代码随想录算法day41 | 单调栈part01 | 739. 每日温度,496.下一个更大元素 I,503.下一个更大元素II
739. 每日温度
这是单调栈一篇扫盲题目,也是经典题。
大家可以读题,思考暴力的解法,然后在看单调栈的解法。 就能感受出单调栈的巧妙
请根据每日 气温 列表,重新生成一个列表。对应位置的输出为:要想观测到更高的气温,至少需要等待的天数。如果气温在这之后都不会升高,请在该位置用 0 来代替。
例如,给定一个列表 temperatures = [73, 74, 75, 71, 69, 72, 76, 73],你的输出应该是 [1, 1, 4, 2, 1, 1, 0, 0]。
提示:气温 列表长度的范围是 [1, 30000]。每个气温的值的均为华氏度,都是在 [30, 100] 范围内的整数。
首先想到的当然是暴力解法,两层 for 循环,把至少需要等待的天数就搜出来了。
class Solution {
public int[] dailyTemperatures(int[] temperatures) {
int[] answer = new int[temperatures.length];
for(int i = 0; i < temperatures.length; i++){
for(int j = i; j < temperatures.length; j++){
if(temperatures[i] < temperatures[j]){
answer[i] = j - i;
break;
}
}
}
return answer;
}
}时间复杂度是O(n^2)
那么接下来在来看看使用单调栈的解法。
那有同学就问了,我怎么能想到用单调栈呢? 什么时候用单调栈呢?
通常是一维数组,要寻找任一个元素的右边或者左边第一个比自己大或者小的元素的位置,此时我们就要想到可以用单调栈了。
时间复杂度为O(n)。
例如本题其实就是找到一个元素右边第一个比自己大的元素,此时就应该想到用单调栈了。
那么单调栈的原理是什么呢?为什么时间复杂度是 O(n) 就可以找到每一个元素的右边第一个比它大的元素位置呢?
单调栈的本质是空间换时间,因为在遍历的过程中需要用一个栈来记录右边第一个比当前元素高的元素,优点是整个数组只需要遍历一次。
更直白来说,就是用一个栈来记录我们遍历过的元素,因为我们遍历数组的时候,我们不知道之前都遍历了哪些元素,以至于遍历一个元素找不到是不是之前遍历过一个更小的,所以我们需要用一个容器(这里用单调栈)来记录我们遍历过的元素。
在使用单调栈的时候首先要明确如下几点:
-
单调栈里存放的元素是什么?
单调栈里只需要存放元素的下标 i 就可以了,如果需要使用对应的元素,直接 T[i] 就可以获取。
-
单调栈里元素是递增呢? 还是递减呢?
注意以下讲解中,顺序的描述为从栈头到栈底的顺序,因为单纯的说从左到右或者从前到后,不说栈头朝哪个方向的话,大家一定比较懵。
这里我们要使用递增循序(再强调一下是指从栈头到栈底的顺序),因为只有递增的时候,栈里要加入一个元素 i 的时候,才知道栈顶元素在数组中右面第一个比栈顶元素大的元素是 i。
即:如果求一个元素右边第一个更大元素,单调栈就是递增的,如果求一个元素右边第一个更小元素,单调栈就是递减的。
文字描述理解起来有点费劲,接下来我画了一系列的图,来讲解单调栈的工作过程,大家再去思考,本题为什么是递增栈。
使用单调栈主要有三个判断条件。
- 当前遍历的元素T[i]小于栈顶元素T[st.top()]的情况
- 当前遍历的元素T[i]等于栈顶元素T[st.top()]的情况
- 当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况
把这三种情况分析清楚了,也就理解透彻了。
接下来我们用示例1中的 temperatures = [73, 74, 75, 71, 71, 72, 76, 73] 为例来逐步分析,输出应该是 [1, 1, 4, 2, 1, 1, 0, 0]。
首先先将第一个遍历元素加入单调栈
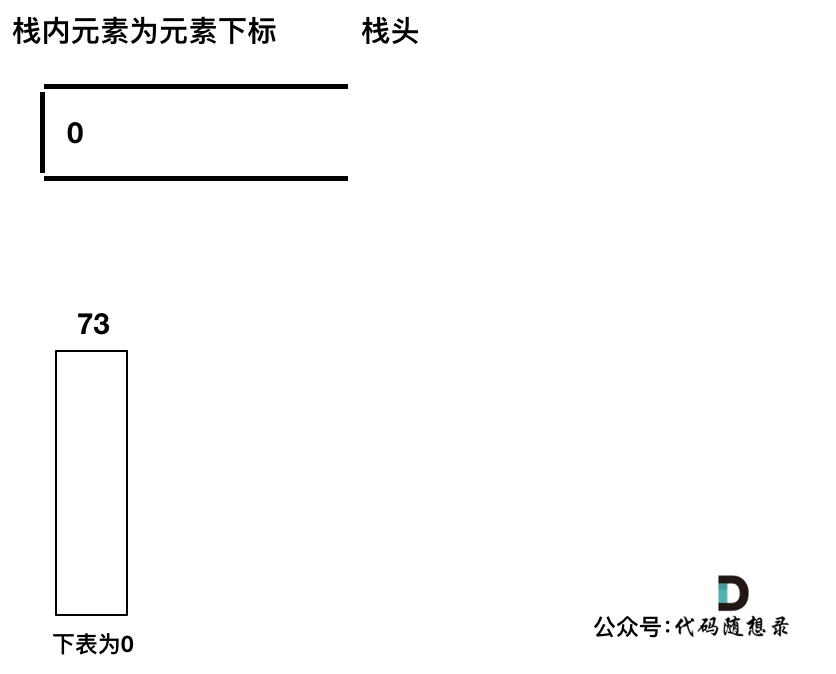
加入T[1] = 74,因为T[1] > T[0](当前遍历的元素 T[i] 大于栈顶元素 T[st.top()] 的情况)。
我们要保持一个递增单调栈(从栈头到栈底),所以将 T[0] 弹出,T[1] 加入,此时result数组可以记录了,result[0] = 1,即 T[0] 右面第一个比 T[0] 大的元素是 T[1]。
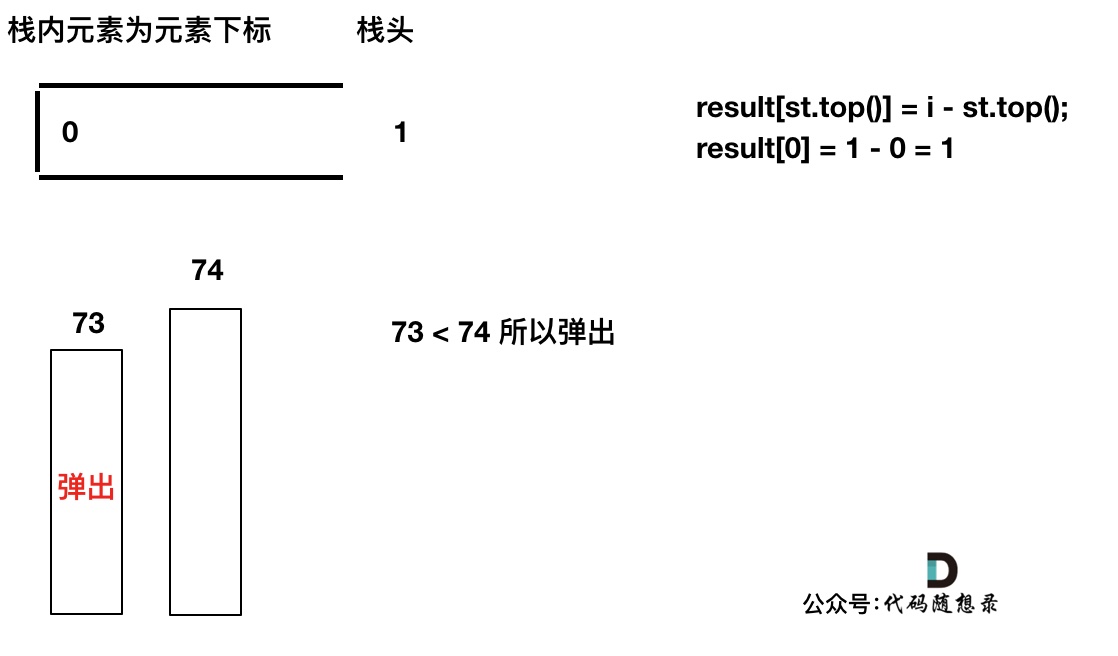
加入 T[2],同理 T[1] 弹出
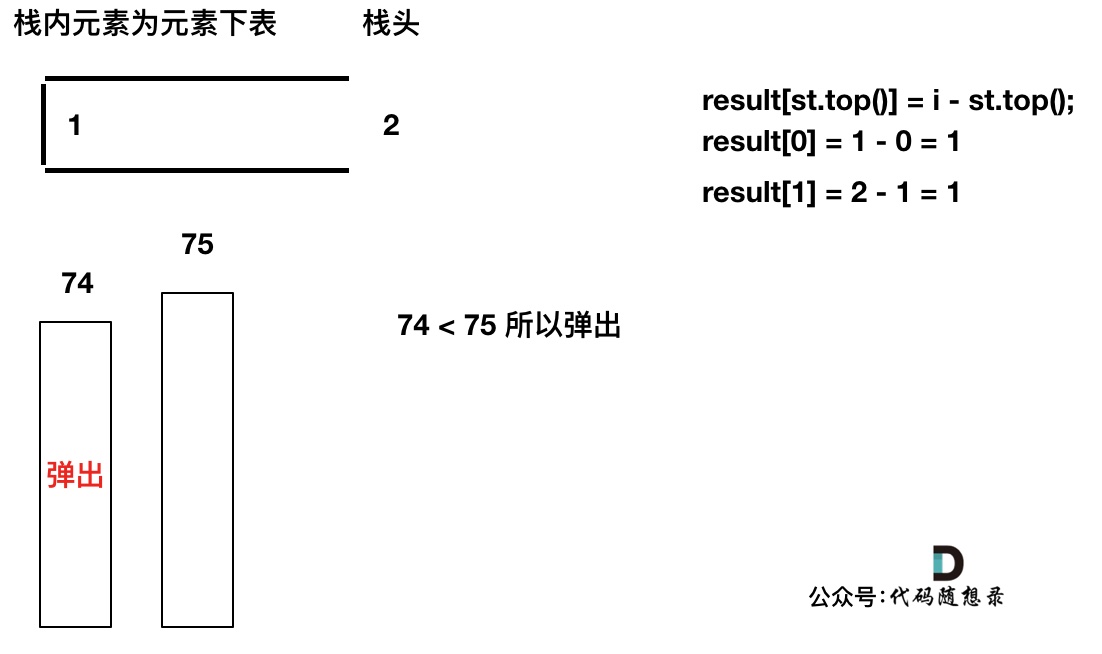
加入T[3],T[3] < T[2] (当前遍历的元素 T[i] 小于栈顶元素 T[st.top()] 的情况),加T[3]加入单调栈。
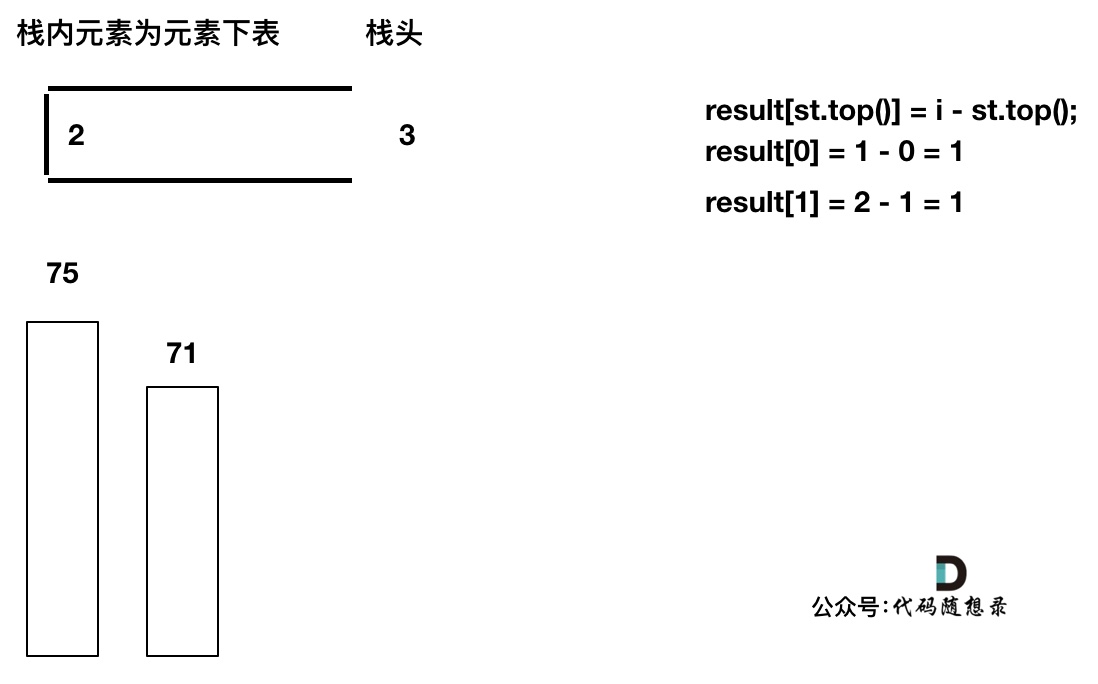
加入T[4],T[4] == T[3] (当前遍历的元素T[i]等于栈顶元素T[st.top()]的情况),此时依然要加入栈,不用计算距离,因为我们要求的是右面第一个大于本元素的位置,而不是大于等于!
![]()
加入T[5],T[5] > T[4] (当前遍历的元素 T[i] 大于栈顶元素 T[st.top()] 的情况),将 T[4] 弹出,同时计算距离,更新result
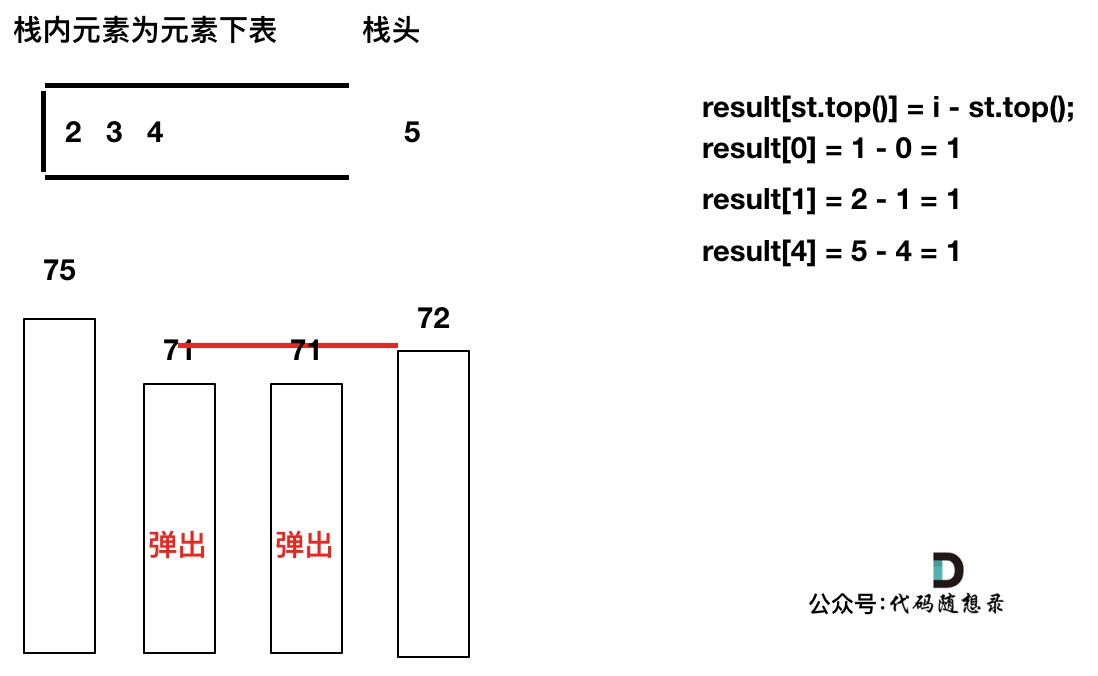
T[4]弹出之后, T[5] > T[3] (当前遍历的元素 T[i] 大于栈顶元素 T[st.top()] 的情况),将 T[3] 继续弹出,同时计算距离,更新result
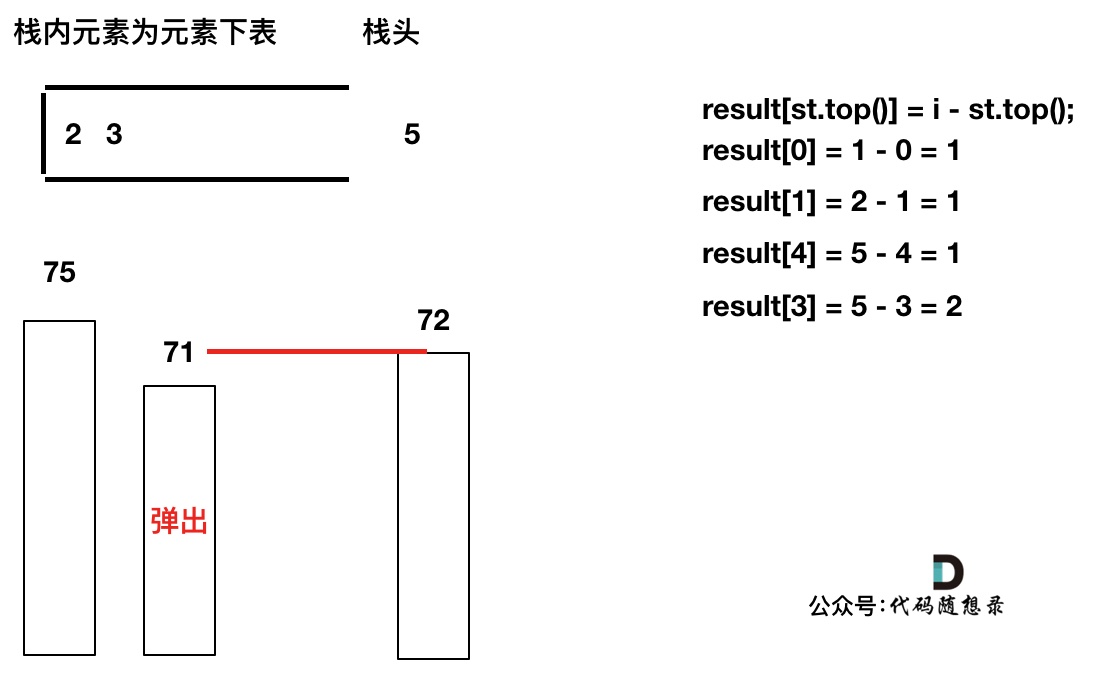
直到发现 T[5] 小于 T[st.top()],终止弹出,将 T[5] 加入单调栈
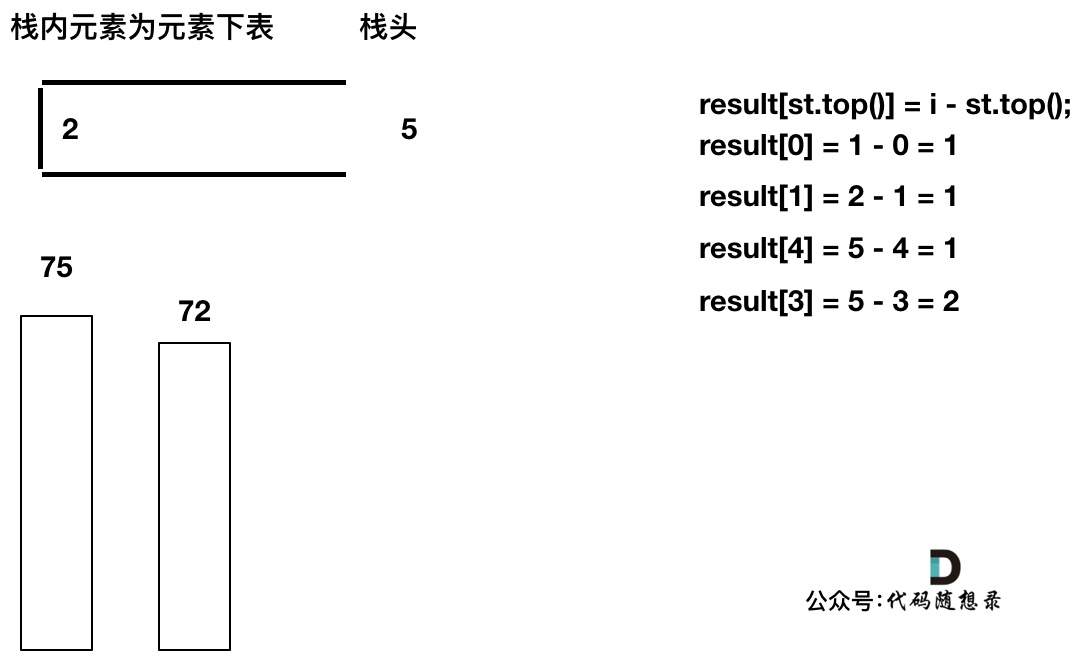
加入T[6],同理,需要将栈里的T[5],T[2]弹出
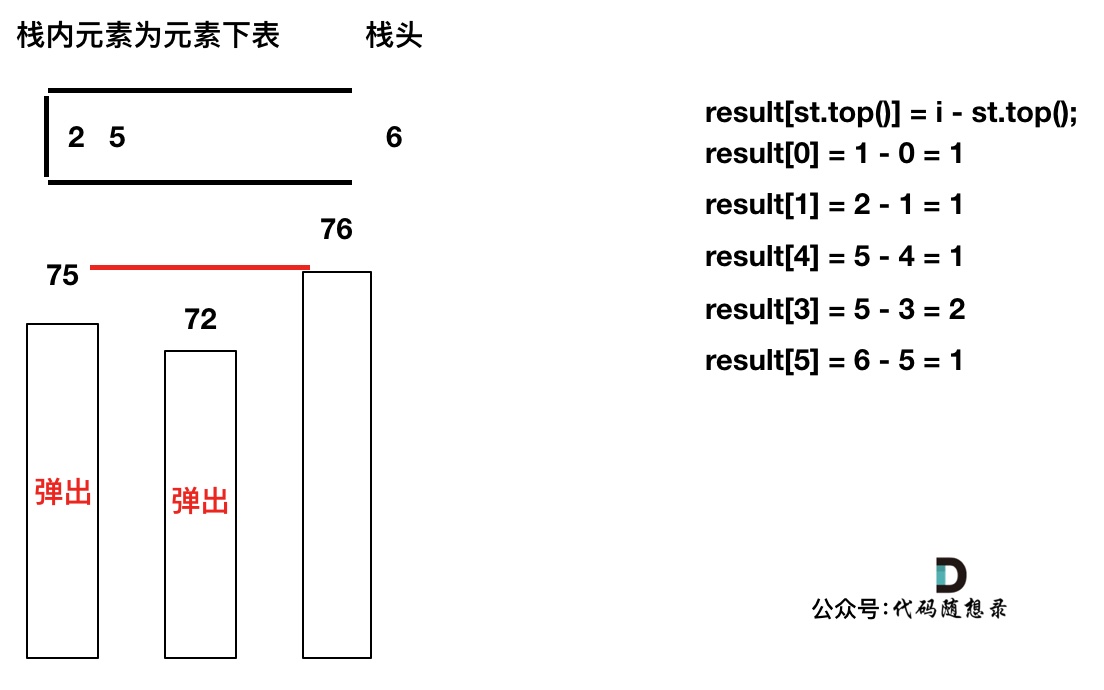
同理,继续弹出
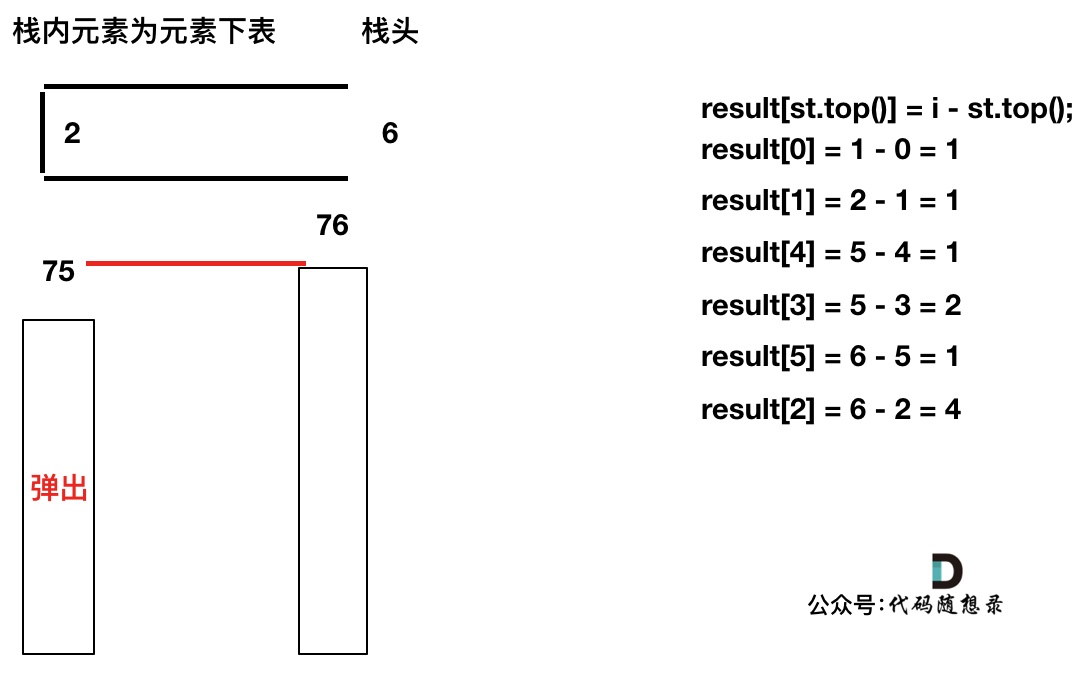
此时栈里只剩下了T[6]

加入T[7], T[7] < T[6] 直接入栈,这就是最后的情况,result数组也更新完了。
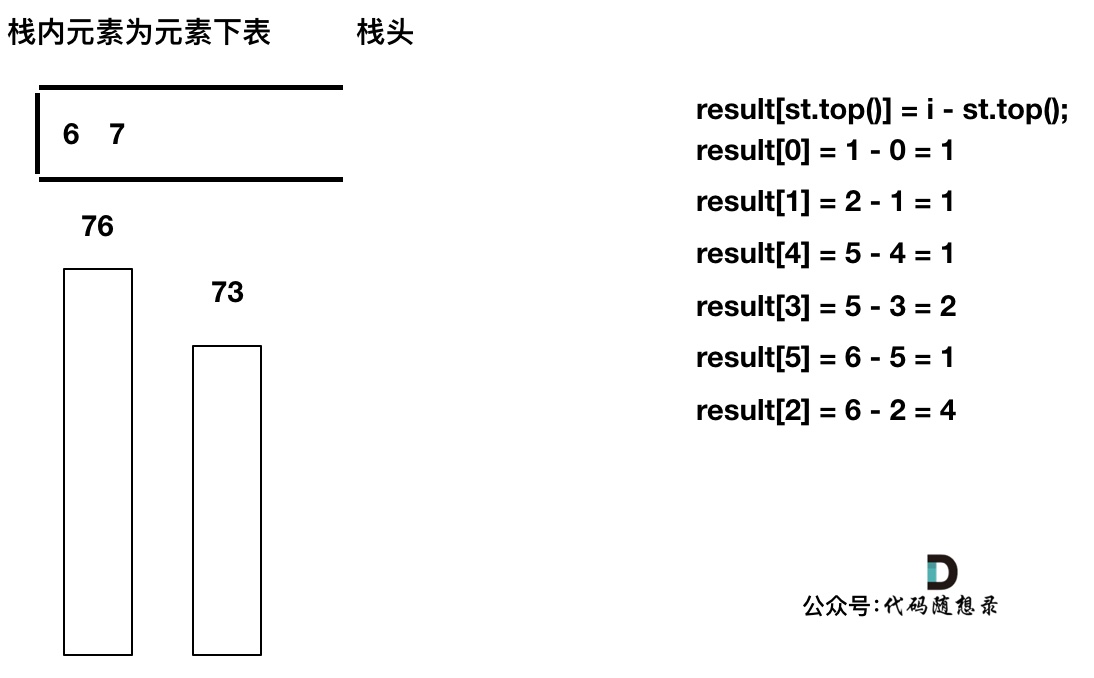
此时有同学可能就疑惑了,那result[6] , result[7]怎么没更新啊,元素也一直在栈里。
其实定义result数组的时候,就应该直接初始化为0,如果result没有更新,说明这个元素右面没有更大的了,也就是为0。
以上在图解的时候,已经把,这三种情况都做了详细的分析。
- 情况一:当前遍历的元素T[i]小于栈顶元素T[st.top()]的情况
- 情况二:当前遍历的元素T[i]等于栈顶元素T[st.top()]的情况
- 情况三:当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况
通过以上过程,大家可以自己再模拟一遍,就会发现:只有单调栈递增(从栈口到栈底顺序),就是求右边第一个比自己大的,单调栈递减的话,就是求右边第一个比自己小的。
Java代码如下:
class Solution {
public int[] dailyTemperatures(int[] temperatures) {
int lens = temperatures.length;
int[] res = new int[lens];
/**
如果当前遍历的元素 大于栈顶元素,表示 栈顶元素的 右边的最大的元素就是 当前遍历的元素,
所以弹出 栈顶元素,并记录
如果栈不空的话,还要考虑新的栈顶与当前元素的大小关系
否则的话,可以直接入栈。
注意,单调栈里 加入的元素是 下标。
*/
Deque<Integer> stack=new LinkedList<>();
stack.push(0);
for(int i=1;i<lens;i++){
if(temperatures[i]<=temperatures[stack.peek()]){
stack.push(i);
}else{
while(!stack.isEmpty()&&temperatures[i]>temperatures[stack.peek()]){
res[stack.peek()]=i-stack.peek();
stack.pop();
}
stack.push(i);
}
}
return res;
}建议一开始 都把每种情况分析好,不要上来看简短的代码,关键逻辑都被隐藏了。
精简代码如下:
class Solution {
public int[] dailyTemperatures(int[] temperatures) {
int lens=temperatures.length;
int []res=new int[lens];
Deque<Integer> stack=new LinkedList<>();
for(int i=0;i<lens;i++){
while(!stack.isEmpty()&&temperatures[i]>temperatures[stack.peek()]){
res[stack.peek()]=i-stack.peek();
stack.pop();
}
stack.push(i);
}
return res;
}
}
- 时间复杂度:O(n)
- 空间复杂度:O(n)
精简的代码是直接把情况一二三都合并到了一起,其实这种代码精简是精简,但思路不是很清晰。
建议大家把情况一二三想清楚了,先写出版本一的代码,然后在其基础上在做精简!
496.下一个更大元素 I
和 739. 每日温度 看似差不多,其实加了点难度
给你两个 没有重复元素 的数组 nums1 和 nums2 ,其中nums1 是 nums2 的子集。
请你找出 nums1 中每个元素在 nums2 中的下一个比其大的值。
nums1 中数字 x 的下一个更大元素是指 x 在 nums2 中对应位置的右边的第一个比 x 大的元素。如果不存在,对应位置输出 -1 。
示例 1:
输入: nums1 = [4,1,2], nums2 = [1,3,4,2].
输出: [-1,3,-1]
解释:
对于 num1 中的数字 4 ,你无法在第二个数组中找到下一个更大的数字,因此输出 -1 。
对于 num1 中的数字 1 ,第二个数组中数字1右边的下一个较大数字是 3 。
对于 num1 中的数字 2 ,第二个数组中没有下一个更大的数字,因此输出 -1 。示例 2:
输入: nums1 = [2,4], nums2 = [1,2,3,4].
输出: [3,-1]
解释:
对于 num1 中的数字 2 ,第二个数组中的下一个较大数字是 3 。
对于 num1 中的数字 4 ,第二个数组中没有下一个更大的数字,因此输出-1 。提示:
- 1 <= nums1.length <= nums2.length <= 1000
- 0 <= nums1[i], nums2[i] <= 10^4
- nums1和nums2中所有整数 互不相同
- nums1 中的所有整数同样出现在 nums2 中
做本题之前,建议先做一下 739.每日温度
在 739.每日温度 中是求每个元素下一个比当前元素大的元素的位置。
本题则是说 nums1 是 nums2 的子集,找 nums1 中的元素在 nums2 中下一个比当前元素大的元素。
看上去和 739.每日温度 就如出一辙了。
几乎是一样的,但是这么绕了一下,其实还上升了一点难度。
需要对单调栈使用的更熟练一些,才能顺利的把本题写出来。
从题目示例中我们可以看出最后是要求 nums1 的每个元素在 nums2 中下一个比当前元素大的元素,那么就要定义一个和 nums1 一样大小的数组 result 来存放结果。
一些同学可能看到两个数组都已经懵了,不知道要定一个一个多大的 result 数组来存放结果了。
这么定义这个result数组初始化应该为多少呢?
题目说如果不存在对应位置就输出 -1 ,所以result数组如果某位置没有被赋值,那么就应该是是 -1,所以就初始化为 -1。
在遍历 nums2 的过程中,我们要判断 nums2[i] 是否在 nums1 中出现过,因为最后是要根据 nums1 元素的下标来更新result数组。
注意题目中说是两个没有重复元素的数组 nums1 和 nums2。
没有重复元素,我们就可以用map来做映射了。根据数值快速找到下标,还可以判断 nums2[i] 是否在 nums1 中出现过。
那么预处理代码如下:
HashMap<Integer, Integer> hashMap = new HashMap<>();
for (int i = 0 ; i< nums1.length ; i++){
hashMap.put(nums1[i],i);
}使用单调栈,首先要想单调栈是从大到小还是从小到大。
本题和 739.每日温度 是一样的。
栈头到栈底的顺序,要从小到大,也就是保持栈里的元素为递增顺序。只要保持递增,才能找到右边第一个比自己大的元素。
可能这里有一些同学不理解,那么可以自己尝试一下用递减栈,能不能求出来。其实递减栈就是求右边第一个比自己小的元素了。
接下来就要分析如下三种情况,一定要分析清楚。
-
情况一:当前遍历的元素T[i]小于栈顶元素T[st.top()]的情况
此时满足递增栈(栈头到栈底的顺序),所以直接入栈。
-
情况二:当前遍历的元素T[i]等于栈顶元素T[st.top()]的情况
如果相等的话,依然直接入栈,因为我们要求的是右边第一个比自己大的元素,而不是大于等于!
-
情况三:当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况
此时如果入栈就不满足递增栈了,这也是找到右边第一个比自己大的元素的时候。
判断栈顶元素是否在 nums1 里出现过(注意栈里的元素是 nums2 的元素),如果出现过,开始记录结果。
记录结果这块逻辑有一点小绕,要清楚,此时栈顶元素在 nums2 数组中右面第一个大的元素是nums2[i](即当前遍历元素)。
代码如下:
while (!temp.isEmpty() && nums2[temp.peek()] < nums2[i]) {
if (hashMap.containsKey(nums2[temp.peek()])){
Integer index = hashMap.get(nums2[temp.peek()]);
res[index] = nums2[i];
}
temp.pop();
}
temp.add(i);以上分析完毕,Java代码如下:(其实本题代码和 739.每日温度 是基本差不多的)
class Solution {
public int[] nextGreaterElement(int[] nums1, int[] nums2) {
Stack<Integer> temp = new Stack<>();
int[] res = new int[nums1.length];
Arrays.fill(res,-1); // 初始化
HashMap<Integer, Integer> hashMap = new HashMap<>(); // 因为无重复
for (int i = 0 ; i< nums1.length ; i++){
hashMap.put(nums1[i],i);
}
temp.add(0);
for (int i = 1; i < nums2.length; i++) {
if (nums2[i] <= nums2[temp.peek()]) {
temp.add(i);
} else {
while (!temp.isEmpty() && nums2[temp.peek()] < nums2[i]) {
if (hashMap.containsKey(nums2[temp.peek()])){
Integer index = hashMap.get(nums2[temp.peek()]);
res[index] = nums2[i];
}
temp.pop();
}
temp.add(i);
}
}
return res;
}
}
// 简洁版
class Solution {
public int[] nextGreaterElement(int[] nums1, int[] nums2) {
HashMap<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums1.length; i++) {
map.put(nums1[i], i);
}
int[] res = new int[nums1.length];
Stack<Integer> stack = new Stack<>();
Arrays.fill(res, -1);
for (int i = 0; i < nums2.length; i++) {
while (!stack.isEmpty() && nums2[stack.peek()] < nums2[i]) {
int pre = nums2[stack.pop()];
if (map.containsKey(pre)) {
res[map.get(pre)] = nums2[i];
}
}
stack.push(i);
}
return res;
}
}503.下一个更大元素II
这道题和 739. 每日温度 几乎如出一辙,可以自己尝试做一做
给定一个循环数组(最后一个元素的下一个元素是数组的第一个元素),输出每个元素的下一个更大元素。数字 x 的下一个更大的元素是按数组遍历顺序,这个数字之后的第一个比它更大的数,这意味着你应该循环地搜索它的下一个更大的数。如果不存在,则输出 -1。
示例 1:
- 输入: [1,2,1]
- 输出: [2,-1,2]
- 解释: 第一个 1 的下一个更大的数是 2;数字 2 找不到下一个更大的数;第二个 1 的下一个最大的数需要循环搜索,结果也是 2。
提示:
- 1 <= nums.length <= 10^4
- -10^9 <= nums[i] <= 10^9
做本题之前建议先做 739. 每日温度 和 496.下一个更大元素Ⅰ。
这道题和 739. 每日温度 也几乎如出一辙。
不过,本题要循环数组了。
关于单调栈的讲解我在题解 739. 每日温度 中已经详细讲解了。
本题侧重与说一说,如何处理循环数组。
相信不少同学看到这道题,就想那我直接把两个数组拼接在一起,然后使用单调栈求下一个最大值不就行了!
确实可以!
将两个 nums 数组拼接在一起,使用单调栈计算出每一个元素的下一个最大值,最后再把结果集即result 数组 resize 到原数组大小就可以了。
这种写法确实比较直观,但做了很多无用操作,例如修改了nums数组,而且最后还要把result数组resize回去。
resize倒是不费时间,是O(1)的操作,但扩充nums数组相当于多了一个O(n)的操作。
其实也可以不扩充nums,而是在遍历的过程中模拟走了两边nums。
class Solution {
public int[] nextGreaterElements(int[] nums) {
//边界判断
if(nums == null || nums.length <= 1) {
return new int[]{-1}; // {-1}是数组的初始化值,表示这个数组只包含一个元素-1
}
int size = nums.length;
int[] result = new int[size];//存放结果
Arrays.fill(result,-1);//默认全部初始化为-1
Stack<Integer> st= new Stack<>();//栈中存放的是nums中的元素下标
for(int i = 0; i < 2*size; i++) {
while(!st.empty() && nums[i % size] > nums[st.peek()]) {
result[st.peek()] = nums[i % size];//更新result
st.pop();//弹出栈顶
}
st.push(i % size);
}
return result;
}
}重点就在:
把 i 的取值放大到两倍nums,但是用作下标的时候和nums取余 --> 得到循环的效果
原文地址:https://blog.csdn.net/m0_62415132/article/details/142781472
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!