关于机器学习/深度学习的一些事-答知乎问(四)
如何评估和量化深度学习的可解释性问题?
针对深度学习模型,评估指标能够全面衡量模型是否满足可解释性。与分类的评估指标(准确度、精确度和召回率)一样,模型可解释性的评估指标应能从特定角度证明模型的性能。但是,由于深度学习模型生成解释的性质不同或输入数据的类型不同,目前还没有一个公认的指标用于评估可解释性。 然而,专家可以定性评估生成解释的相关性;并且存在一些定量评估方法,可以客观地评估各个领域产生的解释。
定性评估
比如平均类激活映射方法,该方法提供的全局解释可以由专家通过分析显著性图的形态和细粒度定性分析评估, 而且特定用户可能从专家反馈中受益。然 而,由于深度学习模型具有高度非线性,领域专家也很难定性评估XAI方法生成解释的质量。因此,应优先考虑定量评估方法。
定量评估
定量评估是量化解释的数字指标,为比较不同的解释提供了一种直观的方法。
(1)正确性:正确性表示解释在多大程度上忠实于预测模型。
(2)连贯性:连贯性是为了比较XAI方法生成的解释是否与领域知识或共识一致。
(3)稳定性:稳定性用于评估原始输入样本和引入噪声的样本分别得到的解释之间的相似性,也就是说,输入加入微小的白噪声,解释也会引入可见的变化。
核方法值得关注的研究方向?
(1)从样本中学习核矩阵。
(2) 高斯过程,高斯过程也称正态过程,是最重要的随机过程之一,当其用于解决机器学习问题时被称为GP模型。 GP模型是一种重要的核方法,模型中的协方差函数实际上就是核函数。
(3) 寻找已有核方法的快速算法,这是核方法用于实时处理的关键。比如稀疏核主成分分析的快速算法。
(4) 核函数设计与模型选择。
(5) 拓展核方法的应用领域。
常见的核方法方法有哪些?
常见的核方法可分为有监督型和无监督型,前者所处理的样本集的类别归属已事先标定,后者主要用来处理未被标定的样本集。
有监督型核方法
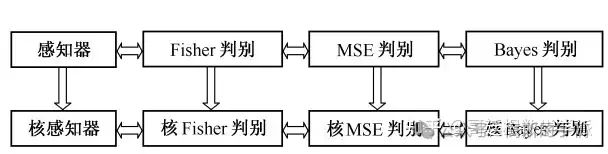
在常见的有监督型核方法中,SVM是最典型的例子。除此之外,还有一批该类方法如核Bayes判别、核Fisher判别、核感知器和最小平方误差判别等,它们分别由经典的线性判别方法如Bayes判别、Fisher判别、感知器和MSE判别核化而来,因此我们将之归并为“基于核的判别方法”。这些方法与相应的线性判别方法相比,最显著的区别是能进行非线性判别。
无监督型核方法
无监督型核方法最典型的例子当数 KPCA,另外还有一批该类方法,如核规范相关分析和核独立成分分析等,它们与信号处理领域里的盲源分离问题是紧密联系在一起的,因此可以称之为“基于核的盲源分离方法”。此外还有核聚类、核投影寻踪等。
构建新的核方法
当掌握了核方法的基本原理、洞察了特征空间的性质后,可模仿已有的核方法,自己动手构建新的核方法。以下给出构建步骤:(1)选择合适的学习算法将其核化。所谓“合适”首先要求学习方法 只能含有样本间的内积运算。其次要求学习方法的复杂度不能太高,因为内积运算通常是包含在矩阵运算里的,核化时用核函数取代内积的过程并不像SVM 那样简单,如果学习方法过于复杂,不仅核化过程异常烦琐,而且所得核方法因复杂度过高而失去意义。(2)根据核方法的处理对象设计合适的核函数。(3)模型选择。
核方法的研究动机是什么?
研究动机至少可以从以下两个方面来理解。
① 核方法在线性与非线性间架设起了一座桥梁。首先,核方法与通常的降维方法背道而驰,通过映射将R中的样本变换到F中,实现样本的升维;升维后的样本在F中变得非常稀疏,便于对其实施线性学习算法。例如对于模式分类而言,一个复杂的模式分类问题被非线性投影到F中以后,该模式比在原始空间中更可能线性可分。因此核方法通过升维使问题得以简化。其次,由于F与R间的映射是非线性的,因此在F中实施的线性算法从R空间的角度看是非线性的,这样核方法可以看作是相应线性算法的一个非线性版本,换句话说,核方法提供了学习算法非线性化的一条新途径。学习算法非线性化的另一条途径是:直接从待分析样本本身的分布出发,希望能找到很好描述其内在结构的非线性模型。例如对于LPCA 方法,若按前述两种途径进行非线性化,可以分别得到KPCA 方法和主曲线方法。两种非线性化途径各有优势:前者原理简单,计算复杂度相对较小;后者对样本的本质特征捕捉更准确。但两者目的都是为了能更准确地描述给定样本集的内在结构。
(2)如果F的维数很高,计算量会很大,甚至会陷入维数灾难而使得计算不可行;但通过代换,F中的内积可基于R中的变量通过给定的核函数直接计算得到,即使F的维数非常高,核方法本身也并没有增加多少计算复杂度。特别是对某些映射函数而言,F的维数是无限的,此时内积必须用积分来计算,这种代换的作用就更加明显。
综上所述,核方法在线性与非线性间架设起一座桥梁,同时通过引入核函数回避了维数灾难,也没有增加计算复杂度,这正是它受到高度关注的原因。
嵌入学习未来的发展方向?
嵌入学习方法,又称表示学习,嵌入即映射,与降维类似,核心思想是将样本嵌入到低维空间中,将样本特征转化特征向量的形式保存在低维特征空间中,减少假设空间的范围,通过较小的嵌入空间来进一步扩大嵌入样本间的区分度,使得同类样本联系更加紧密,而异类样本分布则更加分散,它的关键在于如何嵌入样本特征以及特征嵌入之后如何学习。
小样本场景中,嵌入学习方法的核心思想是训练优秀的特征嵌入函数来实现对样本的映射,旨在让样本在较小的样本特征嵌入空间具有更加清晰的区分度。 嵌入学习方法主要由嵌入模块和度量模块组成,嵌入模块的功能是利用CNN构建并训练特征嵌入函数,将样本以特征向量的形式映射到特征空间中;度量模块则选择合适的度量函数计算样本的相似度度量,完成对样本的分类。
(1)在数据角度上,可以尝试利用其他先验知识(知识图谱)进行特征嵌入函数的训练,探索不依赖模型预训练特征嵌入函数的可行性。训练时,辅助数据中利用较多的是已标注的数据,而现实场景的数据以无标注数据为主,往往无标注数据蕴含着许多有用的信息,值得进行挖掘和利用。
(2)混合嵌入模型的深入研究尤为必要。对比单一 嵌入模型,无论是训练出更优秀且稳定的特征嵌入函数还是缓解过拟合问题方面,混合嵌入模型已经初步证明 了自身的巨大优越性和潜力,未来混合嵌入模型势必会 成为嵌入学习方法的主流,有必要深层次地研究与完善该类方法。
(3)优化Episodic Training训练模式,设计一个更加强大的元学习器。如今元学习作为新兴的代表,在模型应用上不够成熟,现有的元学习器无法学习到足够且有效的元知识。未来,如何设计好的元学习器并提升学习的有效性和丰富性也是至关重要的研究方向。
(4)设计性能更加优秀的神经网络算法。首先,构建以及训练特征嵌入函数的过程中离不开神经网络的支持,参数能否快速学习和优化决定了特征嵌入函数的有效性;另外,度量的有关研究已经较为成熟,固定度量的改进空间非常小,很可能会被动态的可学习度量取代,而动态度量的学习很大程度依赖于神经网络。综上所述,未来对于性能更优的神经网络算法的设计需求将会越来越大。
(5)尝试结合不同嵌入学习方法中各自的优势,或者在嵌入学习方法的基础上,融合其他小样本学习解决方法(不平衡学习、强化学习等先进机器学习框架)的思想,改进原有的方法,形成新的可靠且有效的解决方法。
知乎学术咨询:
工学博士,担任《Mechanical System and Signal Processing》等期刊审稿专家,擅长领域:现代信号处理,机器学习,深度学习,数字孪生,时间序列分析,设备缺陷检测、设备异常检测、设备智能故障诊断与健康管理PHM等。
原文地址:https://blog.csdn.net/weixin_39402231/article/details/137766384
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!