机器学习:考试复习提纲
该页仅为复习资料,内含博客链接均通过搜索得到。
当然直接访问我的GitHub博客会更方便。
1. 线性回归 Linear Regression
https://www.cnblogs.com/geo-will/p/10468253.html
要求1:可以按照自己的理解简述线性回归问题。
回归分析是一种预测性的建模技术,它研究的是因变量(目标)和自变量(预测器)之间的关系。线性回归是回归问题中的一种,线性回归假设目标值与特征之间线性相关,即满足一个多元一次方程。通过构建损失函数,来求解损失函数最小时的参数w和b。
要求2:可以对简单数据进行计算(PPT中例题)。
最小二乘法与梯度计算
见网页
要求3: 可以编程实现线性回归算法。
见网页
2. 逻辑回归 Logistic Regression
https://www.cnblogs.com/geo-will/p/10468356.html
要求1:可以按照自己的理解简述逻辑回归问题以及与线性回归问题的区别与联系。
逻辑斯蒂回归(Logistic Regression) 虽然名字中有回归,但模型最初是为了解决二分类问题。
线性回归模型帮助我们用最简单的线性方程实现了对数据的拟合,但只实现了回归而无法进行分类。因此LR就是在线性回归的基础上,构造的一种分类模型。LR 通过一个联系函数,将预测值转化为离散值从而进行分类。对数几率引入了一个对数几率函数(logistic function),将预测值投影到 0-1 之间,从而将线性回归问题转化为二分类问题。
要求2:掌握梯度下降法、牛顿法的基本原理和迭代公式。
要求3:可以编程实现逻辑回归算法。
见网页
3. 决策树 Decision Tree
https://www.cnblogs.com/geo-will/p/9773621.html
要求1:可以按照自己的理解简述决策树算法。
简单而言,决策树是一个多层if-else函数,对对象属性进行多层if-else判断,获取目标属性的类别。由于只使用if-else对特征属性进行判断,所以一般特征属性为离散值,即使为连续值也会先进行区间离散化,如可以采用二分法(bi-partition)。
要求2:可以利用ID3,C4.5 和 CART算法对数据进行分类。
ID3 使用信息熵 Ent(D) 得到信息增益 Gain(D,a),衡量划分属性
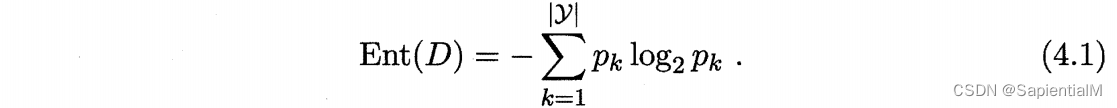
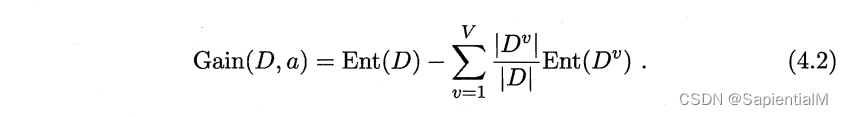
C4.5 使用增益率 Gain_ratio(D,a),衡量划分属性
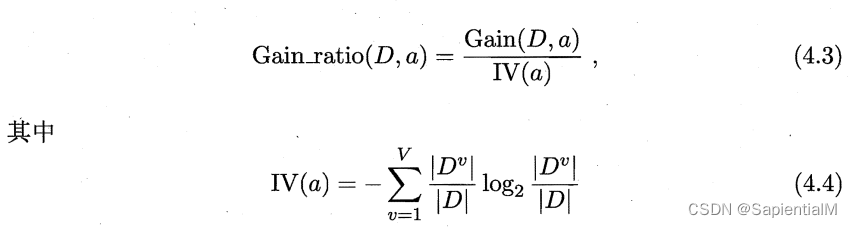
CART 使用基尼值 Gini(D) 得到 基尼指数 Gini_index(D,a),衡量划分属性
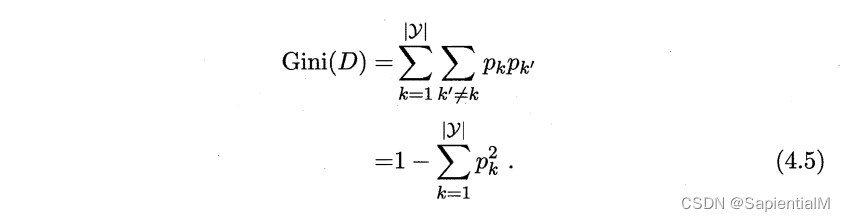
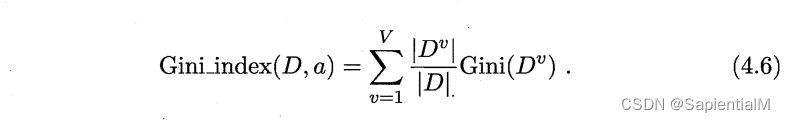
要求3:可以对生成的决策树进行剪枝处理。
预剪枝 与 后剪枝
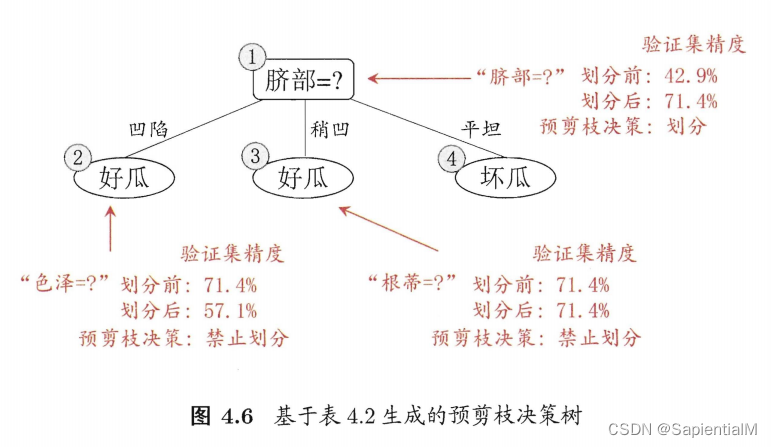
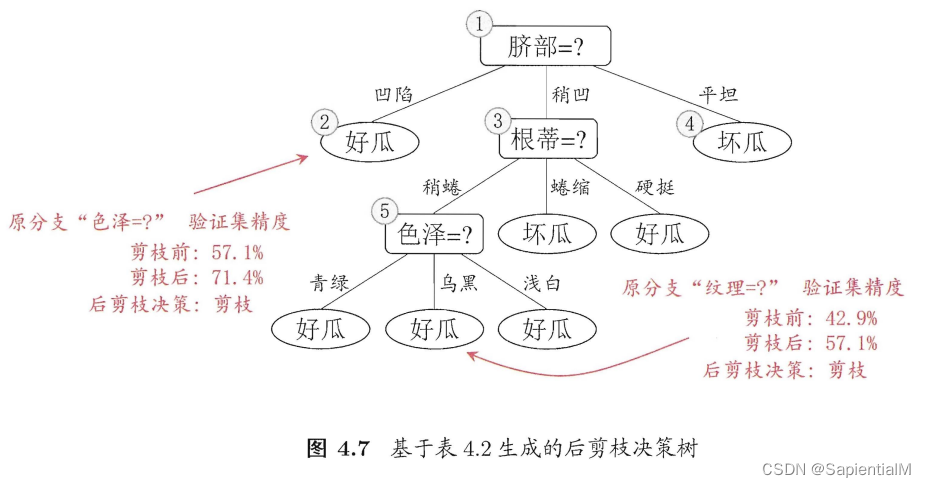
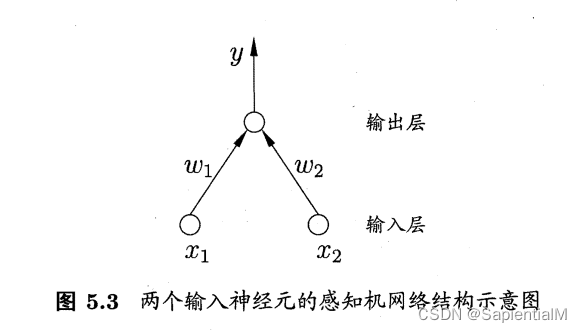
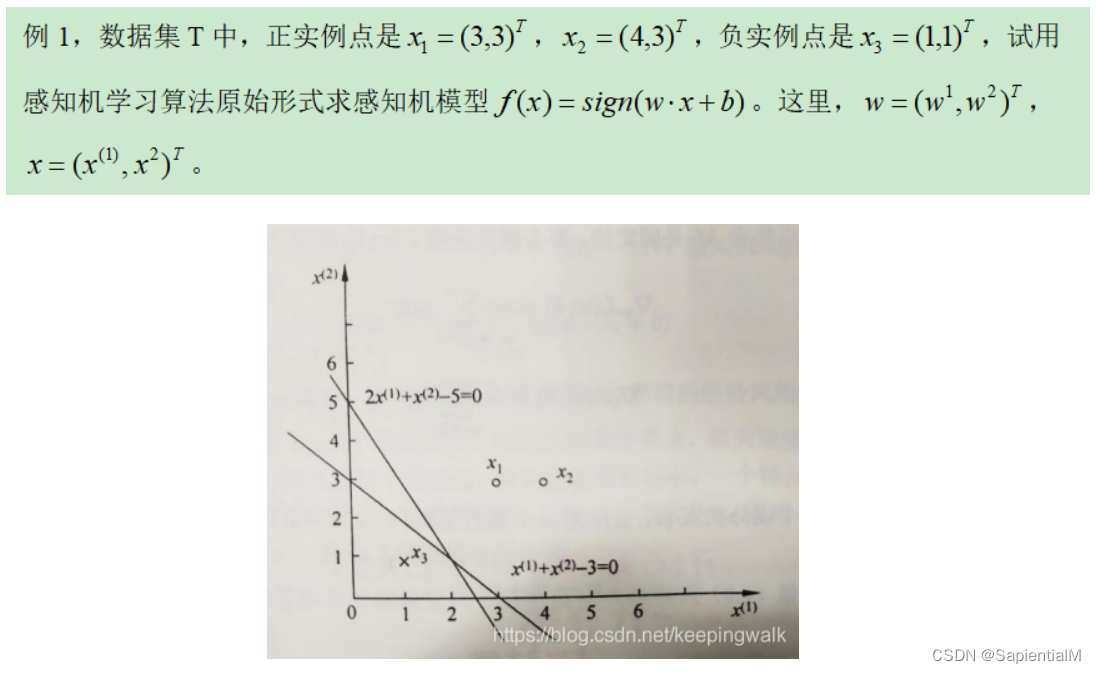
4. 感知机 Perceptron —— 神经网络的组成单元
要求1:可以按照自己的理解简述感知机模型。
感知机(Perceptron) ,最简单的感知机是由两层神经元组成的一个简单模型。
感知机是一个接收多个输入信号,输出一个信号的简单模型。它是神经网络的组成单元。
它的输出层是M-P神经元,即输出层神经元进行激活函数处理,也称为阈值神经单元(threshold logic unit);也叫功能神经元。
输入层接受外界信号(样本属性)并传递给输出层(输入层的神经元个数等于样本的属性数目),而没有激活函数。
多层感知机还有一个层在输出层到输入层之间叫隐含层,隐含层类似于输出层,接收上一层的输出,通过激活函数将值传入下层。
要求2:可以利用感知机解决逻辑分类问题。(不是很懂)



5. 神经网络 Neural Networks
https://blog.csdn.net/qq_32865355/article/details/80260212
https://blog.csdn.net/RAO_OO/article/details/77234524
要求1:可以按照自己的理解简述神经网络模型,以及与感知机的关系。
神经网络是由具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实世界物体所做的交互反应。神经网络中最基本的成分便是神经元(Neuron)模型,也就是上面说的适应性简单单元。
感知机由两层神经元组成,是最简单形式的前馈式人工神经网络。
要求2:掌握BP算法的基本原理和迭代公式。
误差反向传播算法简称反向传播算法(即BP算法)。使用反向传播算法的多层感知器又称为BP神经网络。BP算法是一个迭代算法,它的基本思想为:(1)先计算每一层的状态和激活值,直到最后一层(即信号是前向传播的);(2)计算每一层的误差,误差的计算过程是从最后一层向前推进的(这就是反向传播算法名字的由来);(3)更新参数(目标是误差变小)。迭代前面两个步骤,直到满足停止准则(比如相邻两次迭代的误差的差别很小)。
6. 支持向量机 Support Vector Machine
https://zhuanlan.zhihu.com/p/77750026
https://zhuanlan.zhihu.com/p/65487578?from_voters_page=true
要求1:可以按照自己的理解简述支持向量机模型,以及与其他分类算法的区别。
支持向量机的基本思想是寻找两类样本之间最中间的超平面。支持向量机的目的是使划分平面对于样本的扰动容忍性好。
逻辑回归算法是基于全部样本的二分类器:考虑全部样本的平均似然性。
支持向量机算法是基于部分样本的二分类器:考虑部分靠近边界的支持向量。
要求2:掌握使用拉格朗日乘子法对约束优化问题进行求解,并理解使用拉格朗日乘子法求解SVM问题的原因。
拉格朗日乘子法是求解约束优化问题常用的方法之一,其基本思想是求解与之等价的无约束对偶问题
拉格朗日乘子加入到目标函数中,有两个作用
- 将约束函数引入到目标函数中,转化为无约束问题,不满足约束条件的解会使得目标函数无穷大,故而无解
- 引入拉格朗日乘子另一个最大的作用就是将约束条件与目标函数混在一起,使得我们可以同时计算目标函数的梯度与约束条件的梯度,根据相关的性质从而找到我们想找到的局部最优解或者全局最优解
要求3:可以按照自己的理解简述软间隔支持向量机,并分析其与常规支持向量机的关系与区别。
在实际应用中,完全线性可分的样本是很少的,如果遇到了不能够完全线性可分的样本,我们就有了软间隔,相比于硬间隔的苛刻条件,我们允许个别样本点出现在间隔带里面.
我们为每个样本引入一个松弛变量 ε,令 εi > 0 ,且:
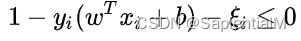
和常规的 SVM 一样,软间隔只是多了个约束,SVM 和 软间隔SVM的对偶问题都有相同的目标函数。
特点:
- 软间隔SVM可以对有outlier的数据分类。
- 软间隔SVM对偶模型与SVM对偶模型非常相似,可以用相同算法求解。
- 软间隔SVM模型可以看作是最小化hinge损失函数的正则化模型。
- 当参数C趋向无穷大时,软间隔SVM退化成普通的SVM。
要求4: 了解SMO算法。
SMO(Sequential Minimal Optimization),序列最小优化算法,其核心思想非常简单:每次只优化一个参数,其他参数先固定住,仅求当前这个优化参数的极值。
7. 主成分分析 Principle Component Analysis
https://blog.csdn.net/zhongkelee/article/details/44064401
要求1:可以按照自己的理解简述主成分分析算法。
当信息维度过多时,对每个指标进行分析往往是孤立的,不是综合的,盲目的减少指标也会损失很多信息,因此我们需要在减少分析指标的同时,还要尽量减少指标包含的信息损失,达到对数据的全面分析。主成分分析 PCA 便是这样一种方法。PCA的思想是将n维特征映射到 k 维上(k < n),这k维是全新的正交特征。我们称之为主成分,是重新构造出来的k维特征,而不是简单地从n维特征中去除其余n-k维特征,它包含了与去除的特征之间的关系。
要求2:可以简述PCA算法的流程。
整个PCA过程貌似及其简单,就是求协方差的特征值和特征向量,然后做数据转换。
网页例子 (1 2 3 45): https://blog.csdn.net/zhongkelee/article/details/44064401
- Step 1: 中心化 计算均值差
- Step 2: 计算协方差矩阵 n*n cov 𝑪 = 𝐜𝐨𝐯 𝑨 = 𝑨𝑨𝐓
- Step 3: 特征值分解
- Step 4: 投影、降维
要求3:核化PCA与PCA的相同与不同。
PCA是利用特征的协方差矩阵判断变量间的方差一致性,寻找出变量之间的最佳的线性组合,来代替特征,从而达到降维的目的。
KPCA利用核化的思想,将样本的空间映射到更高维度的空间,再利用这个更高的维度空间进行线性降维。
对于 KPCA 如果样本的维度是k,样本个数是n(n>k),那么首先需要将样本投射到n维空间,这个n维空间是这样计算的:首先计算n个样本间的距离矩阵D(n*n),核函数F,则F(D)就是他的高维空间投射。
核函数还不是很懂。
8. 线性判别分析 Linear Discriminant Analysis
https://www.cnblogs.com/pinard/p/6244265.html
要求1:可以按照自己的理解简述线性判别分析算法,并分析其与PCA之间的联系与区别。
线性鉴别分析的基本思想是将高维的模式样本投影到最佳鉴别矢量空间,以达到抽取分类信息和压缩特征空间维数的效果,投影后保证模式样本在新的子空间有最大的类间距离和最小的类内距离,即模式在该空间中有最佳的可分离性。因此,它是一种有效的特征抽取方法。使用这种方法能够使投影后模式样本的类间散布矩阵最大,并且同时类内散布矩阵最小。就是说,它能够保证投影后模式样本在新的空间中有最小的类内距离和最大的类间距离,即模式在该空间中有最佳的可分离性。
LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的。这点和PCA不同。PCA是不考虑样本类别输出的无监督降维技术。
比较:
思想上:
- PCA旨在寻找一组子坐标系(定义一个子空间)使得样本点的方差最大,即信息量保留越多。
- LDA旨在寻找一组子坐标系(定义一个子空间)使得样本点类内散度小,类间散度大(Fisher Criteria)。
监督性:
- PCA是无监督学习方法
- LDA是有监督学习方法
算法效率
- PCA效率更胜一筹
子空间学习(Subspace Learning)角度:
- PCA与LDA都属于线性子空间学习算法(Linear Subspace Learning)。
- 目标都是学习一个投影矩阵𝑊 = [𝒘1, ⋯ , 𝒘𝑚],使得样本在新坐标系上的表示具有相应特性(PCA——样本方差最大,LDA——同类样本高聚合度,不同类样本高扩散度)。
- 在样本空间定义一个新的子坐标系(即子空间),其每个列向量定义一个坐标轴,故此类算法均称为子空间学习算法。
降维(Dimension Reduction)角度:
- 坐标轴数目少,维度也少了
特征提取(Feature Extraction)角度:
- 样本在新坐标系下的坐标相当于样本的新特征(Feature,or Representation)
要求2:可以简述LDA算法的流程。

9. K-均值聚类 K-means Clustering
https://www.cnblogs.com/pinard/p/6164214.html
https://www.cnblogs.com/zhxuxu/p/9860654.html
要求1:可以按照自己的理解简述K-means算法。
K-Means算法的思想很简单,对于给定的样本集,按照样本之间的欧式距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离(簇中心的距离)尽量的大。
要求2:可以简述Lloyd算法的流程。
- Lloyd’s algorithm 过程:
- (1)首先在数据集中随机选定k个初始点
- (2) 计算k个站点的Voronoi图。
- (3)整合Voronoi图的每个单元格,并计算质心。
- (4)然后将每个站点(k)移动到其Voronoi单元的质心。
- Lloyd’s的输入是一个连续的几何区域,而不是一组离散的点。
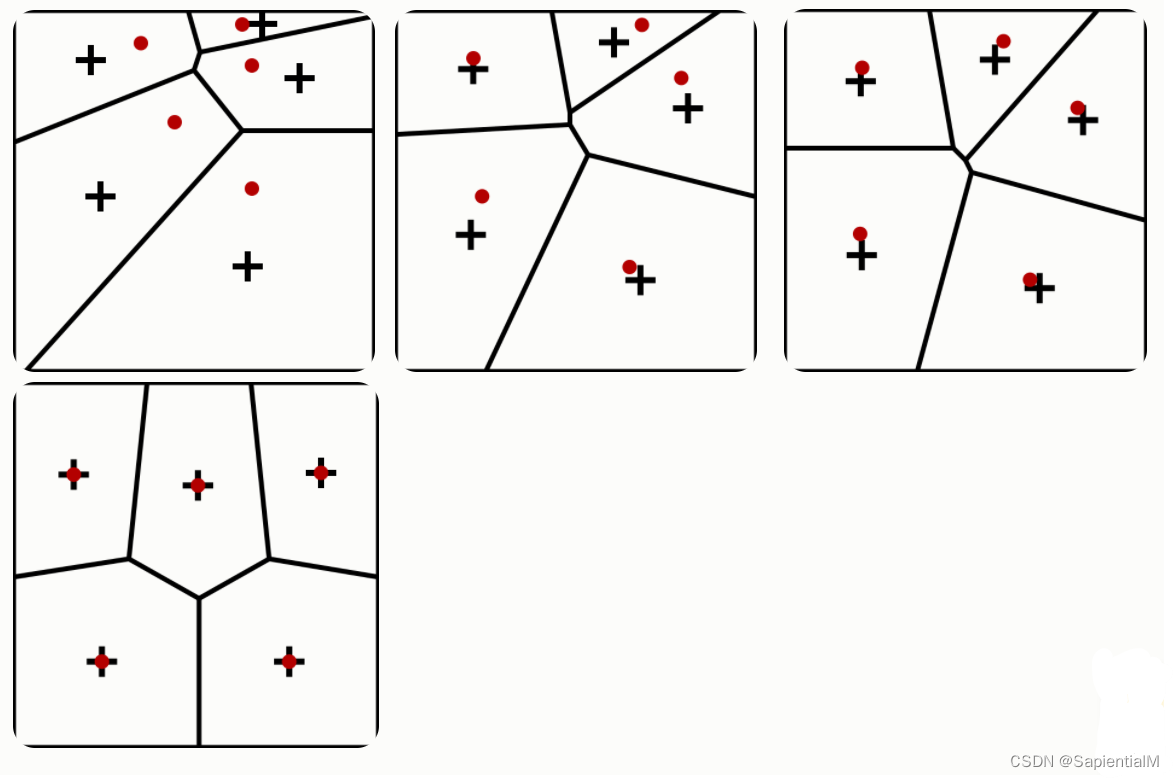
而可以用Lloyd算法来启发式的求解 K-means

- 原K-Means算法过程:
- (1)随机初始化k个聚类中心的位置
- (2)计算每一个点到聚类中心的距离,选取最小值分配给k(i)
- (3)移动聚类中心(其实就是对所属它的样本点求平均值,就是它移动是位置)
- (4)重复(2),(3)直到损失函数(也就是所有样本点到其所归属的样本中心的距离的和最小)
原 K-means 算法是选取距离最小的样本点作为中心,而 Lloyd 来求解则为每次将质点作为新中心。
在 K-Means 聚类时,每个聚类簇的质心是隐含数据。假设 K 个初始化质心,即 EM 算法的 E 步;然后计算得到每个样本最近的质心,并把样本聚类到最近的这个质心,即 EM 算法的 M 步。重复这个 E 步和 M 步,直到质心不再变化为止,这样就完成了 K-Means 聚类。
原文地址:https://blog.csdn.net/qq_43362426/article/details/137965969
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!