深度学习基础之一:机器学习
文章目录
深度学习基本概念(Basic concepts of deep learning)
机器学习
-
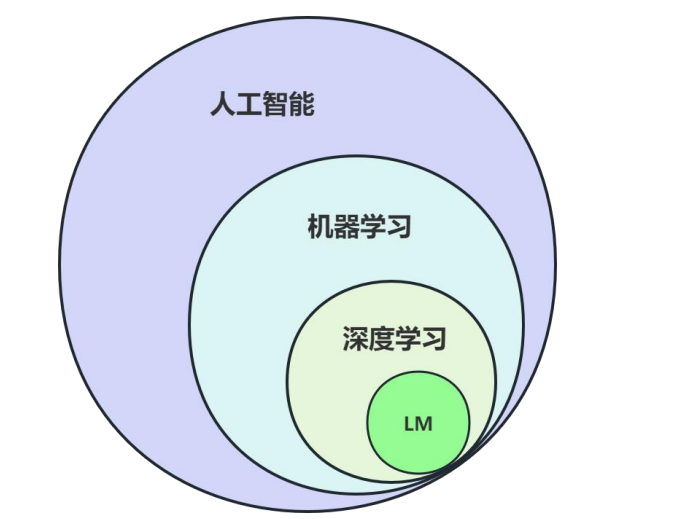
深度学习基于机器学习,是人工智能的一部分,而LM又是深度学习的一部分。
-
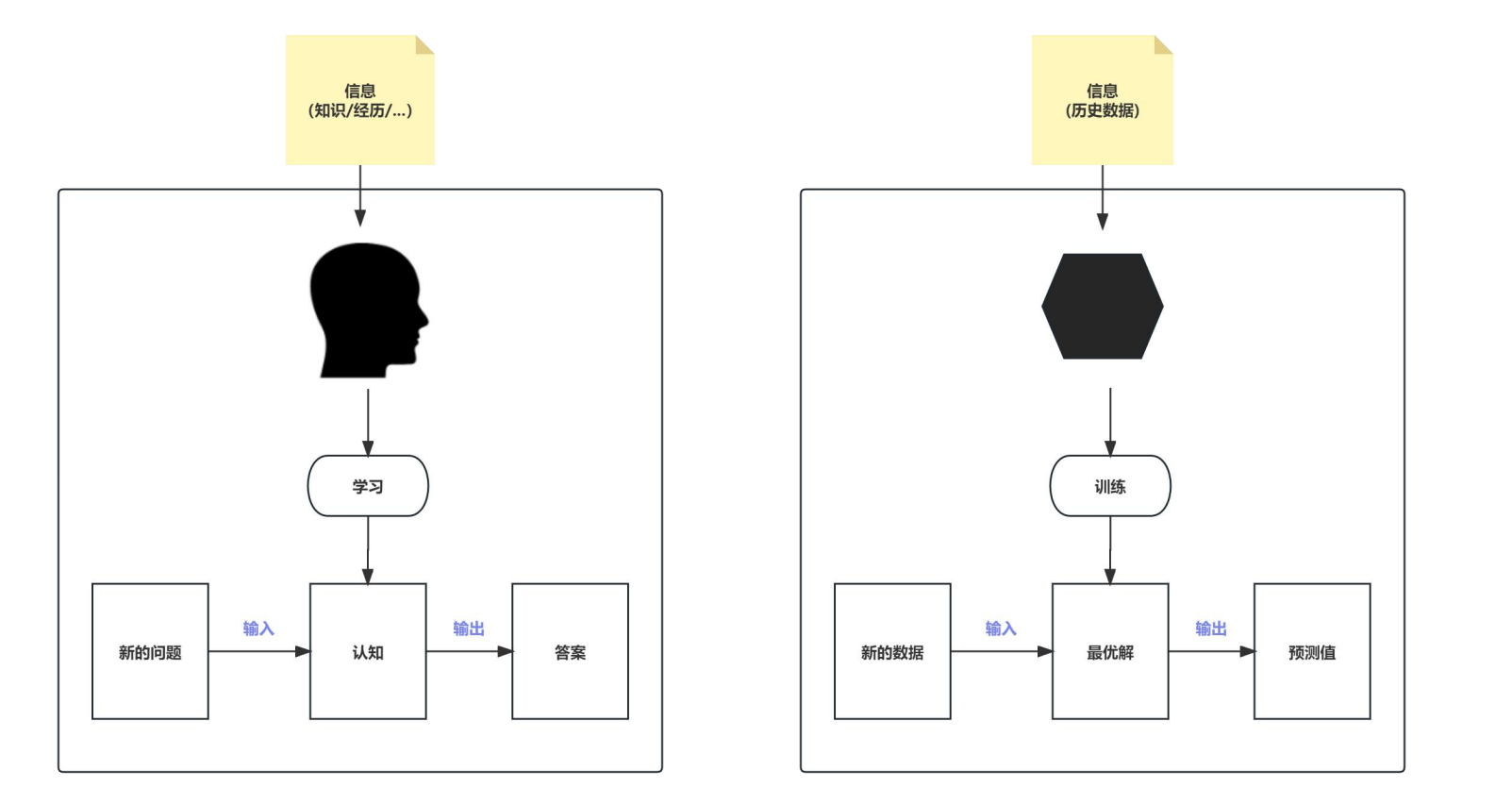
机器学习模拟人的学习过程,通过历史数据进行训练,然后利用积累的经验解决新的问题。
-
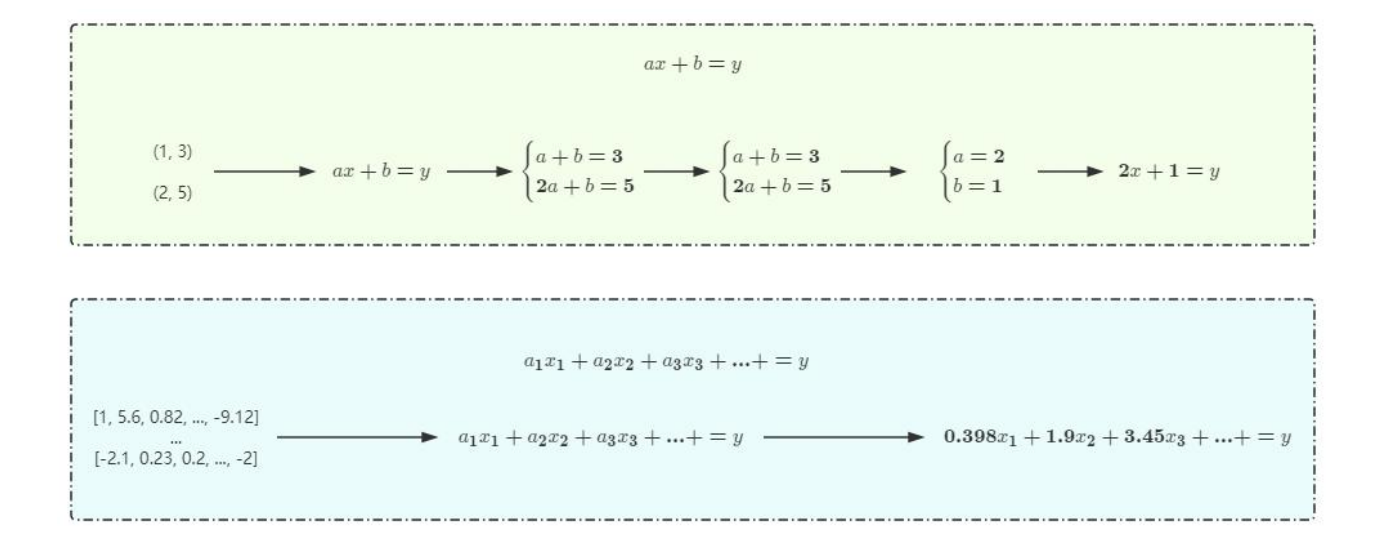
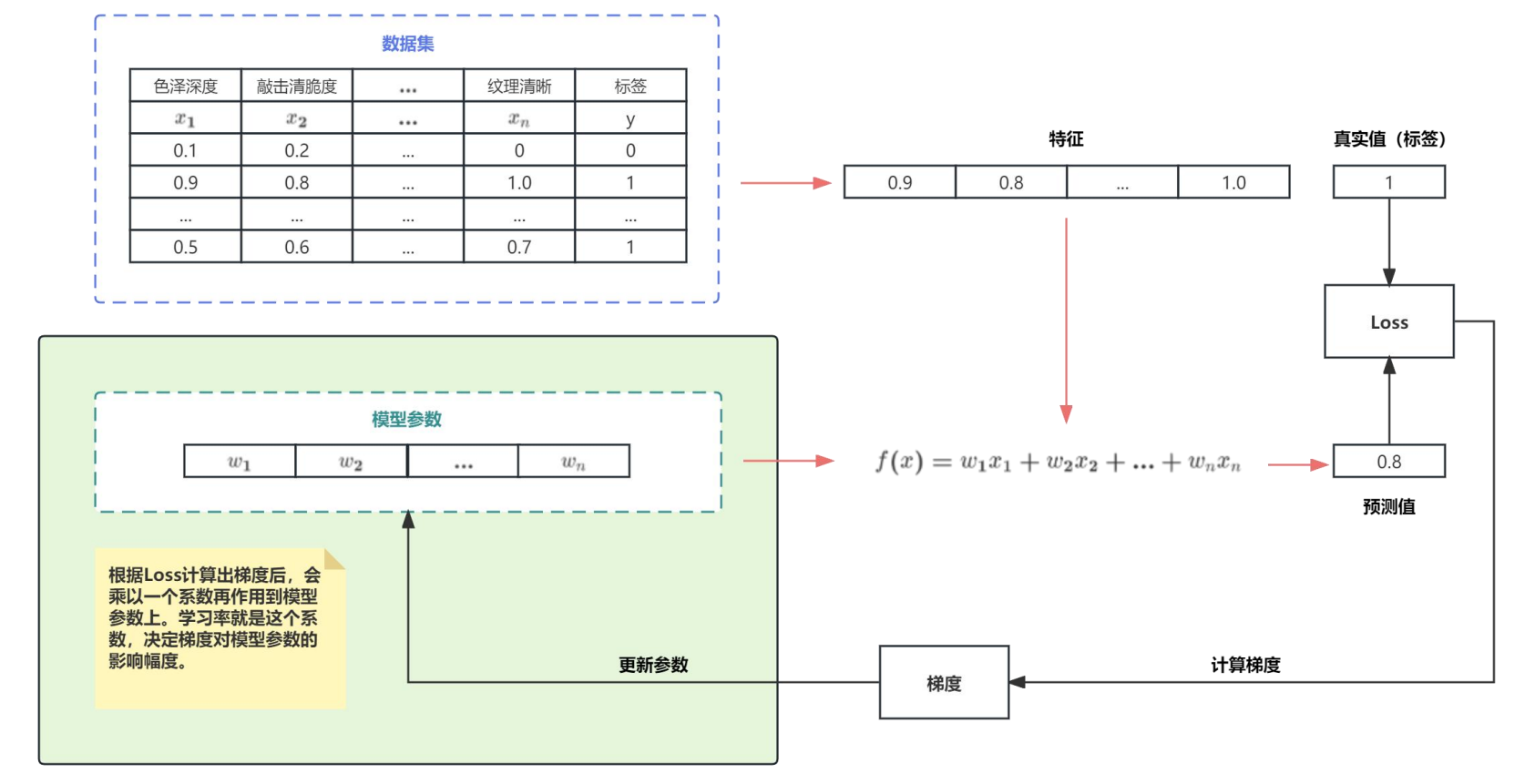
模型:一个包含大量未知参数的函数,所谓训练,就是通过大量的数据去迭代逼近这些未知参数的最优解
-
机器学习:是一门专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能的学科。简单说,就是“从样本中学习的智能程序”。
-
深度学习:深度学习的概念源于人工神经网络的研究,是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。
-
不论是机器学习还是深度学习,都是通过对大量数据的学习,掌握数据背后的分布规律,进而对符合该分布的其他数据进行准确预测
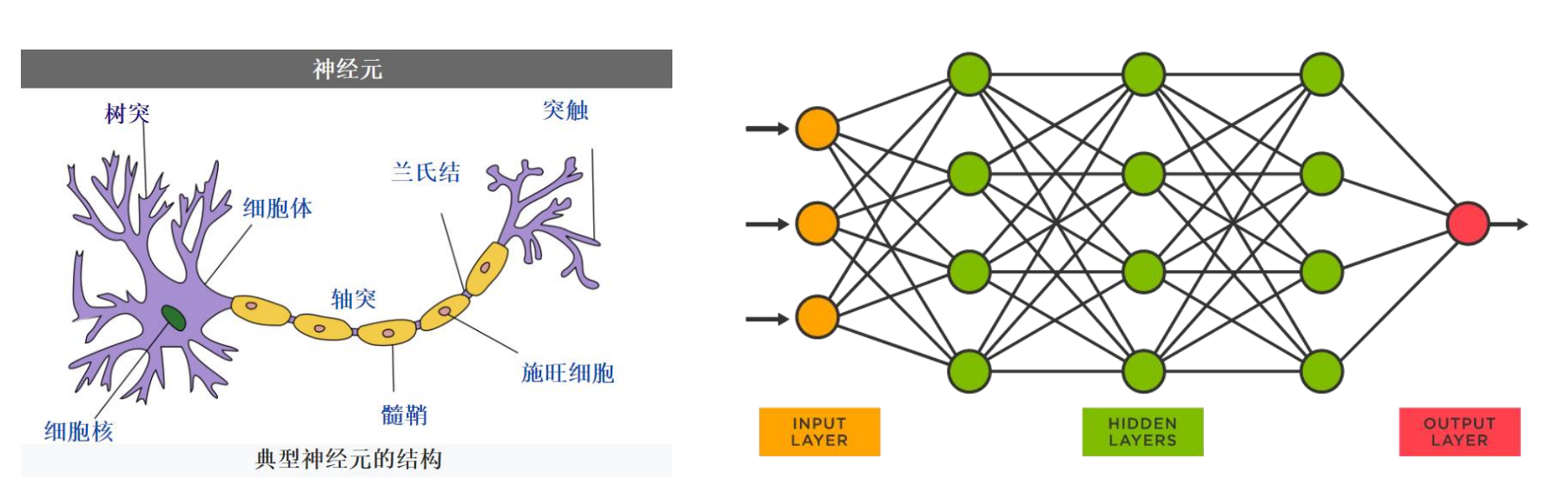
- 人体神经元结构和机器学习结构对比,
典型任务
-
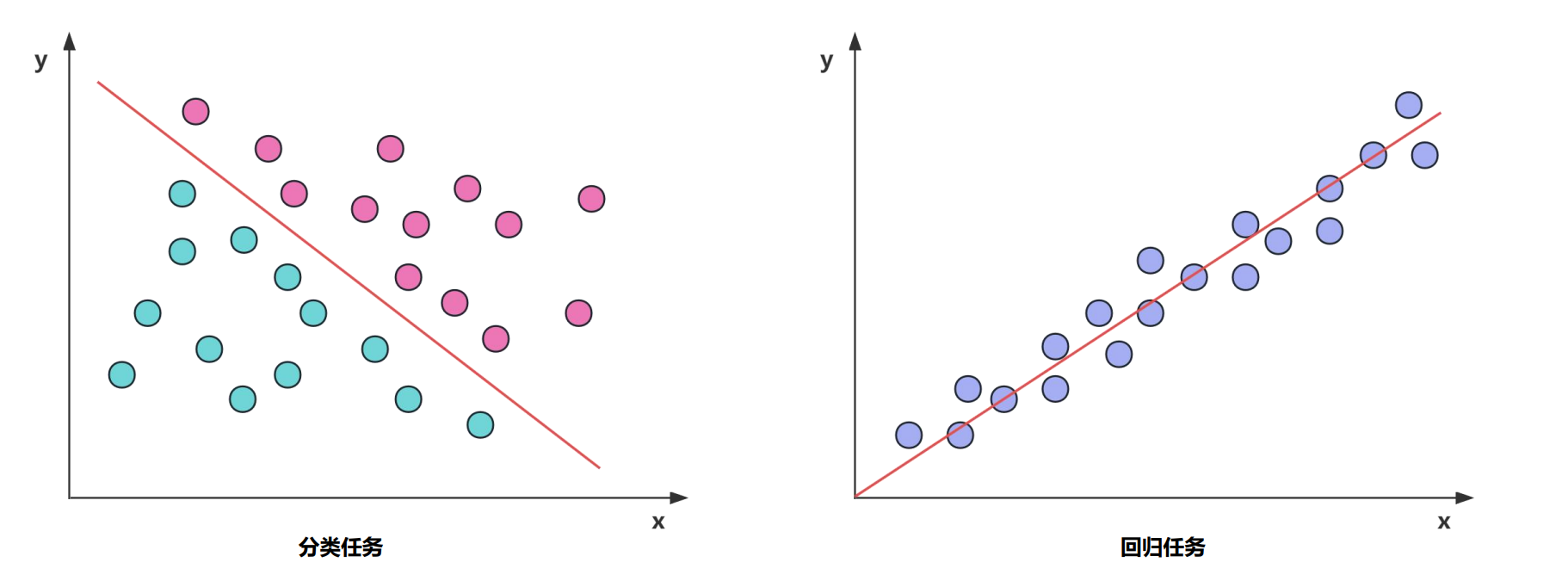
机器学习中的典型任务类型可以分为分类任务(Classification)和回归任务(Regression)
-
分类任务是对离散值进行预测,根据每个样本的值/特征预测该样本属于类型A、类型B 还是类型C,相当于学习一个分类边界(决策边界),用分类边界把不同类别的数据区分开来。
-
回归任务是对连续值进行预测,根据每个样本的值/特征预测该样本的具体数值,例如房价预测,股票预测等,相当于学习这组数据背后的分布,能够根据数据的输入预测该数据的取值。
-
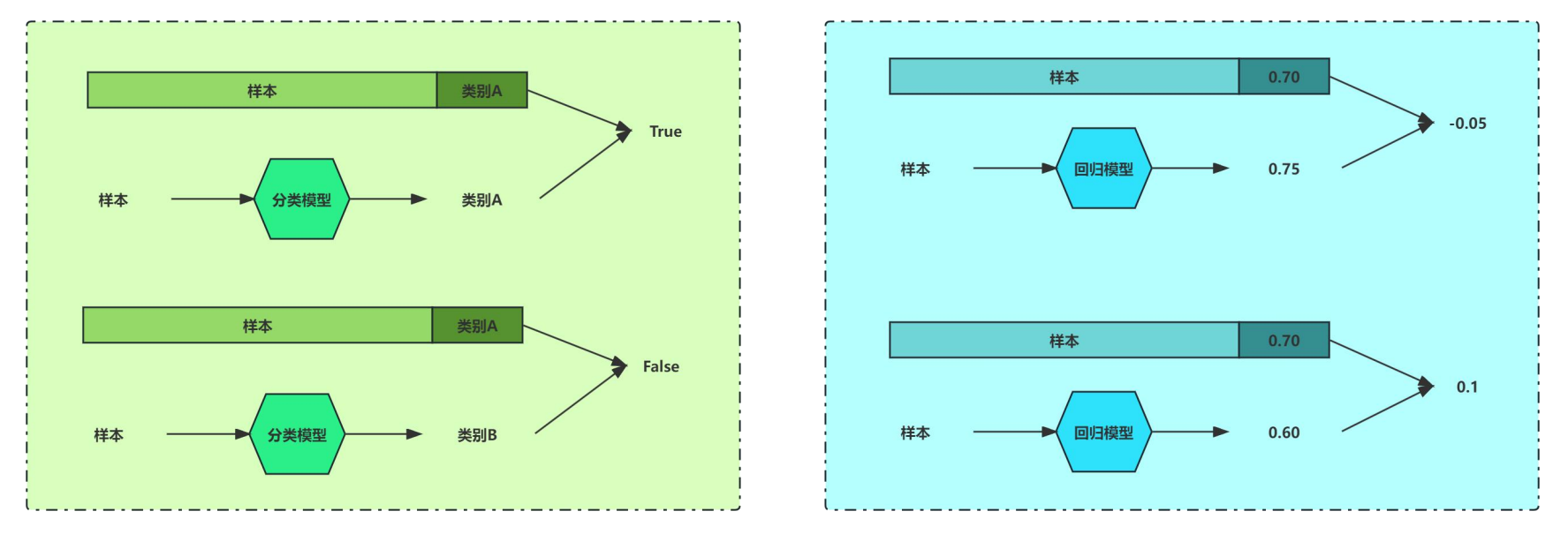
分类与回归的根本区别在于输出空间是否为一个度量空间。
f ( x ) → y , x ∈ A , y ∈ B f(x) \rightarrow y,x \in A,y \in B f(x)→y,x∈A,y∈B -
对于分类问题,目的是寻找决策边界,其输出空间B不是度量空间,即“定性”。也就是说,在分类问题中,只有分类“正确”与“错误”之分,至于分类到类别A还是类别B,没有分别,都是错误数量+1。
-
**对于回归问题,目的是寻找最优拟合,其输出空间B是一个度量空间,即“定量”,通过度量空间衡量预测值与真实值之间的“误差大小”。**当真实值为10,预测值为5时,误差为5,预测值为8时,误差为2
机器学习分类
- 有监督学习:监督学习利用大量的标注数据来训练模型,对模型的预测值和数据的真实标签计算损失,然后将误差进行反向传播(计算梯度、更新参数),通过不断的学习,最终可以获得识别新样本的能力。
- 每条数据都有正确答案,通过模型预测结果与正确答案的误差不断优化模型参数
- 无监督学习:无监督学习不依赖任何标签值,通过对数据内在特征的挖掘,找到样本间的关系,比如聚类相关的任务。
- 只有数据没有答案,常见的是聚类算法,通过衡量样本之间的距离来划分类别
-
有监督和无监督最主要的区别在于模型在训练时是否需要人工标注的标签信息。
-
半监督学习:利用有标签数据和无标签数据来训练模型。一般假设无标签数据远多于有标签数据。例如使用有标签数据训练模型,然后对无标签数据进行分类,再使用正确分类的无标签数据训练模型
- 利用大量的无标注数据和少量有标注数据进行模型训练
- 自监督学习:机器学习的标注数据源于数据本身,而不是由人工标注。目前主流大模型的预训练过程都是采用自监督学习,将数据构建成完型填空形式,让模型预测对应内容,实现自监督学习。
- 通过对数据进行处理,让数据的一部分成为标签,由此构成大规模数据进行模型训练
- 远程监督学习:主要用于关系抽取任务,采用bootstrap的思想通过已知三元组在文本中寻找共现句,自动构成有标签数据,进行有监督学习。
- 基于现有的三元组收集训练数据,进行有监督学习
- 强化学习:强化学习是智能体根据已有的经验,采取系统或随机的方式,去尝试各种可能答案的方式进行学习,并且智能体会通过环境反馈的奖赏来决定下一步的行为,并为了获得更好的奖赏来进一步强化学习。
- 以获取更高的环境奖励为目标优化模型
模型训练的基本概念
基本名词
- 样本:一条数据
- 特征:被观测对象的可测量特性,例如西瓜的颜色、纹路、敲击声等
- 特征向量:用一个 d 维向量表征一个样本的所有或部分特征
- 标签(label)/真实值:样本特征对应的真实类型或者真实取值,即正确答案
- 数据集(dataset):多条样本组成的集合
- 训练集(train):用于训练模型的数据集合
- 评估集(eval):用于在训练过程中周期性评估模型效果的数据集合
- 测试集(test):用于在训练完成后评估最终模型效果的数据集合
- 模型:可以从数据中学习到的,可以实现特定功能/映射的函数
- 误差/损失:样本真实值与预测值之间的误差
- 预测值:样本输入模型后输出的结果
- 模型训练:使用训练数据集对模型参数进行迭代更新的过程
- 模型收敛:任意输入样本对应的预测结果与真实标签之间的误差稳定
- 模型评估:使用测试数据和评估指标对训练完成的模型的效果进行评估的过程
- 模型推理/预测:使用训练好的模型对数据进行预测的过程
- 模型部署:使用服务加载训练好的模型,对外提供推理服务
机器学习任务流程
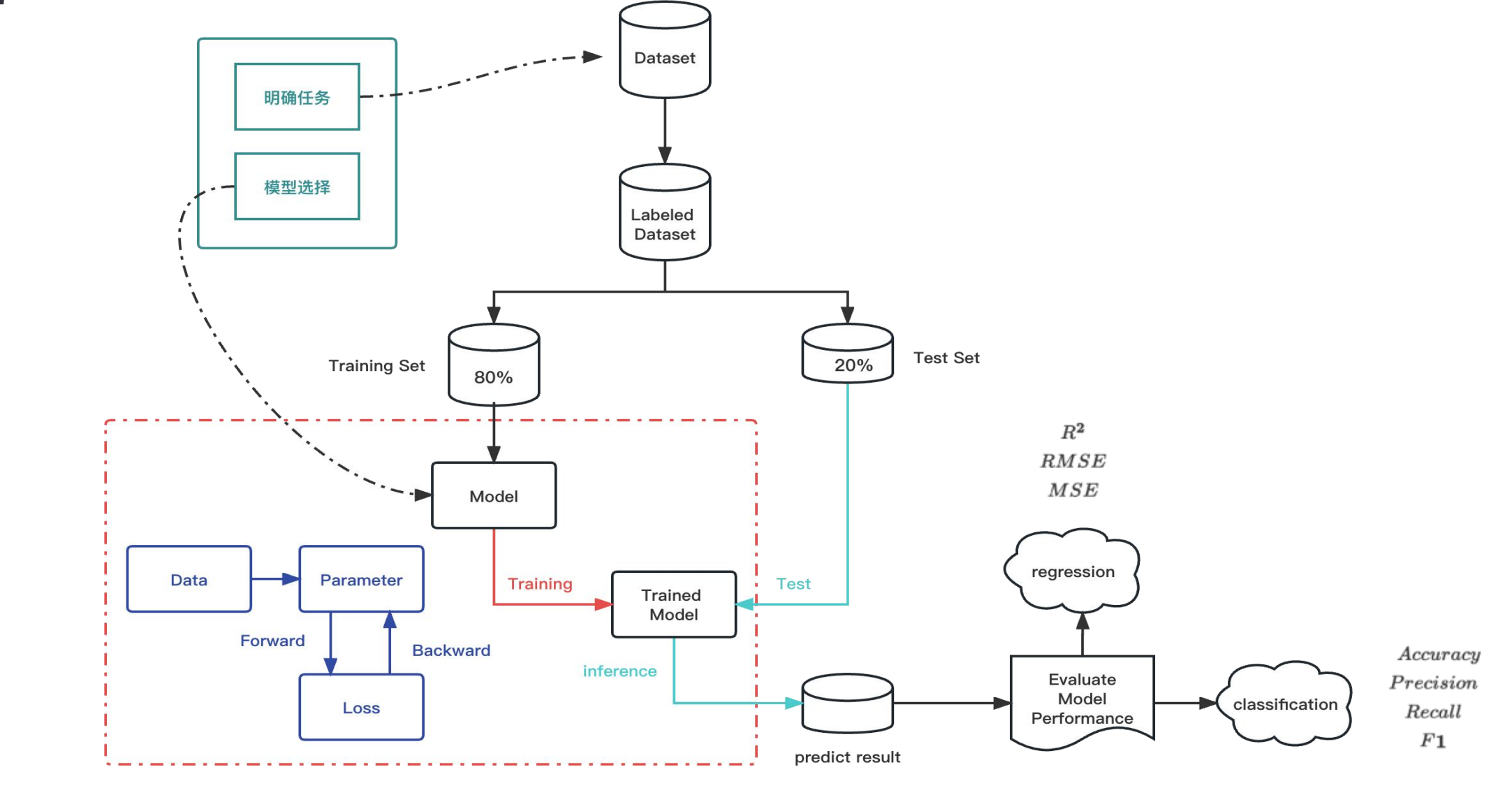
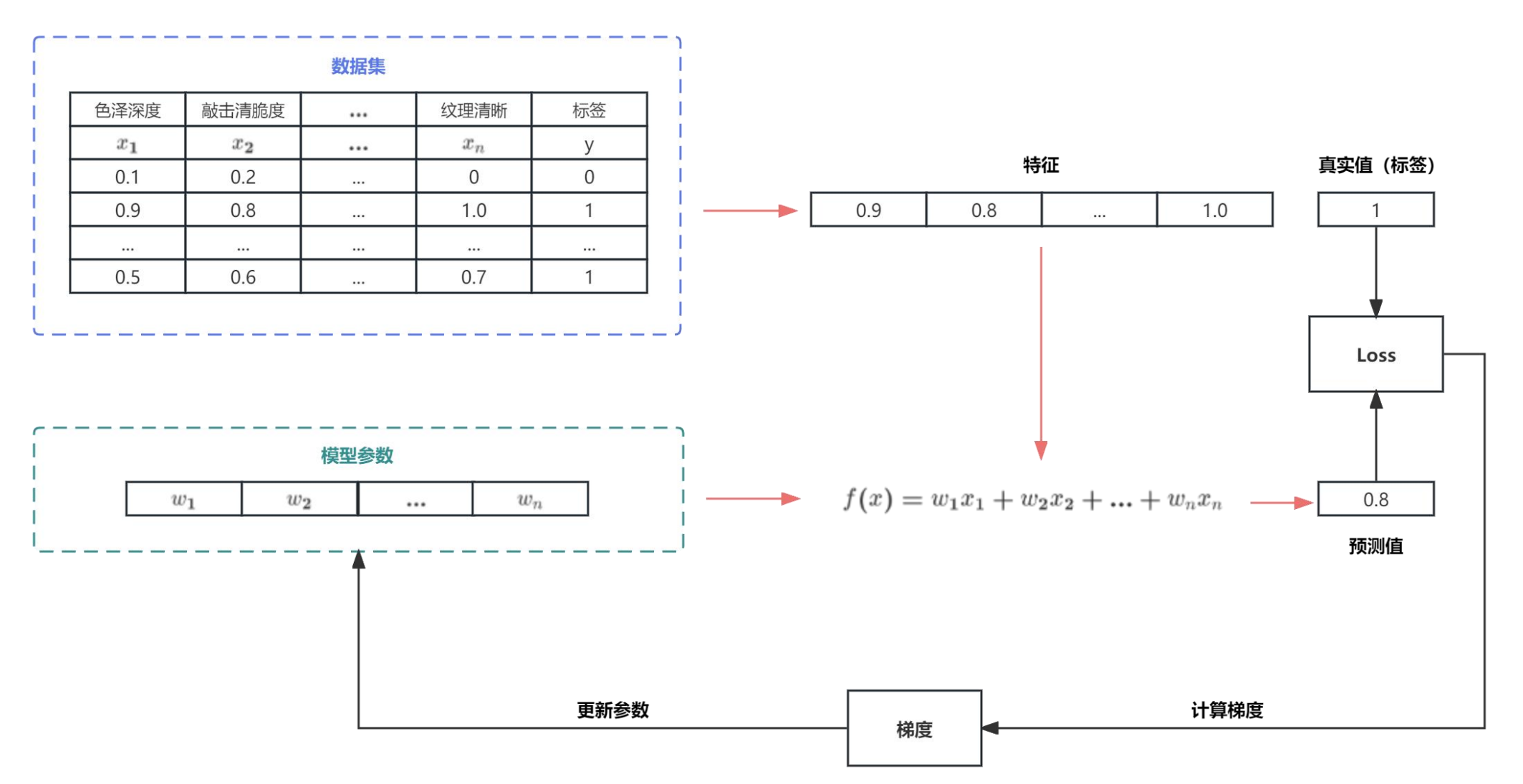
模型训练详细流程
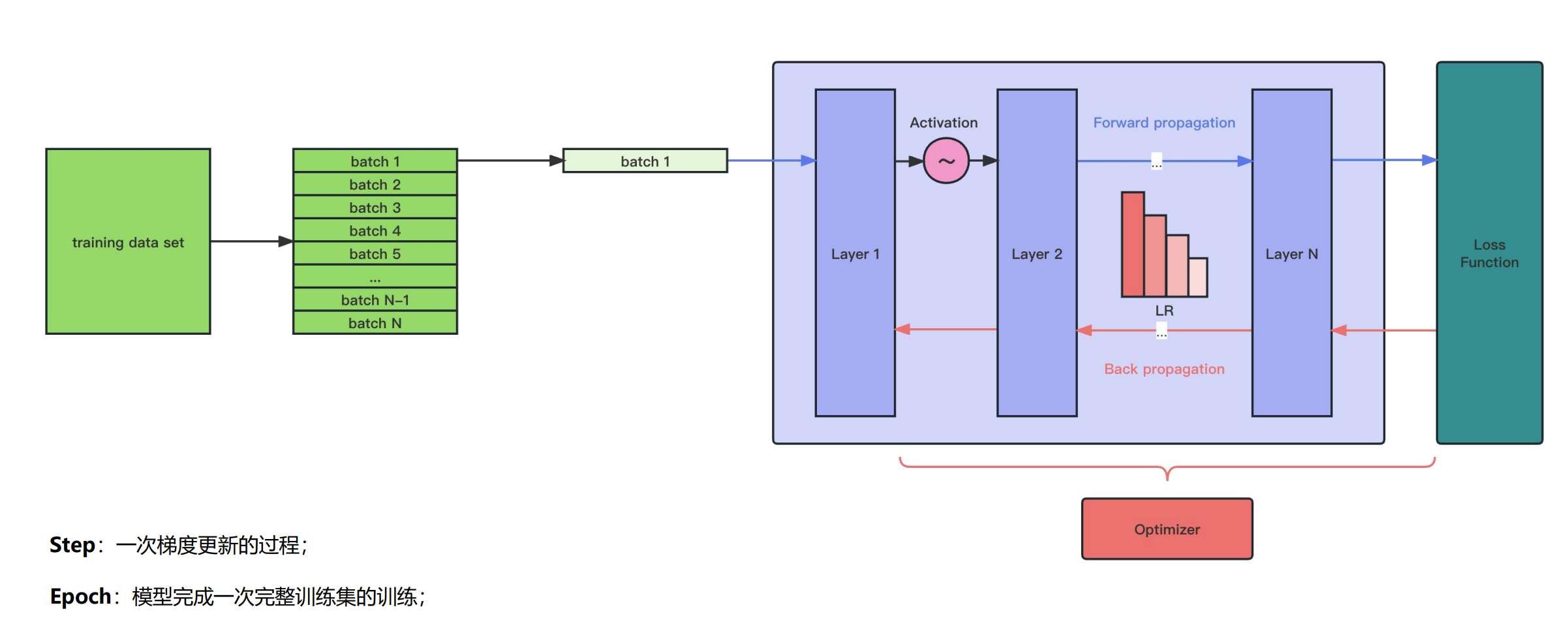
正、反向传播
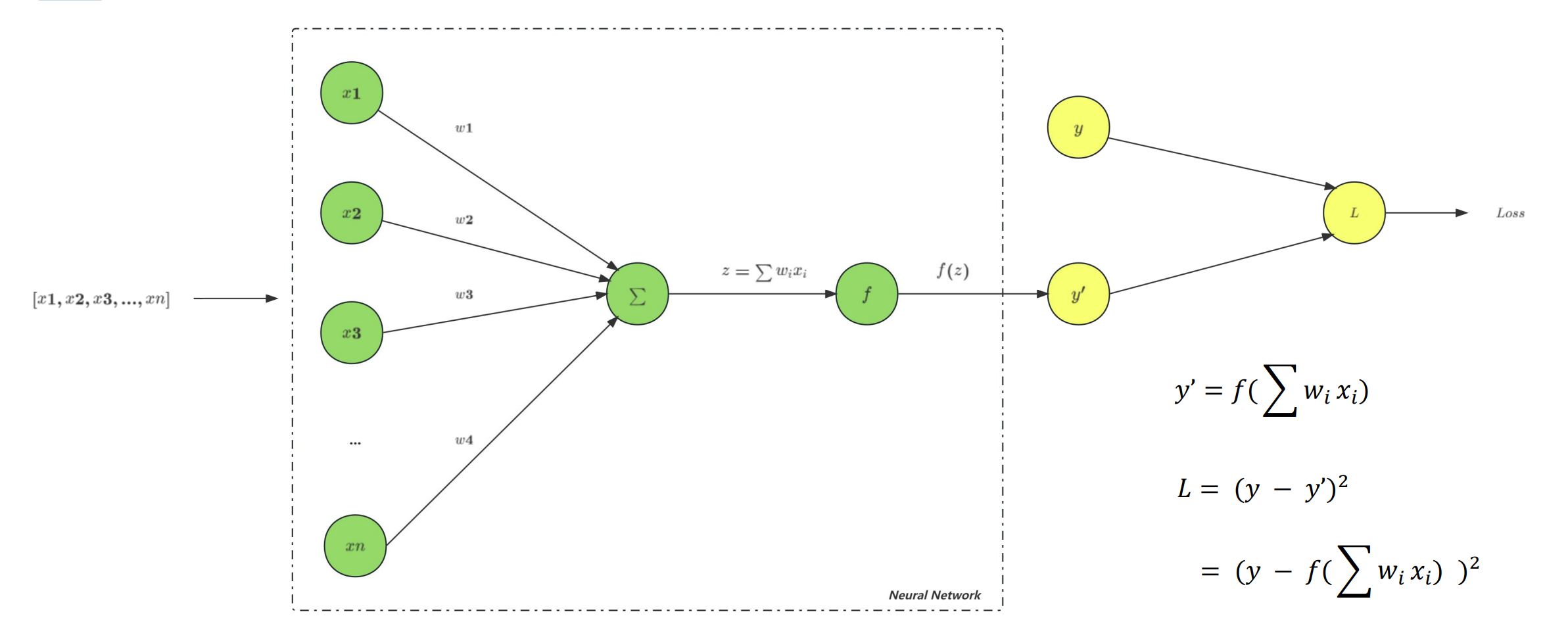
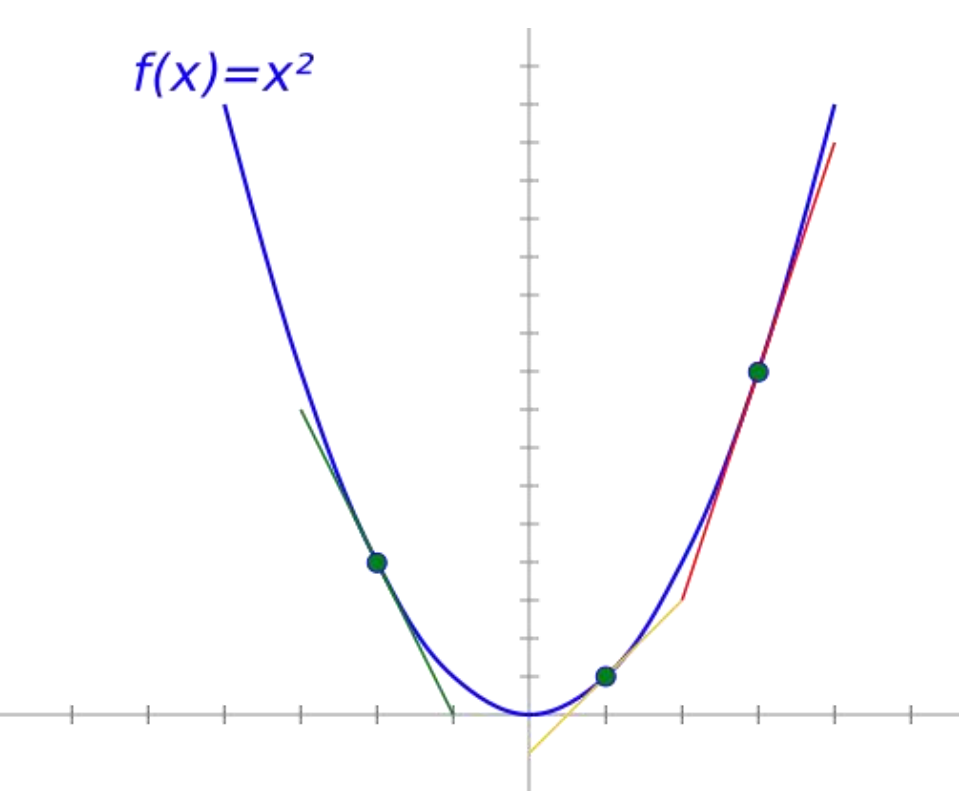
- 梯度:梯度是一个向量(矢量),函数在一点处沿着该点的梯度方向变化最快,变化率最大。换而言之,自变量沿着梯度方向变化,能够使因变量(函数值)变化最大。
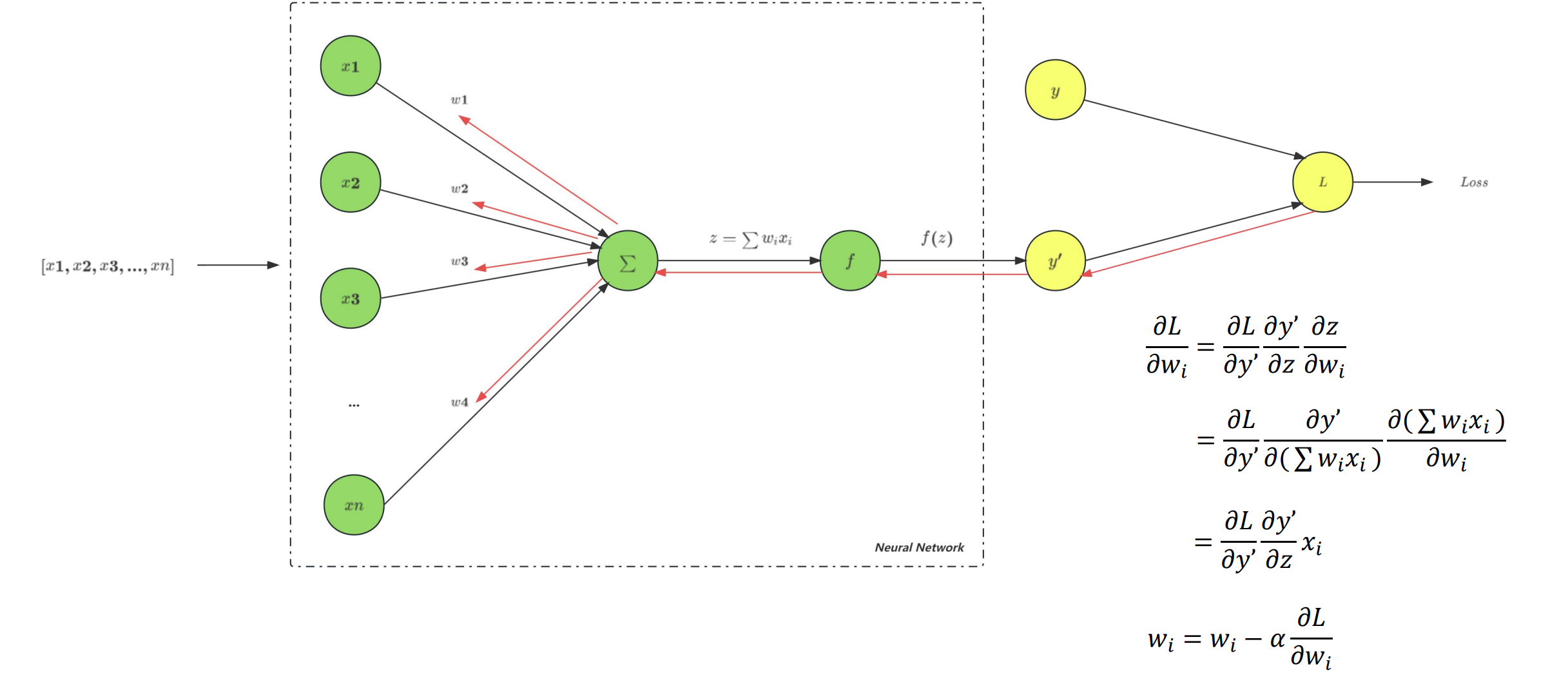
学习率
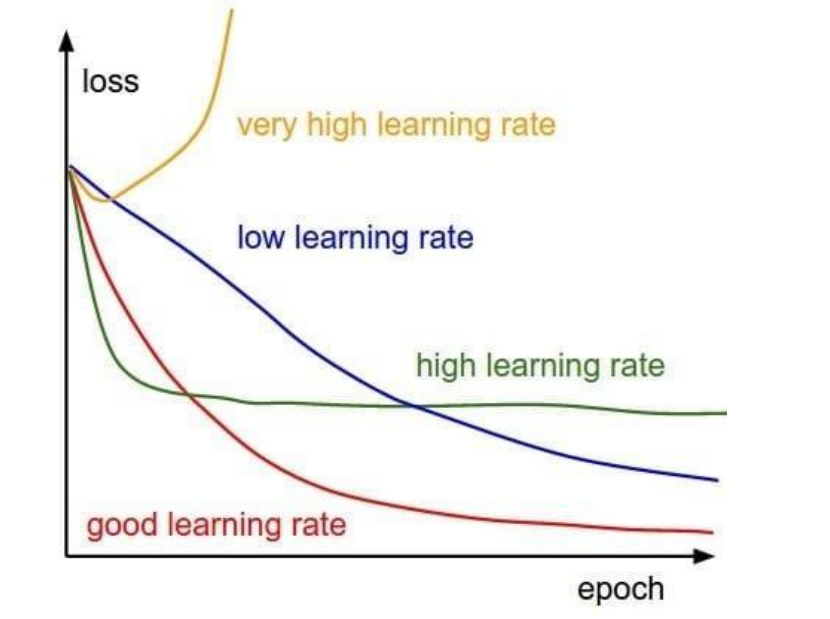
- 学习率(Learning Rate,LR)决定模型参数的更新幅度,学习率越高,模型参数更新越激进,即相同 Loss 对模型参数产生的调整幅度越大,反之越越小。
- 如果学习率太小,会导致网络 loss 下降非常慢;如果学习率太大,那么参数更新的幅度就非常大,产生振荡,导致网络收敛到局部最优点,或者 loss 不降反增。
Batch size
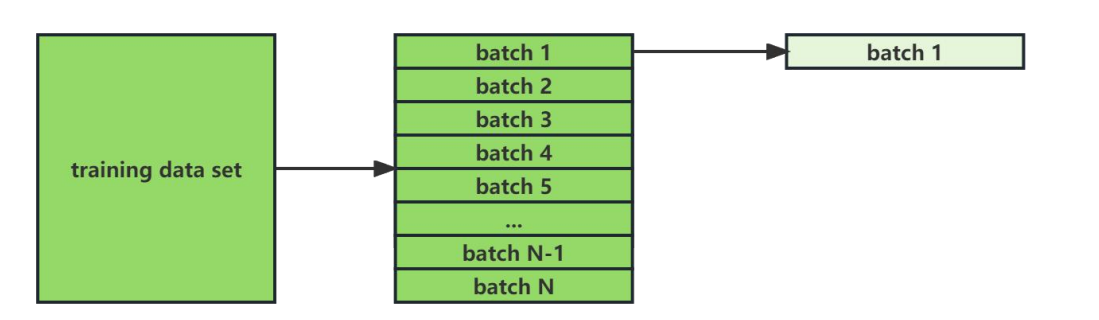
- Batch size 是一次向模型输入的数据数量,Batch size 越大,模型一次处理的数据量越大,能够更快的运行完一个 Epoch,反之运行完一个 Epoch 越慢
- 由于模型一次是根据一个 Batch size 的数据计算 Loss,然后更新模型参数,如果 Batchsize 过小,单个 Batch 可能与整个数据的分布有较大差异,会带来较大的噪声,导致模型难以收敛。
- Batch size 越大,模型单个 Step 加载的数据量越大,对于 GPU 显存的占用也越大,当 GPU 显存不够充足的情况下,较大的 Batch size 会导致 OOM,因此,需要针对实际的硬件情况,设置合理的 Batch size 取值。
在合理范围内,更大的 Batch size 能够:
- 提高内存利用率,提高并行化效率
- 一个 Epoch 所需的迭代次数变少,减少训练时间
- 梯度计算更加稳定,训练曲线更平滑,下降方向更准,能够取得更好的效果
对于传统模型,在较多场景中,较小的 Batch size 能够取得更好的模型性能;对于大模型,往往更大的 Batch size 能够取得更好的性能。
激活函数
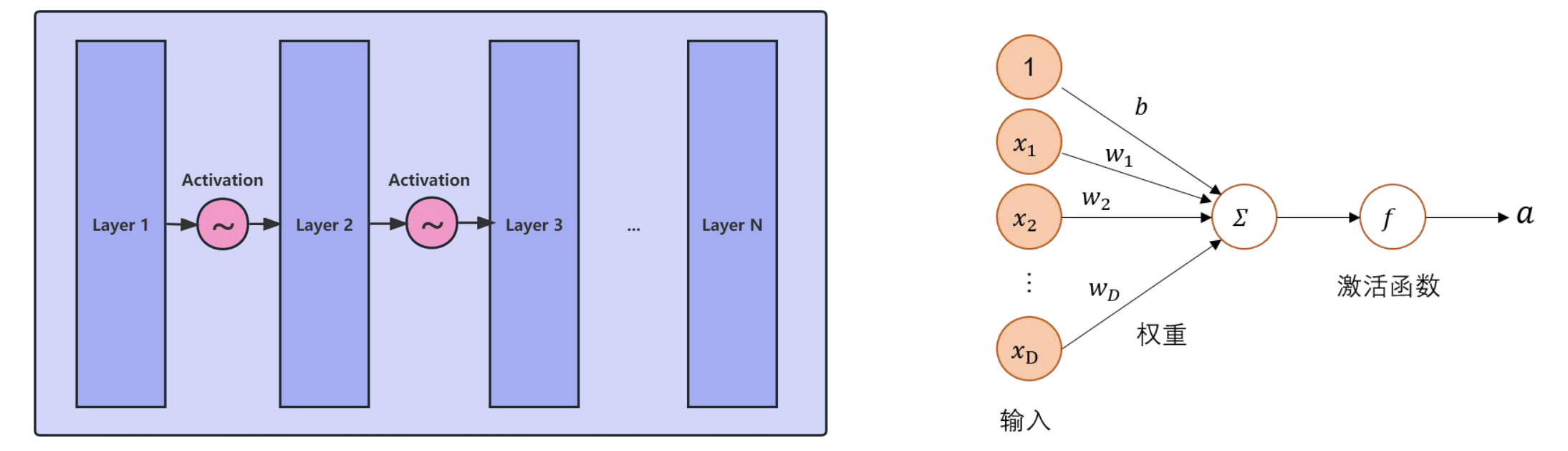
- 线性函数是一次函数的别称,非线性函数即函数图像不是一条直线的函数。非线性函数包括指数函数、幂函数、对数函数、多项式函数等等基本初等函数以及他们组成的复合函数。
- 激活函数是多层神经网络的基础,保证多层网络不退化成线性网络
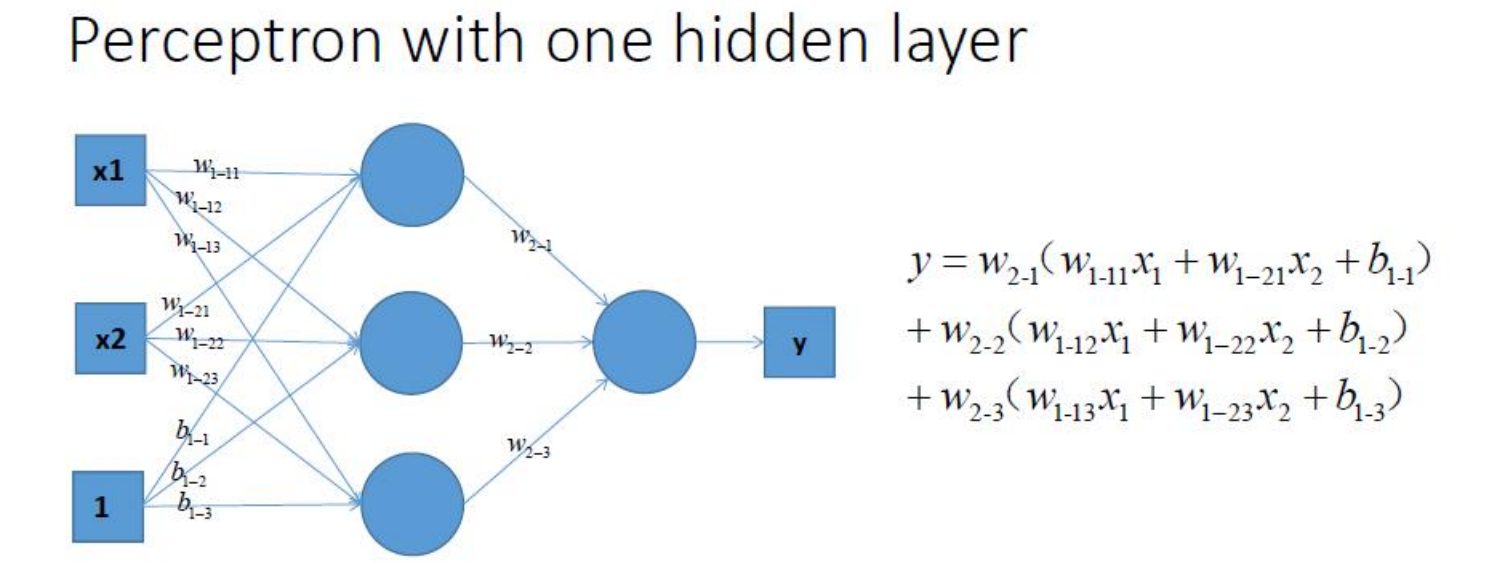
- 为什么需要使用激活函数?
- 线性模型的表达能力不够,激活函数使得神经网络可以逼近其他的任何非线性函数,这样可以使得神经网络应用到更多非线性模型中
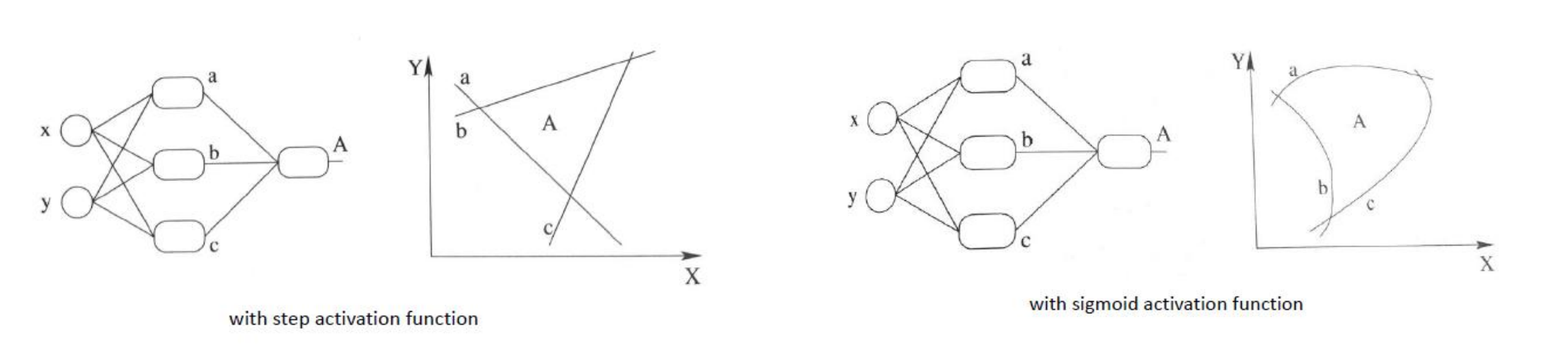
- 线性模型的表达能力不够,激活函数使得神经网络可以逼近其他的任何非线性函数,这样可以使得神经网络应用到更多非线性模型中
激活函数 sigmoid
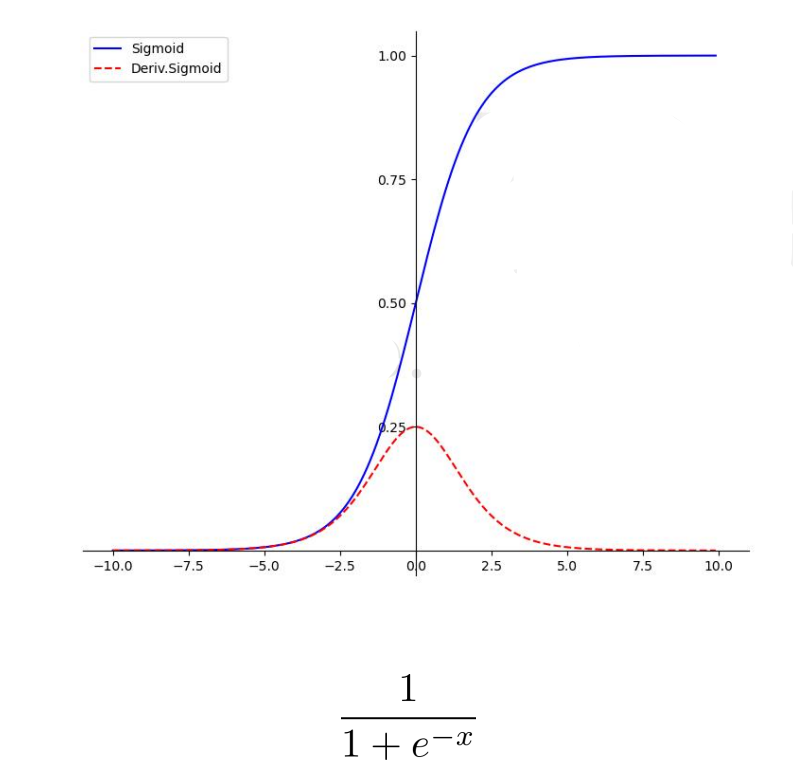
- sigmoid函数具有软饱和特性,在正负饱和区的梯度都接近于0,只在0附近有比较好的激活特性
- sigmoid导数值最大0.25,也就是反向传播过程中,每层至少有75%的损失,这使得当sigmoid被用在隐藏层的时候,会导致梯度消失(一般5层之内就会产生)
- 函数输出不以0为中心,也就是输出均值不为0,会导致参数更新效率降低;
- sigmoid函数涉及指数运算,导致计算速度较慢。
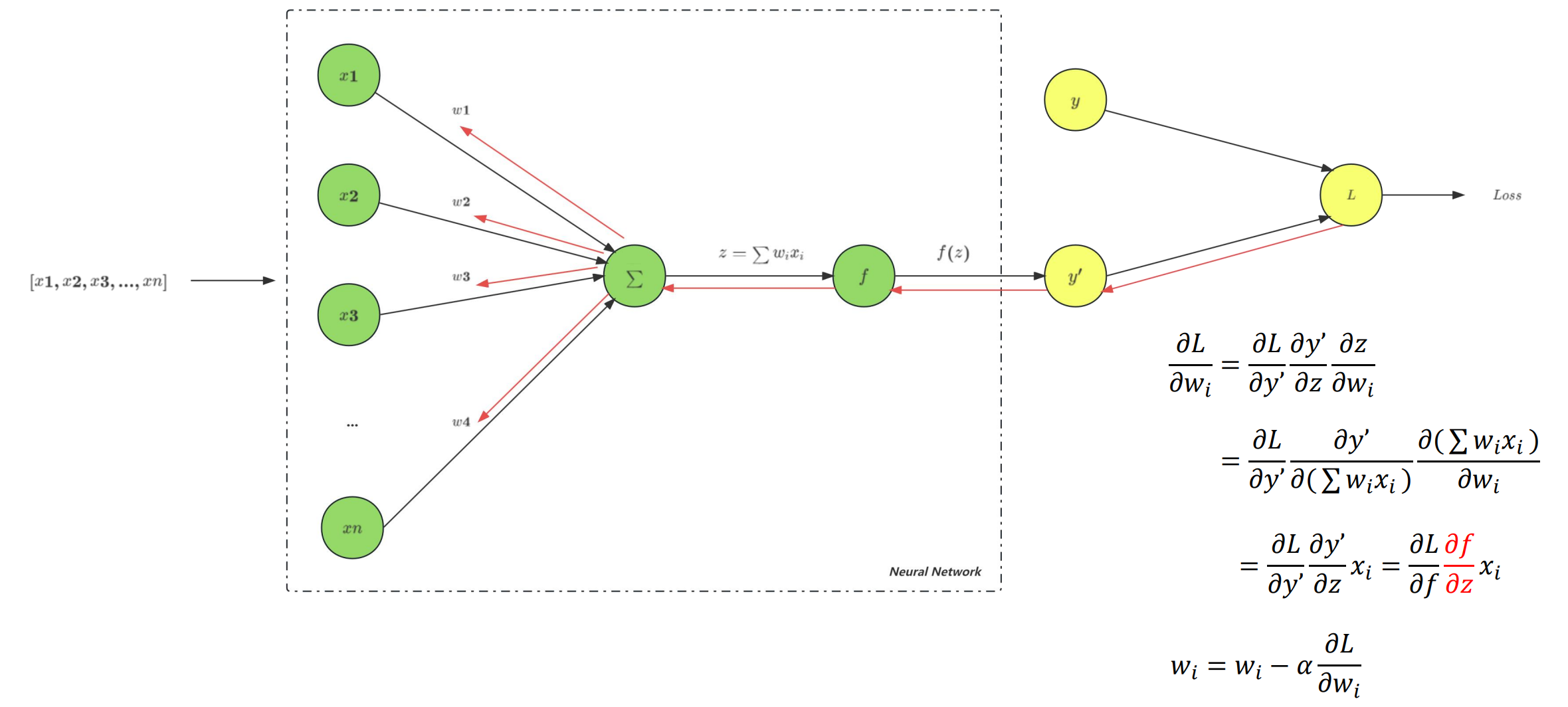
- 为什么希望激活函数输出均值为0?
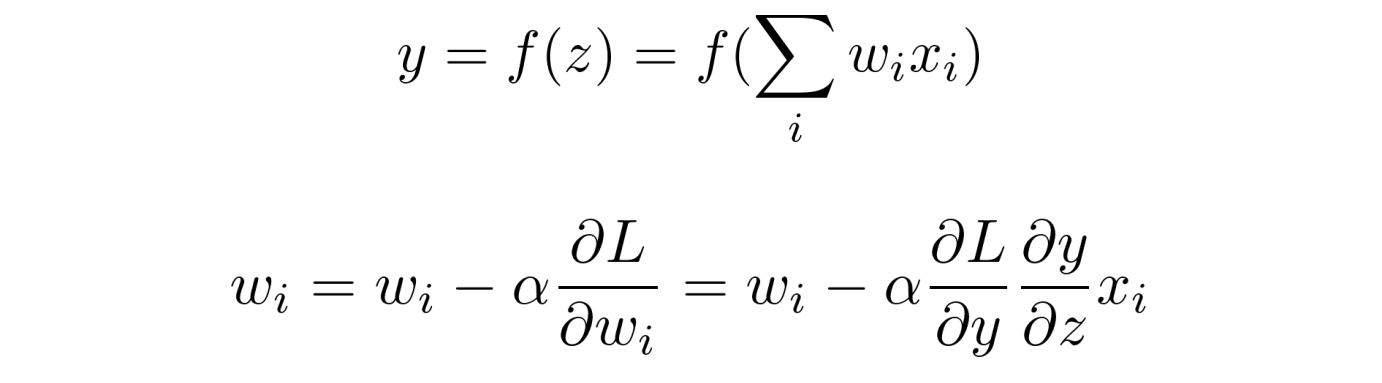
- 在上面的参数 w i w_i wi 更新公式中,对于所有 w i w_i wi 都是一样的, x i x_i xi 是 i − 1 i - 1 i−1 层的激活函数的输出,如果像 sigmoid 一样,输出值只有正值,那么对于第 i i i 层的所有 w i w_i wi ,其更新方向完全一致,模型为了收敛,会走 Z 字形来逼近最优解
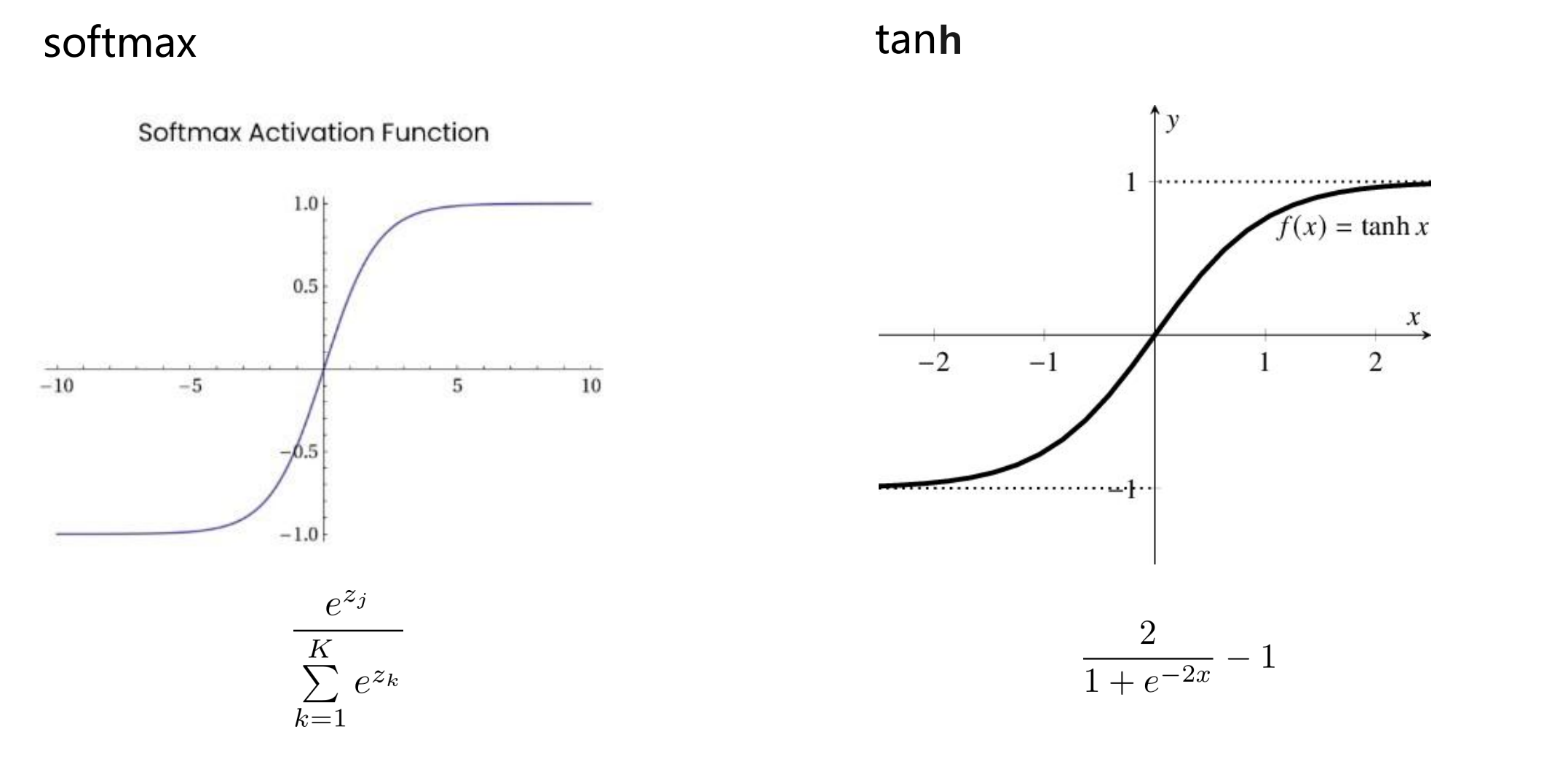
激活函数 softmax & tanh(双曲正切)
激活函数 ReLU
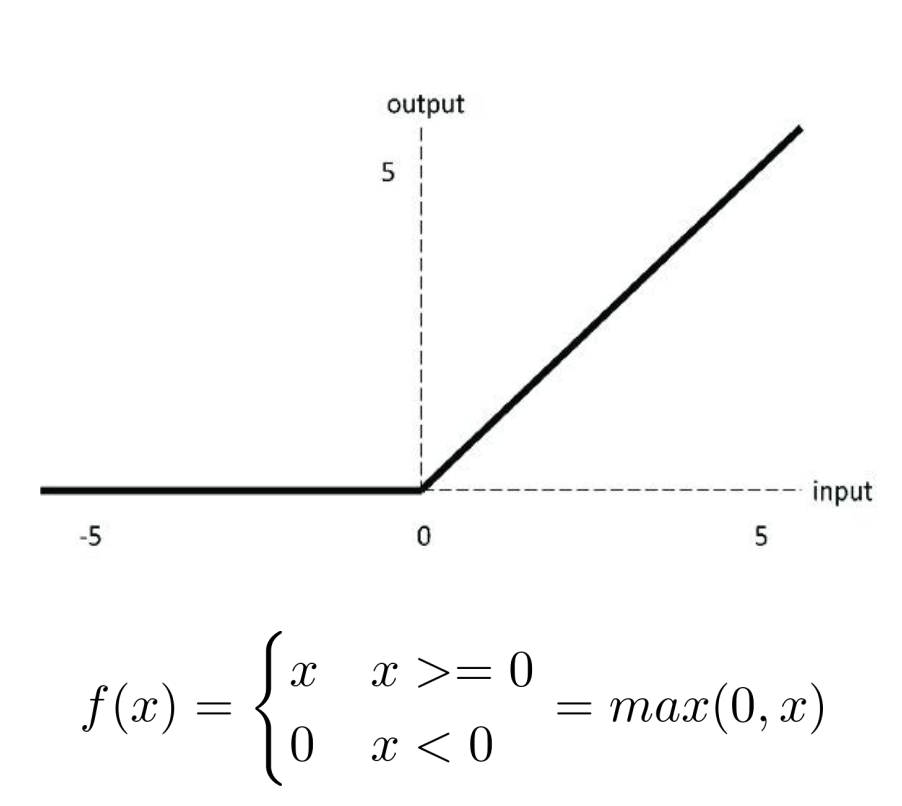
- eLU 是一个分段线性函数,因此是非线性函数;
- ReLU 的发明是深度学习领域最重要的突破之一;
- ReLU 不存在梯度消失问题;
- ReLU 计算成本低,收敛速度比 sigmoid 快6倍;
- 函数输出不以0为中心,也就是输出均值不为0,会导致参数更新效率降低;
- 存在 dead ReLU 问题(输入 ReLU 有负值时,ReLU输出为0,梯度在反向传播期间无法流动,导致权重不会更新)
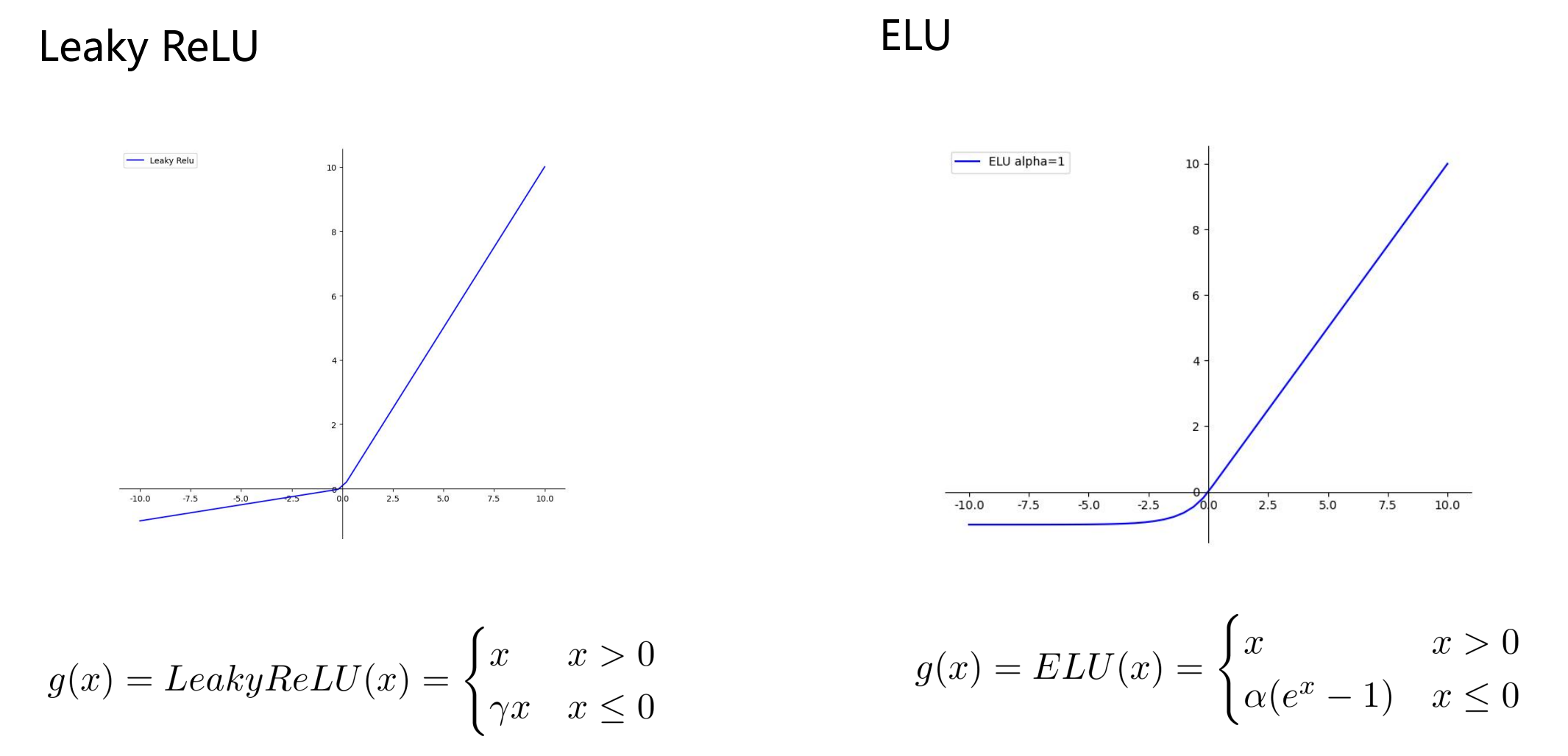
激活函数 Swish
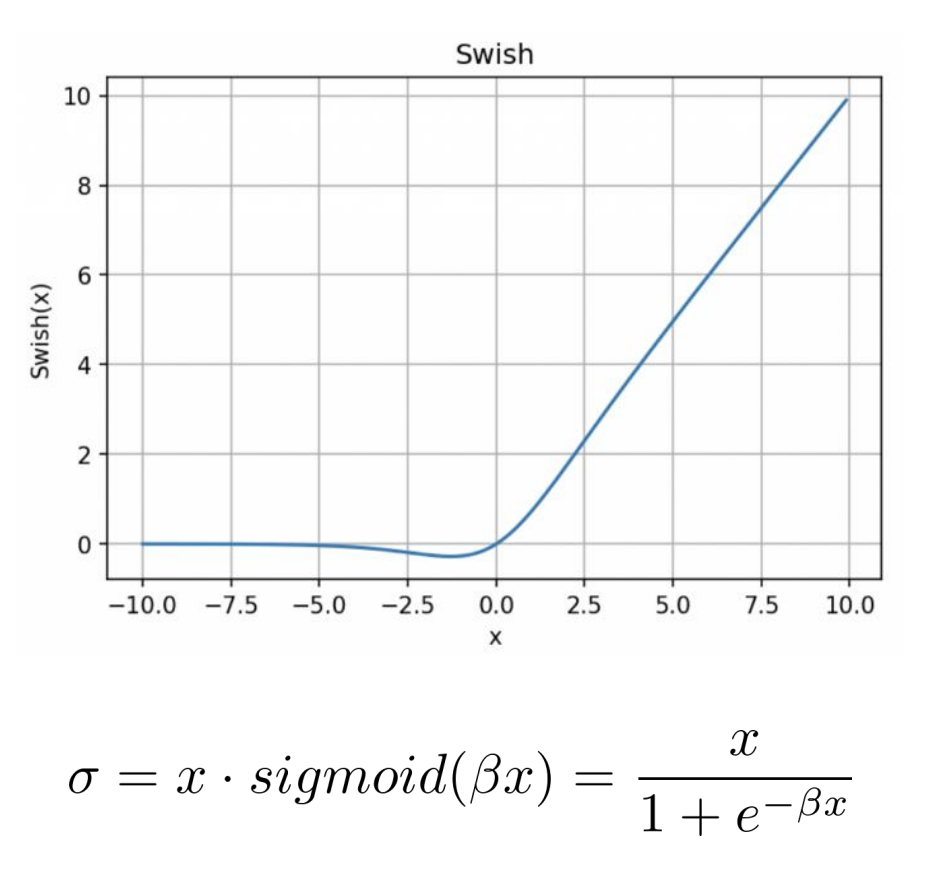
- 参数不变情况下,将模型中ReLU替换为Swish,模型性能提升;
- Swish 无上界,不会出现梯度饱和;
- Swish 有下界,不会出现 dead ReLU 问题;
- Swish 处处连续可导
损失函数
- 损失函数(loss function):用来度量模型的预测值f(x)与真实值Y的差异程度(损失值)的运算函数,它是一个非负实值函数。
- 损失函数仅用于模型训练阶段,得到损失值后,通过反向传播来更新参数,从而降低预测值与真实值之间的损失值,从而提升模型性能。
- 整个模型训练的过程,就是在通过不断更新参数,使得损失函数不断逼近全局最优点(全局最小值)
- 不同类型的任务会定义不同的损失函数,例如回归任务重的MAE、MSE,分类任务中的交叉熵损失等
MSE & M
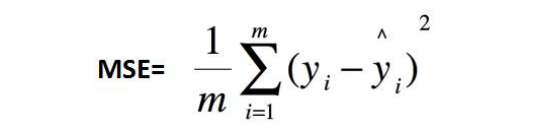
- 均方误差(mean squared error,MSE),也叫平方损失或 L2 损失,常用在最小二乘法中,它的思想是使得各个训练点到最优拟合线的距离最小(平方和最小)
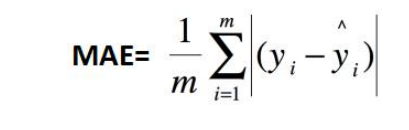
- 平均绝对误差(Mean Absolute Error,MAE)是所有单个观测值与算术平均值的绝对值的平均,也被称为 L1 loss,常用于回归问题中
交叉熵损失
-
【二分类】
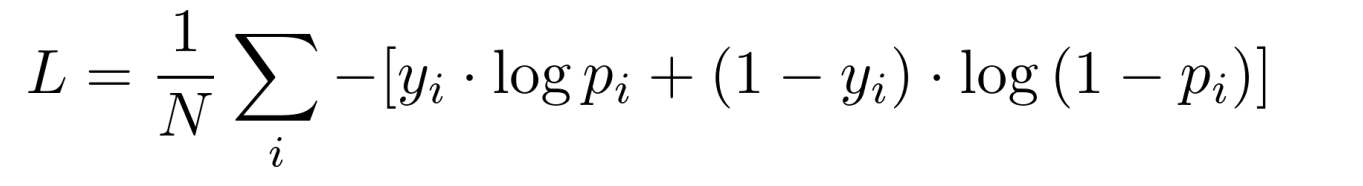
- y i y_i yi 为样本 i i i 的真实标签,正类为 1,负类为 0; p i p_i pi 表示样本 i i i 预测为正类的概率
-
【多分类】
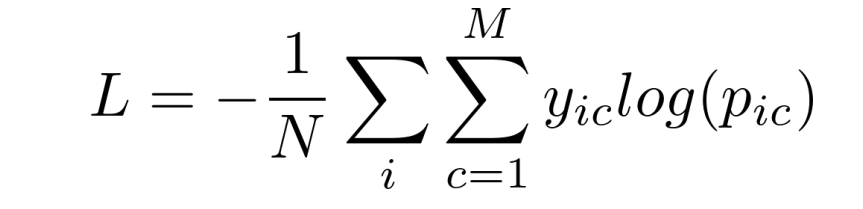
- M 为类别数量; y i c y_{ic} yic 符号函数,样本 i i i 真实类别等于 c 则为 1,否则为 0;预测样本 i i i属于类别 c 的预测概率
-
假设有一个二分类任务,正类为1,负类为0,存在一个正样本A,当模型输出其为正类的概率为0.8时,交叉熵损失为:
l o s s = − ( 1 × l o g ( 0.8 ) + 0 × l o g ( 0.2 ) ) = − l o g ( 0.8 ) = 0.0969 loss=-(1\times log(0.8)+0 \times log(0.2))=-log(0.8)=0.0969 loss=−(1×log(0.8)+0×log(0.2))=−log(0.8)=0.0969
当模型输出其为正类的概率为0.5时,交叉熵损失为:
l o s s = − ( 1 × l o g ( 0.5 ) + 0 × l o g ( 0.5 ) ) = − l o g ( 0.5 ) = 0.3010 loss=-(1\times log(0.5)+0 \times log(0.5))=-log(0.5)=0.3010 loss=−(1×log(0.5)+0×log(0.5))=−log(0.5)=0.3010 -
由此可见,当模型预测的误差越大时,交叉熵损失函数计算得到的损失越大
-
假设分类任务有3种类别A,B,C,有三个样本,其中 sample 1类型为C,smaple 2类型为B,sample 3类型为A,对于 sample 1,当模型预测概率不同时:
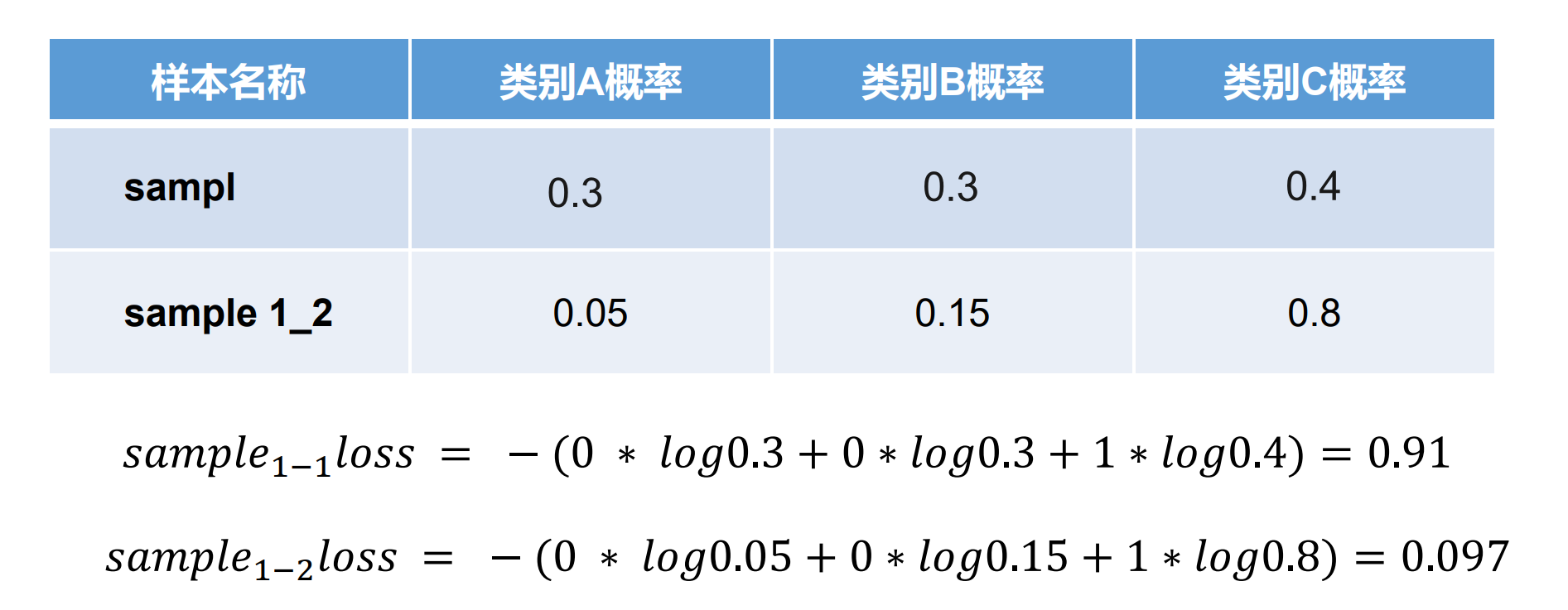
-
假设模型对这三个样本的预测概率为:
| 样本名称 | 类别A概率 | 类别B概率 | 类别C概率 |
|---|---|---|---|
| sample 1 | 0.3 | 0.3 | 0.4 |
| sample 2 | 0.3 | 0.4 | 0.3 |
| sample 3 | 0.1 | 0.2 | 0.7 |
- 交叉熵损失计算
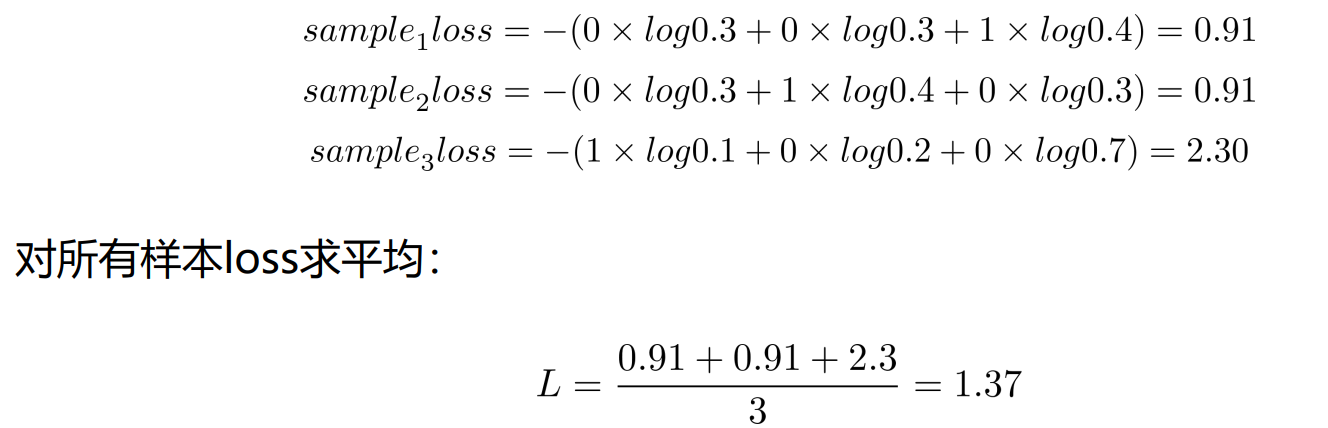
对于不同的分类任务,交叉熵损失函数使用不同的激活函数(sigmoid/softmax)获得概率输出:
- 二分类:使用sigmoid和softmax均可,注意在二分类中,Sigmoid函数,可以当作成它是对一个类别的“建模”,另一个相对的类别就直接通过1减去得到。而softmax函数,是对两个类别建模,同样的,得到两个类别的概率之和是1
- 单标签多分类:交叉熵损失函数使用softmax获取概率输出(互斥输出)
- 多标签多分类:交叉熵损失函数使用sigmoid获取概率输出
优化器
- 优化器就是在深度学习反向传播过程中,指引损失函数(目标函数)的各个参数往正确的方向更新合适的大小,使得更新后的各个参数损失函数(目标函数)值不断逼近全局最小。
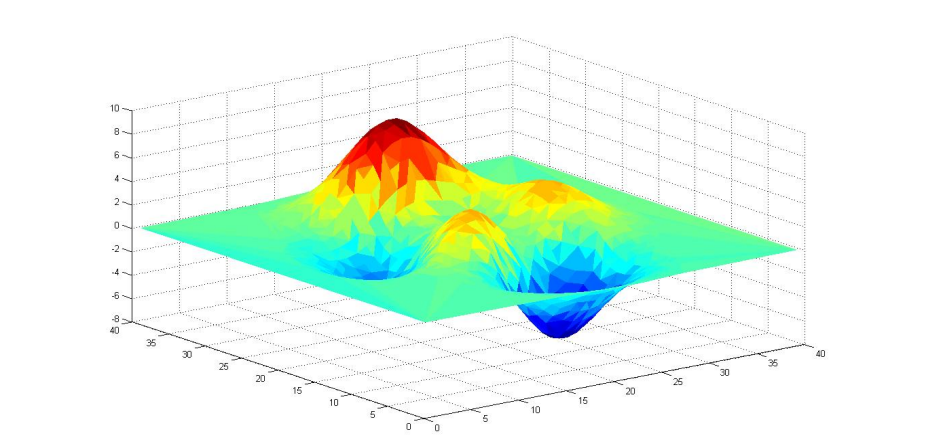
- 如果损失函数是一座山峰,优化器会通过梯度下降,帮助我们以最快的方式,从高山下降到谷底

- 梯度是一个向量,它的每一个分量都是对一个特定变量的偏导数,每个元素都指示了函数里每个变量的最陡上升方向(梯度指向函数增长最多的方向。)
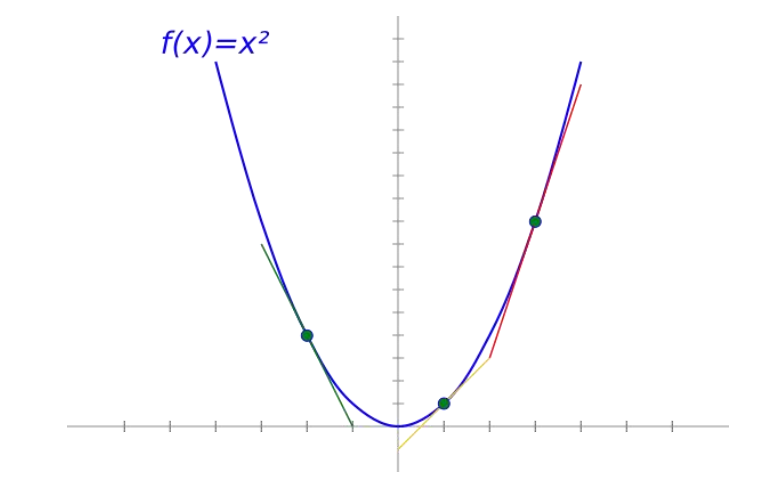
优化器 — 梯度下降
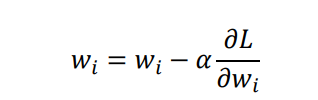
-
BGD:批量梯度下降法在全部训练集上计算精确的梯度。
-
SGD:随机梯度下降法则采样单个样本来估计的当前梯度。
-
mini-batch GD:mini-batch梯度下降法使用batch的一个子集来计算梯度。
-
为获取准确的梯度,批量梯度下降法的每一步都把整个训练集载入进来进行计算,时间花费和内存开销都非常大,无法应用于大数据集、大模型的场景。
-
随机梯度下降法则放弃了对梯度准确性的追求,每步仅仅随机采样一个样本来估计当前梯度,计算速度快,内存开销小。但由于每步接受的信息量有限,随机梯度下降法对梯度的估计常常出现偏差,造成目标函数曲线收敛得很不稳定,伴有剧烈波动,有时甚至出现不收敛的情况。
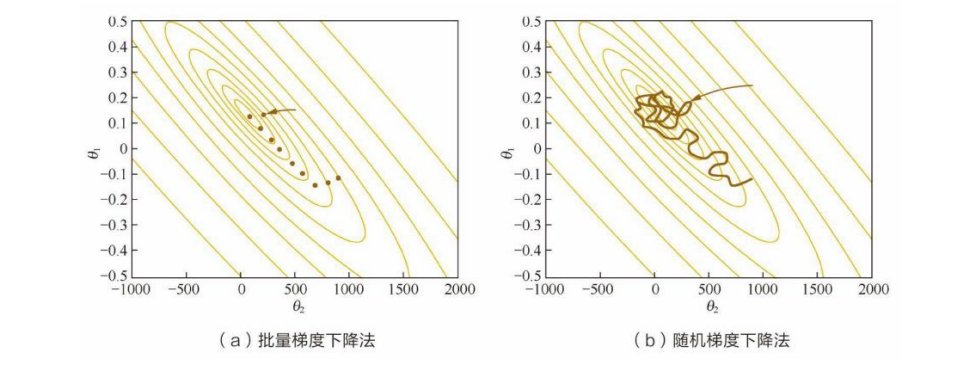
- 鉴于 BGD 和 SGD 各自的局限性,目前的训练采用 Mini-Batch GD,每次对batch_size的数据进行梯度计算,更新参数
优化器 — Momentum
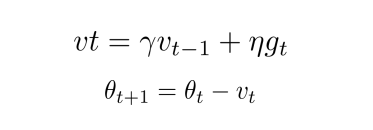
v
t
vt
vt 由两部分组成:一是学习速率
η
η
η 乘以当前估计的梯度
g
t
g_t
gt ;二是带衰减的前一次步伐
v
t
−
1
v_{t−1}
vt−1 和
g
t
g_t
gt, 而不仅仅是
g
t
g_t
gt。另外,衰减系数
γ
γ
γ 扮演了阻力的作用
优化器 — AdaGrad
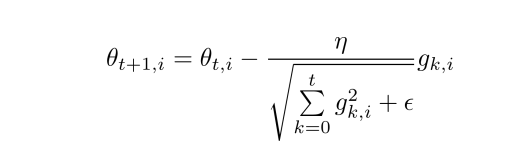
- 引入自适应思想,训练过程中,学习速率逐渐衰减,经常更新的参数其学习速率衰减更快
- AdaGrad方法采用所有历史梯度平方和的平方根做分母,分母随时间单调递增,产生的自适应学习速率随时间衰减的速度过于激进
优化器 — RMSprop
- RMSprop 是 Hinton 在课程中提到的一种方法,是对 Adagrad 算法的改进,主要是解决学习速率过快衰减的问题
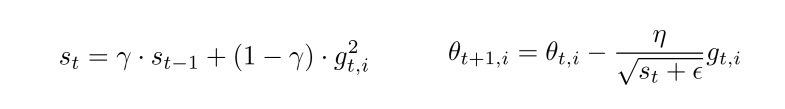
- 采用梯度平方的指数加权移动平均值,其中一般取值0.9,有助于避免学习速率很快下降的问题,学习率建议取值为0.001
优化器 — Adam
- Adam方法将惯性保持(动量)和自适应这两个优点集于一身
- Adam记录梯度的一阶矩(first moment),即过往梯度与当前梯度的平均,这体现了惯性保持:
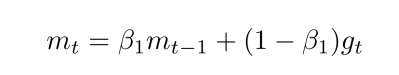
- Adam还记录梯度的二阶矩(second moment),即过往梯度平方与当前梯度平方的平均,这类似AdaGrad方法,体现了自适应能力,为不同参数产生自适应的学习速率:
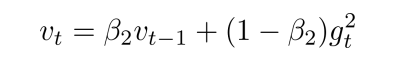
- 一阶矩和二阶矩采用类似于滑动窗口内求平均的思想进行融合,即当前梯度和近一段时间内梯度的平均值,时间久远的梯度对当前平均值的贡献呈指数衰减。
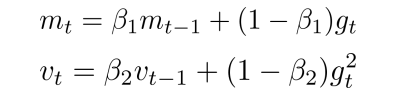
- 其中,β1,β2 为衰减系数,β1通常取值0.9,β2通常取值0.999,
m
t
m_t
mt 是一阶矩,
v
t
v_t
vt 是二阶矩阵。其中,
m
t
^
\hat{m_t}
mt^
和 v t ^ \hat{v_t} vt^ 是 m t m_t mt、 v t v_t vt 偏差矫正之后的结果
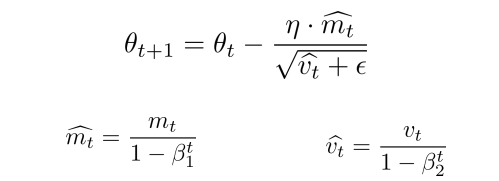
模型评估指标
回归模型
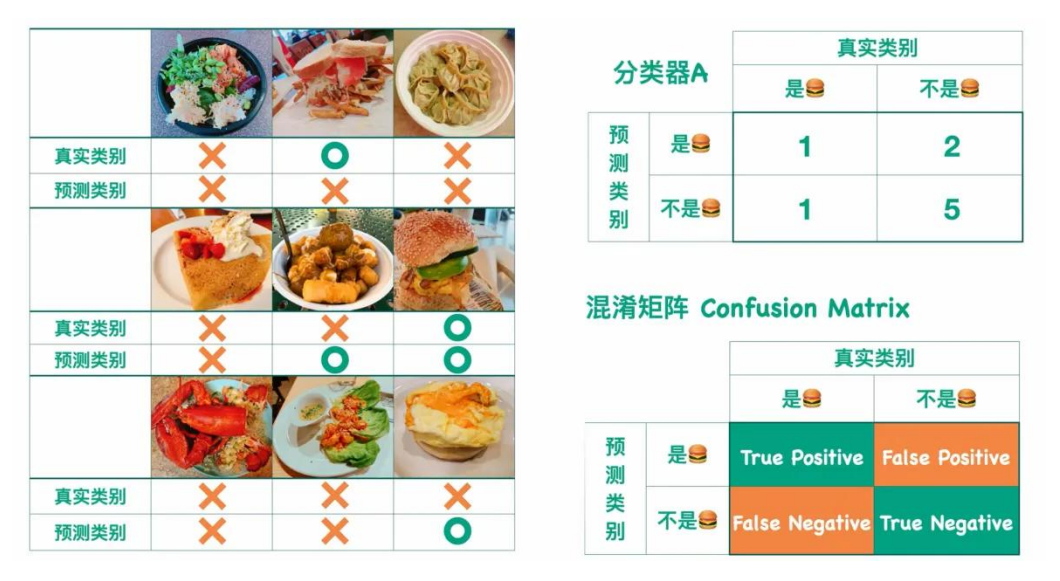
- 混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型预测的类别判断两个标准进行汇总
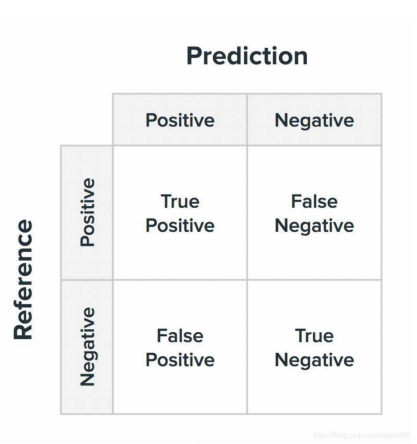
- True Positive(TP):真正类。正类被预测为正类。
- False Negative(FN):假负类。正类被预测为负类。
- False Positive(FP):假正类。负类被预测为正类。
- True Negative(TN):真负类。负类被预测为负类。
- Precision:精准率,表示预测结果中,预测为正样本的样本中,正确预测的概率
T P T P + F P \dfrac{TP}{TP+FP} TP+FPTP - Recall:召回率,表示在原始样本的正样本中,被正确预测为正样本的概率
T P T P + F N \dfrac{TP}{TP+FN} TP+FNTP - Precision值和Recall值是既矛盾又统一的两个指标,为提高Precision值,分类器需要尽量在“更有把握”时才把样本预测为正样本,但此时往往会因为过于保守而漏掉很多“没有把握”的正样本,导致Recall值降低
- F1:F1-score是Precision和Recall两者的综合,是一个综合性的评估指标
F 1 = 2 × P r e c i s i o n × R e c a l l P r e c i s i o n + R e c a l l F1=\dfrac{2 \times Precision \times Recall}{Precision + Recall} F1=Precision+Recall2×Precision×Recall - Micro-F1:不区分类别,直接使用总体样本的准召计算f1 score。
- Macro-F1:先计算出每一个类别的准召及其f1 score,然后通过求均值得到在整个样本上的f1 score。
- 数据均衡,两者均可;样本不均衡,相差很大,使用Macro-F1;样本不均衡,相差不大,优先选择Micro-F1。
-
MSE:均方误差, y i − y i ^ y_i - \hat{y_i} yi−yi^ 为真实值-预测值。MSE中有平方计算,会导致量纲与数据不一致
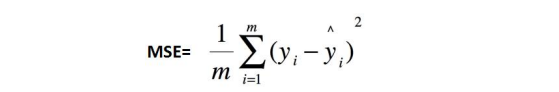
-
RMSE:均方根误差, y i − y i ^ y_i - \hat{y_i} yi−yi^ 为真实值-预测值。解决量纲不一致的问题。
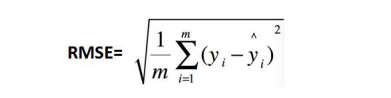
-
MAE:平均绝对误差, y i − y i ^ y_i - \hat{y_i} yi−yi^ 为真实值-预测值。
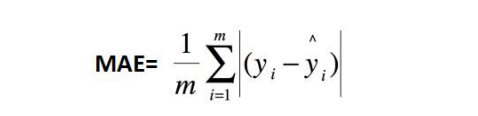
-
RMSE 与 MAE 的量纲相同,但求出结果后我们会发现RMSE比MAE的要大一些。
这是因为RMSE是先对误差进行平方的累加后再开方,它其实是放大较大误差之间的差距。而MAE反应的是真实误差。因此在衡量中使RMSE的值越小其意义越大,因为它的值能反映其最大误差也是比较小的。 -
R 2 R^2 R2
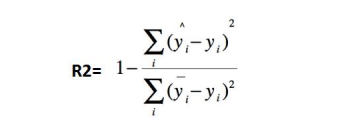
-
决定系数,分子部分表示真实值与预测值的平方差之和,类似于均方差 MSE;分母部分表示真实值与均值的平方差之和,类似于方差 Var。
-
根据 R 2 R^2 R2 的取值,来判断模型的好坏,其取值范围为 [ 0 , 1 ] [0,1] [0,1]:
-
R 2 R^2 R2 越大,表示模型拟合效果越好。 R 2 R^2 R2 反映的是大概的准确性,因为随着样本数量的增加, R 2 R^2 R2 必然增加,无法真正定量说明准确程度,只能大概定量。
-
GSB:通常用于两个模型之间的对比, 而非单个模型的评测,可以用GSB指标评估两个模型在某类数据中的性能差异
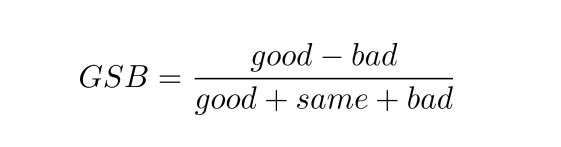
原文地址:https://blog.csdn.net/yang2330648064/article/details/137490799
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!