昇思25天学习打卡营第20天 | RNN实现情感分类
昇思25天学习打卡营第20天 | RNN实现情感分类
文章目录
RNN模型
循环神经网络(Recurrent Neural Network,RNN)是一类以序列数据为输入,在序列的演进方向进行递归且所有节点按链式连接的神经网络。
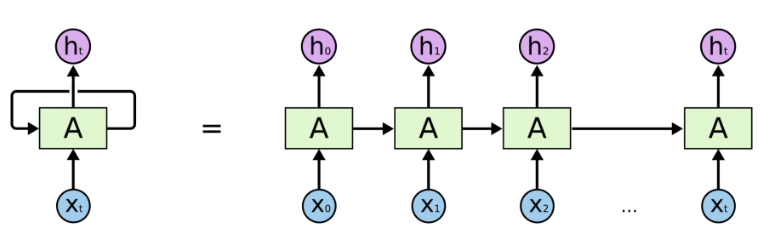
对于上图左侧的RNN Cell循环,展开为右侧的链式结构,但实际只有一个Cell的参数,以确保网络能够接受任意长度的输入。

梯度消失(Gradient Vanishing)
当把RNN网络展开后,可以看到每多循环一次,
w
1
w_1
w1的梯度就会多乘一次。
如果
w
1
w_1
w1的梯度小于
1
1
1,就会导致展开次数越多,梯度累乘就会越小,最终导致梯度消失。
梯度爆炸(Gradient Explosion)
类似的,如果 w 1 w_1 w1的梯度大于1,就会导致展开次数越多,梯度累乘就会指数级增大,最终导致梯度爆炸。
数据集
实验使用IMDB影评数据集,数据包含Positive和Negative两类,用于情感分类任务。
辅助函数
import os
import shutil
import requests
import tempfile
from tqdm import tqdm
from typing import IO
from pathlib import Path
# 指定保存路径为 `home_path/.mindspore_examples`
cache_dir = Path.home() / '.mindspore_examples'
def http_get(url: str, temp_file: IO):
"""使用requests库下载数据,并使用tqdm库进行流程可视化"""
req = requests.get(url, stream=True)
content_length = req.headers.get('Content-Length')
total = int(content_length) if content_length is not None else None
progress = tqdm(unit='B', total=total)
for chunk in req.iter_content(chunk_size=1024):
if chunk:
progress.update(len(chunk))
temp_file.write(chunk)
progress.close()
def download(file_name: str, url: str):
"""下载数据并存为指定名称"""
if not os.path.exists(cache_dir):
os.makedirs(cache_dir)
cache_path = os.path.join(cache_dir, file_name)
cache_exist = os.path.exists(cache_path)
if not cache_exist:
with tempfile.NamedTemporaryFile() as temp_file:
http_get(url, temp_file)
temp_file.flush()
temp_file.seek(0)
with open(cache_path, 'wb') as cache_file:
shutil.copyfileobj(temp_file, cache_file)
return cache_path
加载IMDB数据集
import re
import six
import string
import tarfile
class IMDBData():
"""IMDB数据集加载器
加载IMDB数据集并处理为一个Python迭代对象。
"""
label_map = {
"pos": 1,
"neg": 0
}
def __init__(self, path, mode="train"):
self.mode = mode
self.path = path
self.docs, self.labels = [], []
self._load("pos")
self._load("neg")
def _load(self, label):
pattern = re.compile(r"aclImdb/{}/{}/.*\.txt$".format(self.mode, label))
# 将数据加载至内存
with tarfile.open(self.path) as tarf:
tf = tarf.next()
while tf is not None:
if bool(pattern.match(tf.name)):
# 对文本进行分词、去除标点和特殊字符、小写处理
self.docs.append(str(tarf.extractfile(tf).read().rstrip(six.b("\n\r"))
.translate(None, six.b(string.punctuation)).lower()).split())
self.labels.append([self.label_map[label]])
tf = tarf.next()
def __getitem__(self, idx):
return self.docs[idx], self.labels[idx]
def __len__(self):
return len(self.docs)
imdb_train = IMDBData(imdb_path, 'train')
import mindspore.dataset as ds
def load_imdb(imdb_path):
imdb_train = ds.GeneratorDataset(IMDBData(imdb_path, "train"), column_names=["text", "label"], shuffle=True, num_samples=10000)
imdb_test = ds.GeneratorDataset(IMDBData(imdb_path, "test"), column_names=["text", "label"], shuffle=False)
return imdb_train, imdb_test
imdb_train, imdb_test = load_imdb(imdb_path)
预训练词向量
预训练词向量是输入单词的数值化表示,通过nn.Embedding层构造,采用查表的方式得到输入单词对应的表达向量。
在模型构造前,需要先构造Embedding层所需的词向量和词表。这里使用Glove(Global Vectors for Word Representation)预训练词向量,格式如下:
| Word | Vector |
|---|---|
| the | 0.418 0.24968 -0.41242 0.1217 0.34527 -0.044457 -0.49688 -0.17862 -0.00066023 … |
| , | 0.013441 0.23682 -0.16899 0.40951 0.63812 0.47709 -0.42852 -0.55641 -0.364 … |
使用dataset.text.Vocab将第一列单词按顺序加载,同时将每一行Vector转换为numpy.array,用于nn.Embedding加载权重。
import zipfile
import numpy as np
def load_glove(glove_path):
glove_100d_path = os.path.join(cache_dir, 'glove.6B.100d.txt')
if not os.path.exists(glove_100d_path):
glove_zip = zipfile.ZipFile(glove_path)
glove_zip.extractall(cache_dir)
embeddings = []
tokens = []
with open(glove_100d_path, encoding='utf-8') as gf:
for glove in gf:
word, embedding = glove.split(maxsplit=1)
tokens.append(word)
embeddings.append(np.fromstring(embedding, dtype=np.float32, sep=' '))
# 添加 <unk>, <pad> 两个特殊占位符对应的embedding
embeddings.append(np.random.rand(100))
embeddings.append(np.zeros((100,), np.float32))
vocab = ds.text.Vocab.from_list(tokens, special_tokens=["<unk>", "<pad>"], special_first=False)
embeddings = np.array(embeddings).astype(np.float32)
return vocab, embeddings
由于数据集中可能存在词表没有覆盖的单词,因此加入<unk>标记符;此外由于输入长度的不一致,需要对短文本进行填充,因此加入<pad>标记符。
glove_path = download('glove.6B.zip', 'https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/glove.6B.zip')
vocab, embeddings = load_glove(glove_path)
idx = vocab.tokens_to_ids('the')
embedding = embeddings[idx]
数据集预处理
通过加载器加载的IMDB数据集进行了分词处理,此处还需要额外的处理:
- 通过Vocab将所有Token处理为index id。
- 统一文本长度,不足的使用
<pad>,超出的进行截断。
import mindspore as ms
lookup_op = ds.text.Lookup(vocab, unknown_token='<unk>')
pad_op = ds.transforms.PadEnd([500], pad_value=vocab.tokens_to_ids('<pad>'))
type_cast_op = ds.transforms.TypeCast(ms.float32)
imdb_train = imdb_train.map(operations=[lookup_op, pad_op], input_columns=['text'])
imdb_train = imdb_train.map(operations=[type_cast_op], input_columns=['label'])
imdb_test = imdb_test.map(operations=[lookup_op, pad_op], input_columns=['text'])
imdb_test = imdb_test.map(operations=[type_cast_op], input_columns=['label'])
imdb_train, imdb_valid = imdb_train.split([0.7, 0.3])
imdb_train = imdb_train.batch(64, drop_remainder=True)
imdb_valid = imdb_valid.batch(64, drop_remainder=True)
模型构建
首先需要将输入文本通过查表转化为词向量表示,需要通过nn.Embedding层加载GLove词向量,然后通过RNN提取特征,最后通过一个全连接层,将特征转化为分类素含量相同的size。
此处使用nn.LSTM变种代替RNN,以避免梯度消失问题。
import math
import mindspore as ms
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore.common.initializer import Uniform, HeUniform
class RNN(nn.Cell):
def __init__(self, embeddings, hidden_dim, output_dim, n_layers,
bidirectional, pad_idx):
super().__init__()
vocab_size, embedding_dim = embeddings.shape
self.embedding = nn.Embedding(vocab_size, embedding_dim, embedding_table=ms.Tensor(embeddings), padding_idx=pad_idx)
self.rnn = nn.LSTM(embedding_dim,
hidden_dim,
num_layers=n_layers,
bidirectional=bidirectional,
batch_first=True)
weight_init = HeUniform(math.sqrt(5))
bias_init = Uniform(1 / math.sqrt(hidden_dim * 2))
self.fc = nn.Dense(hidden_dim * 2, output_dim, weight_init=weight_init, bias_init=bias_init)
def construct(self, inputs):
embedded = self.embedding(inputs)
_, (hidden, _) = self.rnn(embedded)
hidden = ops.concat((hidden[-2, :, :], hidden[-1, :, :]), axis=1)
output = self.fc(hidden)
return output
总结
这一小节内容介绍了RNN网络的基本结构,以及RNN结构所带来的梯度消失和梯度爆炸问题。对于文本数据的处理,首先需要经过Embedding层获得单词的数值表示,然后才能送入网络训练,这里使用了Glove预训练词向量作为Embedding。
打卡

原文地址:https://blog.csdn.net/qq_31254435/article/details/140595776
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!