论文分享|AAAI2024‘北航|用大语言模型缩小有监督和无监督句子表示学习的差距
先说结论,大语言模型除了作为聊天的Agent,也可以为检索模型生成优质的文本对训练数据,从而做到无监督场景下也能够适用。这里分享一篇AAAI2024的工作,重点探讨如何生成比评估集更困难的训练数据来提升无监督句子表示学习质量,应该对很多表示学习工作都有一定启发
来源:AAAI2024/实验室师兄/北航
方向:文本表示学习
开源地址:https://github.com/BDBC-KG-NLP/NGCSE
摘要
句子表示学习(SRL)是自然语言处理(NLP)中的一项基本任务,句子编码对比学习(CSE)因其优越的性能而成为主流技术。CSE中一个有趣的现象是有监督方法和无监督方法之间的显著性能差异,它们唯一的区别在于训练数据。以前的工作将这种性能差距归因于对齐和均匀性的差异。然而,由于对齐和均匀性只衡量结果,他们没有回答“训练数据的什么方面导致了性能差距?”以及“如何才能缩小性能差距?”。
本文进行了实验来回答这两个问题。首先通过彻底比较监督和无监督CSE在各自训练过程中的行为来回答“什么”的问题。从比较中,我们确定了相似度模式是性能差距的关键因素,并引入了一个度量,称为相对拟合难度Relative Fitting Difficulty(RFD),来衡量相似度模式的复杂性。
然后,基于从“什么”问题中获得的见解,我们通过增加训练数据的模式复杂性来解决“如何”问题。我们通过利用大语言模型(LLM)的上下文学习(ICL)能力来生成模拟复杂模式的数据来实现这一点。通过利用LLM生成数据中的有层次的模式,本文有效地缩小了有监督和无监督CSE之间的差距。
介绍
“什么”导致了性能差距
相似度模式:一个数据集怎样定义相似和不相似的文本对。训练数据集的相似度模式越复杂,训练效果越好。训练集的相似度模式可以用训练集与评估集间的对齐和均匀性的相对大小来衡量。用这种方式,可以发现有监督训练集(NLI)中的相似度模式要比评估集更复杂,而无监督训练集(Wiki)中的相似度模式要比评估集简单。下图说明了这一结论,在对齐和均匀性两个指标上,有监督训练集都要高于评估集,而无监督训练集都要更低。
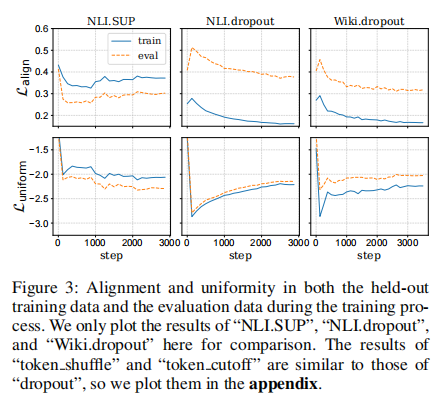
由此本文提出了相对匹配难度Relative Fitting Difficulty (RFD)来评估相似度模式的复杂性,即计算对比学习训练过程中,Bert每个时间步在训练集和评估集的表征的对齐和均匀性的差值,再取平均
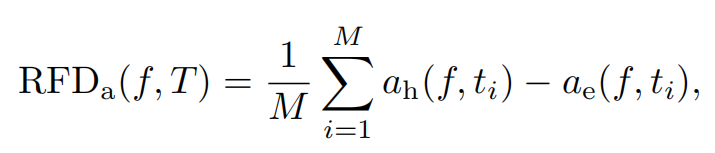
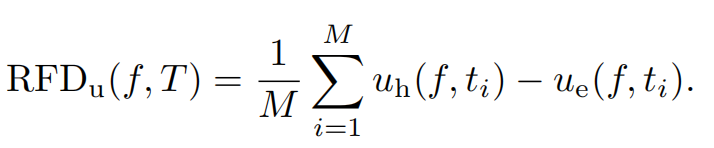
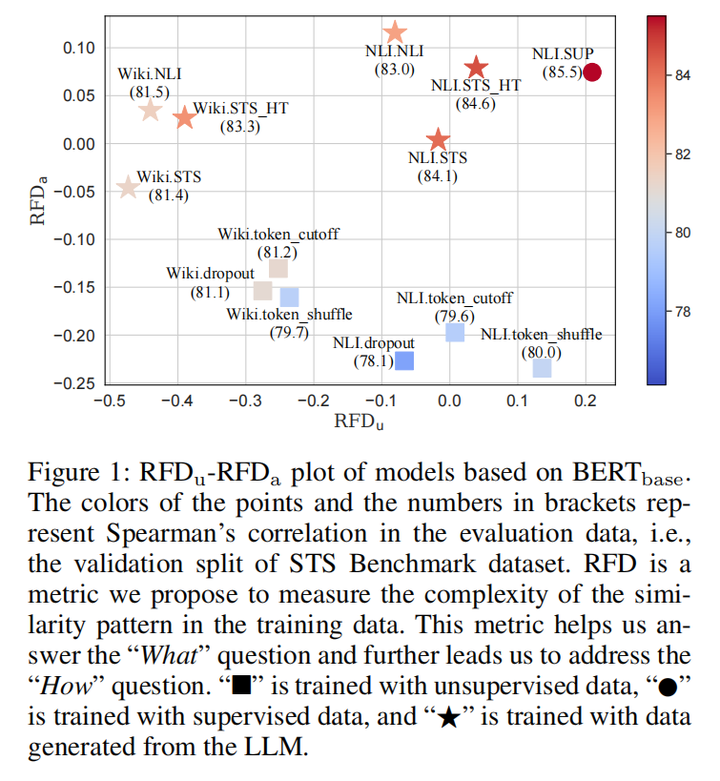
实验表明RFD较大的数据确实能获得更好的效果,下图中右上角的五角星代表本文的训练方法的结果,可以看到相比左下方的之前的无监督训练方式都有明显提升,同时RFD也基本都更大
如何才能缩小性能差距?
接着本文通过LLM的上下文学习,提示LLM模拟了NLI数据(即两个句子是违背还是不违背)和STSSTS数据(将两个句子的相似度分为positive,intermediate,negative,其中中间等级是让语言模型生成比positive细节少一些的句子)
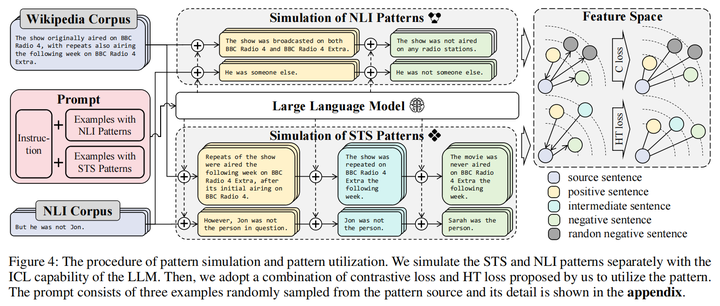
为了有效利用STS生成数据中的层次化结构关系,本文还提出了一种层次化结构的三元损失Hierarchical Triplet (HT) loss
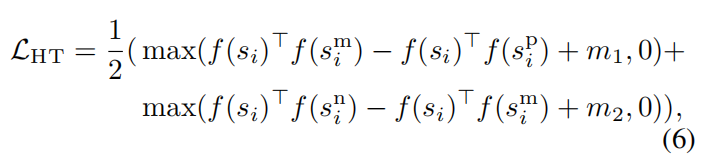
并将这个损失和对比损失结合作为训练目标
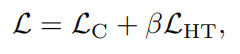
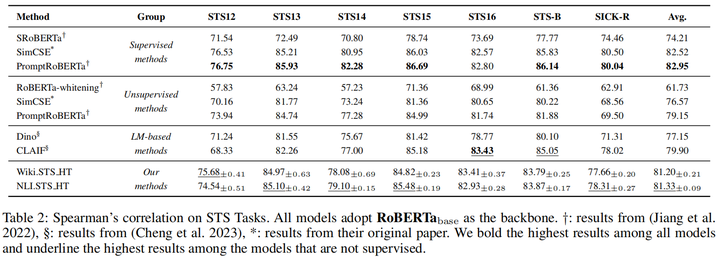
STS实验结果表明确实缩小了有监督和无监督训练的差异,在STS16上完成了反超,不过大部分还是不能达到有监督的水平
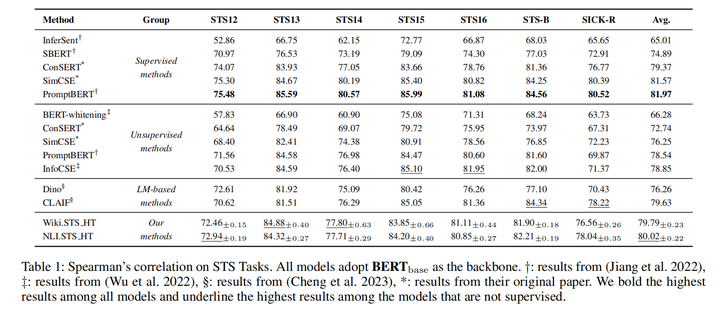
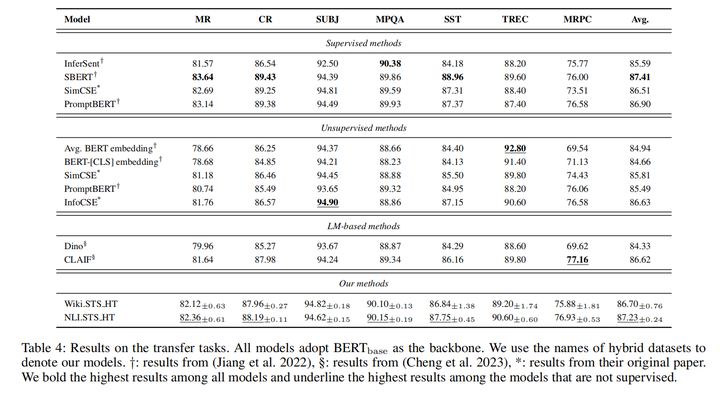
分类任务上将差距缩小到一个点以内,部分结果基本相当
大家好,我是NLP研究者BrownSearch,如果你觉得本文对你有帮助的话,不妨点赞或收藏支持我的创作,您的正反馈是我持续更新的动力!如果想了解更多LLM/检索的知识,记得关注我!
原文地址:https://blog.csdn.net/weixin_45783724/article/details/140455016
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!