2024论文精读:利用大语言模型(GPT)增强上下文学习去做关系抽取任务
文章目录
GPT-RE: In-context Learning for Relation Extraction using Large Language Models
论文信息
年份: 2023
状态:arXiv
引用次数:77(截至至2024年7月20日)
是否开源:是
1. 前置知识
- ICL (In-Context Learning) 上下文学习
2. 文章通过什么来引出他要解决的问题
文章说,现在通过上下文学习 (ICL) 的大语言模型有很大的潜力,但是在关系抽取的任务上 (RE) 依旧是落后全监督的方法,所以作者提出了两个可能的问题,就是因为这两个问题导致现在的大预言模型关系抽取的精度比那些全监督的关系抽取模型还要差。这两个问题是:
- **问题一:**现有的在句子级别的示范检索方法中,与实体和关系的相关性低。
- **问题二:**缺乏对示范中输入-标签映射的解释,导致ICL的效果不佳。
- **问题三:**大模型会错误将NULL示例分类为其他预定义标签的强烈倾向。
3. 作者通过什么提出RE任务存在上面所提出的那几个问题
3.1 问题一:ICL检索到的示范中实体个关系的相关性很低。
什么是示范?
示范指的是在使用大型语言模型进行上下文学习(ICL)时,作为学习样本的示例。可以理解为提示词,这种数据通常来源于训练数据。
在别人使用大模型进行关系抽取任务的时候,示范(我个人认为是提示词)都是通过句子嵌入随机选者,或者通过KNN搜索选择。
ok?那么为什么使用上面的方法导致使用大模型进行关系抽取效果会不好呢?
作者说,基于句子嵌入的KNN检索更关注整体句子语义的相关性,而不太关注其中包含的具体实体和关系,这就导致了示范的质量较低。在这里作者举了一个例子:
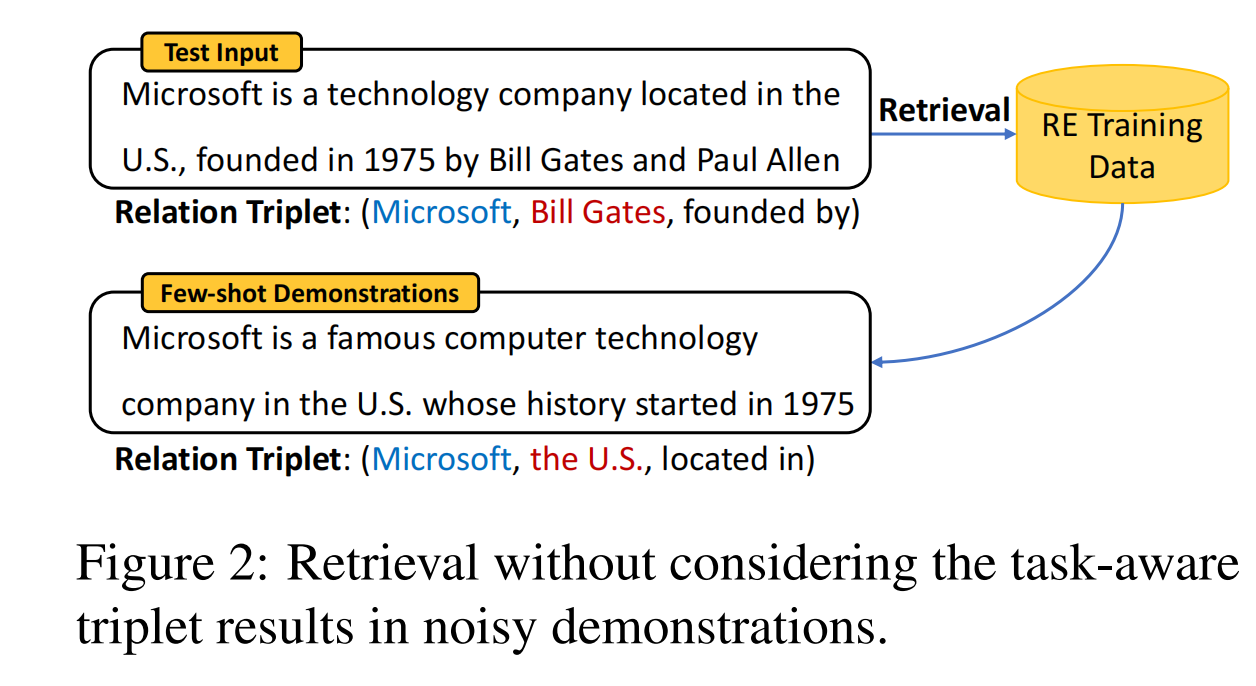
这个图片呢,就是说明了我们有一个测试输入的句子Test Input,想要使用大模型来进行关系抽取,但是,他想要使用KNN的方法从训练集中找到一些一样关系的句子,来作为提示词中的示范。但是能,由于使用句子嵌入的原因 ,导致了拿到的示范并不准确,我们输入的句子是想要找到公司和一个城市founded by的关系,但是示例呢找到的是located in的关系,这并不符合,这也导致了大模型的抽取精度不高的原因。
3.2 问题二:示范中缺乏解释输入-标签映射导致ICL效果不佳。
普通形式的ICL将所有示范列为输入-标签对,而没有任何解释。这可能会误导大型语言模型(LLMs)从表面词汇中学习浅层线索,而关系可以因语言的复杂性以多种形式呈现。特别是当ICL有最大输入长度限制时,优化每个单独示范的学习效率变得极为重要。
4. 作者为了解决上述的问题,所提出来的方法
- 解决办法一:在示范检索中引入任务感知的表示。
incorporating task-aware representations in demonstration retrieval.
核心是使用刻意编码并强调实体和关系信息的表示,而不是用于KNN检索的句子嵌入。
作者使用两种不同的检索方法实现了这一点,(1)实体题是的句子嵌入(2)经过微调的关系表示,这自然的强调了实体和关系。这两种方法都包含了比句子语义更多的RE任务所需要的特定信息,从而有效地解决了低相关性的问题。
- 解决办法二:通过金标签引导的推理逻辑丰富示范内容。
enriching the demonstrations with gold label-induced reasoning logic.
作者提议将推理逻辑注入示范中,去提供更多的证据来对齐输入和标签,这一策略类似于思维链(Chain-of-Thought)
但是作者这次使用的方式与传统的思维链不一样,他不仅解释为什么给定句子应该被归类于这样特定的标签,而且还要解释为什么NULL示例不应干被分配到任何预定义类别中。
4.1 证明作者提出的第三个问题是一个问题
作者提出了大语言模型会有过度预测的问题。
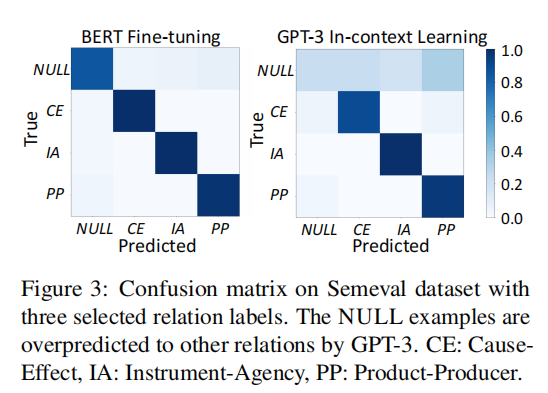
观察到大型语言模型(LLMs)有将NULL示例错误分类到其他预定义标签的强烈倾向。作者在三个流行的通用领域关系抽取(RE)数据集上评估了我们提出的方法:Semeval 2010任务8、TACRED和ACE05,以及一个科学领域数据集SciERC。我们观察到GPT-RE不仅在现有的GPT-3基准上取得了改进,而且也超过了全监督基准。具体来说,GPT-RE在Semeval和SciERC数据集上取得了最佳性能,在TACRED和ACE05数据集上也表现竞争力。
5. 实现方式
5.1 任务定义
C
C
C 表述输入的上下文,
e
s
u
b
e_{sub}
esub表示主体,
e
o
b
j
e_{obj}
eobj表示客体,以下的公式表示主体和客体之间的实体对。我们在关系抽取任务之前,会给定一组预定一个关系类别
R
R
R,关系抽取的目的就是预测上下文
C
C
C中实体对(
e
s
u
b
e_{sub}
esub,
e
o
b
j
e_{obj}
eobj)之间关系
y
y
y,并且
y
∈
R
y \in R
y∈R的,当然还有一种情况就是他们之间并没有关系,那么预测的结果就为
y
=
n
u
l
l
y=null
y=null
e
s
u
b
∈
C
e
o
b
j
∈
C
e_{sub} \in C \\ e_{obj} \in C
esub∈Ceobj∈C
5.2 概述
根据上面所提到的两个内容,作者引入了两个模块
- 模块一:任务感知的示范检索,目的是为了检索到更高精度的示范。
- 模块二:金标签的诱导推理,用来丰富每个示范中的解释。
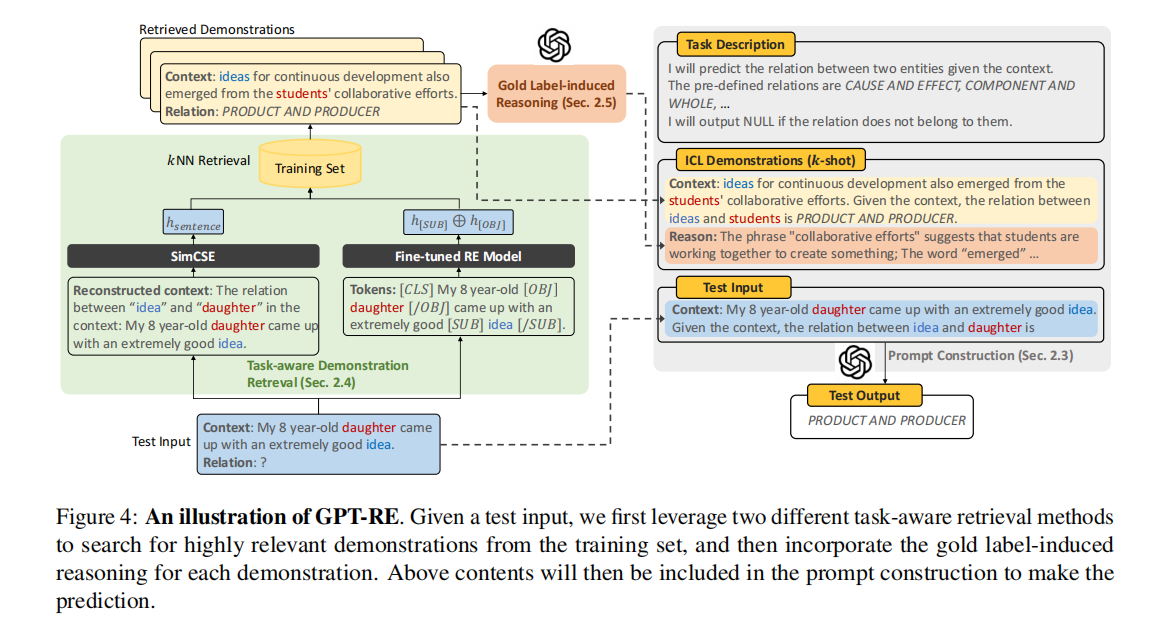
图四为整个系统的架构图。
5.3 提示构建
我们为每个测试用例都设定一个提示语,这个提示语会输入到GPT-3模型中去。每个提示会包含以下这几个部分:
**指令 I I I:**我们提供关系抽取任务描述和预定义的的类别集 R R R的简要概述,模型的明确要求输出属于预定义类别的关系。否者,模型将要输出NULL。
在框架图中为这个部分:
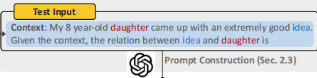
**ICL 范式 D D D:利用任务感知检索器(在5.4节中会提到)**获取 K K K次是示范集,然后用金标签诱导的推理ri丰富每个示范(xi, yi),构建新的示范集(xi, yi, ri)作为D。 测试输入 xtest:类似于示范,我们提供测试输入xtest,期望GPT-3生成相应的关系ytest。
在整个流程图中的这个环节:

说实话,这里上面讲的并不是人话,按照作者前面的意思,就是会利用训练集,然后再结合大模型,让大模型去说出为什么这个句子中的这两个实体存在这样的关系,所以往下继续看。
5.4 任务感知的示范检索
作者在上面说了KNN的效果不好,所以他提出了两种新的方法来提供更稳健的表示,用来获取更好的检索质量
- 方法一:一个初级的实体提示的句子嵌入
压根不是什么实体提示,就是重构句子,在句子之前加一句话,说两个实体之间的关系是什么。
- 方法二:一个高级的微调关系表示
这个部分在整个流程图中的这个位置:
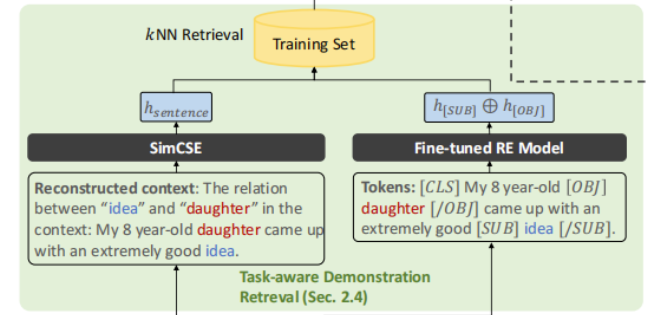
5.4.1 实体提示的句子嵌入
我们会对输入的句子进行改造
Input Text
他有一个姐没Lisa
改造后的句子
Reconstructed context:
在上下文中‘他’与‘Lisa’之间的关系:他有一个姐妹Lisa
然后,作者利用SimCSE去在训练集中找到测试句子嵌入相似度高的句子。
5.4.2 微调关系表示
个人理解:就是模仿了Bert
目前基于BERT的微调方法用于RE,试图通过添加额外的标记符号来突出主体和客体实体及其类型,从而捕捉上下文信息和实体信息。具体来说,给定一个示例:“他有一个姐妹Lisa。”,输入的标记是:
“ [ C L S ] [CLS] [CLS] [ S U B _ P E R ] [SUB\_PER] [SUB_PER]他 [ / S U B _ P E R ] [/SUB\_PER] [/SUB_PER]有一个姐妹$[OBJ_PER] L i s a Lisa Lisa[/OBJ_PER]$。[SEP]”
其中**“PER”**是提供的实体类型。假设BERT编码器的第n个隐藏表示为 h n h_n hn。假设 i i i和 j j j是两个实体标记 [ S U B _ P E R ] [SUB\_PER] [SUB_PER]和 [ O B J _ P E R ] [OBJ\_PER] [OBJ_PER]的索引,我们将关系表示定义为 R e l = h i ⊕ h j Rel = h_i ⊕ h_j Rel=hi⊕hj,其中⊕表示在第一维上的表示连接。随后,这个表示被输入到一个前馈网络中,用于预测关系概率 p ( y ∈ R ∪ N U L L ∣ R e l ) p(y ∈ R ∪ {NULL} | Rel) p(y∈R∪NULL∣Rel)。
实体标记明确编码了主体和客体实体,关系表示Rel自然地丰富了实体信息。我们认为这种方法可能弥补GPT-3在RE中的限制。虽然GPT-3 ICL的示范是有限的,但微调过程是不受限制的,可以在整个训练数据上进行。这具有两个后续优点。首先,关系表示直接微调以适应RE任务,这可能显著提高整体检索质量。其次,过度预测NULL的问题将得到大幅缓解,因为微调后的模型可以准确识别类似的NULL示例。
5.5 金标签诱导推理
就是把上一步找到的在训练集中的句子,输入给大模型中,让大模型去回答,为什么这个句子中的这两个实体是这样的一个关系。
提示词为:
What are the clues that lead to the relation between [entity1] and [entity2] to be [relation] in the sentence [context]?
生成出的内容就会拼接到[ICL范式](# 5.3 提示构建)中去
以下为论文中提出的一个例子:

6. 实验结果
肯定是很好才能发啦
7. 复现情况
即将开始
原文地址:https://blog.csdn.net/caiyongxin_001/article/details/140562360
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!