Meta的哈士奇架构能取代GPT等级的模型吗?
在没有大模型LLM的时代,实际上也不是NLP,只不过负责的任务会分成有多个NLP模型(还得加上其他模型,包括写死的策略引擎)来解决。
自从LLM出了以后,尤其是scaling law推出了以后,伴随着大模型的涌现能力和COT能力越来越强,其实NLPer们挺难受的,一方面这些做算法的人大都是穷哥们
(事实勿喷),手里没有什么卡,所以以前解决问题的方向,往往是开发模型架构和算法,借此来获得百分之几的正收益,scaling law了以后,他们的就很难受了,往往辛苦一年吭哧瘪肚的憋出来的算法在某些任务的效果上提升了百分之几,但OpenAI这种公司,上了几万卡瞬间提升百分之几十。
前朝老臣们并没有死心,还是想期待用小模型来解决问题,他们的说辞也很简单,大模型并不适合一切场景,这才有了LLama7b, phy3 这些东西,一方面对普通用户确实友好,另一方面,我们也应该看到,小模型大多优化的方向是数据质量(也有COT迁移的,这个我们以后讲,就是所谓的STAR*,或者类似的方案,但是这玩意现在能做成的世界上不超过3家)
光靠洗数据是永远让Phi3达到大模型的高度的,核心的问题就是他们往往有知识,没推理,模型的推理能力和你灌进去的数据的相关性,不如和神经元数量相关性更高(别犟)
小模型也想上生产啊,尤其是一些serious的场景,和无法使用效果特别好的互联网模型访问的场景。
Meta就想了一个解决方案(我个人认为不算算法创新就是解决方案)哈士奇,Husky
论文地址:2406.06469 (http://arxiv.org)
它的主要思想和逻辑就是用多个在专业领域表现比较好的小模型来完成复杂任务的合力解决。
其实很好理解,如果一个模型的神经元数量或者网络深度,无法在通用智能上有很好的表现,可以训练它(主要是特定数据和指令微调)在某些特定领域做到相对好的COT和复杂任务推理性能,比较常见的如codellama(虽然表现也不能称得上top级别,但是比普通的通用小模型还是好狠多)

就像哈士奇拉雪橇一样,一个哈士奇力量不行,一堆拉共同完成任务,这个逻辑就跟最早的NLP,或者其他的多小模型实现的一些企业任务就很类似了,只不过这个面向的是通用,或者绝大多数通用人工智能的场景(不咬文嚼字,这里肯定谈不上AGI,就是解决的问题是通用问题,不是特定领域)。
比如目前官方就特别调制了几个模型
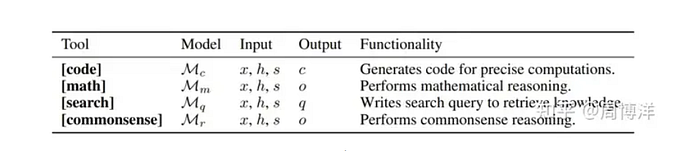
- 表1
- action是A是解决任务分解和Tool选择的
- query是搜索
- deepseekmath是解决数学问题
- deepseekcode是代码问题(看来Meta对deepseek的东西还挺认可)
表1
表1这里面被冠以4种toolModel的代号,Mc到Mr。只有Mr也就是action它不是经过特定领域数据微调的。
而调度这些模型的解决方案(其实是模型化的Agent)就是Husky,Husky不同于以往的Agent方案,可以理解为一个Agent+一个任务分解和分类模型来实现的。
在Husky的物理实现中,实际只有四个模型组件。这四个模型中包括动作生成器 (Action Generator,
A),代码生成器 (Code Generator, Mc),数学推理器 (Math Reasoner, Mm) 和查询生成器 (Query Generator,
Mq)。常识推理器 (Mr) 实际上没有被单独作为一个物理模型存在,而是被融合在动作生成器中,通过现有模型的能力来处理常识推理任务。
具体模型组件解析
1. 动作生成器 (Action Generator, A)
- 功能:预测任务的每一步操作和所需工具。
- 实现:使用LLAMA-2–7B、LLAMA-2–13B进行训练。
- 物理模型:这是实际存在的模型之一,用于生成下一步的操作和选择适当的工具。
2. 代码生成器 (Code Generator,Mc)
- 功能:生成精确计算所需的代码。
- 实现:使用DEEPSEEKCODER-7B-INSTRUCT-v1.5进行微调。
- 物理模型:这是实际存在的模型之一,用于代码生成任务。
3. 数学推理器 (Math Reasoner, Mm)
- 功能:执行数学推理任务。
- 实现:使用DEEPSEEKMATH-7B-INSTRUCT进行微调。
- 物理模型:这是实际存在的模型之一,用于数学推理任务。
4. 查询生成器 (Query Generator, Mq)
- 功能:生成搜索查询以检索知识。
- 实现:使用LLAMA-2–7B进行微调。
- 物理模型:这是实际存在的模型之一,用于生成查询任务。
5.关于常识推理器 (Mr)
Mr 并没有被单独作为一个物理模型存在,而是A就把解析出来的任务T如果是Mr就自己上了。
Husky的训练过程2个阶段:
阶段1

- 使用教师语言模型(Teacher LM怀疑是GPT4,论文没讲)合成工具集成的解决方案轨迹。
- 从这些工具集成解决方案中提取用于每个模块的训练提示。
- 为啥用TeacherLM,因为目前没有现成的训练数据可以用于执行下一步预测和工具调用(如代码、数学或搜索查询生成),那用GPT4啥的合成数据肯定用起来还相对准确的。
- 数据如何合成的?
- 解决方案轨迹格式为一系列步骤 si(i∈[1,…]),每一步分配一个工具
t_iti,并输出每一步的结果oi。s代表step,t是tool,o是output - 每个解决方案从高层次步骤开始,如“Step i:si”。
工具 ti 从表1中选择,包括[code][code]、[math][math]、[search][search]、[commonsense] - 对于 [code] 和[search][search],工具调用会伴随生成的代码片段ci 或搜索查询qi,并通过代码解释器或搜索引擎执行,输出结果会被教师模型(Teacher LM)重写为自然语言。
- 对于数学或常识推理,其输出直接由对应的LM模型生成。
fewshot加持:
- 使用少量提示(few-shot prompt)来生成所有训练任务集中的工具集成解决方案轨迹。
- 生成轨迹后,评估最终答案是否与训练集中的标签一致,并保留正确答案的解决方案实例。
阶段2
使用工具集成解决方案轨迹作为蓝图,为Husky中所有需要训练的模块构建训练数据。
Action Generator:
- 动作生成器 A 在步骤 i 的输入包括任务指令 x(用户的输入) 和解决方案历史 hi-1的拼接(因为是多步问答,所有得有context)。
- 输入格式为 “{x}{h_{i-1}}” = “{x}[s1][o1]…[si-1][oi-1]}”。
- A生成输出 [Ti]si,例如
x=”FindthebirthdayofthefirstpresidentoftheUnitedStates”那么可能的输出”[search]IdentifythefirstpresidentoftheUnitedStates”。
- 通过正则表达式匹配从解决方案轨迹中提取步骤及其输出,并按上述格式组织以训练 A。
Expert Models:
- A搞定了以后,就得精调专家模型了,相当于任务派发每个专家模型的输入包括任务指令 x,解决方案历史 hi−1 及当前步骤s_isi。
- 给定此输入,
Mc 返回代码片段 ci,Mm 返回数学解决方案 mi,以此类推。 - 从解决方案轨迹中提取步骤和工具特定的输出,并按格式构建专家模型的训练数据(都是GPT4给的)。
独立微调:
- 这就没啥可解释的了,独立微调所有Husky模块,使用标准的下一个token预测目标。
Eval:
训练完了之后要eval,这块因为也不是预训练,是微调,所以标准评估数据集也没用,方案还是老样子,让GPT-4去评估,包括生成评估数据集和直接评估。
Inference:
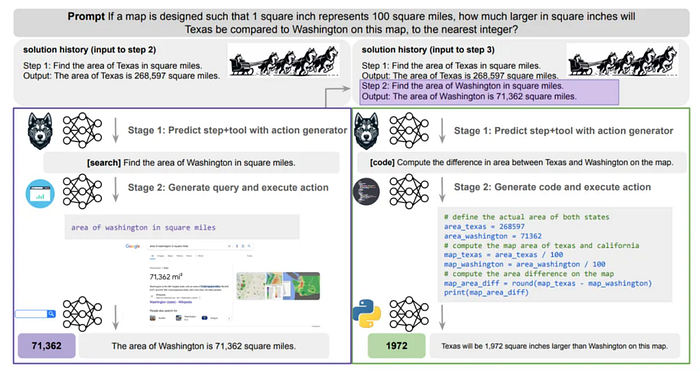
推理就是是各个模型联动的体现了,如这个图展示了Husky在处理一个复杂的多步骤推理任务时的具体推理过程。任务的提示是:“如果一张地图的设计是每1平方英寸代表100平方英里,那么德州比华盛顿大多少平方英寸,取最近的整数?”
咱说一般模型(2类,3类水准)基本问到这就废了
Husky是怎么做的呢?
Husky推理过程解析
Stage 1: Predict step+tool with action generator
输入提示:给定提示和解决方案历史的输入,当前任务是找到德州和华盛顿的面积。
通过动作生成器预测下一步操作和所需工具。
动作生成器 (A) 预测步骤 [search][search] 并找到华盛顿的面积。
选择的工具是 [search]。
Stage 2: Generate query and execute action
生成查询:
动作生成器生成搜索查询“Find the area of Washington in square miles”。
这个查询会由搜索工具(查询生成器 Mq)执行。
执行查询:
查询生成器生成搜索查询并通过搜索引擎执行,得到结果:“The area of Washington is 71,362 square miles”。
更新解决方案历史:
解决方案历史更新为包含华盛顿的面积信息。
下一步推理过程
Stage 1: Predict step+tool with action generator (Step 3)
再次通过动作生成器预测下一步操作和所需工具。
动作生成器 (A) 预测步骤[code] 并计算德州和华盛顿在地图上的面积差。
选择的工具是 [code][code]。
Stage 2: Generate code and execute action
生成代码:
- 动作生成器生成代码片段,用于计算德州和华盛顿在地图上的面积差。
- 这个代码片段由代码生成器Mc 执行。
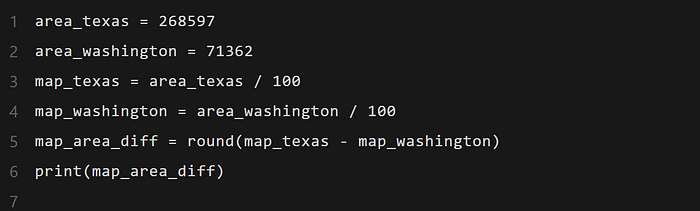
输出最终答案:
- 根据计算结果,德州比华盛顿在地图上大1972平方英寸。
反正总结下来就是反复折腾,这个实际的延迟取决于你多步模型的推理step被分解的复杂程度,太复杂的任务,先不说对错,多步调度肯定是要慢的,这个也是没办法的事情。
总而言之,就是Husky这个Agent+特定专家模型的解决方案,可以一定程度上给小模型在复杂应用场合的占有一席之地,这个结论首先应该是可以的(思路也挺清晰)
换个角度,它能不能就靠这个来替代超级模型,也可以给出个结论,替不了,先不说使用体验,这里有个核心就是蒸馏也就是蒸馏知识,你蒸馏不了网络,会把一定的COT能力加持进来,特别是训练A也就是action的时候,还有个半人工的COT加持。
但是不可能面面俱到,总之还是加载了知识,尤其它其实就是微调,也可以叫加载的只是知识回答的范式吧。实际上并没有加载推理的能力,我们一定要看到这个本质问题,在这个本质问题没有解决的前提下,其他的假设都是空谈。
在拆解任务上取决于多个step,每个step的短板就是整个木桶的最短板,可能会影响整体任务的效果。
大家要是拿来做一些基本的任务,我个人还是挺推荐的,还是那句话,因为设计思路清晰,要解决的问题也很有针对性。思路只要清晰的东西,用起来大抵还是没问题的,可以取代一部分大模型的复杂任务,但是全面,这个永远不可能。(Star也不可能,后面讲)
本文完。

原文地址:https://blog.csdn.net/kingsoftcloud/article/details/140429805
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!