自动化爬虫DrissionPage
自动化爬虫DrissionPage
目录
1.使用自动化爬虫DrissionPage
2.操作浏览器并爬取数据保存到本地
3.实战
我们在讲之前, 说说DrissionPage和Selenium这两个自动化爬虫之间的对比。
Selenium自动话爬虫需要下载对应版本的浏览器的驱动并将驱动放置到项目文件夹里面去, 需要用代码Service(r’chromedriver.exe’)来指定驱动的路径, 而DrissionPage自动化爬虫不需要这些操作。
DrissionPage相对比Selenium的语法稍微简单些。
我还是更推荐大家之后去使用DrissionPage。但不代表Selenium没有存在的意义, 很多网站的自动化爬虫的方法, 也都在用Selenium。
一、使用自动化爬虫DrissionPage
我们在使用自动化DrissionPage爬虫之前, 需要安装第三方库。
pip install drissionpage安装好以后均可使用。
导包:
from DrissionPage._configs.chromium_options import ChromiumOptions from DrissionPage._pages.chromium_page import ChromiumPage我们创建一个浏览器对象, 并打开网页
page = ChromiumPage() page.get('https://www.mi.com/shop/category/list')结果:

我们成功的打开了网页。
DrissionPage的基本操作
获取网页的源代码:
print(page.html)解析数据, 获取标签对象:
浏览器对象.ele() #拿一个标签 浏览器对象.eles() #拿多个标签根据标签名获取标签对象(tag:标签名):
print(page.ele('tag:div'))返回结果:如果根据表达式能够成功获取到某一个标签,则返回标签对象,反之则获取None。
print(page.eles('tag:div'))返回结果:如果根据表达式能够成功获取到标签,则返回列表,列表中装标签对象,反之则获取空列表。
同理, 还有id, class, name等属性, xpath之类的操作。
通过id属性获取标签对象 id=‘app’ #app:
print(page.ele('#app'))通过class属性获取标签对象 class=“breadcrumbs” .breadcrumbs:
print(page.ele('.breadcrumbs'))通过name属性获取标签对象 @属性名=属性值:
print(page.ele('@name=description'))@属性名=属性值, 这里面的属性名, 可以是其它在标签里面的任意属性。
比如:
print(page.ele('@id=app'))通过xpath筛选 配合前缀:xpath:或者x:
print(page.ele('xpath://div[@id="app"]'))或者:
print(page.ele('x://div[@id="app"]'))获取文本内容 标签对象.text:
print(page.ele('tag:title').text)获取属性值 标签对象.attr(属性名):
print(page.ele('@name=description').attr('content'))
二、操作浏览器并爬取数据保存到本地
我们还是以那个当当网为例子:
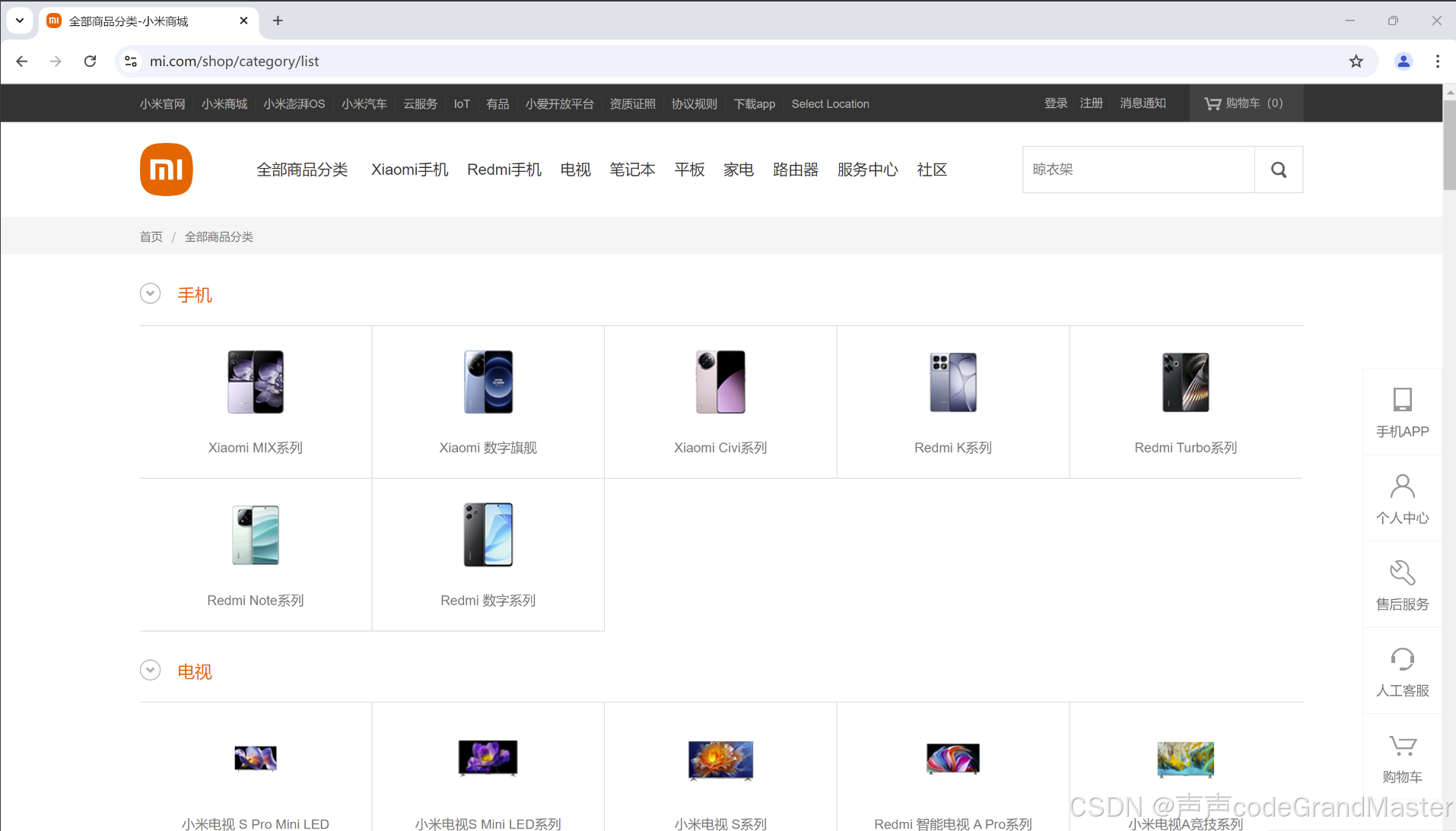
url是https://www.mi.com/shop/category/list
我们先用DrissionPage打开网页:
import time
from DrissionPage._pages.chromium_page import ChromiumPage
# alt+enter
page = ChromiumPage()
# 打开网页
page.get('https://www.mi.com/shop/category/list')
然后我们在网页的右上边那里的输入框输入文字并且点击搜索按钮进行搜索内容:
# 往搜索框中输入手机
page.ele('#search').input('手机')
# 点击放大镜
page.ele('x://input[@type="submit"]').click()
获取商品数据:
divs = page.eles('.goods-item')
获取商品和价格:
for div in divs:
# 商品名字
name = div.ele('tag:h2').text
# 价格
price = div.ele('tag:span').text
sheet.append([name, price])
print(name, price)
在这些基础上, 我们还需要加上分页查询并且要保存到excel表格里面这两个需求。
完整代码:
import time
from DrissionPage._pages.chromium_page import ChromiumPage
# alt+enter
page = ChromiumPage()
# 打开网页
page.get('https://www.mi.com/shop/category/list')
# 点击某个标签
# 标签对象.click()
# page.ele('@alt=Xiaomi MIX系列').click()
# 往文本框输入内容
# 往搜索框中输入耳机
page.ele('#search').input('手机')
# 点击放大镜
page.ele('x://input[@type="submit"]').click()
count=1
# 获取商品数据
# 每个商品都在goods-item的标签中
'''
1-没有获取到全部的数据:网页数据还没有加载,代码执行过快
2-轮动条没有到网页的最后,导致数据未加载
'''
# 写入数据到excel文件中
import openpyxl
wb = openpyxl.Workbook()
sheet = wb.active
sheet.title = '小米商城数据'
sheet.append(['名称','价格'])
while True:
time.sleep(2)
# 滚动滚动条 一页数据比较多的情况下
page.run_js('window.scrollBy(0,document.documentElement.scrollHeight)')
divs = page.eles('.goods-item')
for div in divs:
# 商品名字
name = div.ele('tag:h2').text
# 价格
price = div.ele('tag:span').text
sheet.append([name, price])
print(count,name, price)
count+=1
# 实现点击分页 如果不能继续点击,则出异常,标签对象获取不到
try:
page.ele('x://a[@class="numbers last"]',timeout=3).click()
except Exception as e:
print(e)
# 没有分页了
break
wb.save('小米商城数据.xlsx')
结果:

excel表格里面成功保存着数据。
控制台:
实战:
利用DrissionPage自动化爬虫, 打开当当网, 随便搜索内容, 搜索之后的界面, 获取每个商品里面的信息(如标题, 价格, 商店名称之类的信息)。
url是:https://www.dangdang.com/。
先不要马上看答案, 自己尝试的做一做哦!!!
参考答案:
from DrissionPage._configs.chromium_options import ChromiumOptions
from DrissionPage._pages.chromium_page import ChromiumPage
import openpyxl
page = ChromiumPage()
page.get("https://www.dangdang.com/")
page.set.window.max()
page.ele("#key_S").input("智能魔方")
page.ele(".button").click()
grocery_list = page.eles('x://ul[@class="bigimg cloth_shoplist"]//li')
wb = openpyxl.Workbook()
ws = wb.active
ws.title = "商品信息"
ws.append(["标题", "价格", "商店名称"])
count = 1
for item in grocery_list:
# 商品标题
title = item.ele('x:.//p[@class="name"]//a').attr("title")
# 价格
price = item.ele('x:.//p[@class="price"]//span').text
# 店名
try:
store_name = item.ele('x:.//p[@class="link"]//a').text
except Exception:
store_name = "无名氏"
ws.append([title, price, store_name])
print(count, "标题:", title, "\t价格:", price, "\t商店名称:", store_name)
count += 1
wb.save("商品信息.xlsx")
结果:


这道实战题, 你写出来了吗? 如果写出来的话, 给自己鼓掌哦👏
以上就是自动化爬虫DrissionPage的所有内容了, 如果有哪里不懂的地方,可以把问题打在评论区, 欢迎大家在评论区交流!!!
如果我有写错的地方, 望大家指正, 也可以联系我, 让我们一起努力, 继续不断的进步.
学习是个漫长的过程, 需要我们不断的去学习并掌握消化知识点, 有不懂或概念模糊不理解的情况下,一定要赶紧的解决问题, 否则问题只会越来越多, 漏洞也就越老越大.
人生路漫漫, 白鹭常相伴!!!
原文地址:https://blog.csdn.net/m0_55297736/article/details/143648979
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!