深度学习引言
深度学习引言
-
假定想要根据房屋面积拟合一个预测房价的函数,我们令房屋面积作为神经网络的输入 x x x,通过一个神经元进行预测,最终输出价格 y y y。这就是最简单的单神经网络(感知机),神经元对输入进行加权求和,加上偏置,然后通过一个激活函数得到输出。
y = f ( w x + b ) y=f(wx+b) y=f(wx+b)
为了捕捉更复杂的非线性关系,可以构建深度神经网络,它由多个层次的神经元组成。每一层对前一层的输出进行非线性变换,使得整个网络能够学习数据的高阶特征。深度神经网络通过堆叠简单的神经元,并利用非线性激活函数,可以用于解决各种复杂的预测和分类问题。
-
神经网络的强大之处在于,只需要提供输入和输出的数据,网络通过训练可以自动学习输入与输出之间的复杂非线性关系,而无需人为地设计特征提取的规则。神经网络的结构通常由输入层、一个或多个隐藏层以及输出层组成。输入层接收原始数据,隐藏层通过一系列的加权求和和非线性激活函数来提取特征,输出层生成最终的预测结果。通过调整网络的结构和训练参数,神经网络能够在各种任务中取得优异的性能。
-
每个神经元本质上都是函数,可以是线性函数也可以是非线性函数。ReLU(Rectified Linear Unit,修正线性单元)是一种线性激活函数。
ReLU ( x ) = m a x ( 0 , x ) \text{ReLU}(x)=max(0,x) ReLU(x)=max(0,x)
这意味着当输入 x x x为正时,输出为 x x x,当输入为0或负数时,输出为0。ReLU函数形式简单,计算速度快。还可以缓解梯度消失问题,ReLU在正区间梯度为1,能有效缓解深层神经网络中的梯度消失现象。ReLU会将部分神经元的输出置为零,从而引入稀疏性,有助于防止过拟合并提高模型的泛化能力。
但是在训练过程中,如果某些神经元的参数更新导致其再也无法激活(输出始终为零),这些神经元将对模型无贡献。这可能是由于学习率过大或偏置初始化不当引起的。为了解决这个问题,引入Leaky ReLU,使得函数在负数区域也有非零输出。
Leaky ReLU ( x ) = { x , if x > 0 α x , if x ≤ 0 \text{Leaky ReLU}(x) = \begin{cases} x, & \text{if } x > 0 \\ \alpha x, & \text{if } x \leq 0 \end{cases} Leaky ReLU(x)={x,αx,if x>0if x≤0
-
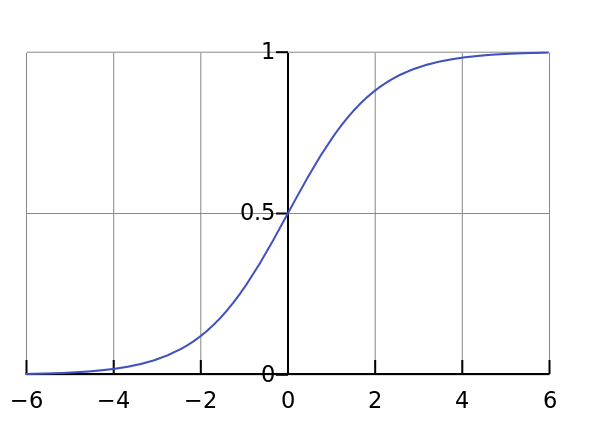
Sigmoid激活函数是一种常用的非线性激活函数。它能够将输入映射到0到1之间的输出,有助于神经网络学习复杂的非线性关系。
Sigmod函数输出范围在 [ 0 , 1 ] [0,1] [0,1]之间,非常适合用于概率预测和二分类问题。函数在整个输入范围内都是平滑且可微的,有利于反向传播算法计算梯度。但是也存在一些问题,例如梯度消失问题,当输入值过大或过小时,导数会变得非常小,导致梯度更新缓慢,影响深层网络的训练效率。以及非零中心化输出问题,输出值始终为正数,可能导致后续层的神经元输入出现偏移,影响训练效果。
S i g m o d ( x ) = 1 1 + e − x Sigmod(x)=\frac{1}{1+e^{-x}} Sigmod(x)=1+e−x1
-
监督学习是机器学习的主要类别之一,主要任务是学习输入 x x x和输出 y y y之间的映射函数。一般来说,我们使用深度神经网络进行房价预测、广告点击预测等,使用卷积神经网络(Convolutional Neural Network, CNN)进行图像分割、物体识别等,使用卷积神经网络(Recurrent Neural Network, RNN)处理序列数据,如机器翻译、语音识别等。
-
结构化数据是指以预定义格式组织的、可以存储在关系型数据库中的数据,具有明确的字段和数据类型。非结构化数据则包括音频、图像、文本、视频等没有固定数据模型的数据,需要特定的方法进行处理。在非结构化数据中,图像的像素值、文本的单词等都可以视为特征。人类凭借自身的感知和认知能力,能够轻松理解这些非结构化数据的内容,但计算机要理解这些数据则较为困难。深度学习通过构建多层神经网络,能够自动从非结构化数据中学习特征表示,帮助计算机更好地理解和处理这些数据。
-
假设我们绘制一张图,水平轴代表任务的数据量,垂直轴代表机器学习算法的性能,代表着不同机器学习算法随着数据量增大的性能提升表现。
对于传统的机器学习算法,性能最初会随着数据量的增加而提升,但由于模型容量的限制和对手动特征工程的依赖,性能在达到一定程度后会趋于平稳,难以进一步提升。(传统机器学习算法需要精心设计的特征来提升性能,当数据量增大且特征复杂时,手动特征工程变得困难。)
相比之下,神经网络,尤其是深度神经网络,展示了随着数据量的增加和模型规模的扩大,性能可以持续提升的趋势。如果我们训练一个小型的神经网络,性能会有所提高;训练一个中等规模的神经网络,性能会进一步提升;而当我们训练一个大型神经网络时,随着数据量的增多,性能可能会持续显著提高。
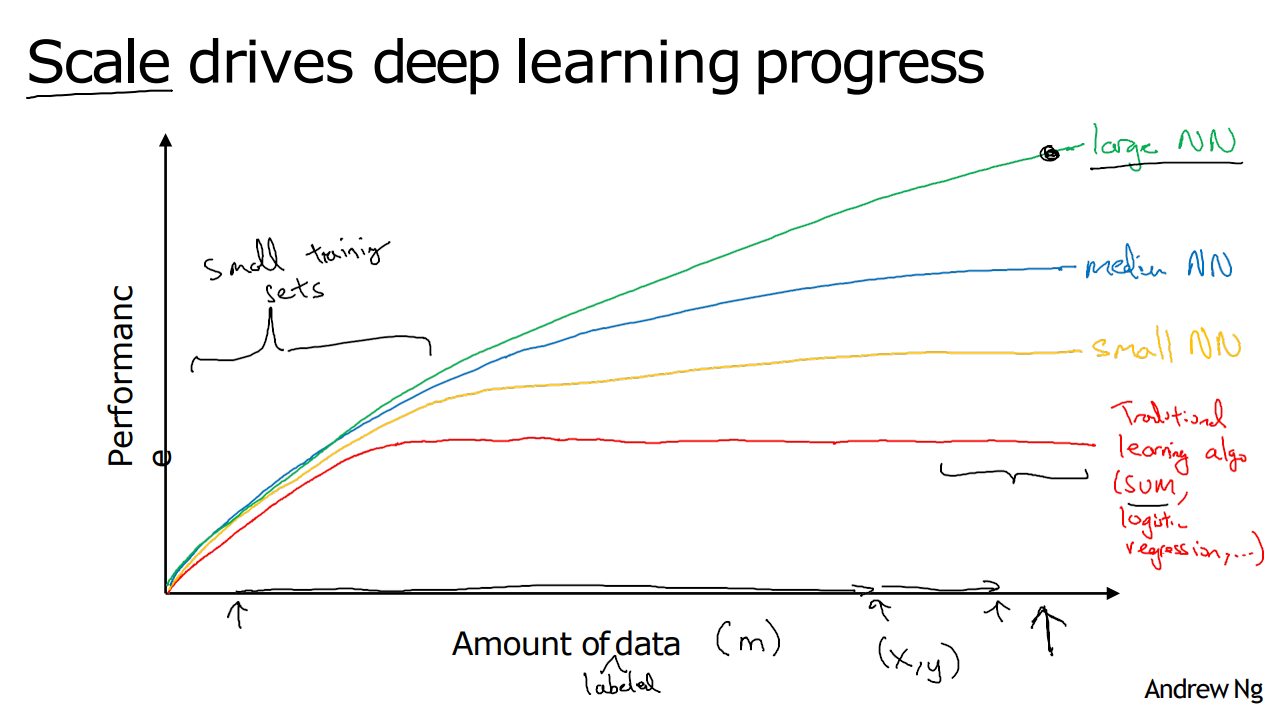
因此,要想获得更高的性能,首先需要训练一个规模足够大的神经网络,以充分利用大量数据的优势;其次,需要大量的标记训练数据来支持模型的训练,规模推动深度学习的进步。
-
我们用 m m m表示训练集的规模。当训练集规模较小的时候,模型能从数据中学习到的信息有限,这时特征工程的能力以及算法的精细调整决定了模型的最终性能。优秀的特征工程可以帮助模型在小数据集上取得更好的效果。当训练集规模庞大时,神经网络尤其是深度神经网络能够持续展现其优势,因为它们可以从大量数据中自动学习复杂的特征和模式,性能会随着数据量的增加而不断提升。
-
经验丰富的深度学习工程师在处理新问题时,通常可以利用对以往问题的洞察力,在第一次尝试时就训练出一个良好的模型,而无需多次迭代不同的模型。这个说法是错误的,因为找到模型的特点是获得良好性能的关键。虽然经验会有所帮助,但要建立一个好的模型需要多次反复试验。
-
GPU/CPU硬件的改进有助于发现更好的深度学习算法。通过加快迭代过程,更好的硬件可以让研究人员发现更好的算法。而更好的算法可以减少必要的计算时间,从而加快迭代过程。ReLU激活函数的引入可以帮助缩短训练模型所需的时间的。
原文地址:https://blog.csdn.net/m0_60541499/article/details/143569688
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!