beeFormer——基于Transformer 结合文本信息和交互的数据推荐系统
背景
论文地址:https://www.arxiv.org/pdf/2409.10309
本文提出了一种新的推荐系统–beeFormer。
传统的推荐系统主要使用 “协同过滤”(CF),即根据用户过去的互动(如购买历史)进行推荐,但它面临着 "冷启动 "和 "零投篮 "问题。系统面临 "零投篮 "问题,尤其难以适用于新产品和新用户。
为了弥补这一不足,人们开发了使用文本信息(如产品描述和评论)的方法,但这些方法往往只关注 “语义相似性”,无法充分捕捉用户行为模式。
技术
为了解决上述两个问题,beeFormer直接使用文本数据和交互数据来训练Transformer模型、然后将其与交互数据结合起来进行训练。这种方法不仅利用了产品之间的语义相似性,还利用了用户实际选择的产品之间的交互数据,从而提高了推荐的准确性。
在训练过程中,Transformer 模型首先对商品文本进行编码,生成一个向量矩阵。
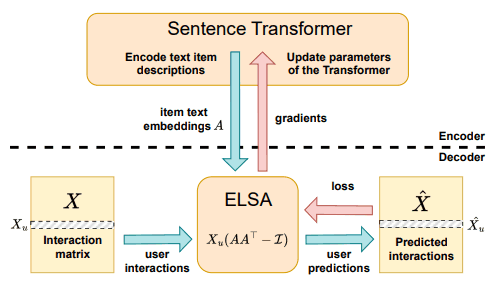
生成的矢量随后使用一个名为 "ELSA "的解码器模型,结合用户交互矩阵进行训练。在这一过程中,使用了梯度检查点和负采样等技术,以减少训练过程中的内存消耗,并确保即使在大型数据集上也能进行高效训练。
beeFormer 的优势在于它能够在多个不同的数据集之间传递知识。例如,通过整合和训练一个电影数据集和一个图书数据集,有望建立一个通用的、与领域无关的推荐模型。因此,基于 beeFormer 训练的模型比传统的协同过滤方法和其他基于文本的方法表现更好,尤其是在新产品和零镜头场景中。
beeFormer 的推出将使推荐更加灵活和先进,超越传统推荐系统的局限。未来,beeFormer 还有望应用于其他多模态领域,如时尚和图像推荐,该技术将对推荐系统的发展产生重大影响。
试验
本文进行了几项实验,以评估拟议方法 beeFormer 的有效性。
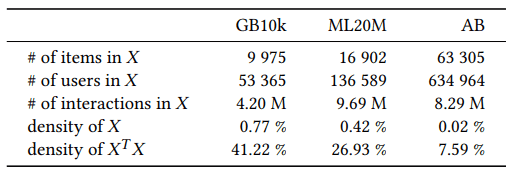
首先,我们使用了三个具有代表性的数据集–MovieLens20M、Goodbooks-10k 和 Amazon Books–来测试 beeFormer 与其他模型相比的表现。这三个数据集分别包含电影和图书的用户评分数据。Recall@20、Recall@50 和 NDCG@100 被用作评分指标。
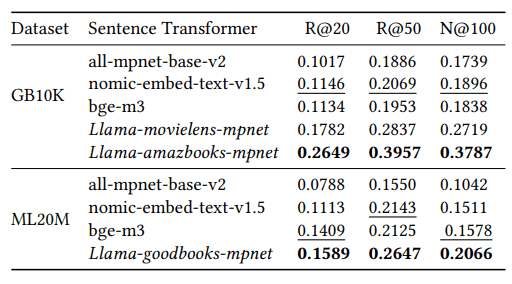
在实验中,数据集在两种情况下进行了评估–"零起点 "和 “冷启动”–以检验beeFormer是否有能力在不同领域转移知识。在 "零起点 "场景中,我们假设训练的模型是在与被评估数据集不同的领域中训练的。例如,我们研究在书籍数据集上训练的模型能否在电影数据集上运行。结果表明,beeFormer 在零点场景下的表现优于其他基准模型。
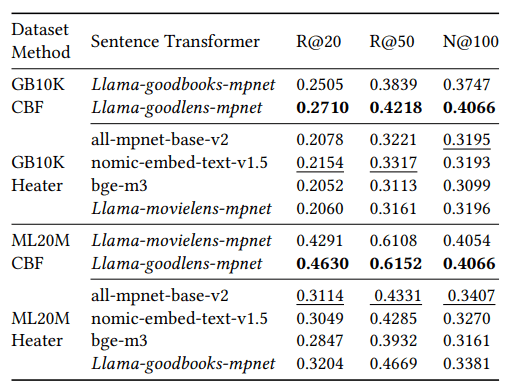
beeFormer 利用基于文本的信息来提高对新项目的推荐准确性。在这项实验中,与传统的加热器模型和表现最好的句子转换器模型相比,beeFormer 显示出更优越的结果。特别是在不同数据集之间的知识转移方面,beeFormer保持了较高的性能,明显优于传统方法。
此外,还进行了一项 "时间分割 "实验,对按时间顺序分割的数据进行评估,结果显示,beeFormer优于协同过滤(CF)方法,尤其是在亚马逊图书数据集上。该实验评估了根据历史数据训练的模型预测最新互动的准确度。结果证实,beeFormer超越了单纯的文本相似性,能够根据用户的实际行为模式进行推荐。
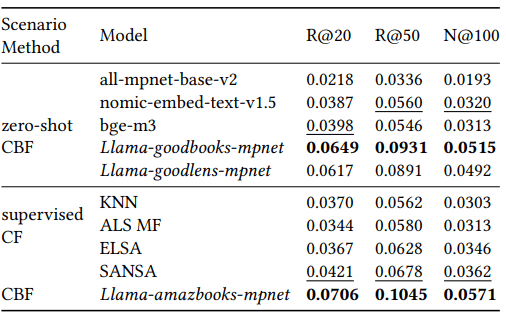
总之,这些实验结果证明了 beeFormer 强大的知识转移能力和较高的推荐准确率,并证明它在实现跨领域通用推荐系统方面迈出了可喜的一步。
总结
本文的结论表明,与传统的推荐系统相比,所提出的beeFormer方法是一个重大进步。相似性,还能学习隐藏的用户行为模式。这使它能够超越现有的方法,尤其是在 "冷启动 "和 "零拍摄 "的情况下。
总之,beeFormer 的实现可以在未来推荐系统的设计中发挥重要作用。特别值得一提的是,它能够在跨越不同数据源和多个领域的情况下提供持续的高性能。此外,beeFormer 与现有工具的高度兼容性以及在实际操作中的易实施性使其在实际商业环境中的应用前景广阔。
该方法未来还可应用于时尚和图像推荐等其他领域,为推荐系统的发展提供了新的可能性。beeFormer的未来发展包括在更大的多领域数据集上进行训练,以及开发集成视觉信息的多模态推荐模型。此外,还将开发集成视觉信息的多模态推荐模型。如果这些努力取得成功,预计更高性能和更灵活的推荐系统将成为现实。
原文地址:https://blog.csdn.net/matt45m/article/details/142833092
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!