神经网络算法原理
目录
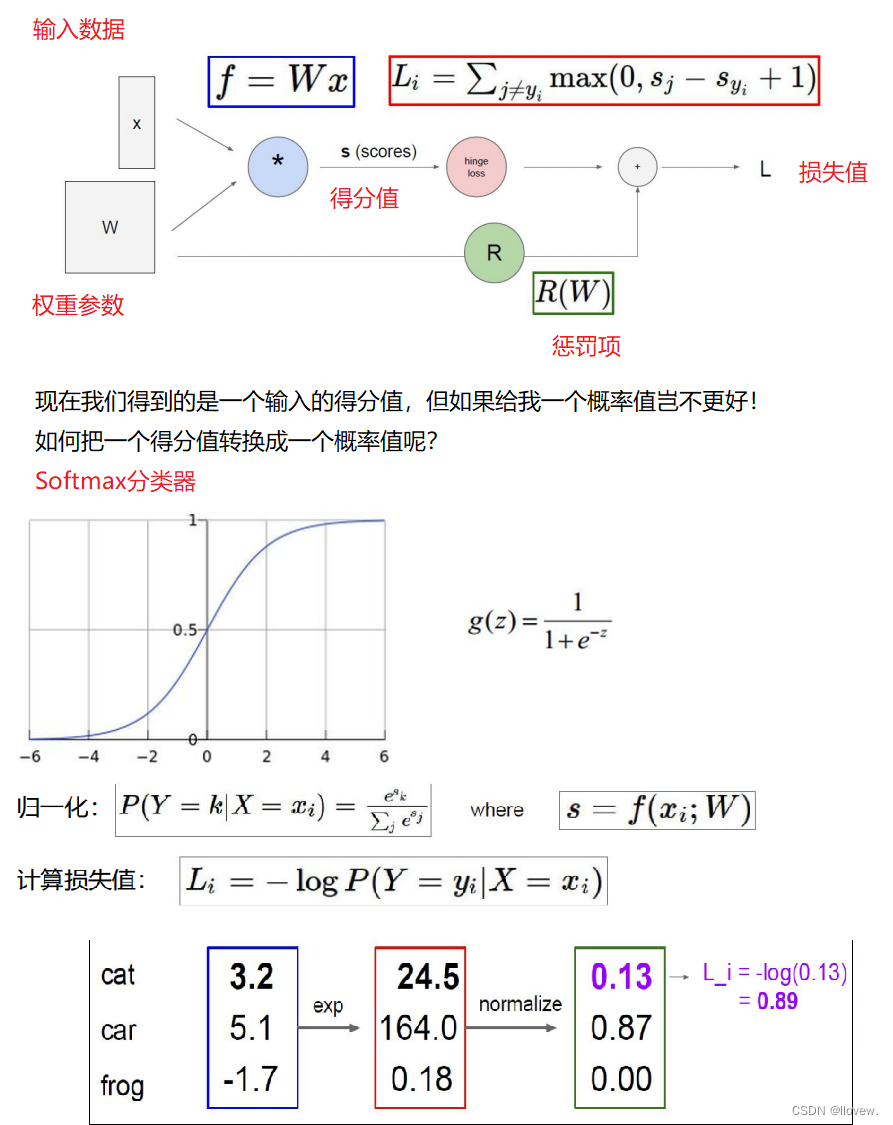
得分函数
得分函数是在机器学习和自然语言处理中常用的一种函数,用于评估模型对输入数据的预测结果的准确性或匹配程度。得分函数通常根据模型的预测结果与真实标签或期望输出之间的差异来计算得分。
数学表示
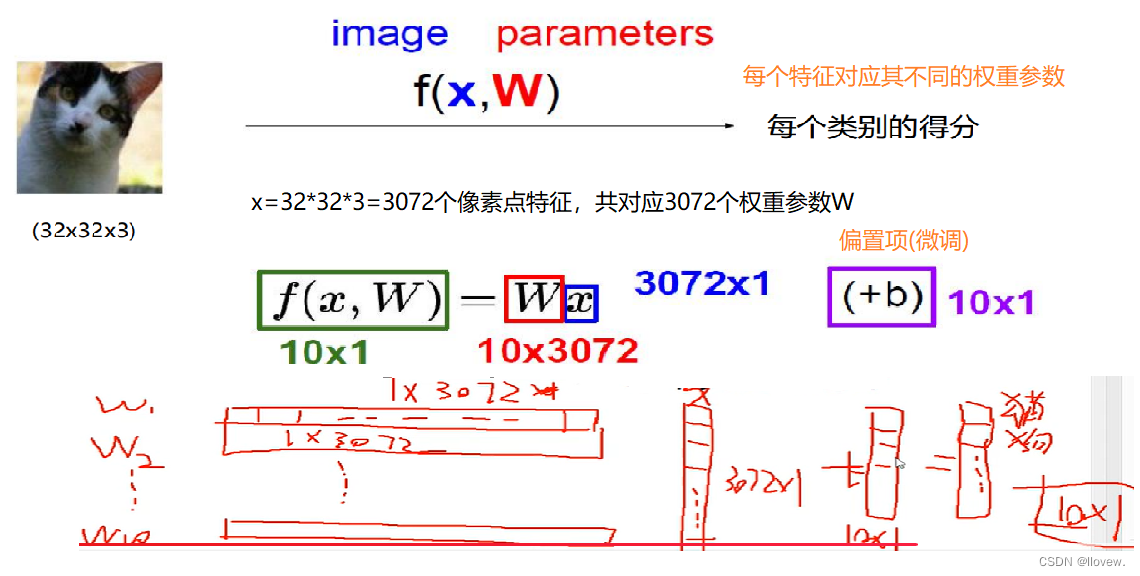
计算方法
输入数据 x 是不变的,通过不断优化改变权重矩阵 W。在神经网络的整个生命周期中只在做一个事情,什么样的W可以更适合于我们的数据做当前的任务我们就相应的去改变W。
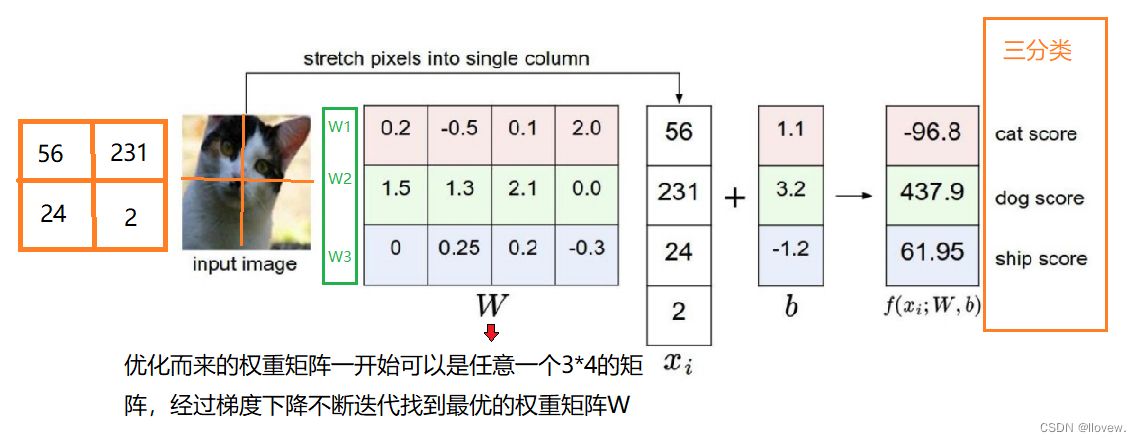
损失函数
损失函数(Loss Function)是机器学习中的一个重概念,用于衡量模型预测结果与真实值之间的差异程度。它是优化算法的核心,最小化损失函数来调整模型的参数,使得模型能够更好地拟合训练数据。
常见的损失函数有以下几种:
1. 均方误差(Mean Squared Error,MSE):计算预测值与真实值之间的平方差的平均值。适用于回归问题。
2. 交叉熵损失(Cross Entropy Loss):用于分类问题,特别是二分类和多分类问题。常见的交叉熵损失函数包括二分类交叉熵损失(Binary Cross Entropy Loss)和多分类交叉熵损失(Categorical Cross Entropy Loss)。
3. 对数损失(Log Loss):常用于逻辑回归问题,衡量模型对样本分类的准确性。
4. Hinge损失:常用于支持向量机(SVM)中,用于最大间隔分类。
5. KL散度(Kullback-Leibler Divergence):用于衡量两个概率分布之间的差异。
6. Huber损失:结合了均方误差和绝对误差,对异常值具有一定的鲁棒性。

 前向传播
前向传播
前向传播是神经网络中的一种计算过程,用于将输入数据通过网络的各个层进行计算,最终得到输出结果。在前向传播过程中,数据从输入层开始,逐层经过各个隐藏层的计算,最终到达输出层。
具体来说,前向传播的计算过程如下:
1. 将输入数据传递给输入层,作为网络的输入。
2. 输入数据经过输入层的权重和偏置的线性变换,得到隐藏层的输入。
3. 隐藏层对输入进行非线性变换,通常使用激活函数(如ReLU、Sigmoid等)来引入非线性特性。
4. 隐藏层的输出再次经过权重和偏置的线性变换,得到下一层隐藏层的输入。
5. 重复步骤3和步骤4,直到数据通过所有隐藏层的计算。
6. 最后一层隐藏层的输出再次经过权重和偏置的线性变换,得到输出层的输入。
7. 输出层对输入进行非线性变换,得到最终的输出结果。
通过前向传播,神经网络可以将输入数据映射到输出空间中,实现对输入数据的预测或分类等任务。
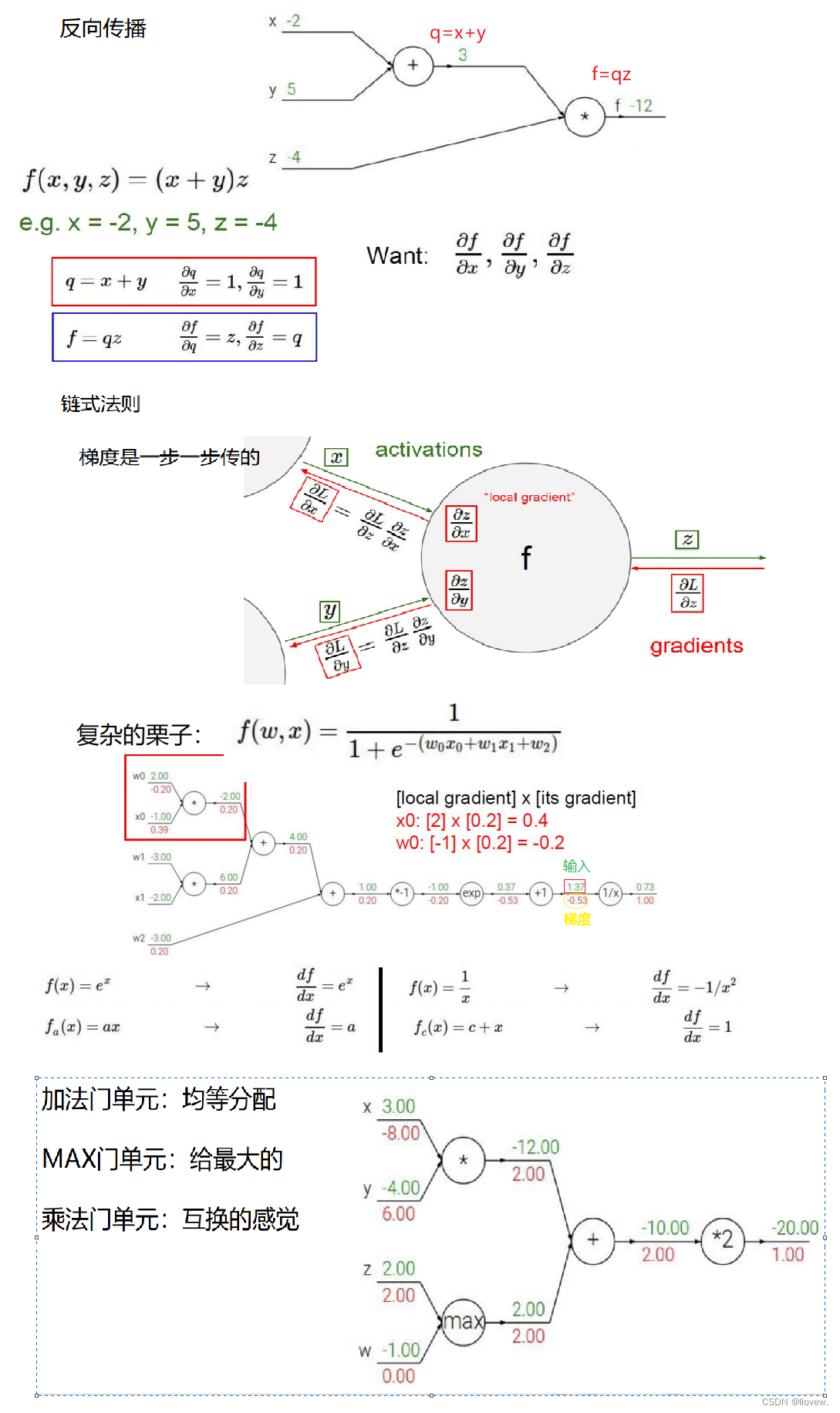
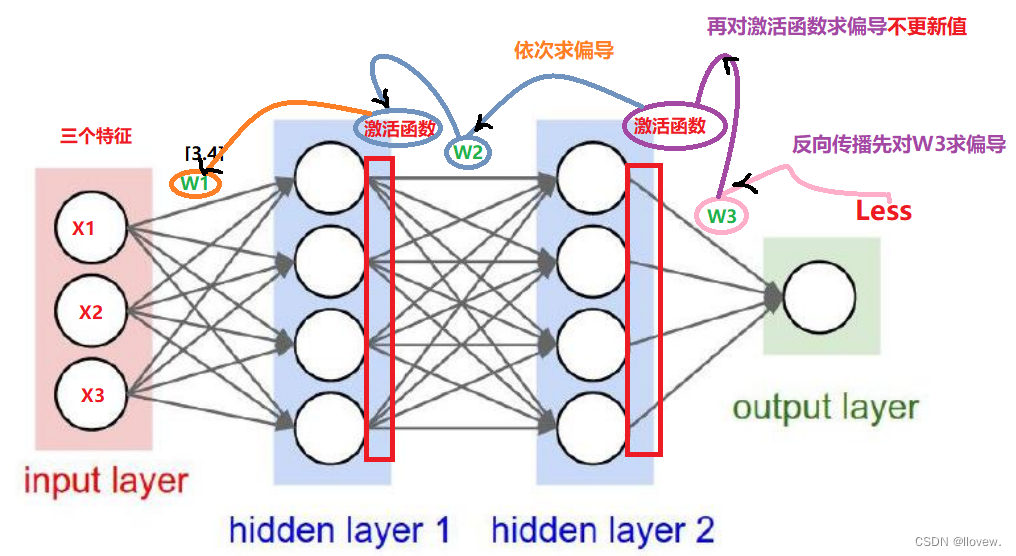
反向传播
反向传播(Backpropagation)是一种用于训练神经网络的算法。它通过计算损失函数对网络中每个参数的梯度,然后利用梯度下降法来更新参数,从而使得网络能够逐步优化并适应输入数据。
具体来说,反向传播算法可以分为以下几个步骤:
1. 前向传播:将输入数据通过神经网络的各层进行计算,得到输出结果。
2. 计算损失:将网络的输出结果与真实标签进行比较,计算出网络的损失值。
3. 反向传播:从输出层开始,根据链式法则计算每个参数对损失函数的梯度。这个过程从输出层向输入层逐层进行,将梯度信息传递回网络中的每个参数。
4. 参数更新:根据计算得到的梯度信息,使用梯度下降法或其他优化算法来更新网络中的参数,使得损失函数逐渐减小。
反向传播算法的关键在于链式法则的应用,它允许我们通过将梯度从输出层向输入层传递,有效地计算出每个参数对损失函数的贡献程度。这样,我们就可以根据梯度信息来调整参数,使得网络能够更好地拟合输入数据。
整体架构
神经网络是一种模拟人脑神经系统的计算模型,它由多个神经元组成,通过神经元之间的连接和权重来进行信息传递和处理。整体上神经网络可以分为输入层、隐藏层和输出层。
- 输入层:接收外部输入的数据,将其转化为神经网络可以处理的形式。每个输入节点对应输入数据的一个特征。
- 隐藏层:位于输入层和输出层之间的一层或多层神经元组成的层。隐藏层的神经元通过权重和激活函数对输入信号进行加权求和和非线性变换,然后将结果传递给下一层。
- 输出层:输出神经网络对输入数据的预测或分类结果。输出层的神经元通常使用不同的激活函数,如sigmoid函数、softmax函数等。
每个神经元都有一个激活函数,用于将输入信号进行非线变换。常用的激活函数包括sigmoid函数、ReLU函数、tanh函数等。
神经网络的训练过程通常使用反向传播算法(Backpropagation)来更新权重,使得网络能够逐渐优化并减小预测误差。反向传播算法通过计算预测值与真实值之间的误差,并根据误差来调整网络中每个连接的权重。
神经网络的架构可以根据任务的不同而有所变化,例如卷积神经网络(Convolutional Neural Network,CNN)用于图像处理,循环神经网络(Recurrent Neural Network,RNN)用于序列数据处理等。
正则化的作用
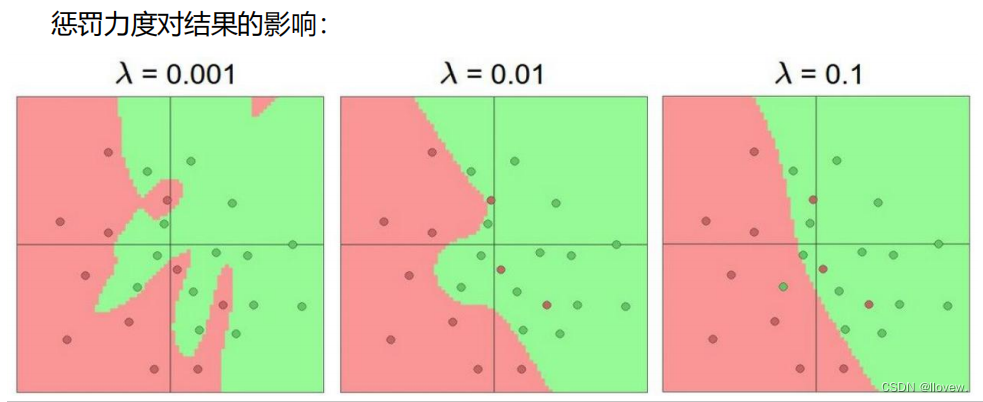
正则化是一种常用的机器学习技术,用于防止模型过拟合。过拟合指的是模型在训练数据上表现良好,但在新数据上表现较差的情况。正则化通过在损失函数中引入一个正则化项,来限制模型的复杂度,从而提高模型的泛化能力。
正则化的作用主要有以下几个方面:
1. 控制模型复杂度:正则化通过对模型参数进行约束,限制了模型的复杂度。这样可以避免模型过于拟合训练数据,提高模型在新数据上的表现。
2. 减少过拟合:正则化通过对模型参数进行惩罚,使得模型更倾向于选择较小的参数值。这样可以减少模型对训练数据中噪声的敏感性,从而降低过拟合的风险。
3. 特征选择:正则化可以通过对模型参数进行约束,使得某些参数趋向于零。这样可以起到特征选择的作用,即自动选择对目标变量有较大影响的特征,去除对目标变量影响较小的特征。
4. 改善模型解释性:正则化可以使得模型更加简洁,去除了一些不重要的参数。这样可以提高模型的解释性,使得模型更易于理解和解释。
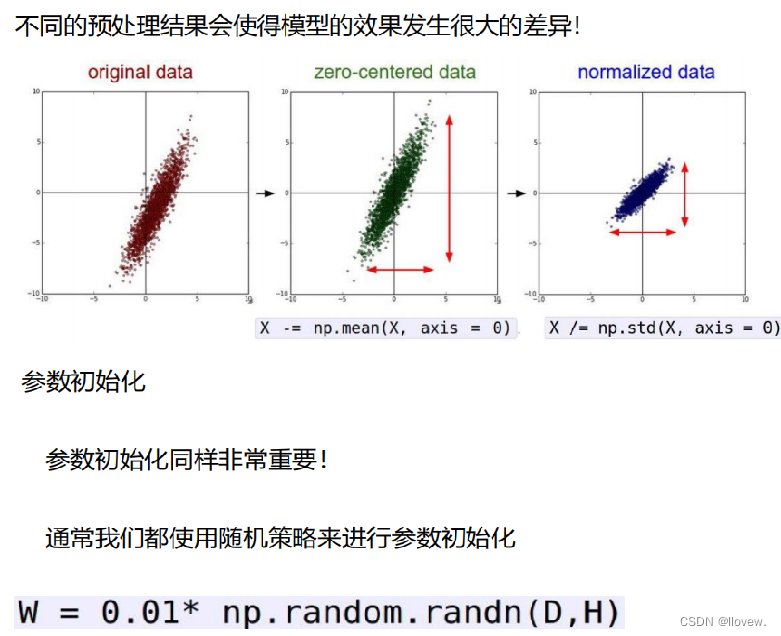
数据预处理
 过拟合解决方法
过拟合解决方法
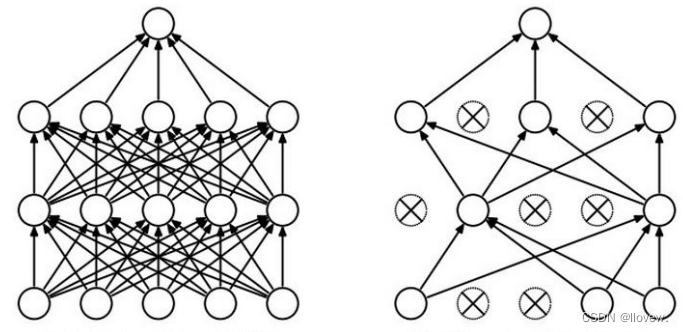
Dropout是一种常用的正则化技术,用于减少神经网络的过拟合问题。在训练过程中,Dropout会随机地将一部分神经元的输出置为0,这样可以强制网络去学习更加鲁棒的特征表示。具体来说,Dropout会以一定的概率p将某个神经元的输出置为0,而保留其他神经元的输出。这样做的好处是,每次训练时都会随机地“丢弃”一些神经元,使得网络不能过度依赖某些特定的神经元,从而提高了网络的泛化能力。
通过使用Dropout,可以有效地减少神经网络的过拟合问题,提高模型的泛化能力。此外,Dropout还可以起到集成多个不同的子网络的作用,因为每次训练时都会随机地“丢弃”一些神经元,相当于训练了多个不同的子网络,最终将它们集成起来可以得到更好的性能。
总结一下,Dropout的主要作用是:
1. 减少过拟合问题。
2. 提高模型的泛化能力。
3. 实现模型集成。
原文地址:https://blog.csdn.net/m0_61517307/article/details/136138377
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!