固本培元!盛派 AI 调用本地大模型
一、引言
连续几期和大家分享了基于纽插 NeuCharAI(NeuChar)的免费算力(若您还未领取,敬请联系小嗨)进行盛派 AI 相关应用(请见前几期分享文章,文章下面合集可查看)打造后,有的朋友们提出来,我们可以用本地算力么?我们由于种种原因,只能用本地算力。好的,那么本期我们就一起揭开本地大模型与盛派 AI 结合使用的神秘面纱~
1、什么是本地大模型?
本地大模型是指将大型语言模型(LLM)或其他类型的深度学习模型在本地计算环境中(如个人电脑、公司服务器或本地数据中心)运行,而不是通过云服务调用。例如,像通义千问、智谱清言等开源大模型可以部署到本地机器上运行。
2、为什么要用本地大模型?
✔️数据隐私和安全:本地部署的大模型可以确保数据不离开本地网络,尤其对于涉及敏感信息的企业或项目,使用本地大模型可以有效减少数据泄露的风险。某些应用需要处理高度敏感的个人或商业数据,如医疗记录、金融信息或知识产权数据。离线部署可以确保这些数据不离开本地环境,减少泄露的风险。一些行业和地区对数据保护有严格的法规和要求(如 GDPR),要求数据必须在本地存储和处理。
✔️离线运行:本地模型不依赖云服务,允许在断网或网络不稳定的情况下继续使用。本地部署可以在没有互联网连接的情况下工作,适合在网络连接不稳定或不可用的环境中使用,如远程或边缘设备。这对于远程或偏远地区的应用非常有用。依赖云服务可能会遇到服务中断或限制,本地部署可以提供更高的可用性和可靠性。
✔️自定义优化:在本地部署模型允许更高的定制化。你可以针对特定的硬件进行优化,或调整模型结构和参数,以满足特定应用需求,提升性能和精度。在本地部署中,你可以自由地实验新的技术和方法,而不受云服务提供商的限制。这对前沿研究和开发特别重要。
✔️节省成本:如果频繁使用大模型,长时间调用云服务会产生高昂的费用。而使用本地大模型,除了初期部署和硬件投入之外,后期几乎没有运行成本。
✔️控制和灵活性:本地大模型可以完全根据需要调控,不受云服务商的限制或更新频率影响。你可以选择何时升级模型,如何处理模型输入输出等。使用云服务时,费用可能会因使用量波动而不可预测。离线部署能够提供更稳定的成本控制。
总结来说,本地大模型的使用可以提升数据隐私、安全性、自定义性,同时减少长期的运行成本,但需要足够的硬件资源和技术支持。当然也适用于有些工作环境只能使用内网的情况!!!
3、如何使用本地大模型
1、硬件准备: 大模型通常需要大量的计算资源,尤其是 GPU 和内存。部署本地大模型需要确保你的机器有足够的算力,通常建议使用具有多核 CPU、大容量内存和 GPU(如 NVIDIA 的 GPU,支持 CUDA 加速),以及 NPU(如华为昇腾的 NPU,支持 CANN 加速)的服务器。
2、模型下载: 许多大模型已经开源,用户可以从开源社区下载。例如,Meta 的 LLaMA、EleutherAI 的 GPT-NeoX、Hugging Face 上托管的各种模型等。你可以通过这些平台下载预训练模型。
当前我们可以从国内外很多开源平台获取开源大模型,例如:
☑️阿里的魔塔社区 (魔搭社区 )
☑️ 华为云 AI Gallery (AI Gallery_模型_开发者_华为云 )
☑️ ollama 的模型库 (library )
☑️ 昇腾 ModelZoo (LLM语言大模型-昇腾大模型平台-昇腾社区 )
3、安装依赖:需要安装相应的深度学习框架,如TensorFlow、PyTorch 或 MindSpore(昇腾国产开源)。这些框架提供了加载、运行和优化模型的基础工具。
4、模型部署:根据框架加载模型,并设置推理环境。例如,在 PyTorch 中可以用 torch.load 函数加载模型权重,然后通过 model.forward() 来进行推理。
5、推理和调用:部署完成后,你可以通过 API 或命令行工具将输入数据传递给模型进行推理。推理的结果可以集成到本地应用中,如聊天机器人、语音识别系统、图像生成应用等。
6、优化和调优:在本地运行大模型时,可能需要对硬件资源进行调优,例如批量大小的选择、显存优化、混合精度训练等,以便更高效地使用计算资源。
7、持续更新:虽然是本地部署,但仍可以保持与模型开发社区的互动,及时获取模型更新或改进,并根据需要更新本地大模型。
P.S:想想部署起来就很复杂吧~ 何况我们还要基于他们做应用~
您别急,让盛派 AI 来帮您忙!
02
盛派 AI 调用本地大模型
1、什么是盛派 NeuCharFramework(NCF)
NeuCharFramework(NCF) 是一整套可用于构建基础项目的框架,包含了基础的缓存、数据库、模型、验证及配套管理后台,高度模块化,严格遵循 DDD 设计模式,具有高度的可扩展性。

NCF 项目地址(https://github.com/NeuCharFramework/NCF)
本篇分享我们也将使用 NCF 项目来进行 Demo 介绍。
NeuCharFramework(NCF) 框架已经默认集成 Senparc.Xncf.AIKernel,
本地大模型管理可无需修改任何代码,直接使用。
故我们只需要在本地部署好大模型,并获取到 NCF 项目的代码,即可结合盛派 AI 提示词靶场,体验在本地部署大模型进行打靶啦~
那么接下来我们将结合 NCF 项目来带着大家一起感受一下!
注意:
关于本地大模型部署:这里我们采用 Ollama 来作为部署工具。
2、盛派 AI 调用本地大模型
P.S.如果您是第一次使用 NCF,请继续跟着文章进行 NCF 的源码获取和基础模块的搭建;如您已经操作过我们前期的分享,请移步到第 3 步骤。
1、获取并运行盛派 NCF 项目
NCF 项目地址https://github.com/NeuCharFramework/NCF
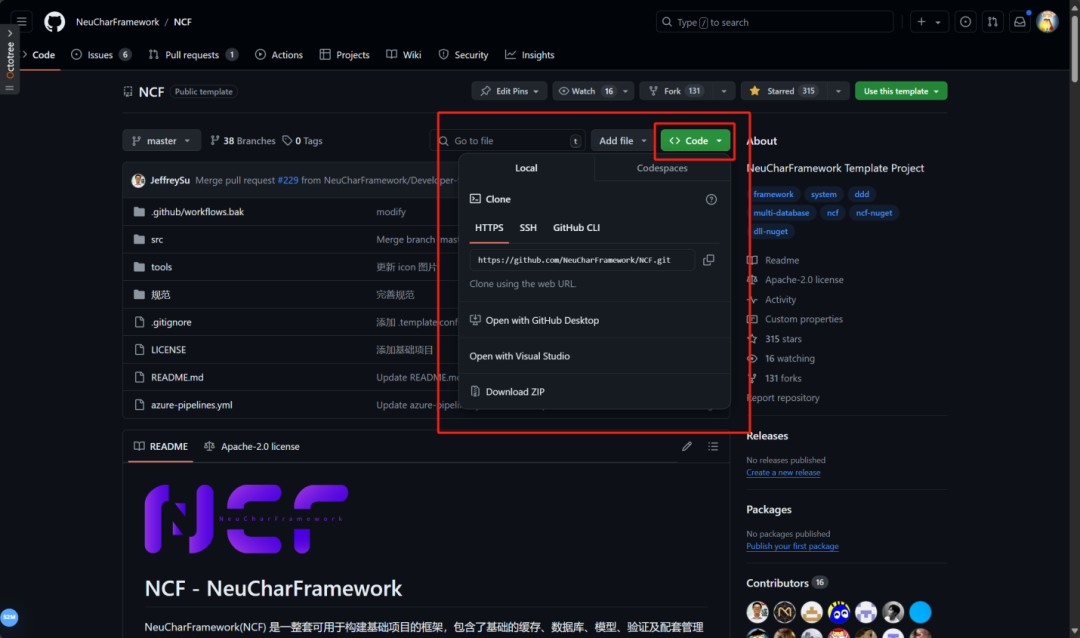
然后我们可以使用 git 工具对仓库进行获取
git clone https://github.com/NeuCharFramework/NCF.git
或者直接下载打包好的 zip 文件
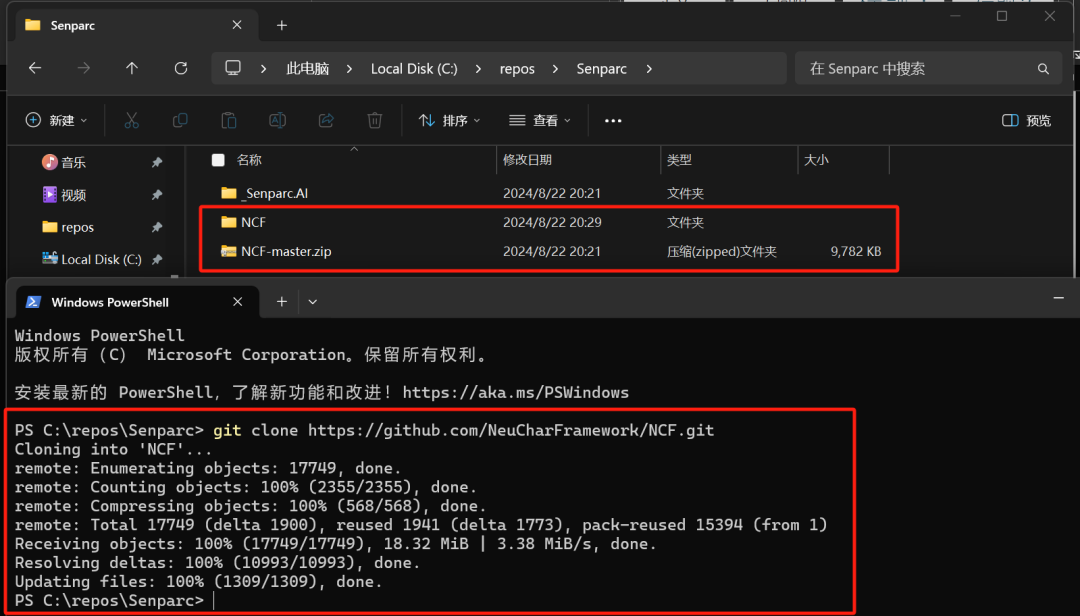
当我们克隆或者解压缩好项目后,我们能看到项目的文件夹结构如下图所示:
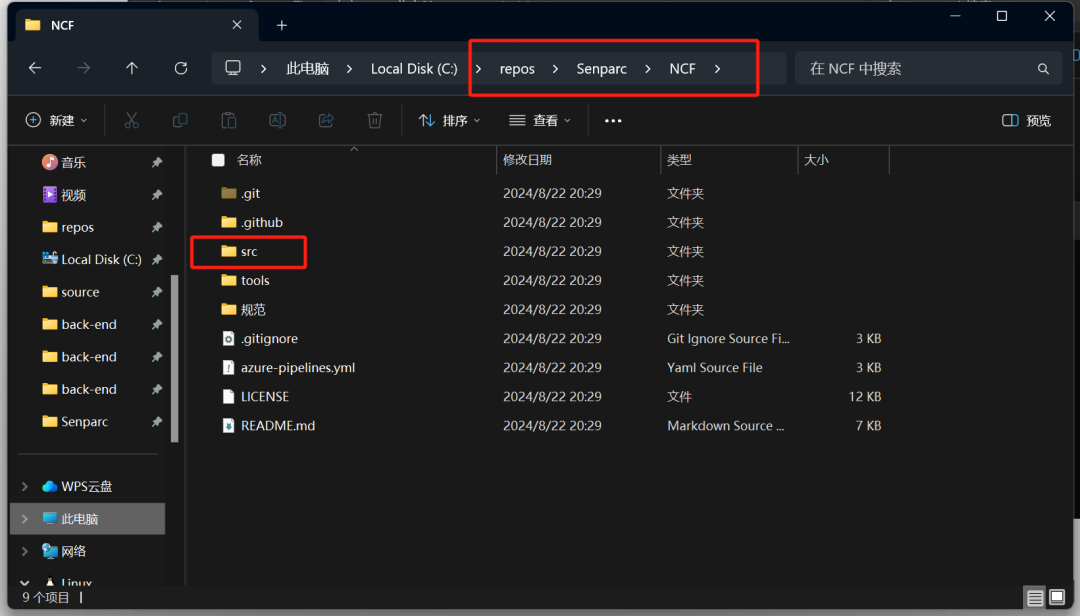
我们找到 src 文件夹 📂src,然后双击进入

我们继续进入 back-end 文件夹📂 back-end,然后双击进入
这就是我们 NCF 项目的后端文件夹,我们找到 NCF.sln 解决方案,并双击打开
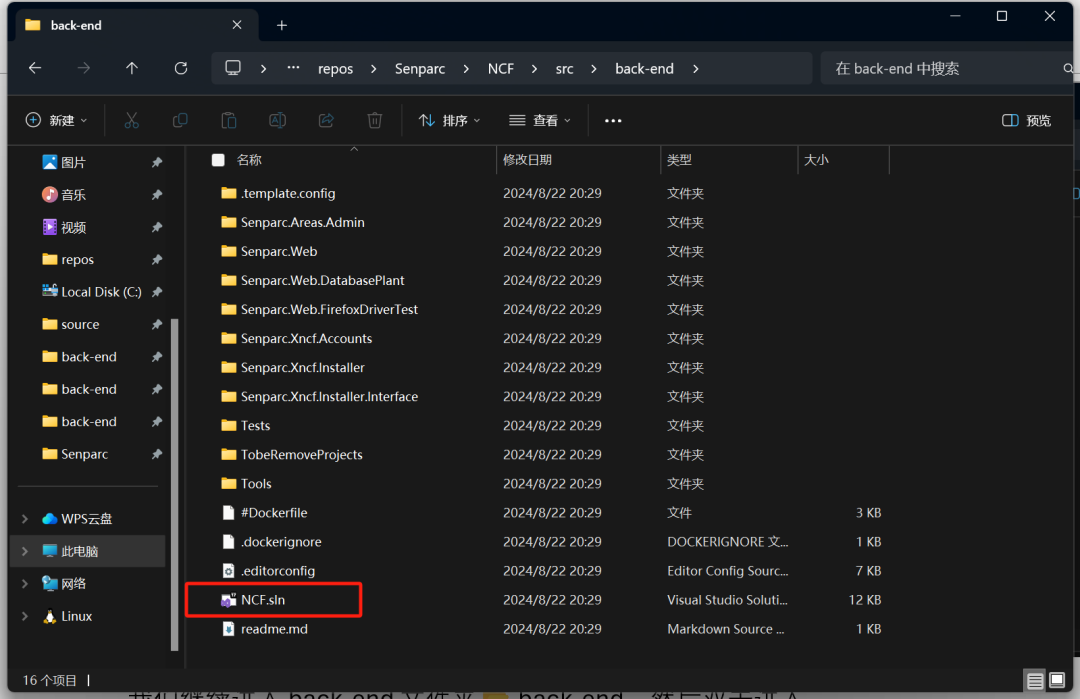
我们看到盛派 AI 核心模块以及盛派 AI 提示词已经默认集成在 NCF 中
所以我们无需任何操作,直接运行项目即可!
按下键盘 F5 或者在窗口的上方我们找到绿色的运行按钮点击即可启动!
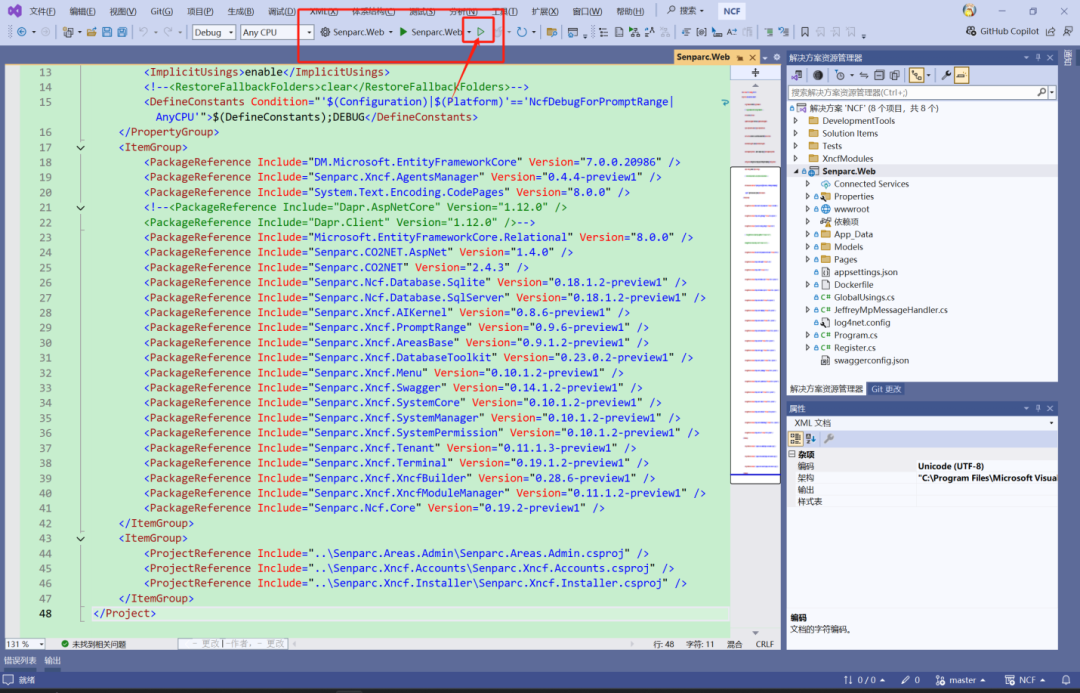
当我们看到 NCF 的启动页面时,恭喜您!这就证明我们项目成功启动了!
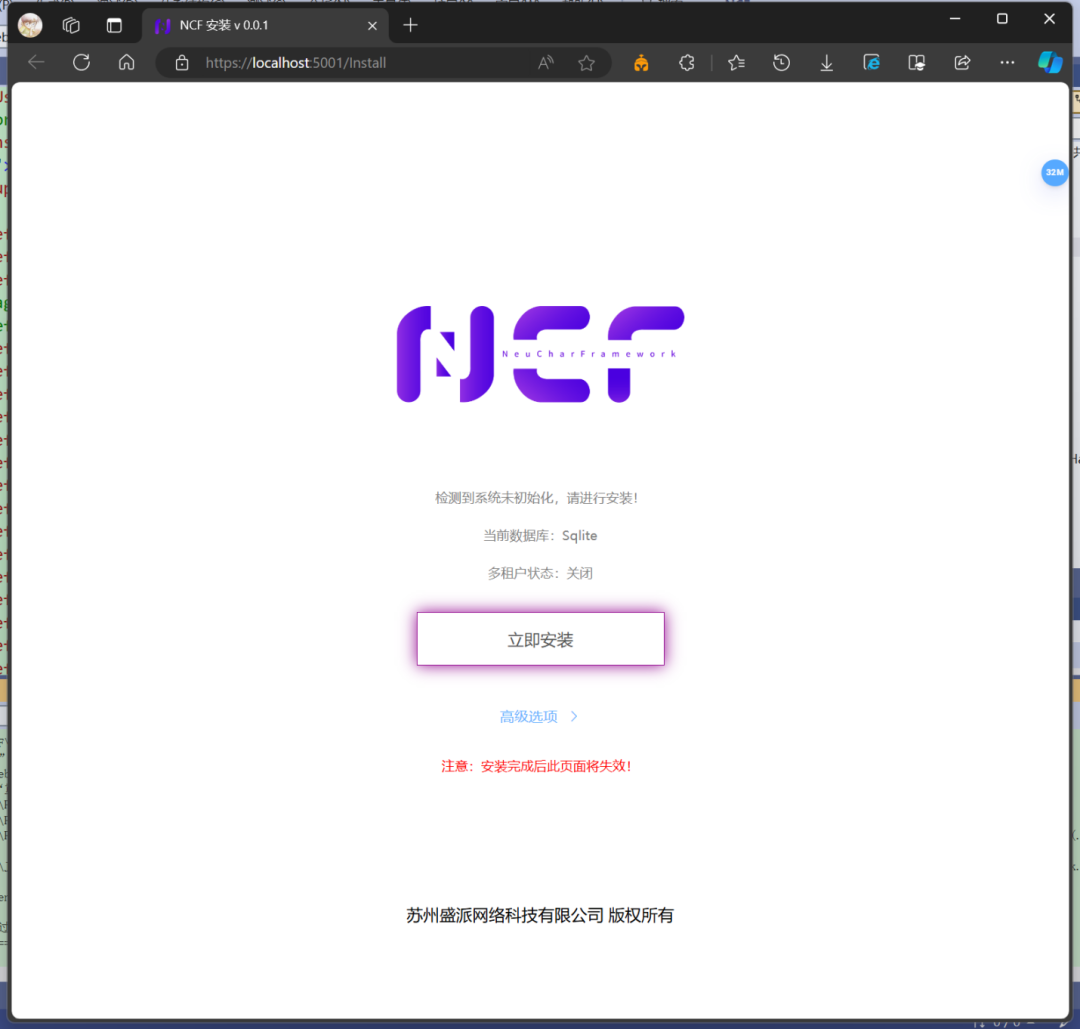
我们继续点击“立即安装”,然后我们点击确定
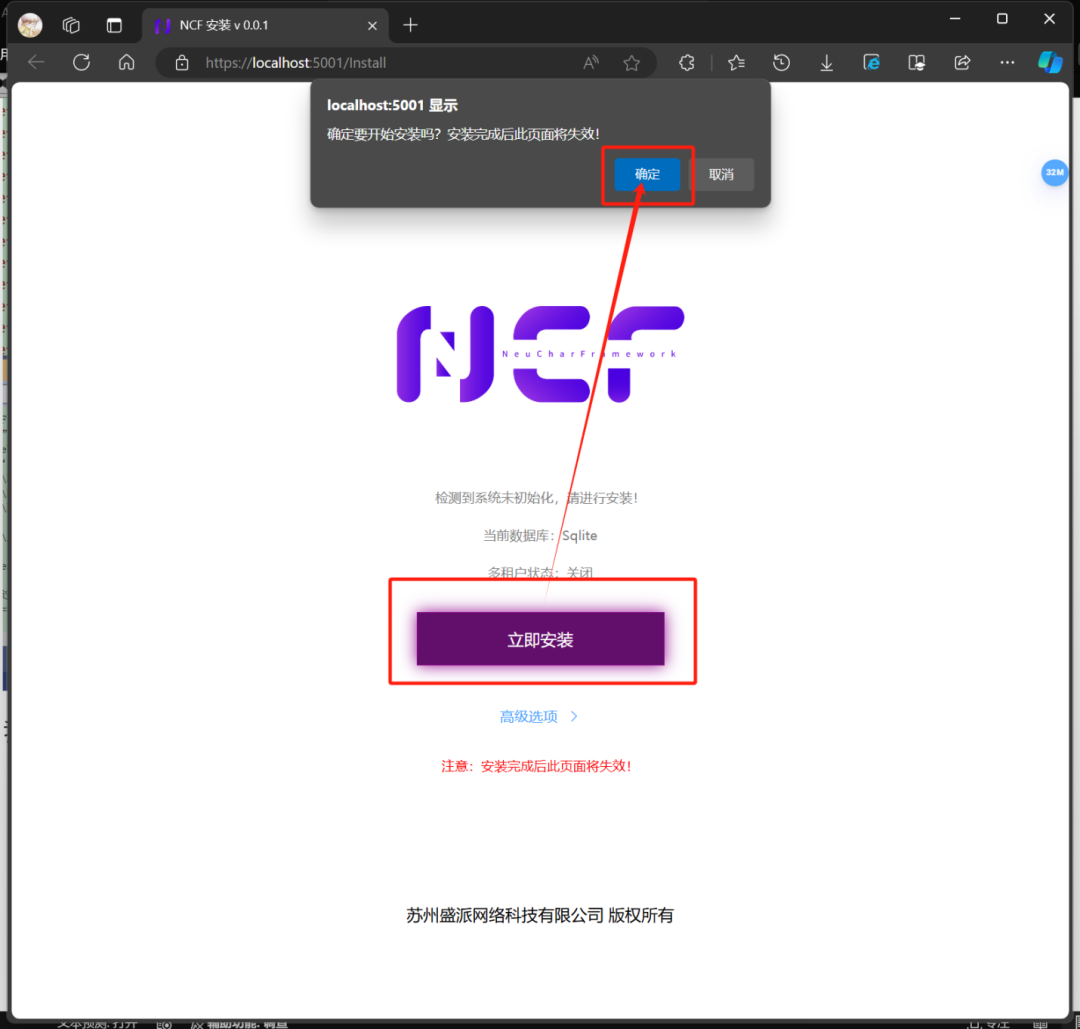
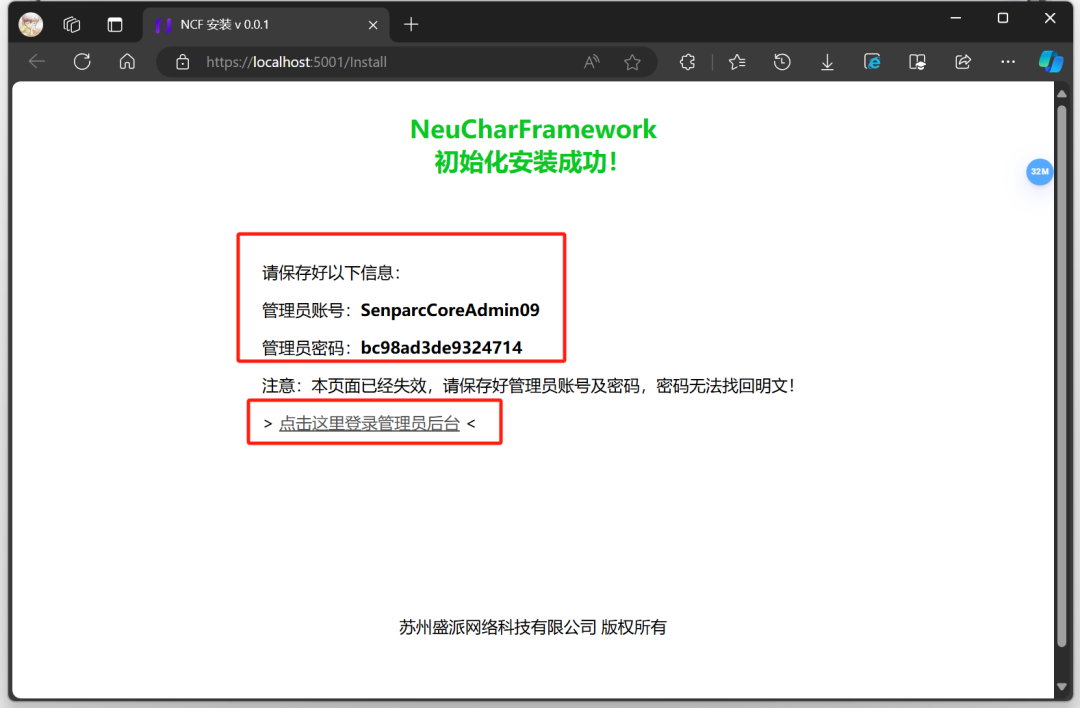
会弹出“NeuCharFramework 初始化安装成功!” 的提示。
请注意保存好您的信息,此处的账号和密码肯定和您显示的不一样,以您电脑浏览器中显示的信息为准!
2、登录盛派 NCF 项目并安装 AI 核心及提示词靶场模块
我们继续点击,点击这里登录管理员后台
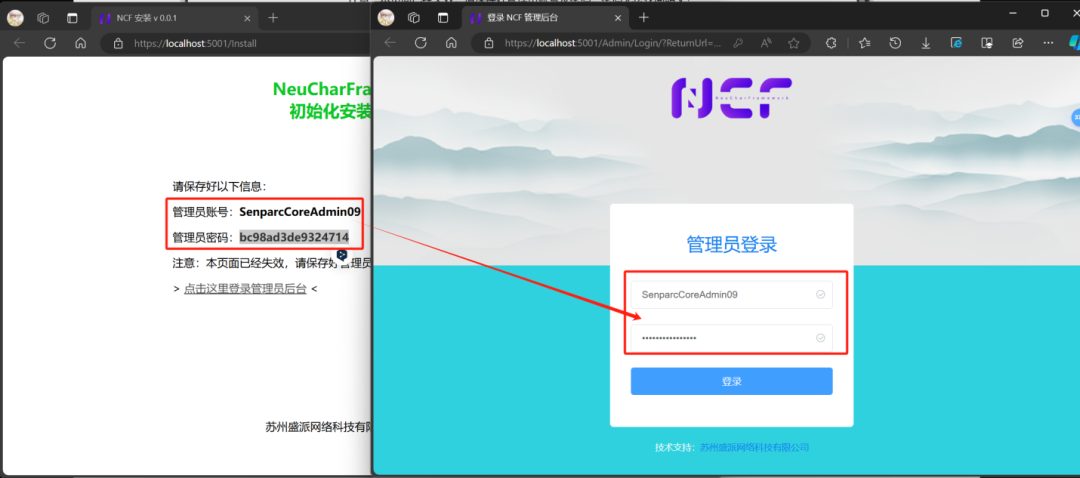
将我们得到的管理员账号和密码分别复制粘贴到我们的登录页面中,然后点击登录
即可进入到 NCF 管理员后台界面
旧版本:
V0.18 之后新版本:
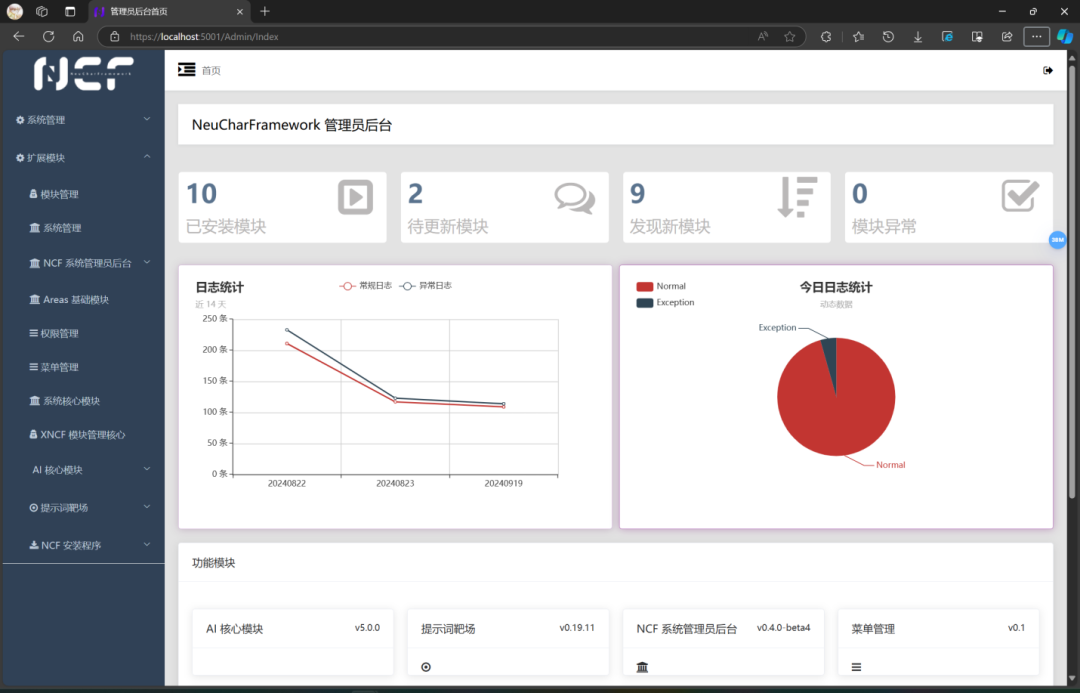
我们看到最新的版本在首页的仪表盘界面有了很大的升级,这些数据是真实的日志信息。
SenparcTraceLog
对应物理文件路径:..\NCF\src\back-end\Senparc.Web\App_Data\SenparcTraceLog
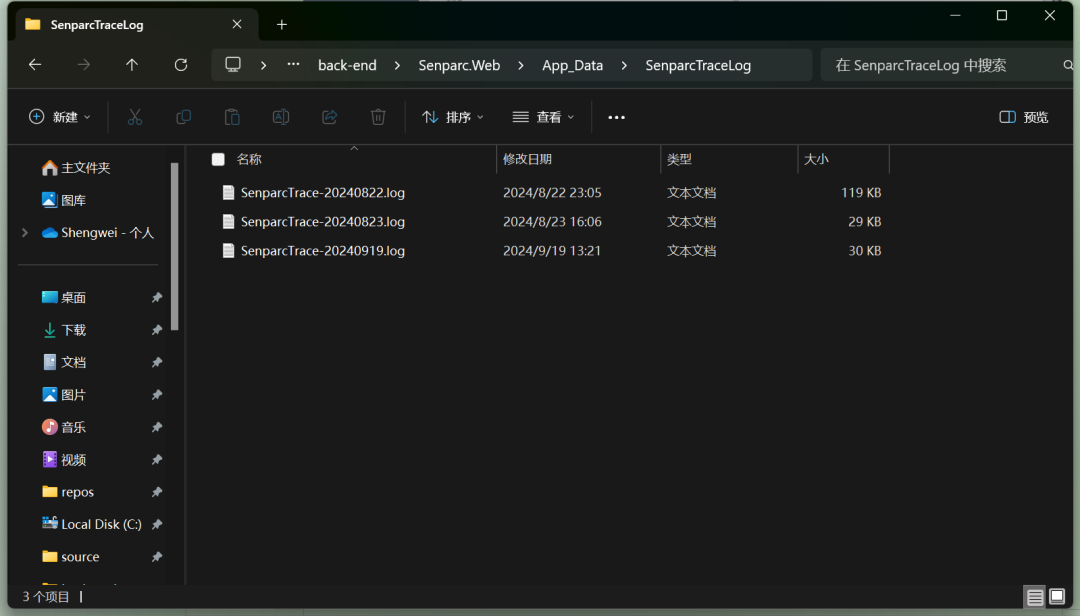
我们可以看到对应的日期和文件名是一致的👍 欢迎大家使用最新的版本进行体验!
接下来展开扩展模块,点击模块管理,或者点击主页的模块统计数字区域,即可进入模块管理页面。
我们需要对”提示词靶场”和“AI 核心模块”进行安装或升级!
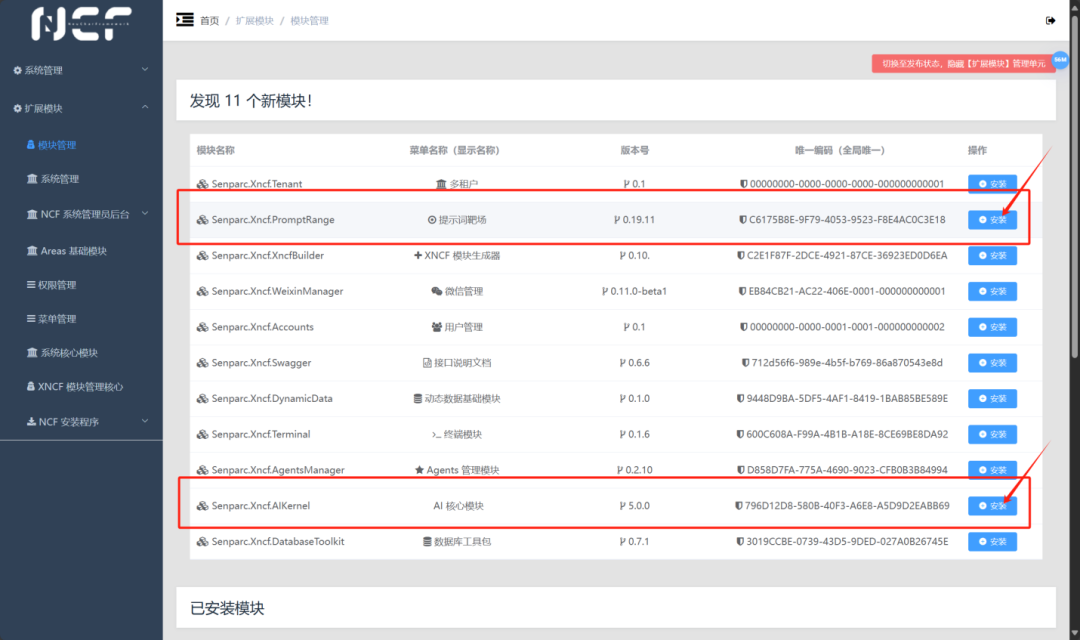
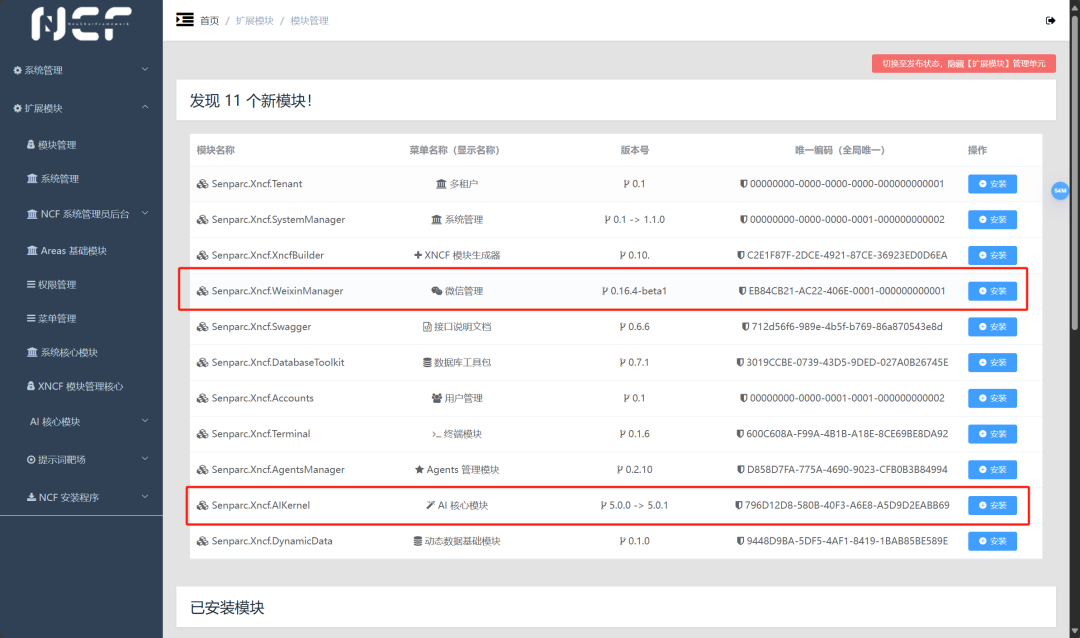
1、安装提示词靶场模块,并点击开启按钮
请一定点击 “开启” 按钮
请一定点击 “开启” 按钮
请一定点击 “开启” 按钮
这是点击开启前的样子
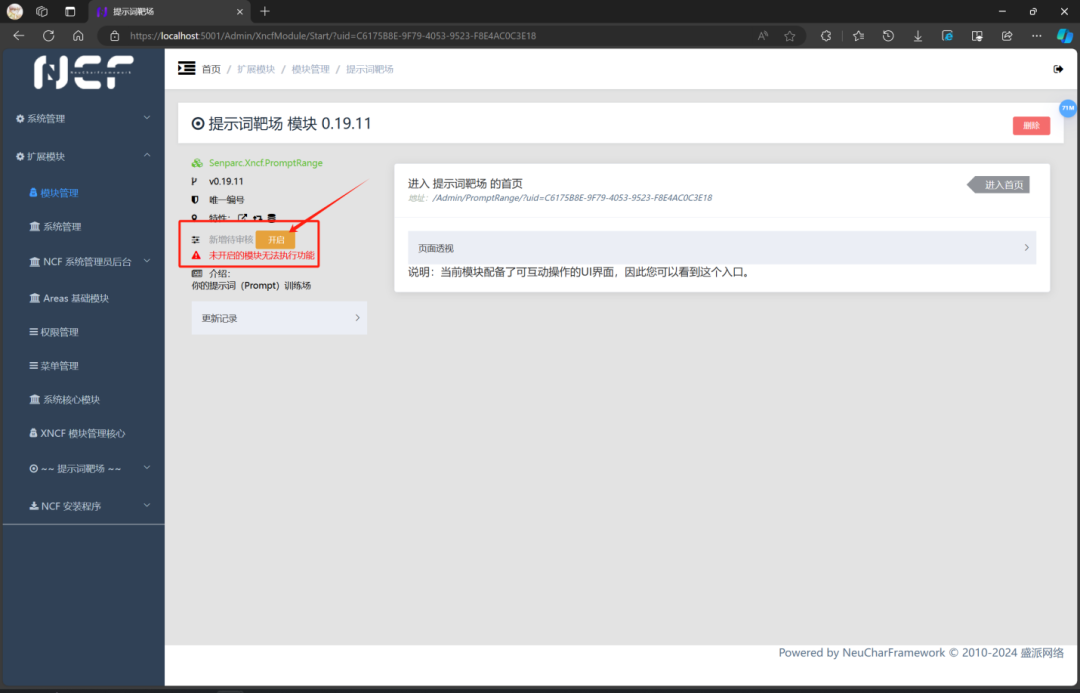
这是点击开启后的样子
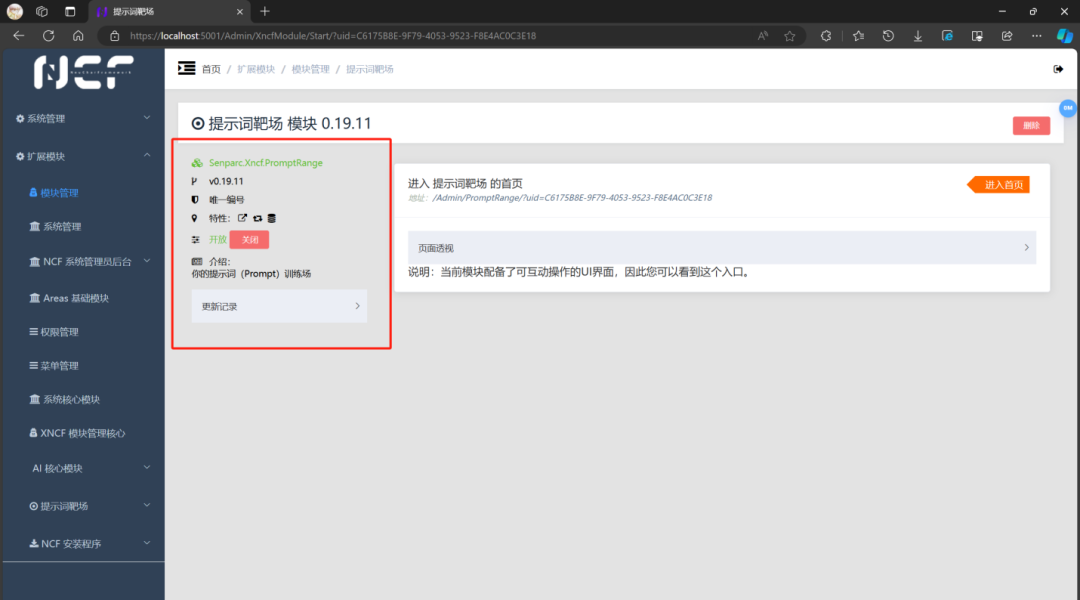
2、安装 AI 核心模块
请一定点击 “开启” 按钮
请一定点击 “开启” 按钮
请一定点击 “开启” 按钮
这是点击开启前的样子
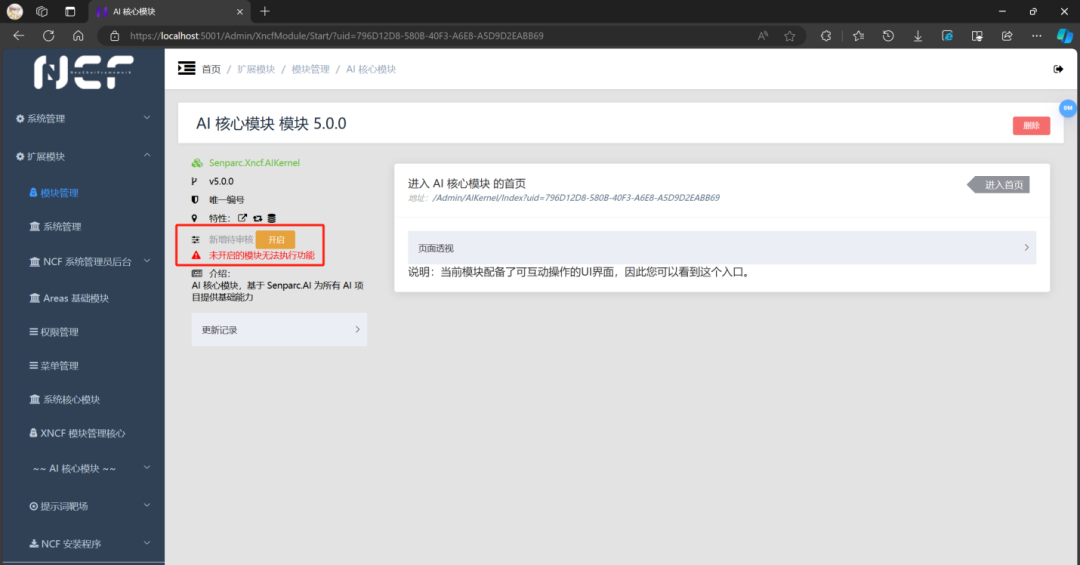
这是点击开启后的样子
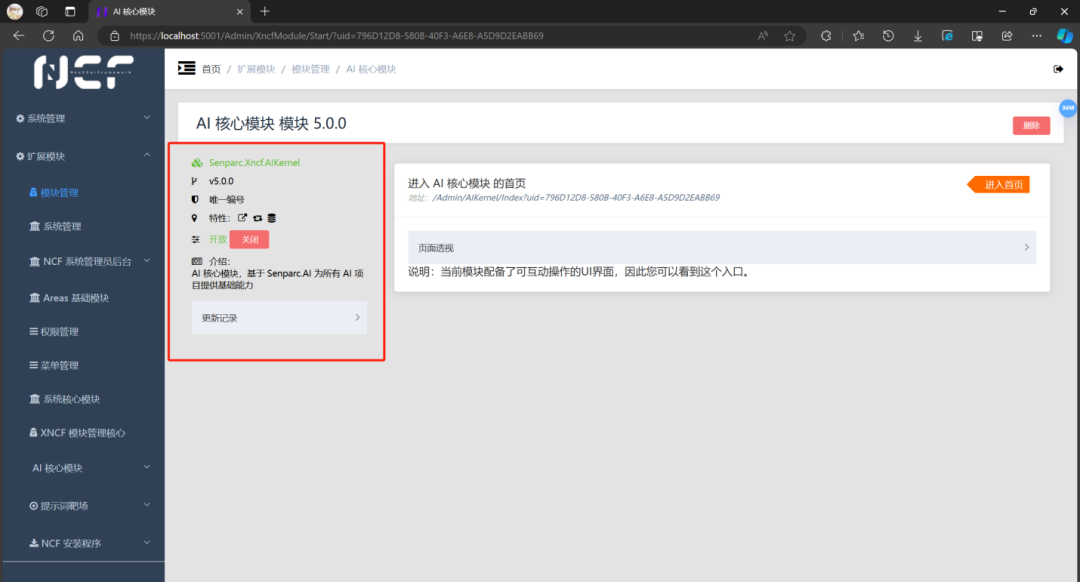
3、配置 AI 核心模块中的 AI 模型(使用 ollama 运行的本地大模型)
前情准备:安装和运行 ollama
ollama 是一个离线运行大模型的工具,注意你可不要把它和 Meta 的大模型 llama 混淆,二者不是同一个东西。
ollama 工具的下载地址为 Download Ollama on macOS
本 Demo 选择 Windows 版本进行下载和安装,当然您可以根据您本地计算机的操作系统,选择对应的支持的版本进行下载。
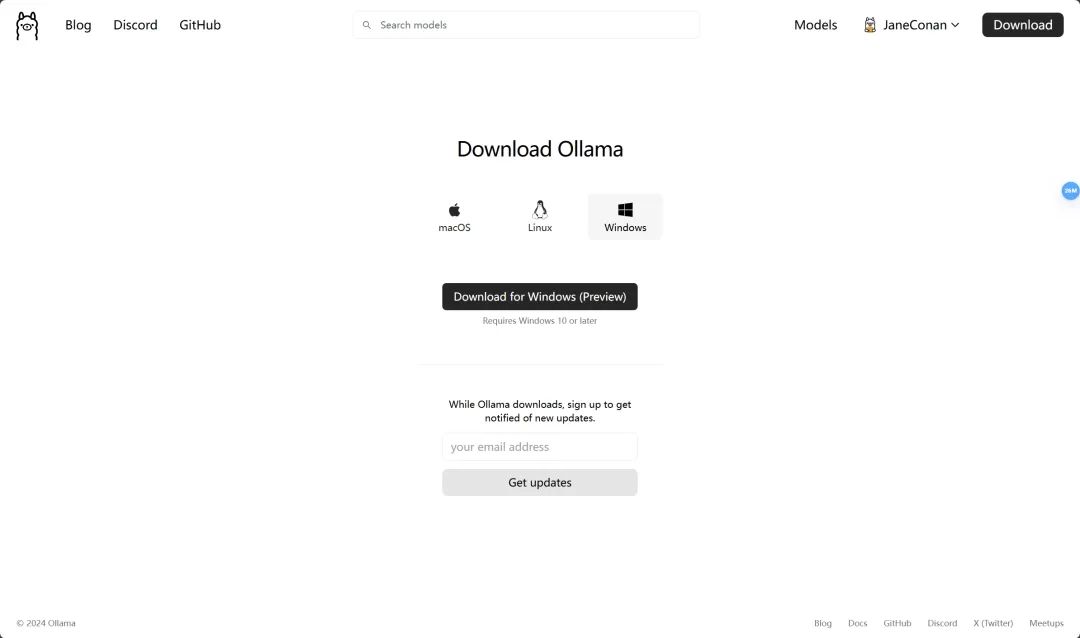
我们下载后会得到这样一个应用,点击运行,

运行后,我们会在我们的任务栏的右侧,系统托盘图标中找到它~
然后我们打开终端或者 CMD(命令提示符)或者 PowerShell
执行 ollama 的相关指令
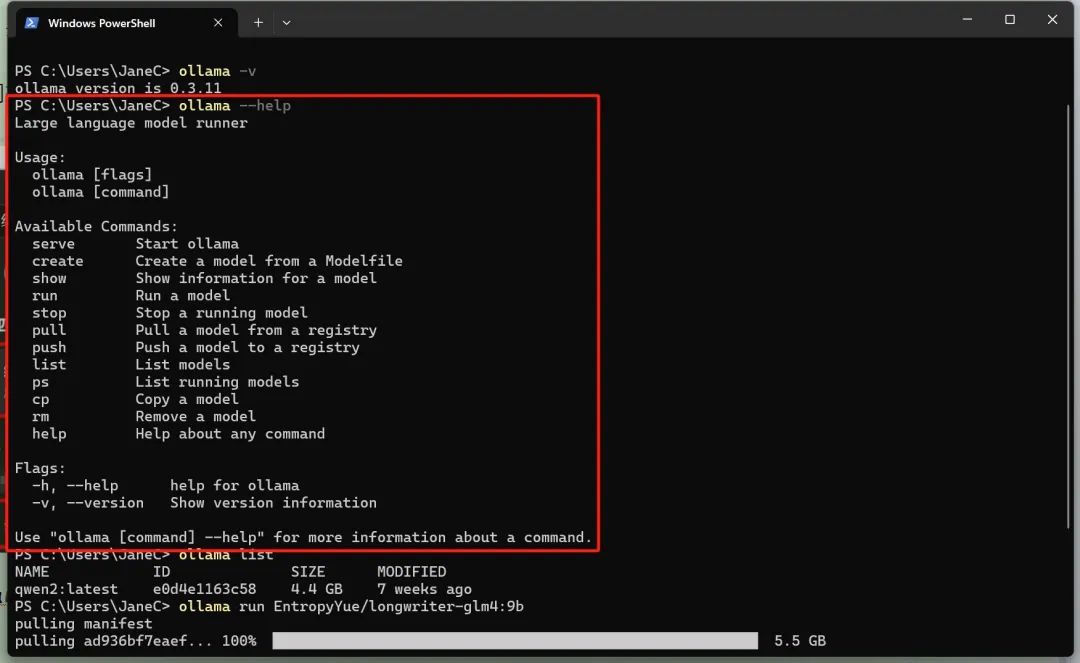
例如:
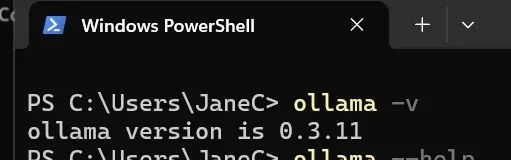
我们可以通过 ollama -v 来查看版本,
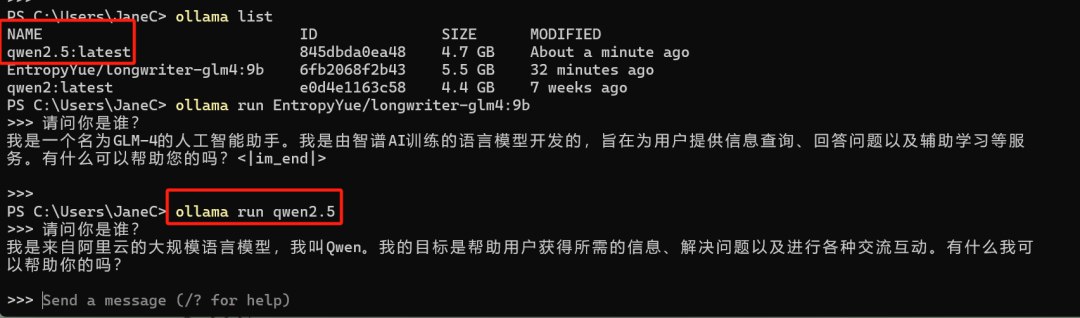
通过 ollama list 来查看本地大模型都有那些

通过 ollama run {大模型名称} 来运行本地大模型
这些大模型我们都可以从 ollama 的官网获取到
(我们还可以创建自己的模型,并分享给更多人)
这里我们看到有 Meta 最新更新的 llama3.2 哈
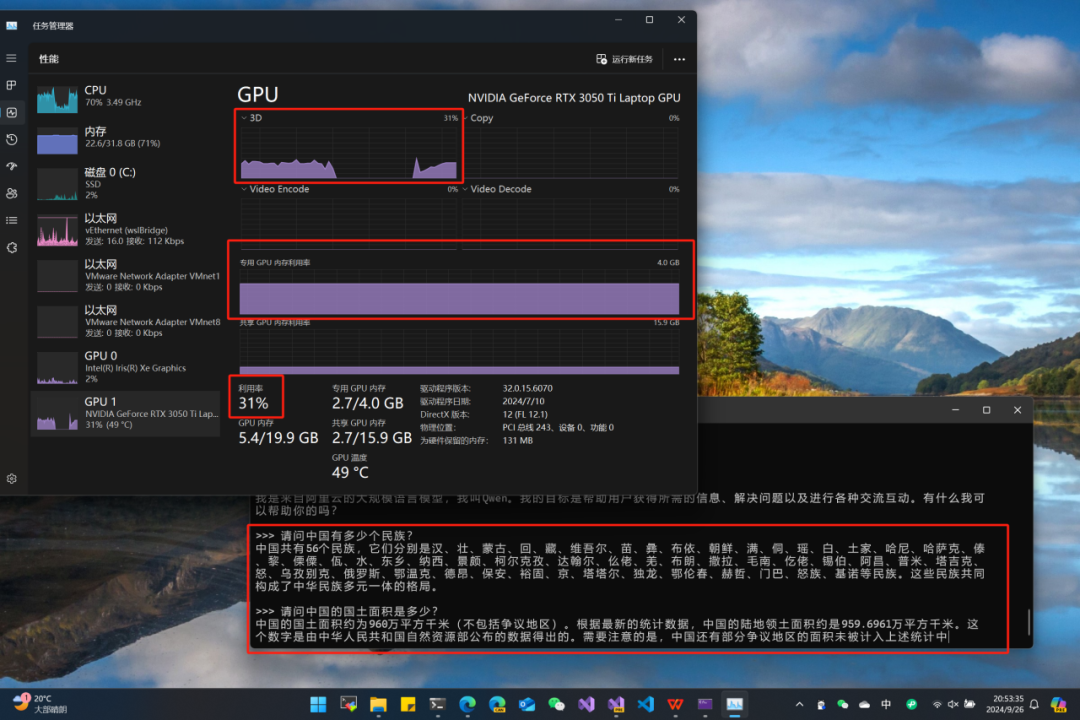
我们可以通过本机的任务管理器,查看性能及资源的使用情况
我们可以在浏览器中,访问如下地址,验证 Ollama 的 WebAPI 服务是否在运行
http://localhost:11434/
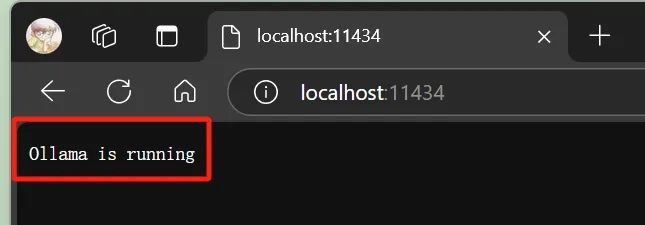
(这很重要,因为我们需要基于这个服务,来使用 NCF 进行我们的本地大模型调用)
好的,到这里我们的准备工作都已经完成了,我们一起来进入 NCF 进行本地大模型的配置和🎯打靶训练吧!
我们在浏览器中,打开我们之前运行的 NCF 应用,找到 AI 核心模块,展开并点击首页
https://localhost:5001/Admin/AIKernel/
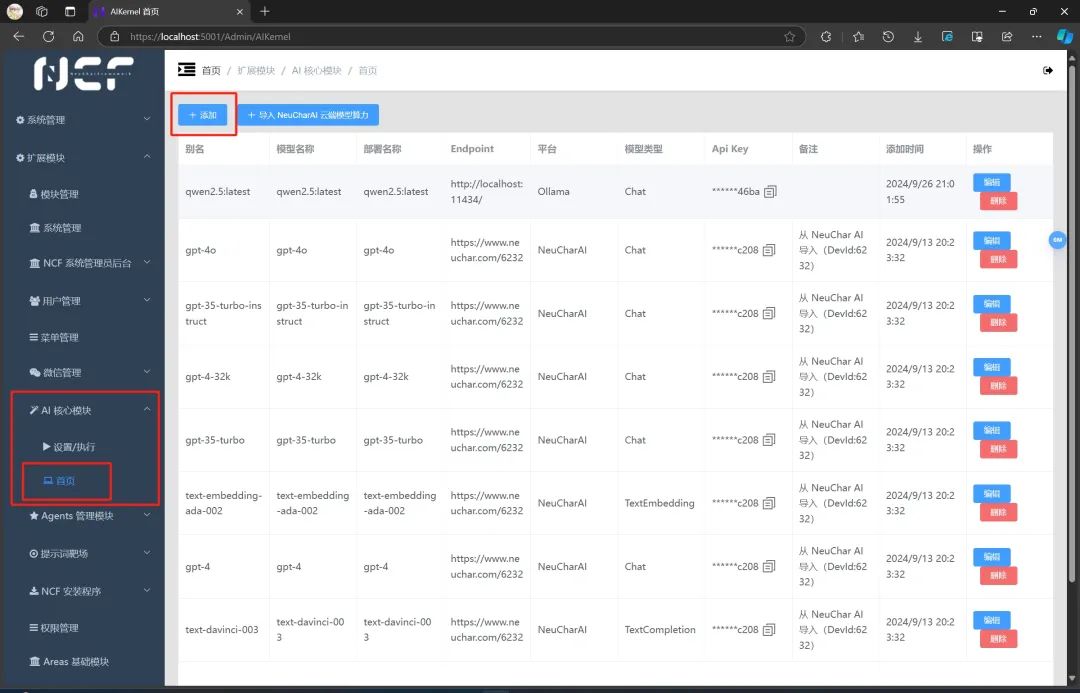
在首页,点击添加,平台选择 Ollama
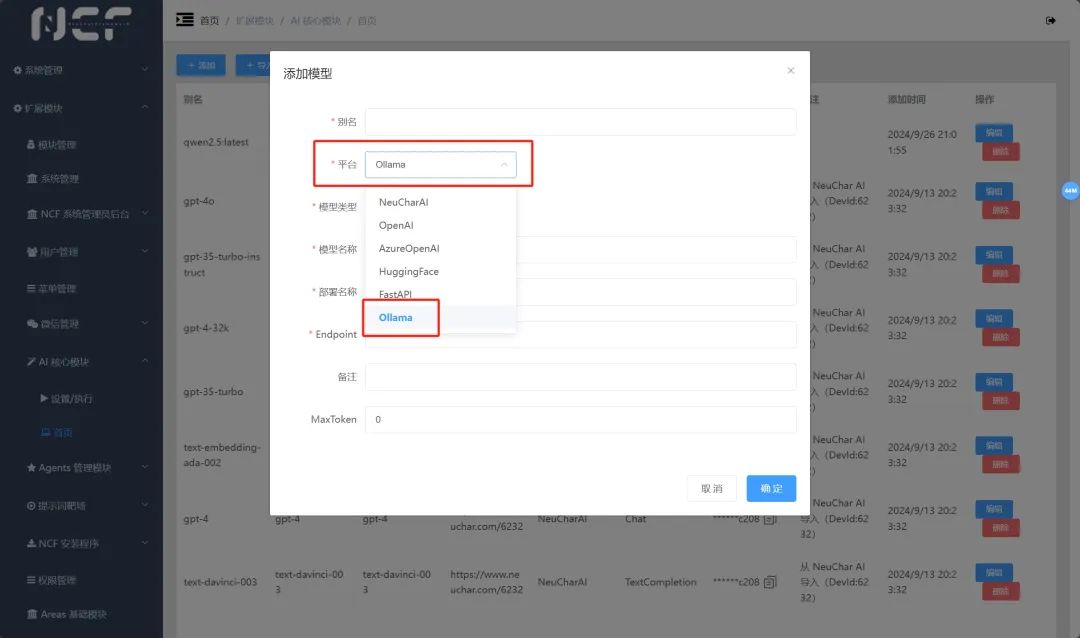
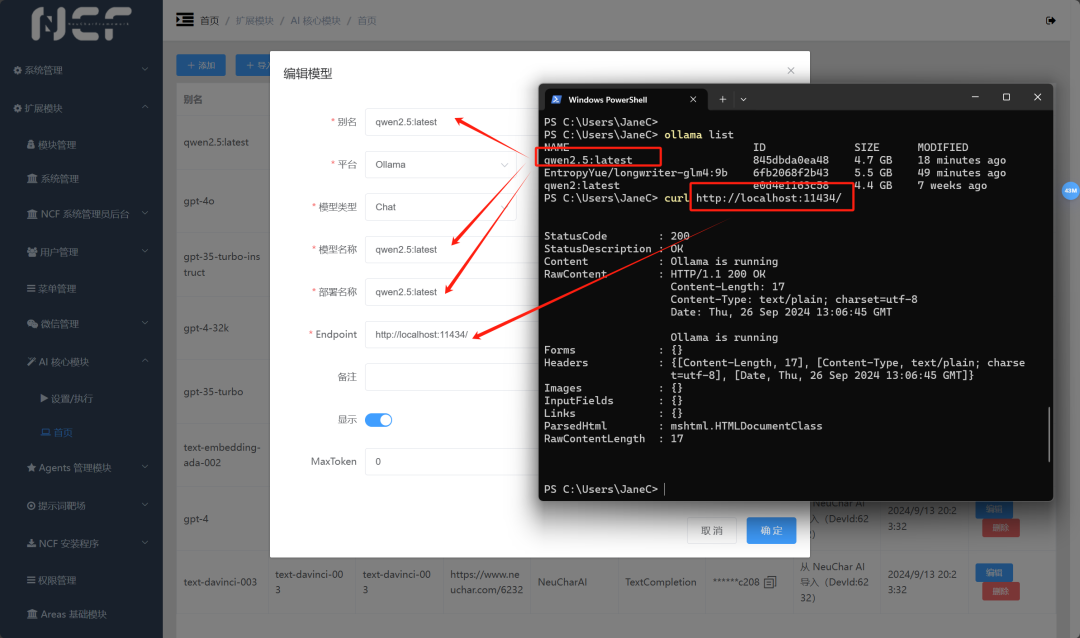
并根据您本地通过 ollama 运行大模型的大模型名称、模型类型,以及 Endpoint 本地运行的 Web 地址进行配置,然后点击确定。本地大模型就已经和 NCF 关联好了!
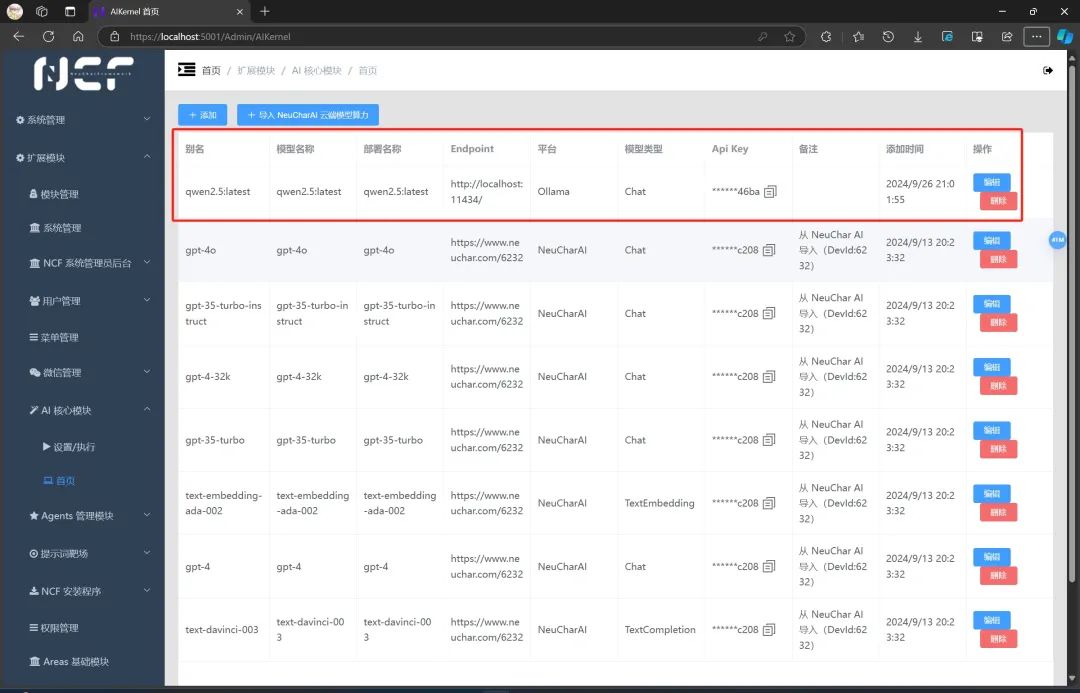
这时,我们无论是使用 NCF 的提示词靶场,训练我们专属的智能体,还是接入我们的微信公众号,乃至接入我们的 QQ 群,以及企业微信等所有 NCF 支持功能都是可以用我们本地大模型的!
那好,这里我们以提示词靶场为例,和大家体验一下我们自己本地运行的大模型应用!
我们进入 NCF 的提示词靶场模块,进入 PromptRange 页面。
这次我们简化些,仅仅对提示词作为输入输出,并配置好传入问题的变量名。

本次使用的提示词:
[输入]
{{$human_input}}
[输出]
END
例如,我们这里问到:请问中国的人口数量
并且请 AI 对自己的回答进行评分,即设置 AI 评分标准。我们都知道我们祖国大约有 14 亿人口,那么我们就把预期结果 1 设置为 14 亿,并点击关闭。
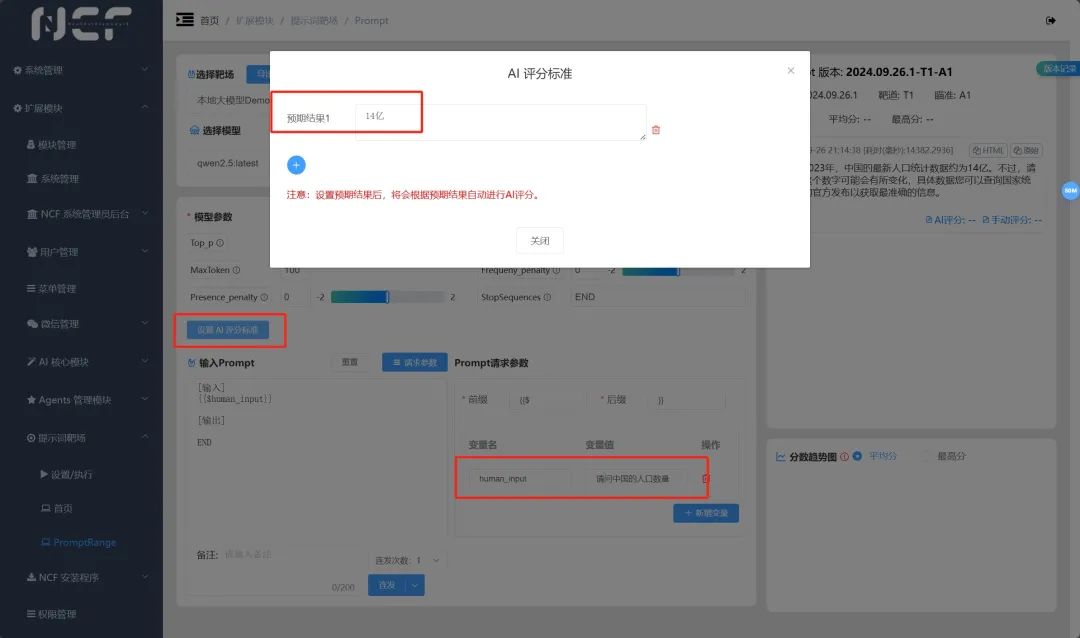
在这里,我们也再次介绍一下提示词靶场的模式:
1、打靶: 根据当前填写的内容或者选择的靶场和靶道,创建新的靶道。
2、连发:根据当前选择的靶道信息,连续输出多个结果。
3、草稿:保存当前输入的内容,并创建新的靶道。
我们可以通过下拉按钮进行体验与尝试~
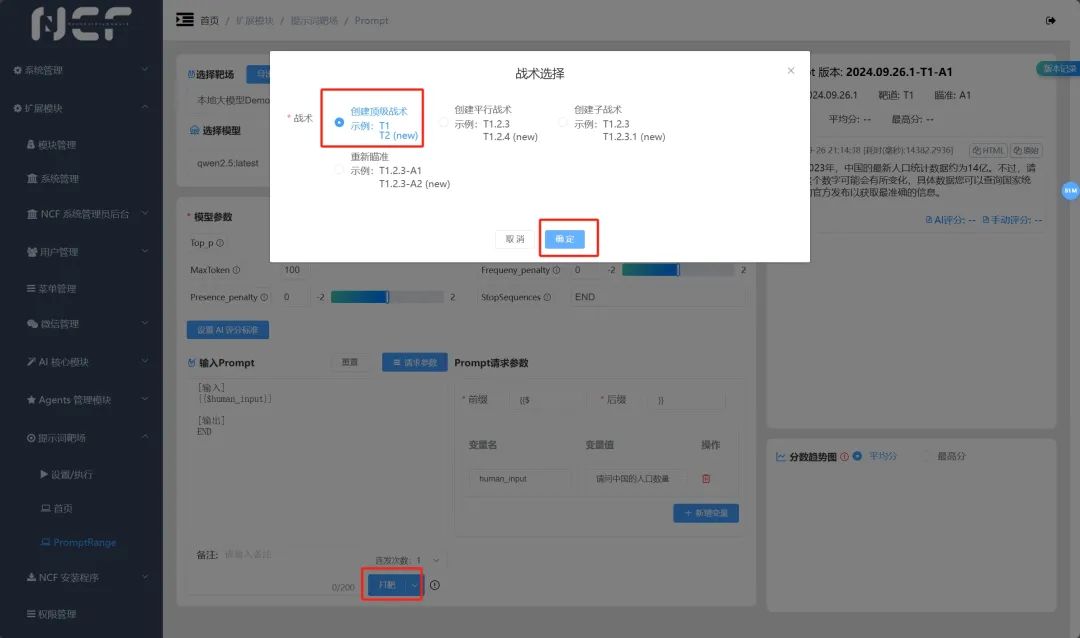
好的,这里我们使用打靶,并使用创建顶级战术来执行打靶~
我们点击确定,并在浏览器的控制台查看本地大模型执行的时间。我们知道大模型的输出方式是流式输出,我们可以在 ollama 于控制台中运行时去观察。我们可以观察 LLM 大模型在回复的时候,是一个一个字输出的,行业里称之为流式输出的方式为您呈现内容的。为什么会这样呢?这是因为,大模型确实是在一个字一个字地去推理生成内容的。
而我们在浏览器页面中,需要等待大模型全部输出完成,再为您展现页面,所以您可能会感觉有些“慢”。
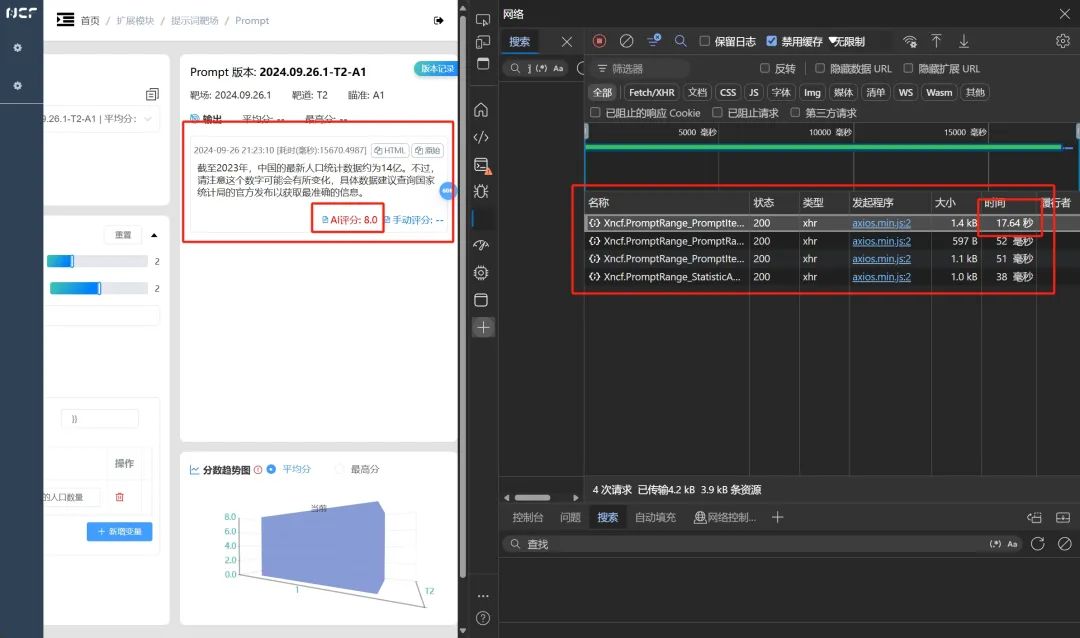
同时我们关注到,也有 AI 评分的生成。我们继续进行连发测试。
并一起观测使用的时间~
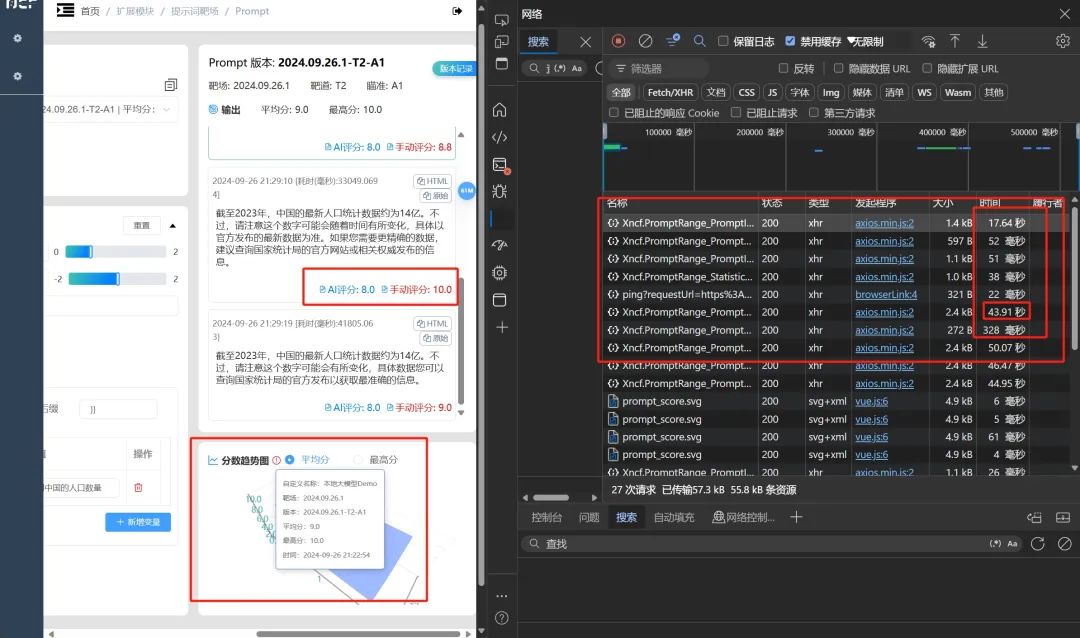
我们看到连发五次的时间大约是 43 秒,与此同时,AI 也给自己的回答进行了打分,我们也可以给它进行手动评分。
好的,到这里,大家也就完成了使用盛派 AI 调用本地大模型的操作,那么这里我们留一个小任务,就请您参考上一篇文章,利用本地大模型和您的微信公众号进行对接吧!
还顺利吧,您有遇见任何问题,都可以联系盛小嗨,将您的心得体会,给我们反馈,以便于我们更好的改进开源项目,感谢您的支持与认可!
原文地址:https://blog.csdn.net/weixin_53746797/article/details/142783627
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!