通用计数系统
当要求设计一个通用计数系统,并给出接口与核心功能。
理解问题并确定问题的边界
理清需求
 :通用计数器是个什么东东?
:通用计数器是个什么东东?
![]() :看过博客吧,每篇博客都有点赞数、评论数、转发数,看过直播吧,直播间也有观看人数,现在就是要实现一个能存储这些各种类型计数的通用计数系统。
:看过博客吧,每篇博客都有点赞数、评论数、转发数,看过直播吧,直播间也有观看人数,现在就是要实现一个能存储这些各种类型计数的通用计数系统。
:这个系统的规模如何?
![]() :必需能处理大量的请求,假设日活用户4亿吧!
:必需能处理大量的请求,假设日活用户4亿吧!
尝试封底估算
- 写操作:假设每个用户平均每天增加100个计数,QPS = 4亿 * 100 / (24 * 60 * 60) ≈ 50w
- 读操作:假设读操作为写操作的10倍,QPS = 50w * 10 = 500w
- 记录数:假设每个用户平均每天增加10种计数,计数器运行10年,将存储10 * 4亿 * 365 * 10 = 146000亿条数据
- 存储:假设每条数据0.1KB,10年存储量为0.1KB * 146000亿 = 1460TB
高层级的设计
这个系统的核心流程即为计数的更新与读取,业务server通过计数器提供的api操作数据,整合资源给到用户。对于计数器而言,业务server是它的客户端。
API设计
基于rpc的api在服务端是比较常见的方式,这里提供最基础的两个API:getCnt、updCnt。
package Counter;
service CounterService {
rpc getCnt(GetReq) returns(GetRsp) {}
rpc updCnt(UpdReq) returns(UptRsp) {}
}
message GetReq {
int32 cnt_type = 1;
string key = 2;
}
message GetRsp {
int64 err_code = 1;
string err_str = 2;
int64 cnt = 3;
}
message UpdReq {
int32 cnt_type = 1;
string key = 2;
int32 diff = 3;
}
message UpdRsp {
int64 err_code = 1;
string err_str = 2;
int64 new_cnt = 3;
}计数器的使用流程
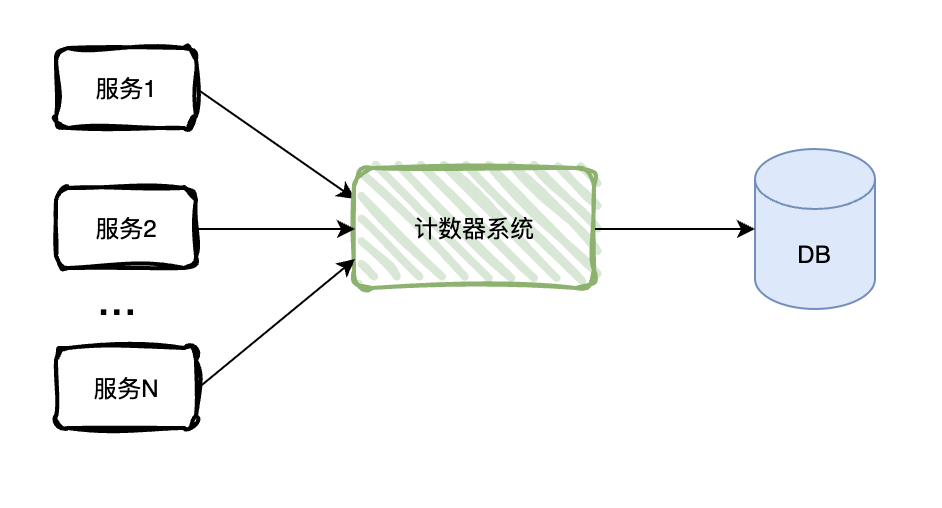
计数器为不同的业务server提供计数功能,并将值存储到DB中,这是最原始的流程。
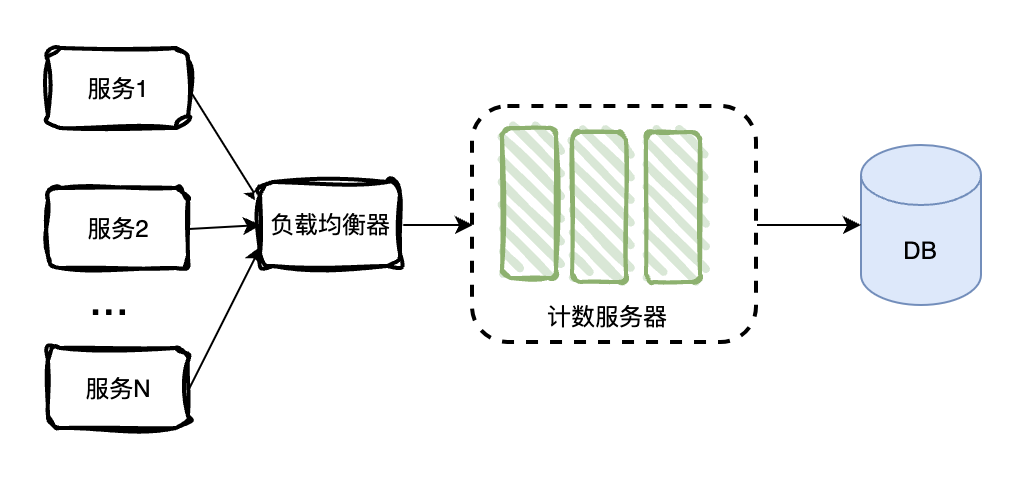
现在来一步步给他增砖添瓦。考虑到我们的系统需要支持高并发访问,显然单机应用不足以支撑这么大的访问量,并且存在单点故障的问题,所以我们的系统应当是分布式的。
在这个设计中,我们可以发现以下几个问题。
- API为内部服务或者验证过的客户端提供服务,故而是有会话的。会话限制了服务器的横向扩展。
- 身份校验可能会消耗大量资源,影响核心功能。
- DB读写慢,拖累响应速度。
- 未处理请求超限的场景。
针对上面的几个点做出如下改进:
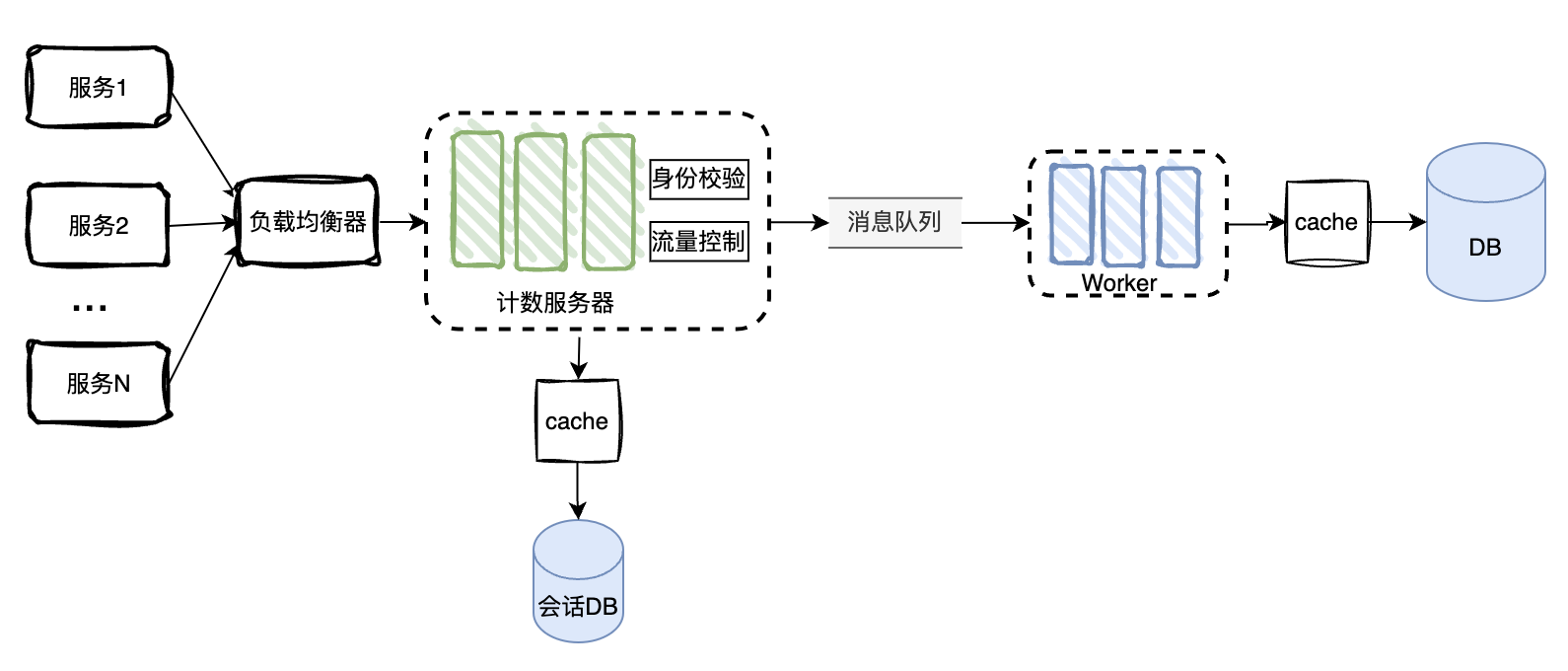
- 将会话状态单独存储到DB中,这样网络层就可以轻松的横向扩展了。
- 将核心功能计数的读与改放到worker中处理,请求通过消息队列传递:可以暂存处理不过来的请求以及解耦这两个组件。
- 给DB增加cache层提高速度。
- 增加流量控制,避免大量请求将系统搞垮。
另外我们的数据量比较大,单台cache或db并不足以存储海量的数据,因此存储必需也是分布式的。
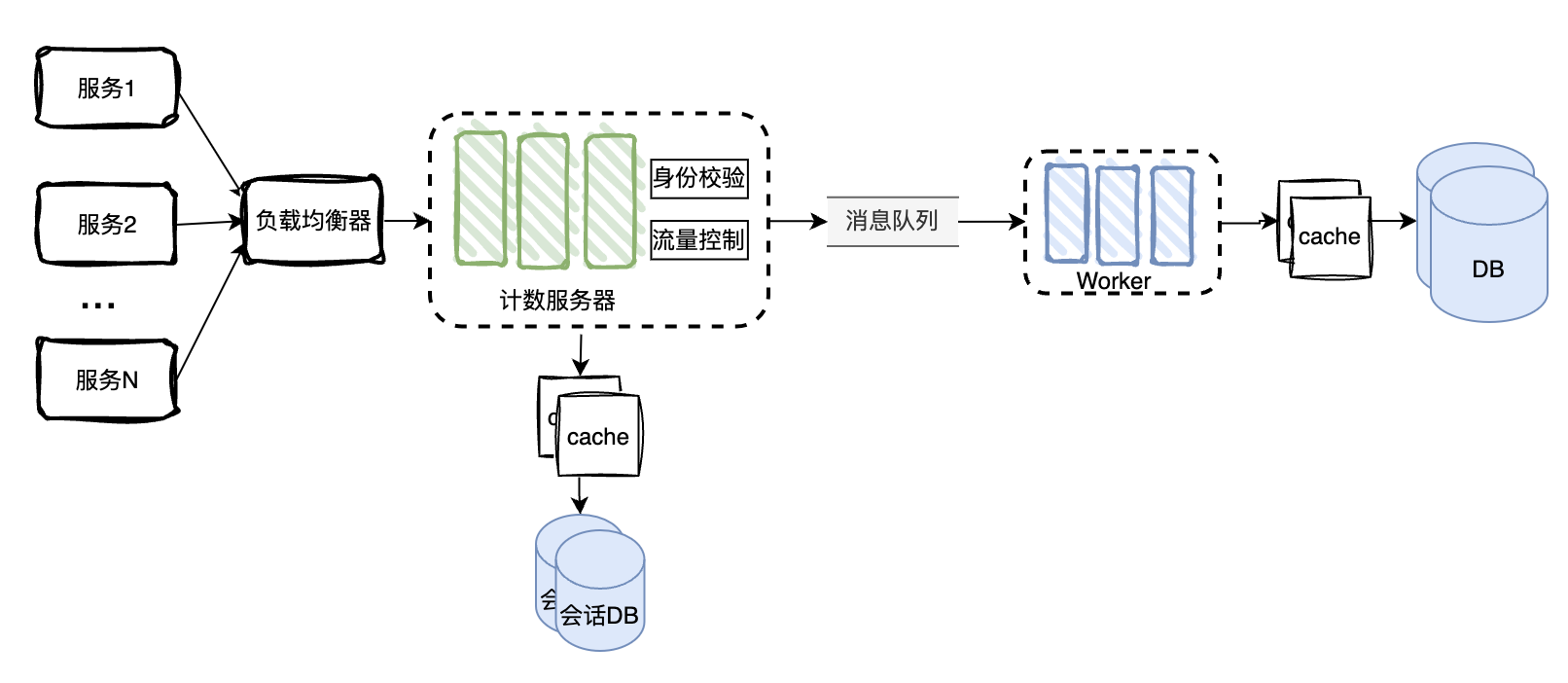
将DB改为去中心化的分布式DB,数据在多台DB中分片存储。分布式集群中的每台DB再做一主多备,保证高可用性。
考虑到一般地震、断电等灾害可能导致一个机房的服务器批量挂掉,我们需要提高可靠性,增加多个异地数据中心。
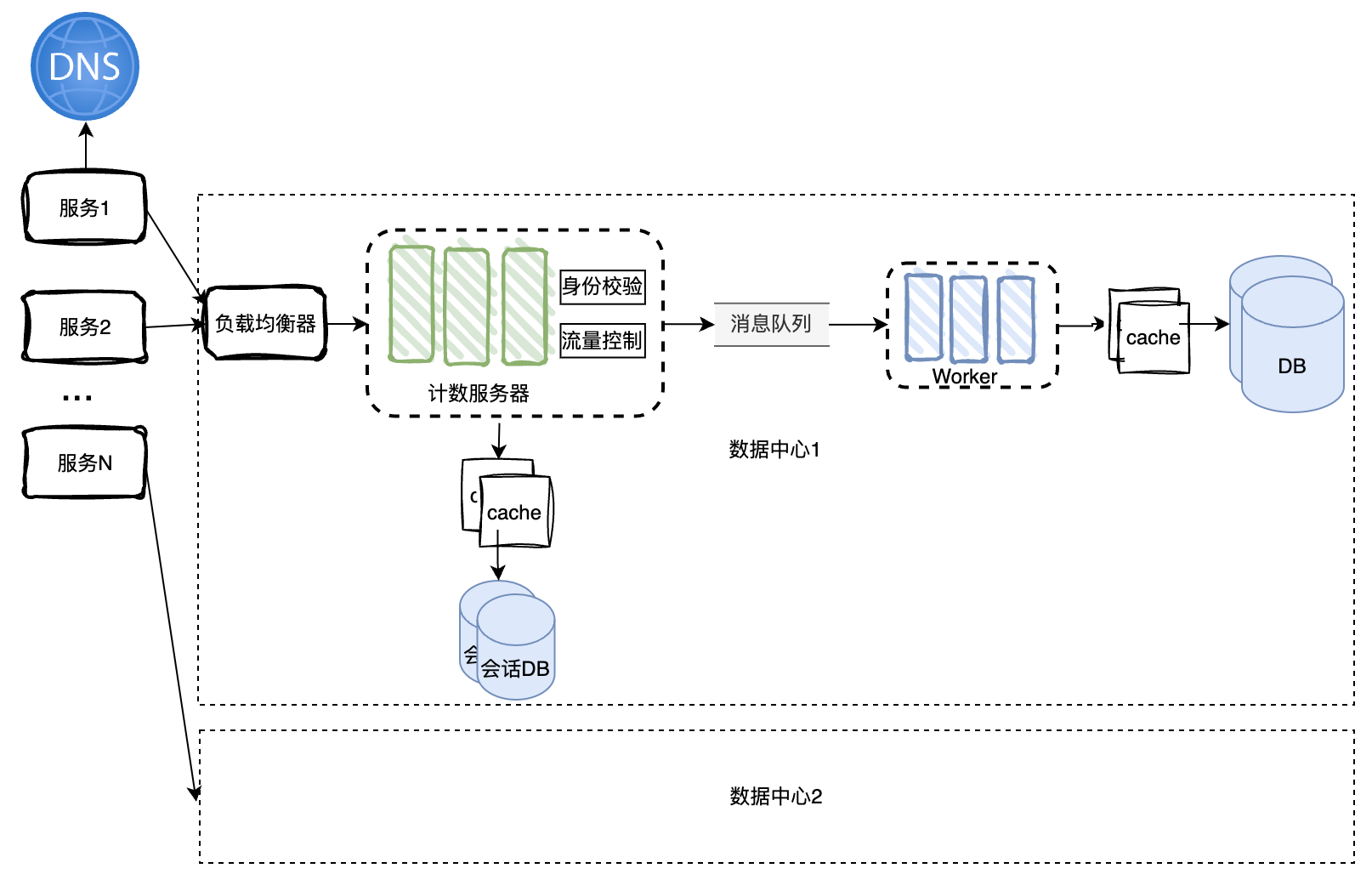
基于地理位置的DNS可以帮我们将不同地区的请求路由到不同的数据中心。
设计继续深入
重试机制
计数系统最重要的需求之一就是不能丢数据。计数可以延迟生效单决不能丢。为了满足这个需求,计数系统需要实现重试机制。
数据分析
请求数、流量限制丢弃的请求数、队列中的通知总数、计数操作结果成功与否是监控的关键指标。需要监控这些数据,以备分析或者告警。
配置管理
需要有一个web服务器负责增加技术类型,避免各业务互相冲突。这个配置服务器仅内部人员访问,请求量不高,数据同步到DB中,并在cache中缓存。worker更新计数时需要先检查对应类型是否存在,否则报错。
更新后的设计
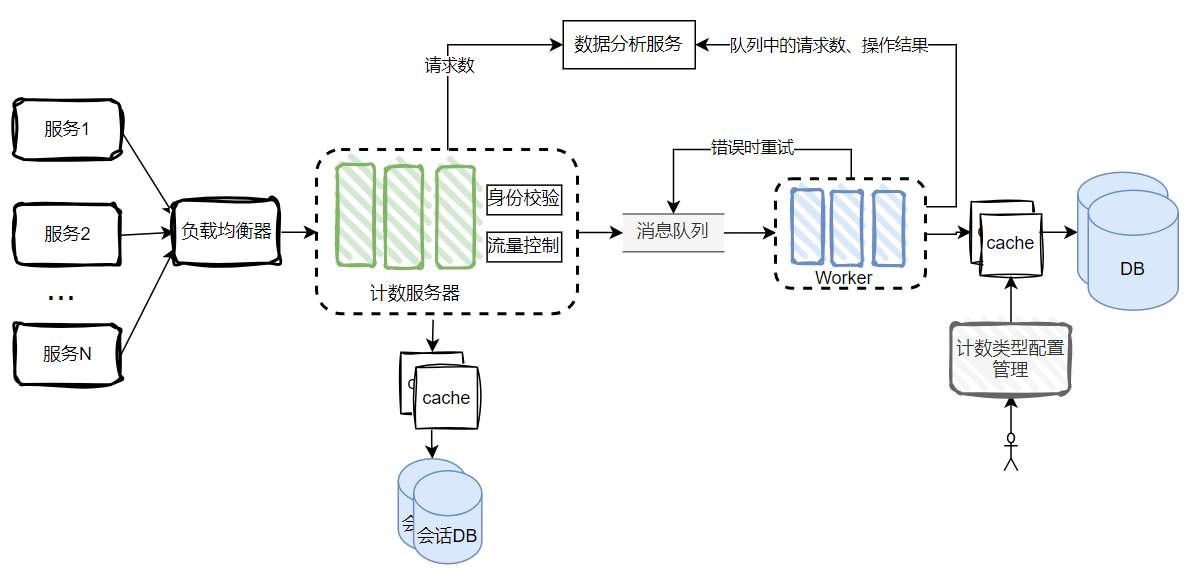 (仅画出一个数据中心)
(仅画出一个数据中心)
总结
一个可扩展的计数器,支持多种类型的计数。除了高层设计,我们还补充了身份校验、流量控制、以及数据分析服务。其中计数服务器因为是无状态的,可以很容易通过添加或移除服务器进行伸缩。
服务冷启动后可以考虑预热缓存。为了更好的利用缓存,负载请求的时候可以选用一致性哈希算法。
对于流量控制,又存在好几种策略,如漏桶、滑动窗口、令牌桶等算法,可以根据实现难度及业务要求选择合适的算法。以及防止恶意用户发送海量的请求,可以基于IP地址或其它过滤条件拦截请求。
不同数据中心的DB还需要发生复制,以保证一致性。
可补充的细节还有很多,这也是一个大型系统设计的难点所在。
原文地址:https://blog.csdn.net/qq_33724710/article/details/136350510
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!