深度解析 Spark(进阶):架构、集群运行机理与核心组件详解
关联阅读博客文章:深度解析SPARK的基本概念
引言:

Apache Spark作为一种快速、通用、可扩展的大数据处理引擎,在大数据领域中备受关注和应用。本文将深入探讨Spark的集群运行原理、核心组件、工作原理以及分布式计算模型,带领读者深入了解Spark技术的内在机制和运行原理。
Spark集群模式的工作原理
Spark可以以多种方式部署在集群上,包括独立部署、YARN模式、Mesos模式等。下面将详细介绍Spark集群模式的工作原理,以Spark Standalone模式为例:
1. 架构概述
在Spark Standalone模式下,集群由一个主节点(Master)和多个工作节点(Worker)组成。主节点负责资源调度和任务分配,而工作节点负责执行任务。主节点和工作节点之间通过RPC进行通信。
2. 工作原理
2.1 主节点(Master)的工作
- 资源管理:
主节点负责管理集群中的资源,包括CPU、内存、执行器(Executor)等。它会周期性地向工作节点发送心跳消息,以监控工作节点的状态。 - 任务调度:
当有任务提交到集群时,主节点负责将任务分配给空闲的工作节点,并监控任务的执行情况。它会根据工作节点的负载情况和任务的资源需求进行动态调度,以实现资源的高效利用。 - 高可用性:
主节点可以配置为高可用模式,通过备用主节点来实现容错和故障转移。在主节点发生故障时,备用主节点会接管主节点的角色,确保集群的稳定运行。
2.2 工作节点(Worker)的工作
-
资源分配:
工作节点向主节点注册,并报告自身的资源情况。主节点根据工作节点的资源容量和负载情况来分配任务,并启动执行器(Executor)来执行任务。 -
任务执行:
工作节点启动的执行器负责执行任务,包括加载数据、执行计算、生成结果等。执行器会在工作节点上启动一个或多个线程来并行执行任务,以提高计算性能。 -
心跳监测:
工作节点定期向主节点发送心跳消息,以汇报自身的状态和资源使用情况。主节点根据心跳消息来监控工作节点的健康状况,并根据需要进行调度和资源重分配。
3. 任务调度与执行流程
- 用户提交任务到Spark集群。
- 主节点接收到任务请求,并进行资源分配和调度,将任务分配给空闲的工作节点。
- 工作节点启动执行器,并在执行器中执行任务。
- 执行器从存储系统(如HDFS)中加载数据,进行计算,并将结果写回存储系统。
- 执行器定期向主节点发送心跳消息,汇报任务执行情况和资源使用情况。
- 主节点根据心跳消息监控工作节点的状态,并根据需要进行任务重分配和资源调度。
集群模式概述
Spark 应用程序作为集群上独立的进程集运行,由SparkContext 主程序(称为驱动程序)中的对象进行协调。
具体来说,为了在集群上运行,SparkContext 可以连接到多种类型的集群管理器 (Spark 自己的独立集群管理器、Mesos、YARN 或 Kubernetes),这些集群管理器跨应用程序分配资源。连接后,Spark 会获取集群中节点上的执行程序,这些执行程序是为应用程序运行计算和存储数据的进程。接下来,它将您的应用程序代码(由传递到 SparkContext 的 JAR 或 Python 文件定义)发送到执行器。最后,SparkContext将任务发送给执行器来运行。
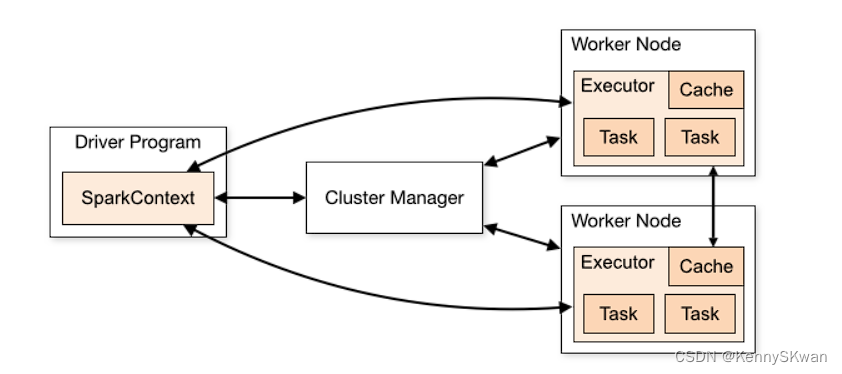
关于此架构,有几个有用的事项需要注意:
- 每个应用程序都有自己的执行程序进程,这些进程在整个应用程序的持续时间内保持运行并在多个线程中运行任务。这样做的好处是可以在调度端(每个驱动程序调度自己的任务)和执行器端(来自不同应用程序的任务在不同的 JVM 中运行)将应用程序彼此隔离。但是,这也意味着如果不将数据写入外部存储系统,则无法在不同的 Spark 应用程序(SparkContext 实例)之间共享数据。
- Spark 对于底层集群管理器是不可知的。只要它能够获取执行程序进程,并且这些进程相互通信,即使在也支持其他应用程序(例如Mesos/YARN/Kubernetes)的集群管理器上运行它也相对容易。
- 驱动程序必须在其整个生命周期中侦听并接受来自其执行程序的传入连接(例如,请参阅网络配置部分中的spark.driver.port)。因此,驱动程序必须可从工作节点进行网络寻址。
- 由于驱动程序在集群上调度任务,因此它应该靠近工作节点运行,最好在同一局域网上。如果您想远程向集群发送请求,最好向驱动程序打开 RPC 并让它从附近提交操作,而不是在远离工作节点的地方运行驱动程序。
集群管理器类型
系统目前支持多种集群管理器:
- Standalone ——Spark 附带的一个简单的集群管理器,可以轻松设置集群。
- Apache Mesos – 通用集群管理器,还可以运行 Hadoop MapReduce 和服务应用程序。 (已弃用)
- Hadoop YARN – Hadoop 3 中的资源管理器。
- Kubernetes – 一个用于自动化部署、扩展和管理容器化应用程序的开源系统。
Spark 是如何工作的?
这是Spark架构的详细图。
来源
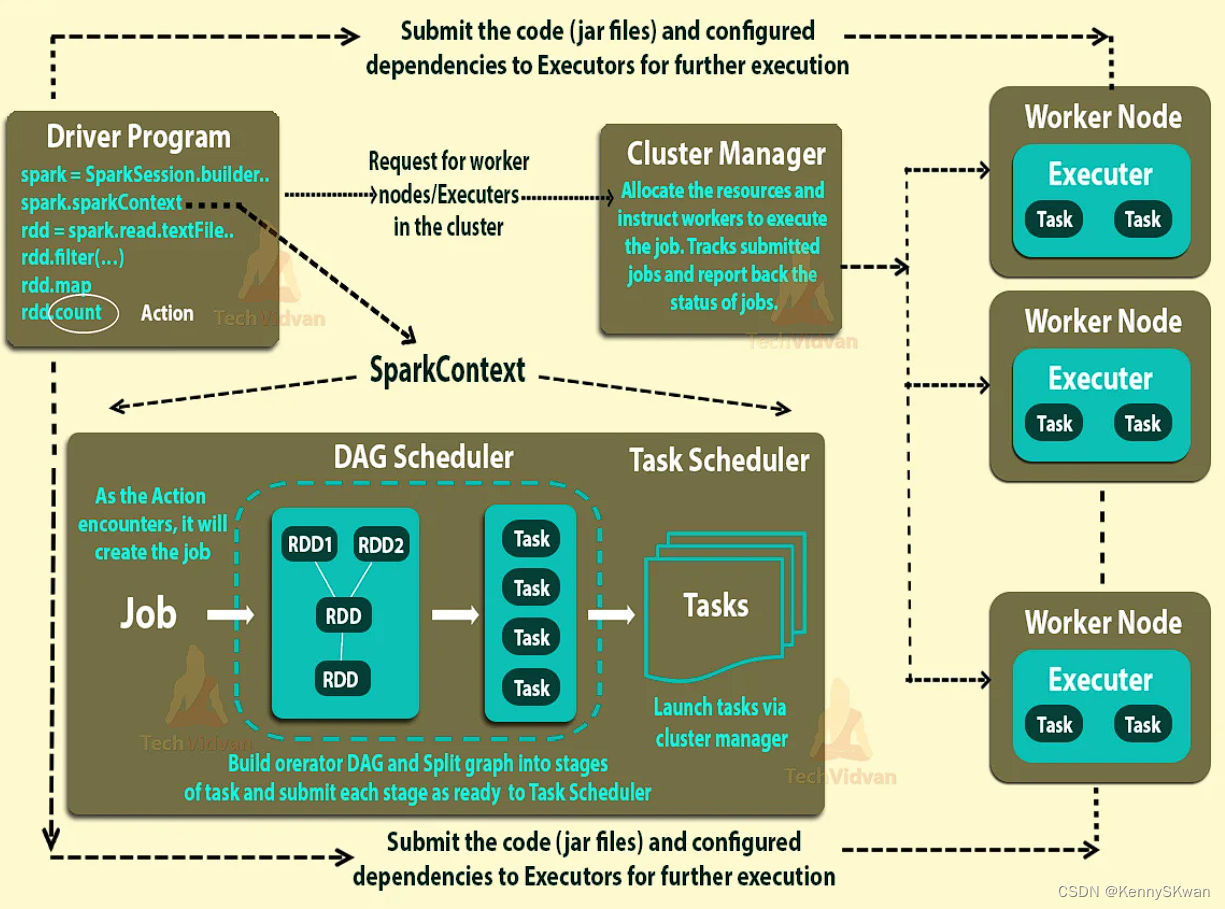
当作业进入时,驱动程序将代码转换为逻辑有向无环图 (DAG)。然后,驱动程序执行某些优化,例如管道转换。
此外,它将 DAG 转换为具有阶段集的物理执行计划。同时,它在每个阶段下创建称为任务的小型执行单元。然后它收集所有任务并将其发送到集群。
它是与集群管理器对话并协商资源的驱动程序。此集群管理器代表驱动程序启动执行程序后。此时,基于数据,放置驱动程序将任务发送到集群管理器。
在执行器开始执行之前,执行器将自己注册到驱动程序中。使驱动程序拥有所有执行者的整体视图。
现在,Executors 执行 driver 分配的所有任务。同时,应用程序运行时,驱动程序监视运行的执行器。在spark架构中驱动程序调度未来的任务。
所有任务都根据数据放置来跟踪缓存数据的位置。当它调用sparkcontext的stop方法时,它会终止所有的执行器。之后,它从集群管理器中释放资源。
Spar的核心组件
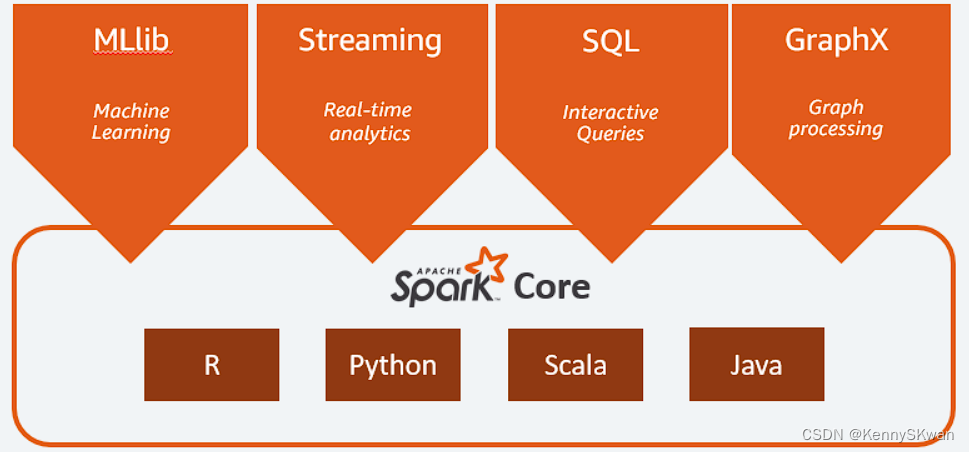
Spark 框架包括:
- Spark Core 是该平台的基础
- 用于交互式查询的 Spark SQL
- 用于实时分析的 Spark Streaming
- 用于机器学习的 Spark MLlib
- 用于图形处理的 Spark GraphX
1. Spark Core
Spark Core是Spark生态系统的核心模块,提供了分布式任务调度、内存管理、错误恢复和与存储系统交互的功能。其主要特性包括:
- RDD(Resilient Distributed Dataset):
RDD是Spark中最基本的抽象,代表一个不可变、可分区、可以并行操作的数据集。RDD可以通过读取外部数据源(如HDFS、HBase、本地文件等)或在其他RDD上进行操作来创建。 - 分布式任务调度:
Spark Core使用基于DAG(有向无环图)的任务调度模型来执行计算任务。它将用户程序转换为DAG图,根据依赖关系并行执行任务。 - 内存计算:
Spark Core充分利用内存计算技术,将中间数据存储在内存中,从而大大提高了计算速度。此外,Spark还提供了可配置的内存管理机制,使用户可以根据应用程序的特点进行调优。
2.Spark Streaming
Spark Streaming是Spark提供的用于实时流数据处理的组件,可以实现对持续不断的数据流进行实时计算和分析。Spark Streaming 是核心 Spark API 的扩展,可实现实时数据流的可扩展、高吞吐量、容错流处理。数据可以从许多来源(如 Kafka、Kinesis 或 TCP 套接字)获取,并且可以使用用高级函数(如 map、reduce、join 和 window)表示的复杂算法进行处理。最后,处理后的数据可以推送到文件系统、数据库和实时仪表板。事实上,您可以将Spark的 机器学习和 图处理算法应用在数据流上。

在内部,它的工作原理如下。 Spark Streaming接收实时输入数据流,并将数据分成批次,然后由Spark引擎处理以批次生成最终结果流。
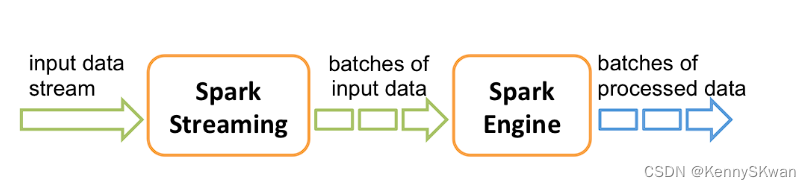
Spark Streaming 提供了称为离散流或DStream的高级抽象,它表示连续的数据流。 DStream 可以通过来自 Kafka 和 Kinesis 等源的输入数据流创建,也可以通过在其他 DStream 上应用高级操作来创建。在内部,DStream 表示为RDD序列 。
其主要特性包括:
-
微批处理:
Spark Streaming将实时数据流分成小批次进行处理,每个批次的数据都可以作为一个RDD进行处理。这种微批处理的方式既保证了低延迟,又兼顾了高吞吐量。 -
容错性:
Spark Streaming具有与Spark Core相同的容错性,能够在节点故障时进行数据恢复和任务重启,保证数据处理的可靠性。
建议结合阅读官方文档以加深对 Spark Streaming的理解。
Spark 流编程指南
3.Spark SQL
Spark SQL 是 Spark 生态系统中的一个组件,用于结构化数据的处理和分析。它提供了 SQL 查询、DataFrame API、集成外部数据源等功能,使用户可以使用标准的 SQL 语句或编程接口来处理大规模的结构化数据。下面将详细展开 Spark SQL 的特点、组成部分以及应用场景。
特点
- 结构化数据处理
Spark SQL 专注于结构化数据的处理,支持将数据加载为 DataFrame,并提供了丰富的操作和转换,如选择、过滤、聚合、连接等。 - SQL 查询支持
Spark SQL 提供了对标准 SQL 查询语句的支持,用户可以直接在 Spark 中执行 SQL 查询,对数据进行查询、筛选、聚合等操作,无需编写复杂的代码。 - DataFrame API
除了 SQL 查询之外,Spark SQL 还提供了 DataFrame API,使用户可以使用类似于 Pandas 的编程接口来操作数据。DataFrame API 提供了丰富的函数和操作,可以完成各种数据处理任务。 - 外部数据源集成
Spark SQL 支持与多种外部数据源的集成,包括 HDFS、Hive、JDBC、Parquet、Avro 等。用户可以轻松地从这些数据源中读取数据,并进行处理和分析。
组成部分
-
Catalyst 查询优化器:
Catalyst 是 Spark SQL 中的查询优化器,负责将 SQL 查询转换为适用于 Spark 的执行计划,并对执行计划进行优化。它采用了基于规则和代价模型的优化策略,可以大大提高查询性能。 -
Tungsten 执行引擎:
Tungsten 是 Spark SQL 中的执行引擎,负责执行查询计划并进行数据处理。它采用了基于内存的列存储和代码生成技术,可以大大提高数据处理的速度和效率。 -
Hive 兼容性:
Spark SQL 兼容 Hive,可以直接读取 Hive 表并执行 HiveQL 查询。它还支持将 Hive UDF(User Defined Function)注册为 Spark SQL 函数,从而实现更丰富的数据处理功能。
4.MLlib(机器学习库)
MLlib是Spark生态系统中的机器学习库,提供了丰富的机器学习算法和工具,可以用于数据挖掘、预测分析、分类、聚类等任务。MLlib的设计目标是实现可扩展性、易用性和高性能,使得用户能够在大规模数据集上进行高效的机器学习计算。
特性
- 可扩展性
MLlib采用了分布式并行计算模型,可以在大规模数据集上进行高效的机器学习计算。它利用了Spark的RDD(Resilient Distributed Dataset)数据抽象和并行计算引擎,实现了对数据的分布式处理和算法的并行执行,从而能够处理PB级别的数据集。 - 易用性
MLlib提供了简单易用的API,使得用户可以轻松地构建和调整机器学习模型。它提供了丰富的机器学习算法和工具,并支持常见的数据格式,如RDD、DataFrame等,同时也提供了丰富的文档和示例,帮助用户快速上手和解决问题。 - 高性能
MLlib的底层实现采用了高效的并行计算算法和数据结构,能够充分利用集群的计算资源,并通过优化算法和数据处理流程来提高计算性能。此外,MLlib还支持在内存中进行计算,可以大大提高计算速度。
主要组成部分
-
分类与回归
MLlib提供了一系列的分类和回归算法,包括逻辑回归、决策树、随机森林、梯度提升树等。这些算法可以用于解决分类和回归问题,如预测用户点击率、预测房价等。 -
聚类
MLlib提供了多种聚类算法,如K均值、高斯混合模型等。这些算法可以用于将数据集划分成若干个类别,并找出类别之间的相似性和差异性。 -
协同过滤
MLlib提供了基于协同过滤的推荐算法,如交替最小二乘法(ALS)等。这些算法可以用于构建推荐系统,预测用户对商品的喜好程度,从而实现个性化推荐。 -
降维与特征提取
MLlib提供了多种降维和特征提取算法,如主成分分析(PCA)、奇异值分解(SVD)等。这些算法可以用于减少数据维度、提取数据特征,从而简化模型和提高计算效率。 -
模型评估与调优
MLlib提供了多种模型评估和调优的工具,如交叉验证、网格搜索等。这些工具可以帮助用户评估模型的性能、选择合适的参数,并优化模型的预测能力。
5.GraphX(图计算库)
GraphX 是 Spark 中用于图和图并行计算的新组件。在较高层面上,GraphX通过引入新的图抽象来扩展 Spark RDD:一个具有附加到每个顶点和边的属性的有向多重图。为了支持图计算,GraphX 公开了一组基本运算符(例如subgraph、joinVertices和 aggregateMessages)以及Pregel API 的优化变体。此外,GraphX 还包含越来越多的图形算法和 构建器,以简化图形分析任务。
特点
- 高级抽象
GraphX 提供了一种高级抽象的方式来表示图数据,将图抽象为顶点和边的集合,并支持属性的附加。用户可以通过简单的 API 来构建和操作图数据,而无需关注底层的数据结构和实现细节。 - 并行计算
GraphX 利用 Spark 的分布式计算模型来实现图的并行计算,可以在大规模数据集上高效地进行图算法的计算。它将图划分成多个分区,并利用并行计算技术来加速计算过程,提高计算性能。 - 容错性
GraphX 具有与 Spark Core 相同的容错性,能够在节点故障时进行数据恢复和任务重启,保证图计算的可靠性。它利用 RDD 的弹性特性和日志记录来实现容错机制,确保计算的正确性和一致性。
组成部分
- 图抽象
GraphX 将图抽象为顶点(Vertex)和边(Edge)的集合,每个顶点和边都可以附加属性。用户可以通过构建顶点和边的集合来创建图对象,并对图进行操作和转换。 - 图操作
GraphX 提供了丰富的图操作和转换,如图的连接、过滤、映射、聚合等。用户可以使用这些操作来对图进行数据处理和分析,如查找最短路径、计算图的连通分量等。 - 图算法
GraphX 实现了多种常见的图算法,如 PageRank、图搜索、最短路径算法等。用户可以直接调用这些算法来解决图相关的问题,而无需自己实现复杂的算法逻辑。
建议结合阅读官方文档以加深对 GraphX 的理解。
GraphX 编程指南
原文地址:https://blog.csdn.net/qq_42963855/article/details/137720906
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!