Redis缓存问题解决方案
Redis缓存问题解决方案
为什么使用Redis缓存:
1.在高并发的情况下,大量查询进入数据库,会大量占用数据库的连接(默认数据库连接数151),数据库压力过大就会出现connection refuse(数据库连接拒绝)问题,
2.Redis缓存数据存在内存中,读取速度比从磁盘大大提升,提高用户的体验;
Redis缓存使用场景:
1.先查后放最常见(先去Redis缓存中查询,没有再查数据库,再存入缓存中),
2.缓存预热/数据预热可解决缓存穿透问题(提前将热点数据放入Redis缓存中):比如李X琦直播间的火爆商品,
3.定时器 + Redis缓存可定时(定时加载缓存,这样服务不需要重启:5月1号就提前把11月11日的热门商品数据准备好,通过定时器在11月11日把数据加载入Redis缓存中)
缓存一致性问题的解决方案:
必须知道:读写都存在的情况下才会出现 缓存一致性问题、操作缓存使用删除而不是修改(修改逻辑复杂且消耗性能);

解决方案:
- 先更新数据库后删除缓存(删除重试)(
无法数据强一致性,存在脏读问题)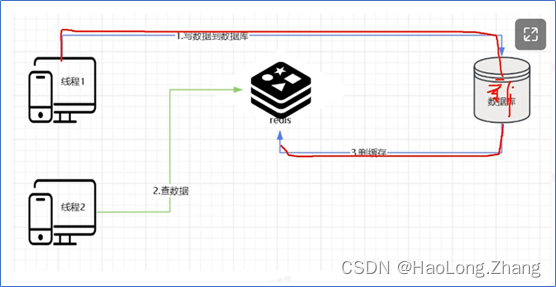
1.存在数据脏读情况1(无法避免):线程1在修改数据库的时候,线程2读取数据并把旧数据放入到redis缓存中——导致数据的脏读,
2.存在数据脏读情况2(删除缓存失败,使用mq或者cannal解决):线程1在修改数据库后,删除redis缓存中的旧数据失败,导致其他线程永远获取到的是redis中的旧数据——导致数据的脏读
-
先删除缓存再修改数据库(延迟双删)(
无法数据强一致性,存在脏读问题)
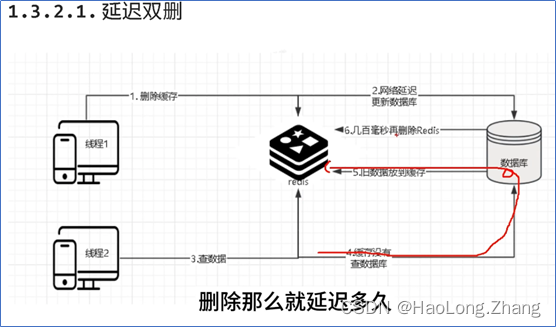
1.存在数据脏读情况(无法避免):线程1在修改数据库的时候,线程2访问了数据库并将数据写入到了redis缓存中,导致线程2和缓存中的数据是脏数据,所以需要线程1进行延迟双删将线程2存入redis中的缓存进行删除, -
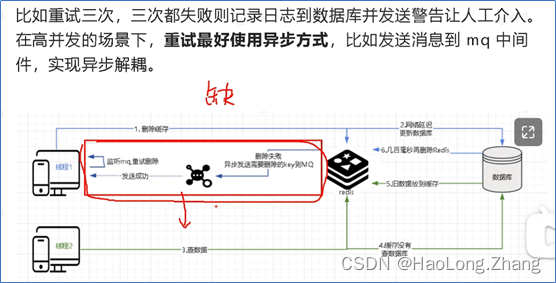
异步写(缺点:代码耦合度高):使用mq(rocketmq,rabbitmq) 完成数据同步。它会有延迟 99.999999%(
无法数据强一致性,存在脏读问题)
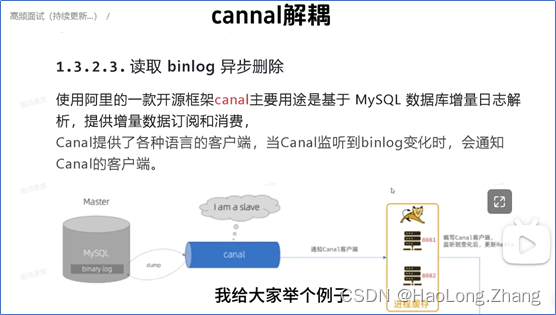
-
Cannal:Cannal监听MySQL的binlog发送变化——通知Cannal客户端——Cannal客户端监听到变化后更新Redis(
无法数据强一致性,存在脏读问题)
-
对
MySQL和redis加锁才能实现(数据强一致性,不存在脏读问题),但是效率会变低(适用于金融、支付等不能出任何差错的业务情况) -
拆表:把数据库业务需要变动字段拆出来,然后把不需要变动进行缓存
缓存穿透解决方案:
缓存穿透的原因:大量的/恶意的查询语句在Redis缓存中没有查询到,直接访问数据库中也没有,导致数据库负载过高,造成了缓存穿透问题(缓存看做访问数据库DB的马甲);
- 设置null缓存:数据库中没有查到的数据,在Redis缓存中设置
key-null-过期时间, - 缓存预热/数据预热(
缺点:不合理的查询依旧会打到数据库中,大量查询一个表中没有的数据):提起将数据放入缓存中,防止大量查询直接打在数据库, - 布隆过滤器(举例:提前将合法的数据id放入布隆过滤器中):布隆过滤器是访问Redis缓存的缓存(马甲),先访问布隆过滤器,如果布隆过滤器中
没有这条数据的id就去数据库DB查询(数据库DB没有的话设置Redis空缓存,有的话返回这条数据),布隆过滤器中有(直接访问Redis缓存数据,如果Redis缓存数据是空缓存则直接返回这空缓存——因为这个空缓存是查询数据库DB没有而设置的Redis空缓存)
设置null缓存:
前置准备:Redis依赖、Redis的yml配置、Redis初始化配置类(解决Redis键的乱码问题:key用String序列化方式,value用jackjson进行处理)
<!--SpringBoot-Redis-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
server:
port: 6380
spring:
# redis配置
redis:
# Redis数据库索引(默认为0)
database: 7
# Redis服务器地址
host: 127.0.0.1
# Redis服务器连接端口
port: 6379
# Redis服务器连接密码(默认为空)
password:
# 连接超时时间
timeout: 10s
lettuce:
pool:
# 连接池最大连接数
max-active: 200
# 连接池最大阻塞等待时间(使用负值表示没有限制)
max-wait: -1ms
# 连接池中的最大空闲连接
max-idle: 10
# 连接池中的最小空闲连接
min-idle: 0
/**
* @Description: 覆盖官方start配置机制,防止官方的redis的键乱码问题
* (key用String序列化方式,value用jackjson进行处理),
*
*/
@Configuration
public class RedisConfiguration {
/**
* @Description 改写redistemplate序列化规则
**/
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
// 1: 开始创建一个redistemplate
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
// 2:开始redis连接工厂跪安了
redisTemplate.setConnectionFactory(redisConnectionFactory);
// 创建一个json的序列化方式
GenericJackson2JsonRedisSerializer jackson2JsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
// 设置key用string序列化方式
redisTemplate.setKeySerializer(new StringRedisSerializer());
// 设置value用jackjson进行处理
redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);
// hash也要进行修改
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);
// 默认调用
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}
@Service
public class CourseService {
// 1: 使用 springboot自带的redis
@Autowired
private RedisTemplate redisTemplate;
/**
* 查询课程需要放入缓存中
*
* @param courseId
*/
public Course getCourse(Long courseId) {
String key = "redis:course:" + courseId;
// 根据课程key = redis:course:1去缓存中查询,是否存在,
Course course = (Course) redisTemplate.opsForValue().get(key);
System.out.println("course = " + course);
// 如果缓存是否为空
if (course == null) {
// 获取数据库DB的数据
course = getCourseDb(courseId);
// 如果数据库也没有查询到
if (course == null) {
course = new Course();
// 这里为什么要设置时间? 因为redis无关不设置时间,就是永久的?
// 这种数据一般设置一个时间,然后过期到,腾出内存空间。这个时间具体写多久。你可以考虑建议写大一点。
redisTemplate.opsForValue().set(key, course, 600, TimeUnit.SECONDS);
} else {
// 数据库的数据开始写入到缓存中
redisTemplate.opsForValue().set(key, course);
}
}
return course;
}
/**
* 伪造数据库的记录
*
* @param courseId
* @return
*/
public Course getCourseDb(Long courseId) {
Map<Long, Course> map = new HashMap<>();
map.put(1L, new Course(1L, "GO系列", new BigDecimal(2999)));
map.put(2L, new Course(2L, "Java系列", new BigDecimal(1999)));
return map.get(courseId);
}
}
布隆过滤器解决数据穿透问题:
前置准备:redis数据库对布隆过滤器服务进行了配置绑定:参考文章https://blog.csdn.net/qq_58326706/article/details/135662671、布隆过滤器依赖、布隆过滤器所在的Redis服务器yml配置、布隆过滤器配置类
<!--布隆过滤器-->
<dependency>
<groupId>com.redislabs</groupId>
<artifactId>jrebloom</artifactId>
<version>2.1.0</version>
</dependency>
<!--jedis客户端(可对布隆过滤器操作)-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.4.1</version>
</dependency>
<!--redisson客户端(可对布隆过滤器操作)-->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.17.6</version>
</dependency>
# 远程redis的布隆过滤器配置
redis:
bloom:
host: 192.XXX.XXX.200
port: 6379
# 布隆过滤器中存放的数据(容量capacity)
capacity: 100
password: redis密码
# 布隆过滤器的误差比例(100个出一次差错1%==0.01)
rate: 0.01
# 布隆过滤器存在Redis数据库的那个库中
db: 7
/**
* Redis的布隆过滤器配置类
*/
@Configuration
@Slf4j
public class BloomFilterConfiguration {
// 布隆过滤器服务关联的Redis的host地址
@Value("${redis.bloom.host}")
private String host;
// 布隆过滤器服务关联的Redis的password
@Value("${redis.bloom.password}")
private String password;
// 布隆过滤器服务关联的Redis的端口
@Value("${redis.bloom.port}")
private Integer port;
// 布隆过滤器存放在关联的Redis的那个库
@Value("${redis.bloom.db}")
private int db;
// 布隆过滤器的(容量capacity)
@Value("${redis.bloom.capacity}")
private Integer capacity;
// 布隆过滤器的错误率
@Value("${redis.bloom.rate}")
private Double rate;
/**
* JedisPool连接池
*/
@Bean
public JedisPool jedisPool() {
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxIdle(8);
poolConfig.setMaxTotal(8);
poolConfig.setMaxWaitMillis(10L);
JedisPool jp = new JedisPool(poolConfig, host, port,
10 * 1000, password, db);
return jp;
}
/**
* 布隆过滤器的Client的初始化:设置布隆过滤器的key名称(可设置多个布隆过滤器的key)
*
* @param pool JedisPool连接池
* @return
*/
@Bean
public Client rebloomClient(JedisPool pool) {
Client client = new Client(pool);
try {
// 布隆过滤器1:课程过滤 底层代码(bf.reserve redis:bloom:courses 100 0.01 )
client.createFilter("redis:bloom:course:list", capacity, rate);
// 布隆过滤器2:黑白名单 bf.reserve redis:bloom:userblack:list 0.01 100
client.createFilter("redis:bloom:userblack:list", capacity, rate);
// 布隆过滤器3:手机号码过滤 bf.reserve redis:bloom:urls 0.01 100
client.createFilter("redis:bloom:phone:list", capacity, rate);
} catch (Exception ex) {
log.info("bloom过滤器已经存在,异常信息是:{}", ex.getMessage());
}
return client;
}
}
@Service
public class CourseService {
// 1: 使用 springboot自带的redis
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private Client bloomFilter;// bloomFilter客户端
// 布隆过滤器key
public static String courseBloomKey = "redis:bloom:course:list";
public static String courseRedisKey = "redis:course:"; // 提前添加数据
/**
* 布隆过滤器解决缓存穿透问题:查询课程需要放入缓存中
*
* @param courseId 课程id
*/
public Course getCourse2(Long courseId) {
// 1、判断布隆过滤器中是否存在
boolean exists = bloomFilter.exists(courseBloomKey, String.valueOf(courseId));
Course course = null;// 定义null对象
// 2、布隆过滤器中存在,在去Redis缓存中查找
if (exists) {
course = (Course) redisTemplate.opsForValue().get(courseRedisKey + courseId);
// 3、如果Redis缓存中也为null,直接返回空对象
if (course == null) {
course = new Course();
}
// 3、!防止布隆过滤器误删
} else {
if (course == null) {
course = getCourseDb(courseId);
// 数据库也没有查到
if (course == null) {
course = new Course();
// 设置Redis空缓存
redisTemplate.opsForValue().set(courseRedisKey + courseId, course, 600, TimeUnit.SECONDS);
} else {
// 数据库的数据开始写入到缓存中
redisTemplate.opsForValue().set(courseRedisKey + courseId, course);
}
}
}
return course;
}
/**
* 伪造数据库的记录
*
* @param courseId
* @return
*/
public Course getCourseDb(Long courseId) {
Map<Long, Course> map = new HashMap<>();
map.put(1L, new Course(1L, "GO系列", new BigDecimal(2999)));
map.put(2L, new Course(2L, "Java系列", new BigDecimal(1999)));
return map.get(courseId);
}
}
缓存预热实现:
缓存预热/数据预热的原理:监听Spring容器启动前做缓存预热(提前将热点数据放入redis缓存中),
实现方式:
@PostConstruct注解(适用于Spring、SpringBoot项目): 使用 @PostConstruct 注解标记一个方法,该方法将在对象被构造后自动调用,
参数和返回值: @PostConstruct 方法没有参数,并且不能有返回值。它通常被设计为执行一些初始化任务,而不关心调用者传递的参数,
异常处理: 如果 @PostConstruct 方法抛出异常,对象的初始化将被终止,并且该异常将被抛出给调用者。
@Slf4j
@Component// 加入Spring容器管理
public class TestPostConstruct{
@Autowired
private ShopService shopService;
// 模拟预热的数据
private static String hot_Data;
/**
* @PostConstruct注解的方法在Spring容器启动前执行,在依赖注入后执行
*/
@PostConstruct
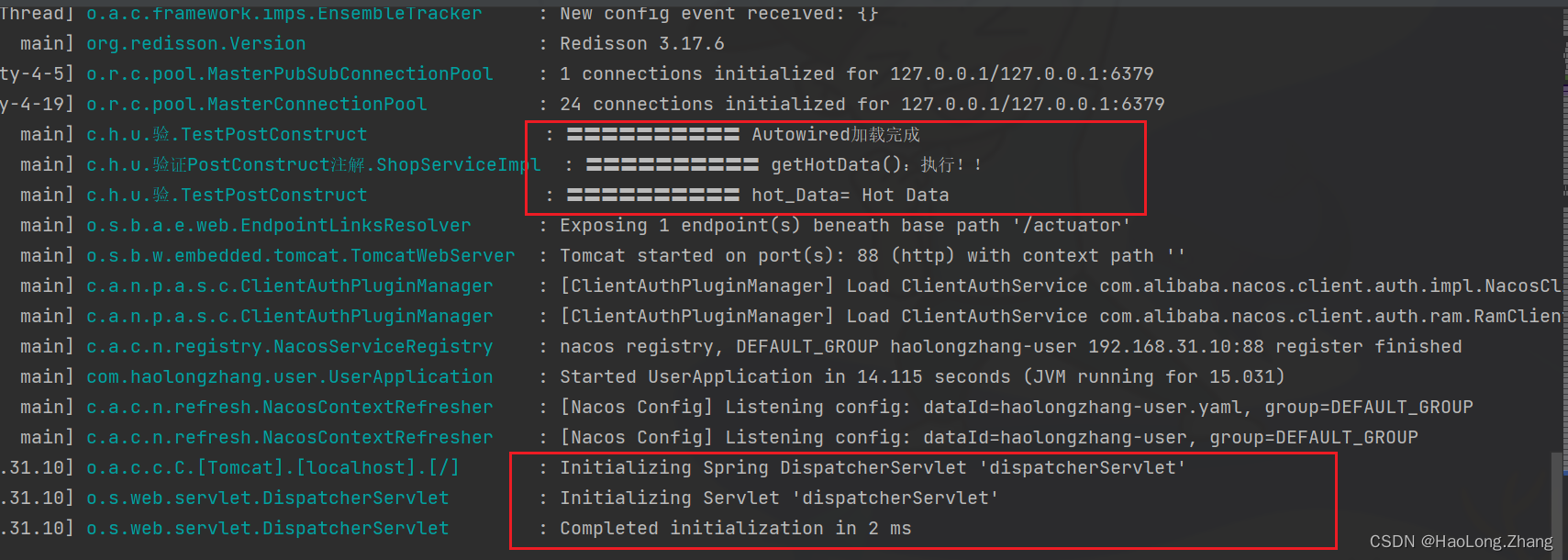
public void construct(){
log.info("〓〓〓〓〓〓〓〓〓〓 Autowired加载完成");
hot_Data= ShopService.demo5();
log.info("〓〓〓〓〓〓〓〓〓〓 hot_Data= " + hot_Data);
}
}
@Slf4j
@Service
public class ShopServiceImpl implements ShopService {
/**
* 模拟从数据库查询数据的操作
*/
public String getHotData() {
log.info("〓〓〓〓〓〓〓〓〓〓 getHotData():执行!!");
return "Hot Data";
}
}
- 类实现
InitializingBean接口(没有返回值,适用于Spring、SpringBoot项目),
@Slf4j
@Service
public class TestInitializingBean implements InitializingBean {
@Override
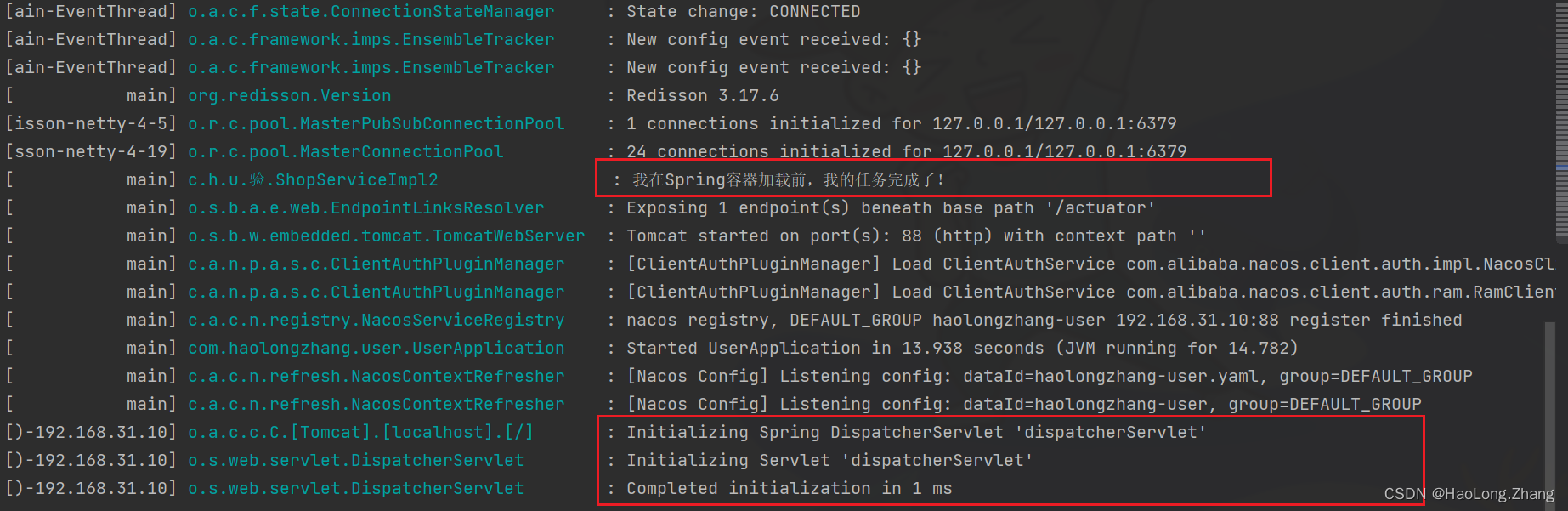
public void afterPropertiesSet() throws Exception {
log.info("我在Spring容器加载前,我的任务完成了!");
}
}
- 类实现
CommandLineRunner接口(没有返回值,适用于SpringBoot项目), - 类实现
ApplicationRunner接口(没有返回值,适用于SpringBoot项目), - 类实现
ApplicationListener接口(没有返回值,适用于Spring、SpringBoot项目),
什么所有方式的执行顺序:构造函数>initmethod>InitializingBean >@PostConstruct>ApplicationListener>CommandLineRunner/ApplicationRunner
原文地址:https://blog.csdn.net/qq_58326706/article/details/135658923
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!