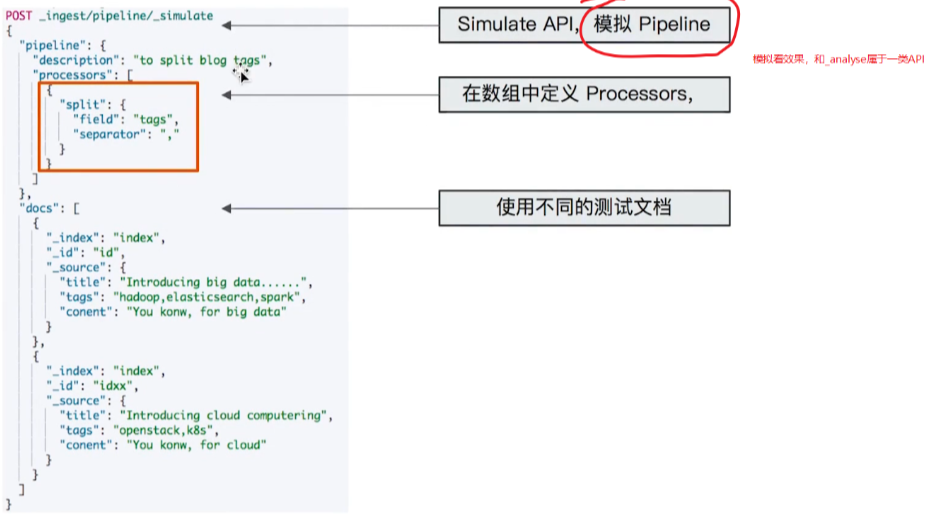
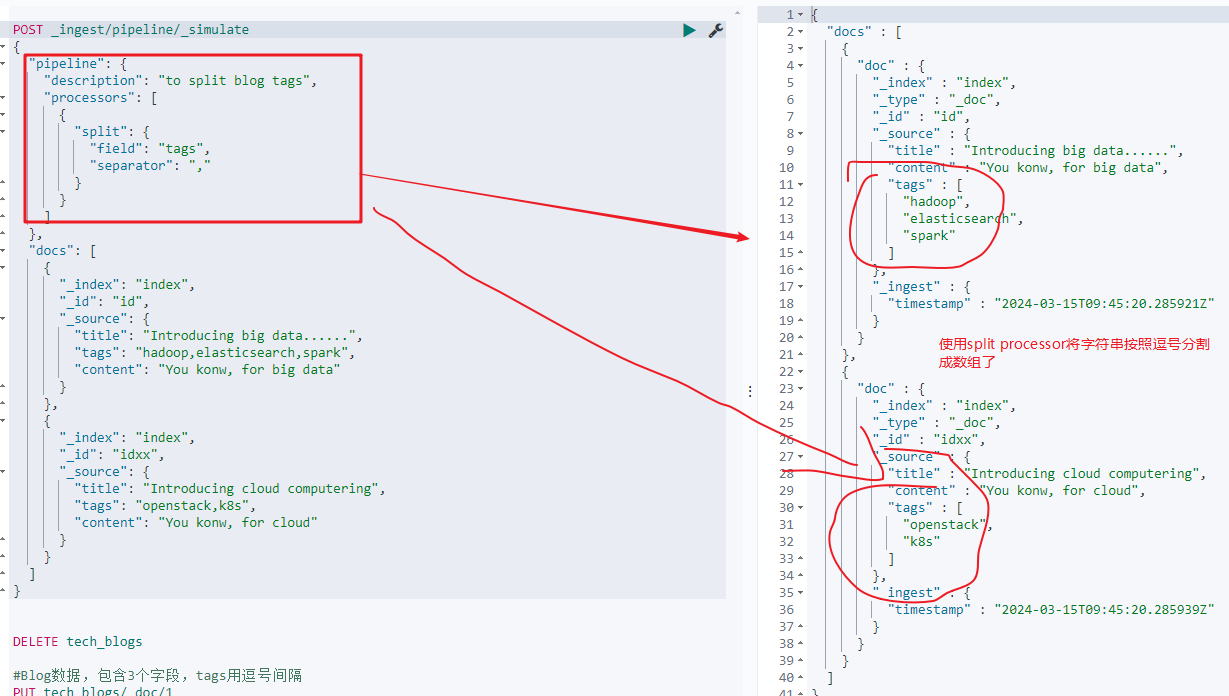
接下来我们看实际的例子。
1.1:实例
- 定义一个pipeline,方便使用
当然也可以直接写pipeline来用。
# 为ES添加一个 Pipeline
PUT _ingest/pipeline/blog_pipeline
{
"description": "a blog pipeline",
"processors": [
{
"split": {
"field": "tags",
"separator": ","
}
},
{
"set": {
"field": "views",
"value": 0
}
}
]
}
通过slit分割tags,通过set给文档增加一个字段views,值为0。
- 查看定义的pipeline

- 测试pipeline
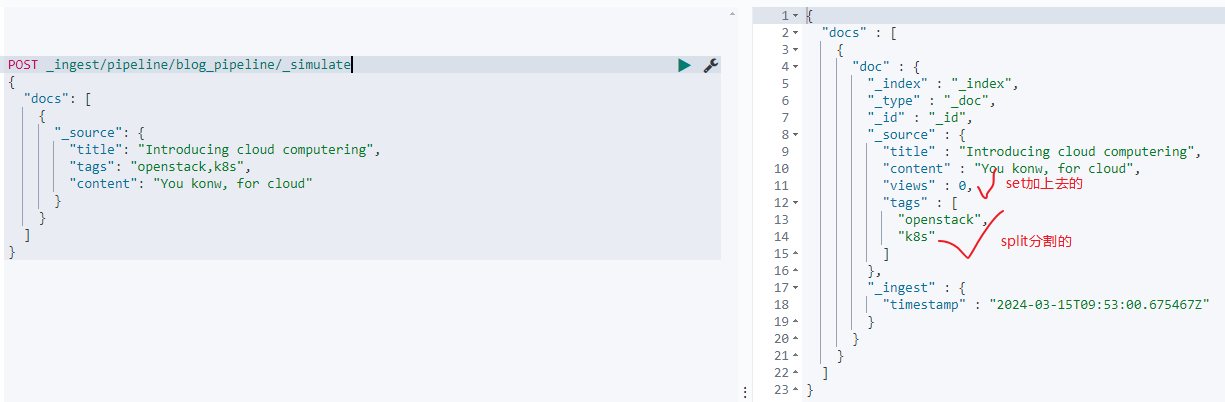
正式使用之前先来测试一下:
- 不使用pipeline新增数据
PUT tech_blogs/_doc/1
{
"title": "Introducing big data......",
"tags": "hadoop,elasticsearch,spark",
"content": "You konw, for big data"
}
- 使用pipeline新增数据
PUT tech_blogs/_doc/2?pipeline=blog_pipeline
{
"title": "Introducing cloud computering",
"tags": "openstack,k8s",
"content": "You konw, for cloud"
}
看下新增的数据:
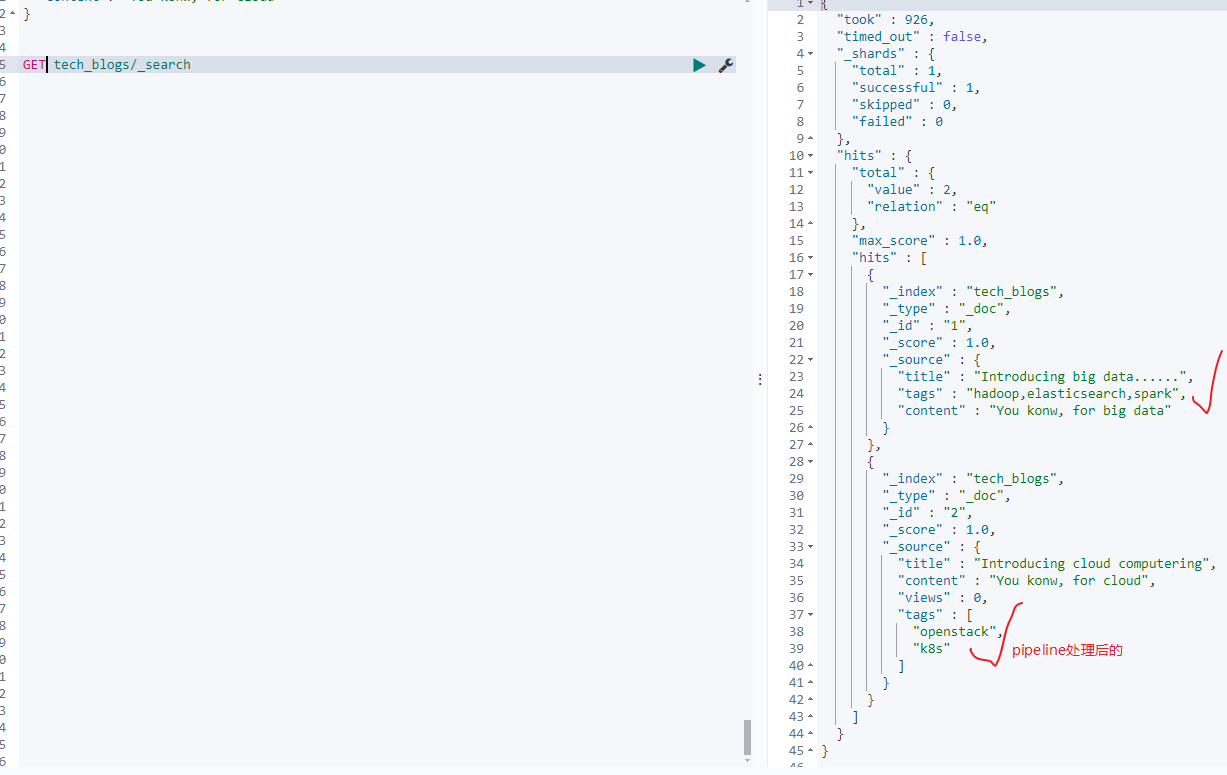
- update_by_query使用pipeline重建本索引
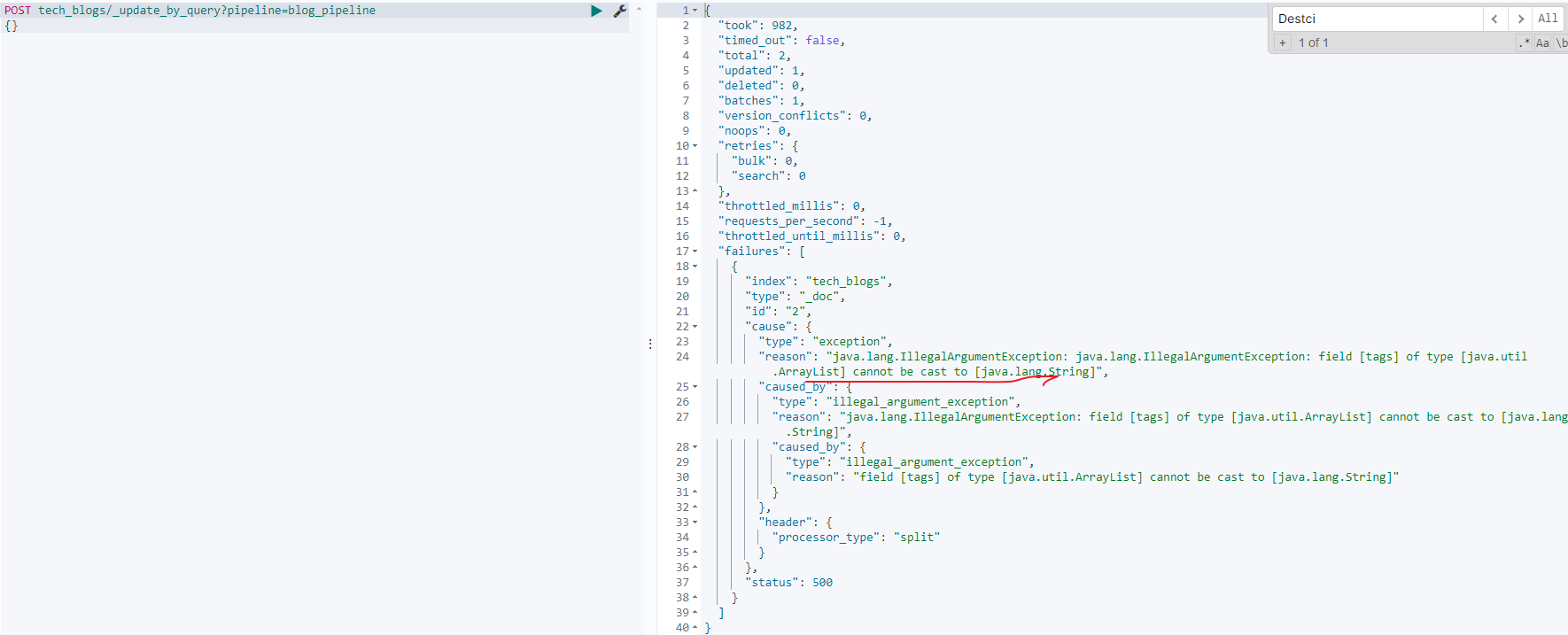
因为pipeline处理后插入的数据底层是ArrayList类型,无法再执行split操作,想要重建索引的话,只需要将已经被pipeline处理过数据过滤掉即可,如果是包含views就是处理过的,如下:
POST tech_blogs/_update_by_query?pipeline=blog_pipeline
{
"query": {
"bool": {
"must_not": {
"exists": {
"field": "views"
}
}
}
}
}
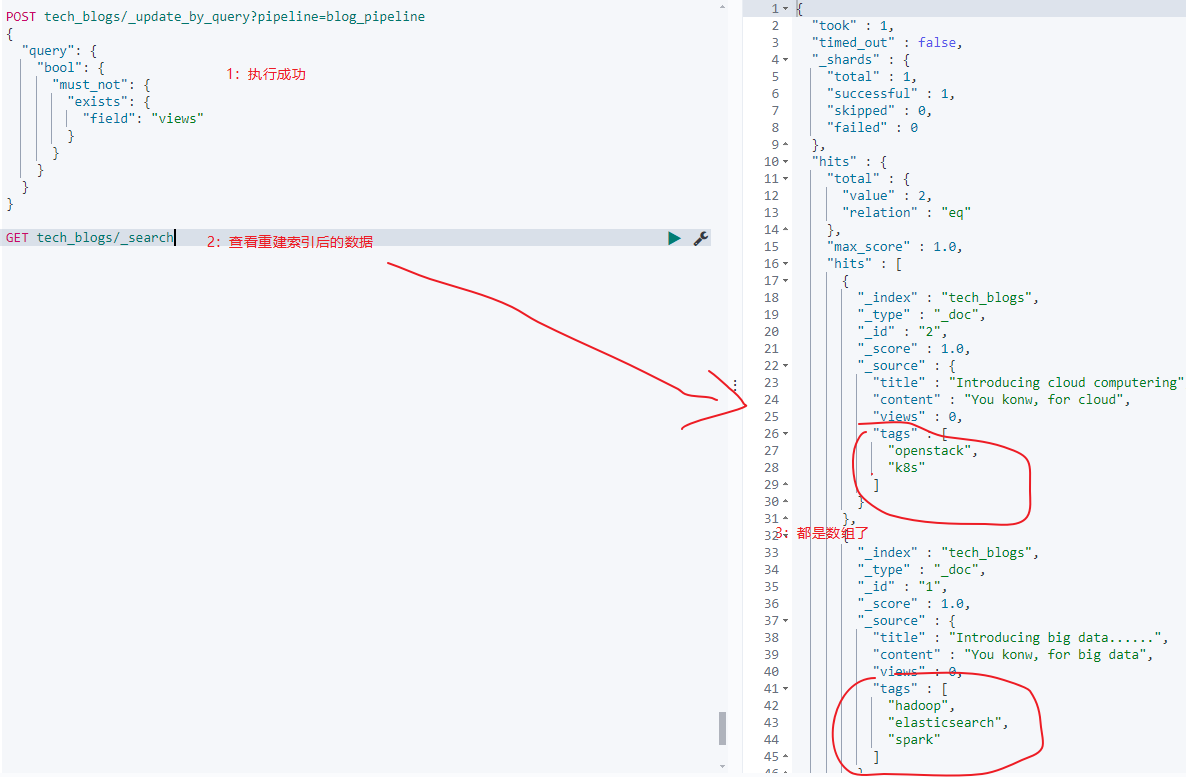
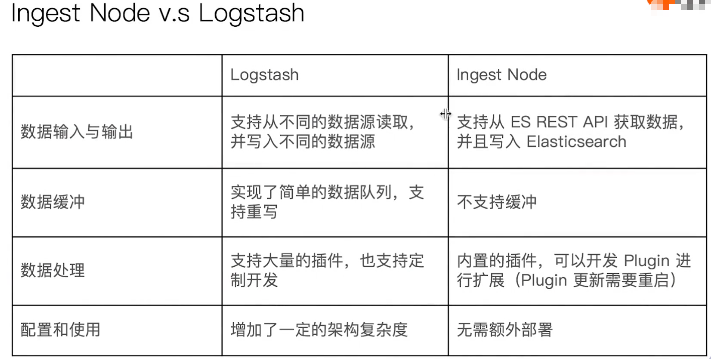
1.2:和logstash的比较
2:painless script
palinless script载es5引入,支持Java,其可实现功能如下:
1:对写入的文档增加,删除,修改字段,可配合ingest pipeline使用
2:对返回的文档增加,删除,修改字段(此时不会影响数据库中的文档)
3:function score,基于相关度评分,按照新规则生成新评分,从而影响最终文档的排序结果:https://dongyunqi.blog.csdn.net/article/details/136341656
2.1:painless 上下文
需要需要在painless脚本中访问文档数据,执行具体的操作,所以就需要对文档的访问,而对文档的访问在不同的上下文中是不一样的,主要有如下三种:
1:在pipeline中,通过ctx.fieldname的方式来访问
2:在update中通过ctx_source.fieldname的方式来访问
3:在search和aggregation中通过dock[fieldname]的方式来访问
2.2:实例
2.2.1:pipeline
使用splitprocesscor将字符串分割为字符串,使用painless scrit增加属性content_length,使用setprocessor增加属性views并设置值为0。
POST _ingest/pipeline/_simulate
{
"pipeline": {
"description": "to split blog tags",
"processors": [
{
"split": {
"field": "tags",
"separator": ","
}
},
{
"script": {
"source": """
if(ctx.containsKey("content")){
ctx.content_length = ctx.content.length();
}else{
ctx.content_length=0;
}
"""
}
},
{
"set":{
"field": "views",
"value": 0
}
}
]
},
"docs": [
{
"_index":"index",
"_id":"id",
"_source":{
"title":"Introducing big data......",
"tags":"hadoop,elasticsearch,spark",
"content":"You konw, for big data"
}
},
{
"_index":"index",
"_id":"idxx",
"_source":{
"title":"Introducing cloud computering",
"tags":"openstack,k8s",
"content":"You konw, for cloud"
}
}
]
}
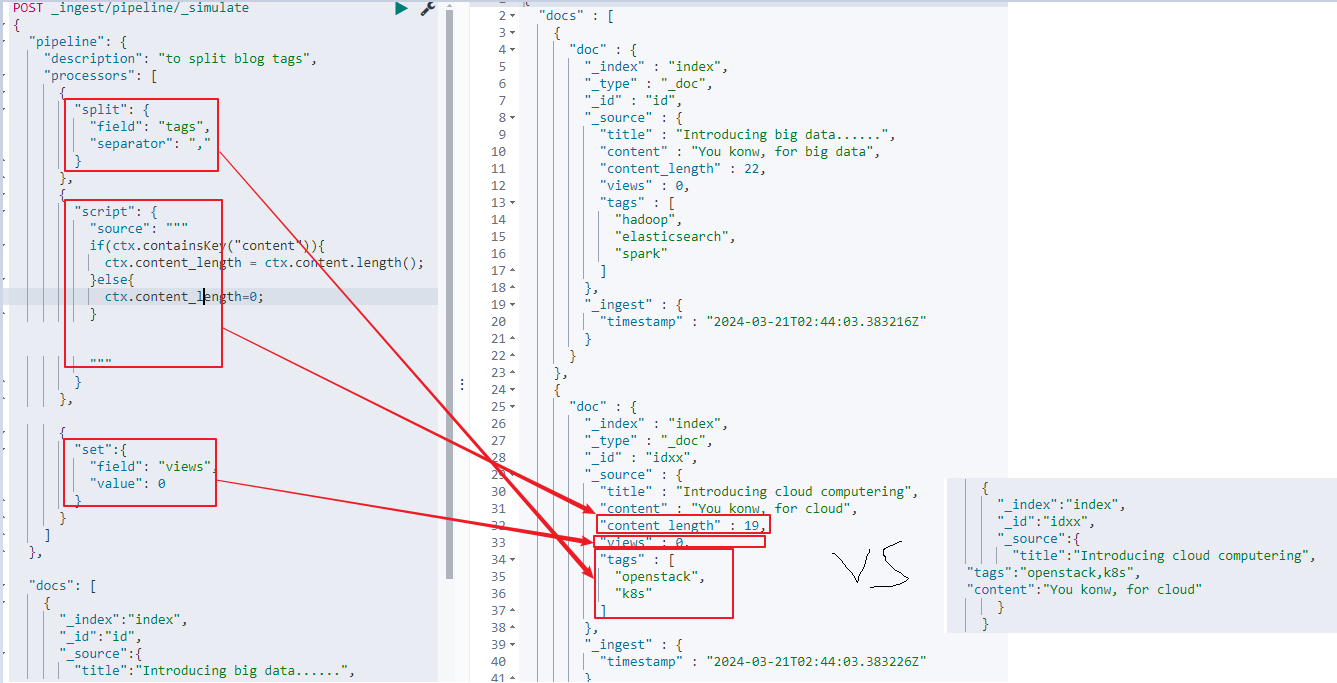
2.2.2:update
- 准备测试数据
DELETE tech_blogs
PUT tech_blogs/_doc/1
{
"title":"Introducing big data......",
"tags":"hadoop,elasticsearch,spark",
"content":"You konw, for big data",
"views":0
}
- 将views增加100
POST tech_blogs/_update/1
{
"script": {
"source": "ctx._source.views += params.new_views",
"params": {
"new_views": 100
}
}
}
GET tech_blogs/_search
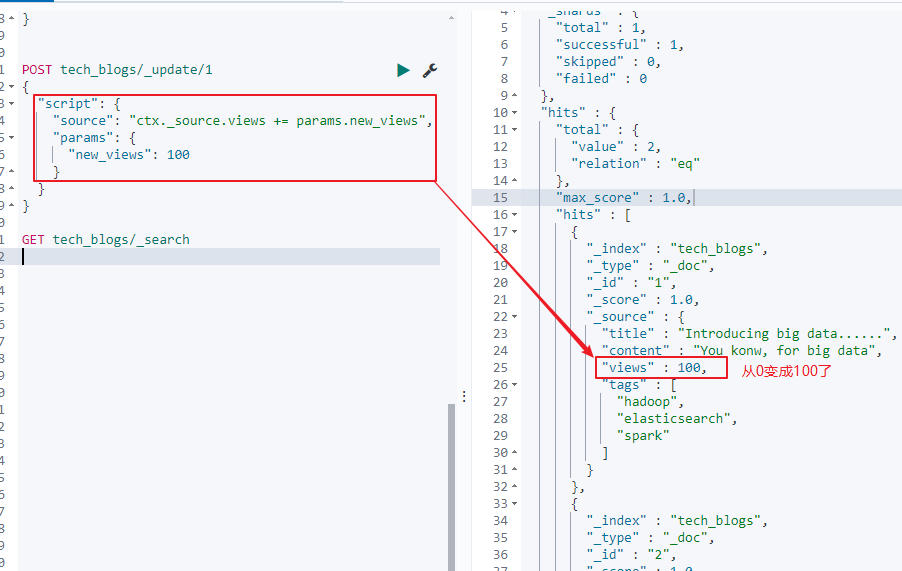
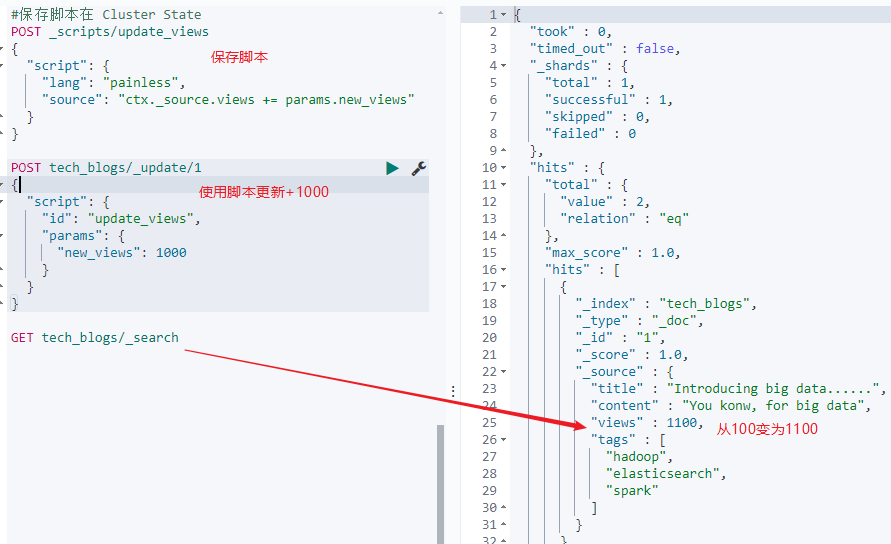
- 使用预定义painless脚本的方式更新
预定义painless脚本,并通过入参的方式,给views+1000。
#保存脚本在 Cluster State
POST _scripts/update_views
{
"script": {
"lang": "painless",
"source": "ctx._source.views += params.new_views"
}
}
POST tech_blogs/_update/1
{
"script": {
"id": "update_views",
"params": {
"new_views": 1000
}
}
}
GET tech_blogs/_search
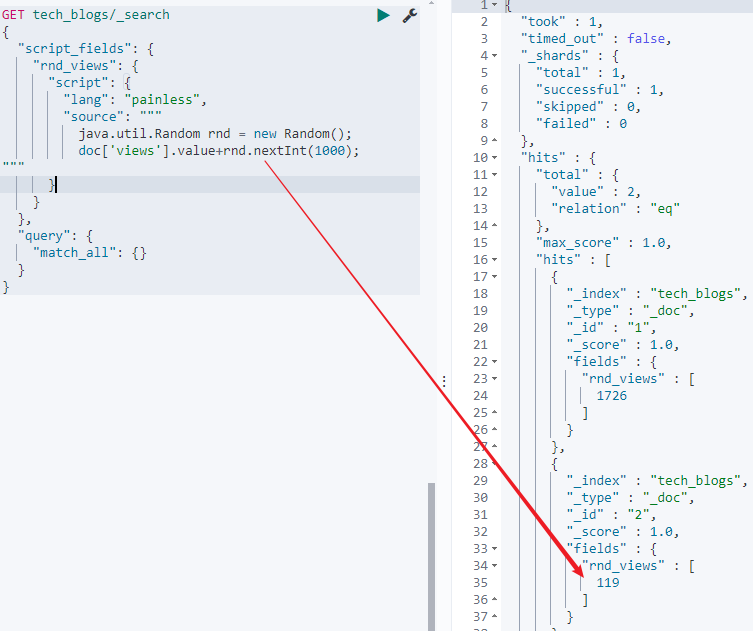
2.2.3:search
返回结果中增加rnd_views字段,其中以views字段并给其加上1000以内的随机数获取作为值:
GET tech_blogs/_search
{
"script_fields": {
"rnd_views": {
"script": {
"lang": "painless",
"source": """
java.util.Random rnd = new Random();
doc['views'].value+rnd.nextInt(1000);
"""
}
}
},
"query": {
"match_all": {}
}
}
写在后面
参考文章列表
原文地址:https://blog.csdn.net/wang0907/article/details/136699246
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!