数据结构--循环链表
一.循环链表的设计
1.循环链表的结构设计:
typedef struct CNode{
int data;
struct CNode* next;
}CNode ,*CList;
2.循环链表的示意图:
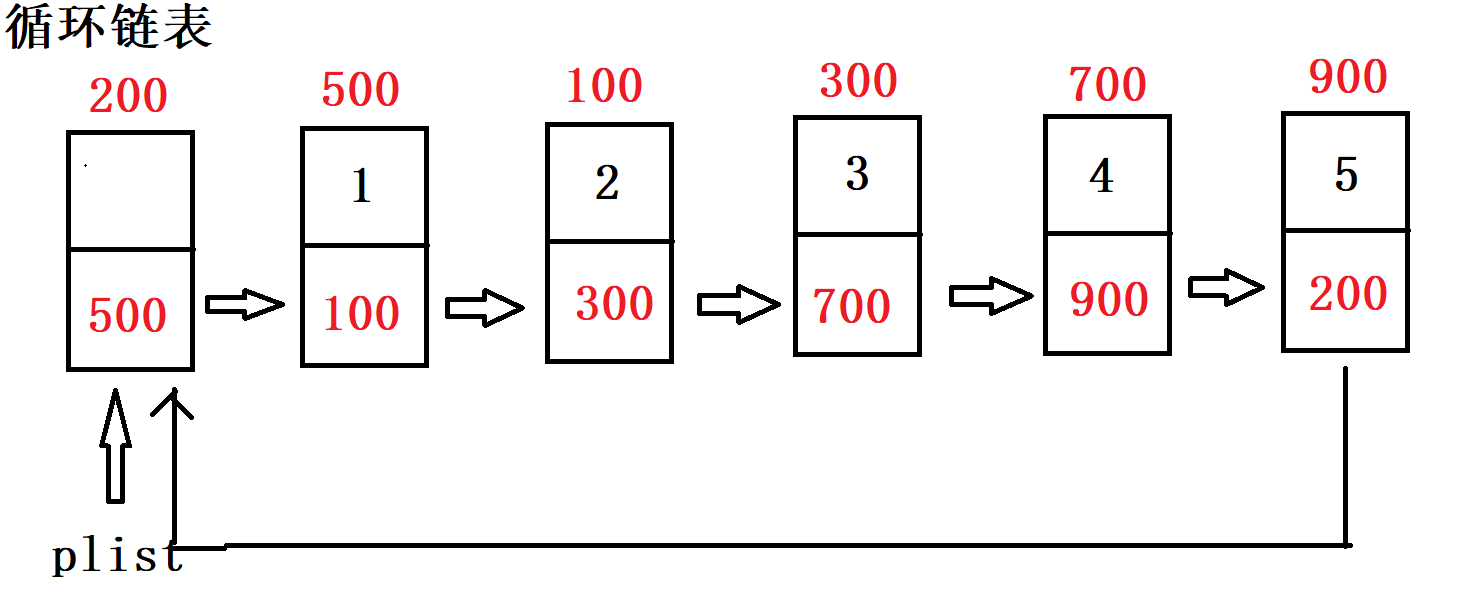
3.循环链表和单链表的区别:
唯一区别,没有空指针,尾节点的后继为头,为循环之意.
二.循环链表的实现
//初始化
free(q);
return true;
}
//返回key的前驱地址,如果不存在返回NULL;
CNode* GetPrio(CList plist, int key)
{
CNode* p;
for (p = plist; p->next != plist; p = p->next)
{
if (p->next ->data == key)
{
return p;
}
}
return NULL;
}
//返回key的后继地址,如果不存在返回NULL;
CNode* GetNext(CList plist, int key)
{
CNode* p = Search(plist, key);
if (p == NULL)
return NULL;
return p->next;
}
//输出
void Show(CList plist)
{
for (CNode* p = plist->next; p != plist; p = p->next)
{
printf("%d ", p->data);
}
printf("\n");
}
//清空数据
void Clear(CList plist)
{
Destroy(plist);
}
//销毁整个内存
void Destroy(CList plist)
{
//总是删除第一个数据节点
CNode* p;
while (plist->next != plist)
{
p = plist->next;
plist->next = p->next;
free(p);
}
}三.循环链表的总结
循环链表其实和单链表是一样的操作,只是在处理的时候处理好尾节点即可,切记,遍历循环链表中不可出现NULL,若遍历的时候出现NULL就错了.
原文地址:https://blog.csdn.net/weixin_75188368/article/details/137611557
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!