自然语言到 SQL 的曙光:我们准备好了吗?
发布于:2024 年 10 月 08 日
各位读者,国庆假期已过,我们打工人要开启奋斗新征程了,今天小编也是刚上班假期综合征还没过去,就被抓过来读论文,还好我在假期没闲着,整理了几篇关于 NL2SQL 的最新论文跟大家分享。
在当今数字化时代,将用户的自然语言问题转换为SQL查询(nl2sql)对于降低访问关系数据库的门槛具有重要意义。随着大型语言模型(LLM)的出现,nl2sql任务的性能得到了显著提升,但这也引发了一个关键问题:我们是否已经完全准备好在生产环境中部署nl2sql模型?
一、nl2sql的发展历程与研究背景
(一)nl2sql方法的演进
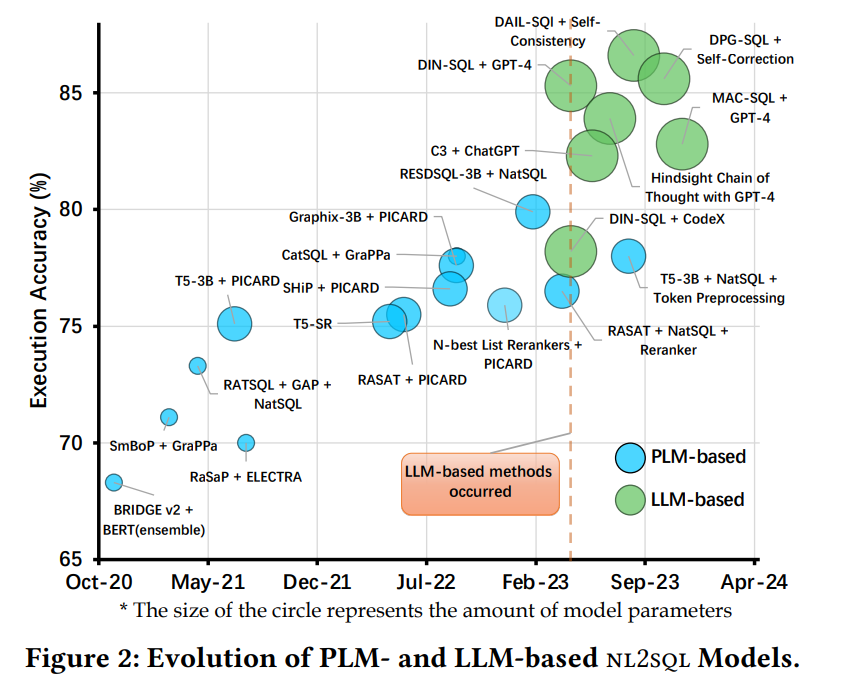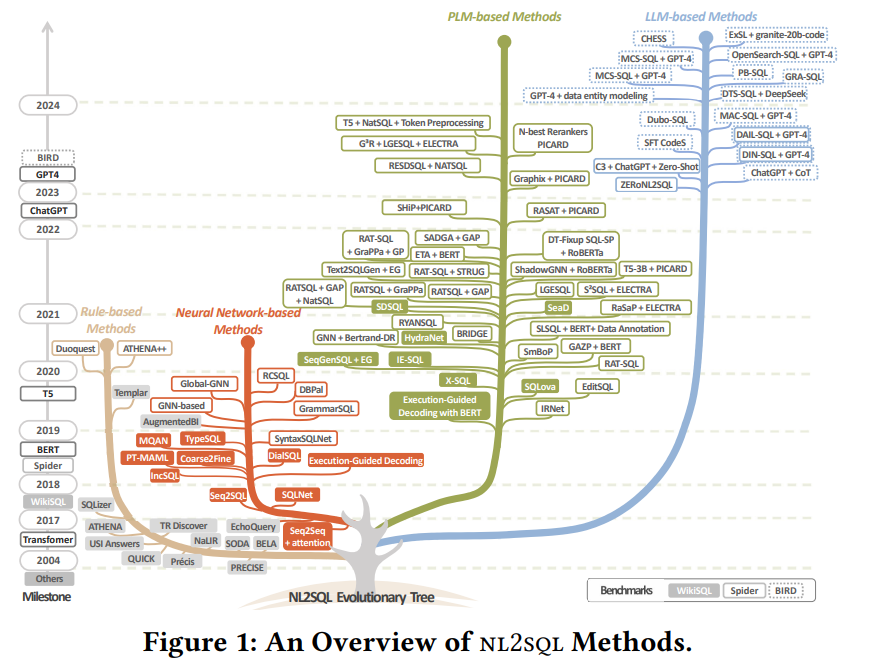
从图1和图2可以看出,nl2sql 方法在过去二十年中经历了从 基于规则 的方法、基于神经网络 的方法、基于可调节预训练语言模型(PLM)到基于大型语言模型(LLM)的演变。早期的基于规则的方法如 NaLIR,依赖于预定义规则或语义解析器,适应性、可扩展性和泛化能力有限。随着神经网络的发展,出现了像IRNet这样的序列到序列方法。2017年左右,Transformer和Spider数据集的引入推动了基于PLM的方法的兴起,例如BERT和T5等模型在基准数据集上取得了很好的结果。而近年来,ChatGPT和GPT - 4等大型语言模型的出现使基于LLM的方法占据了主导地位。
(二)现有研究的局限性
1. **忽视使用场景:**现有评估通常报告在整个基准数据集(如 Spider)上的总体结果,缺乏对特定数据子集的详细比较。例如,没有根据不同的 SQL 特性或数据库领域进行区分,无法深入了解不同 nl2sql 模型对于特定 SQL 查询类型或特定领域场景的相对有效性。 2. **缺乏直接和全面的比较:**许多基于 LLM 和 PLM 的 nl2sql 解决方案没有在成熟的基准和定制数据集上进行系统的比较。 3. **对 nl2sql 设计空间的探索有限:**当前的 nl2sql 研究和实践在使用 LLM 和 PLM 模块探索 nl2sql 框架的设计空间方面存在局限,限制了我们对如何协同整合不同架构和功能模块以增强 nl2sql 解决方案的理解。二、NL2SQL360 评估框架
(一)框架概述
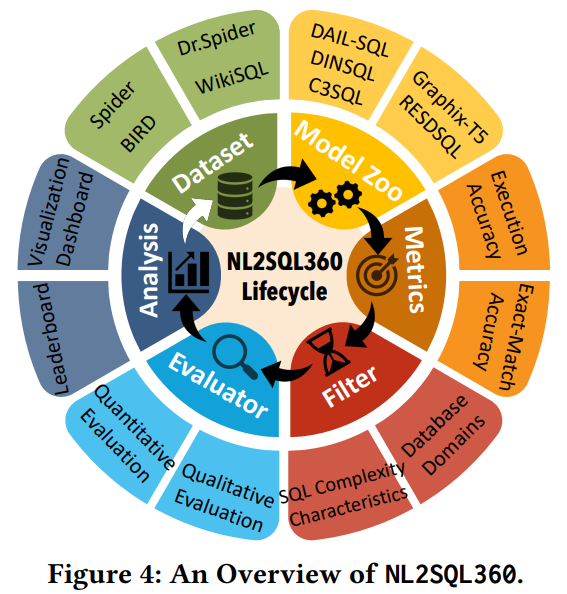为了解决上述问题,本文提出了一个多角度的nl2sql评估框架NL2SQL360,其框架如图4所示,包含六个核心组件。
- 基准数据集(Benchmark Datasts)
维护了广泛使用的基准数据集,如Spider、BIRD、Spider-Realistic、Dr.Spider、KaggleDBQA、WikiSQL 等。 - 模型库(Model Zoo)
包含了在 Spider 和 BIRD 排行榜上的一系列有竞争力的开源 nl2sql 模型,主要包括基于 LLM 和基于 PLM 的方法。 - 数据集过滤(Dataset Filter)
引入了数据集过滤机制,可根据不同标准将测试数据集分离为更有针对性的子集。例如:
- SQL 复杂性(SQL Complexity):从简单到复杂的查询进行分类,以评估nl2sql方法处理不同难度SQL的能力。
- SQL 特性(SQL Characteristics):针对主要使用特定功能(如JOIN操作、子查询或聚合函数)的SQL查询进行分类,评估系统处理不同SQL功能的能力。
- 数据领域(Data Domains):探索系统在不同数据领域(如金融、医疗保健和零售)的性能,评估领域特定的能力和潜在限制。
- 查询方差测试(Query Variance Testing):评估nl2sql系统在处理自然语言查询变化时的稳健性和灵活性。
4. 评估器(Evaluator)
利用日志数据自动生成定量评估,并以易于理解的表格或排行榜形式呈现。还提供可视化工具和仪表板进行交互式分析,方便用户比较不同维度的nl2sql解决方案。
5. 评估指标(Evaluation Metrics)
采用了一系列广泛接受的指标,包括执行准确率(Execution Accuracy,EX)和精确匹配准确率(Exact Match Accuracy,EM)来评估生成的 SQL 查询的有效性,使用有效效率得分(Valid Efficiency Score,VES)来衡量生成有效 SQL 查询的效率。此外,还提出了查询方差测试(Query Variance Testing)这一新指标,用于评估模型对不同形式的自然语言查询的适应能力。
6. 执行器和日志(Executor and Logs)
用户可以定制 nl2sq l模型的评估工作流程,设置超参数和指标等参数。测试床会自动在基准数据集和自定义子集上运行模型,并记录所有结果,这些日志为模型分析提供了详细的见解。
(二)实验设置与结果分析
1. **实验设置** 使用 Spider 和 BIRD 数据集的开发集作为实验数据集,包含1034和1534个(nl,sql)样本。评估了 13 种基于 LLM 和 7 种基于 PLM 的 nl2sql 方法,比较了不同方法在准确性、效率等方面的性能。 2. **准确性实验结果**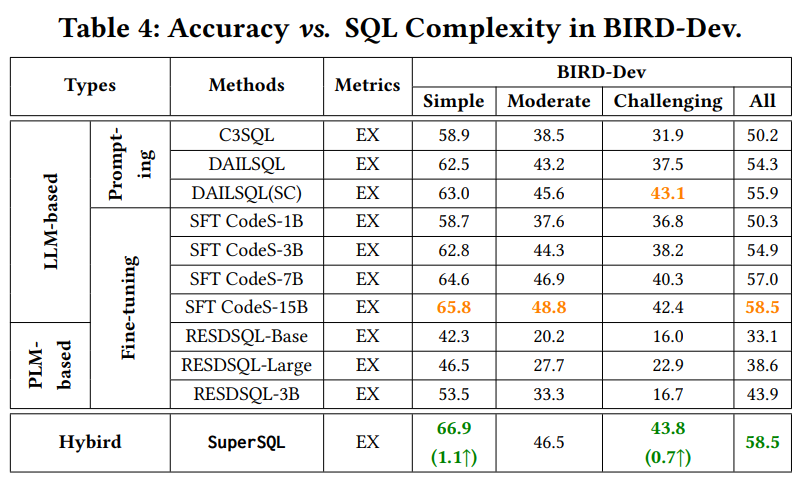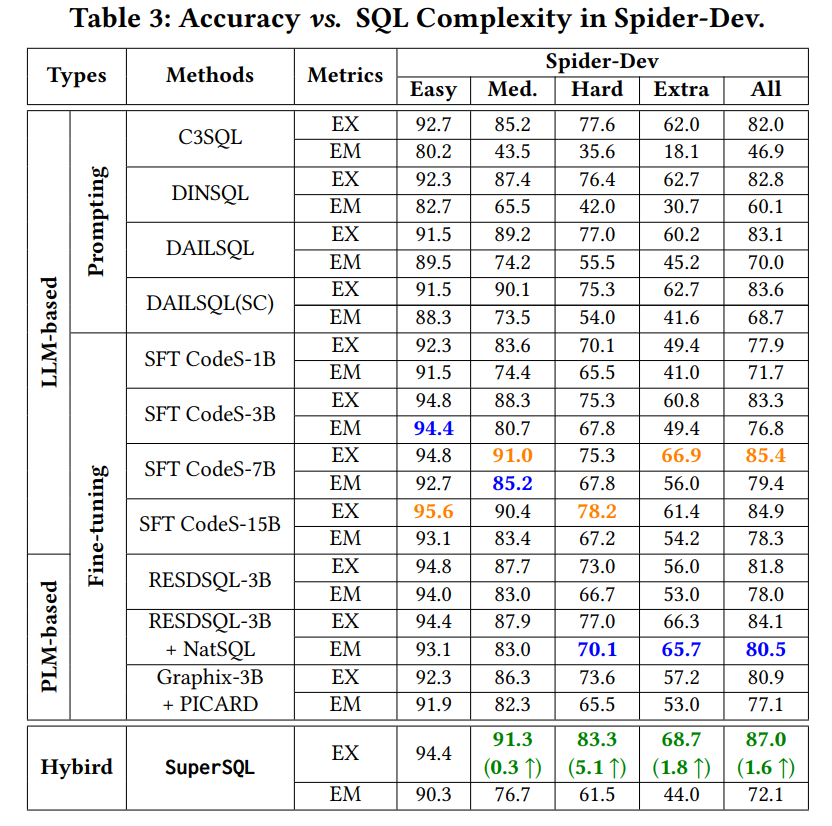 - **准确性与SQL复杂性** 从表3和表4可以看出,在不同难度的SQL子集上,基于LLM的方法在执行准确率(EX)指标上超过基于PLM的方法,而基于PLM的方法在精确匹配准确率(EM)指标上总体表现更好。这表明微调是提高性能的重要策略,基于LLM的方法微调后在EX指标上表现最佳,基于PLM的方法在EM指标上表现最佳。 - **准确性与SQL特性**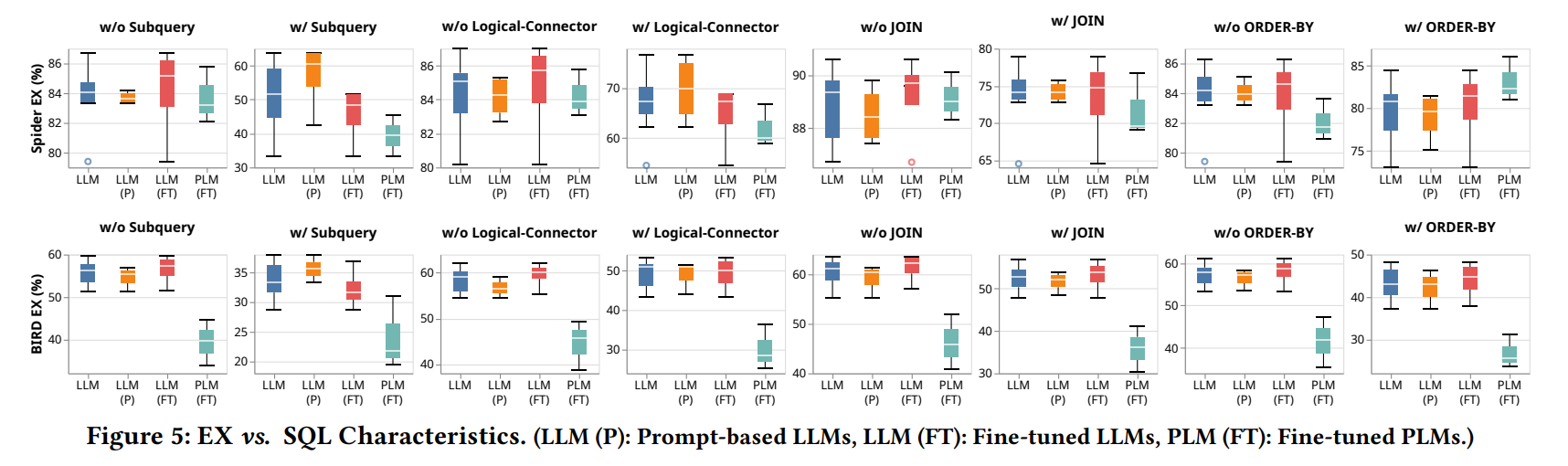 - 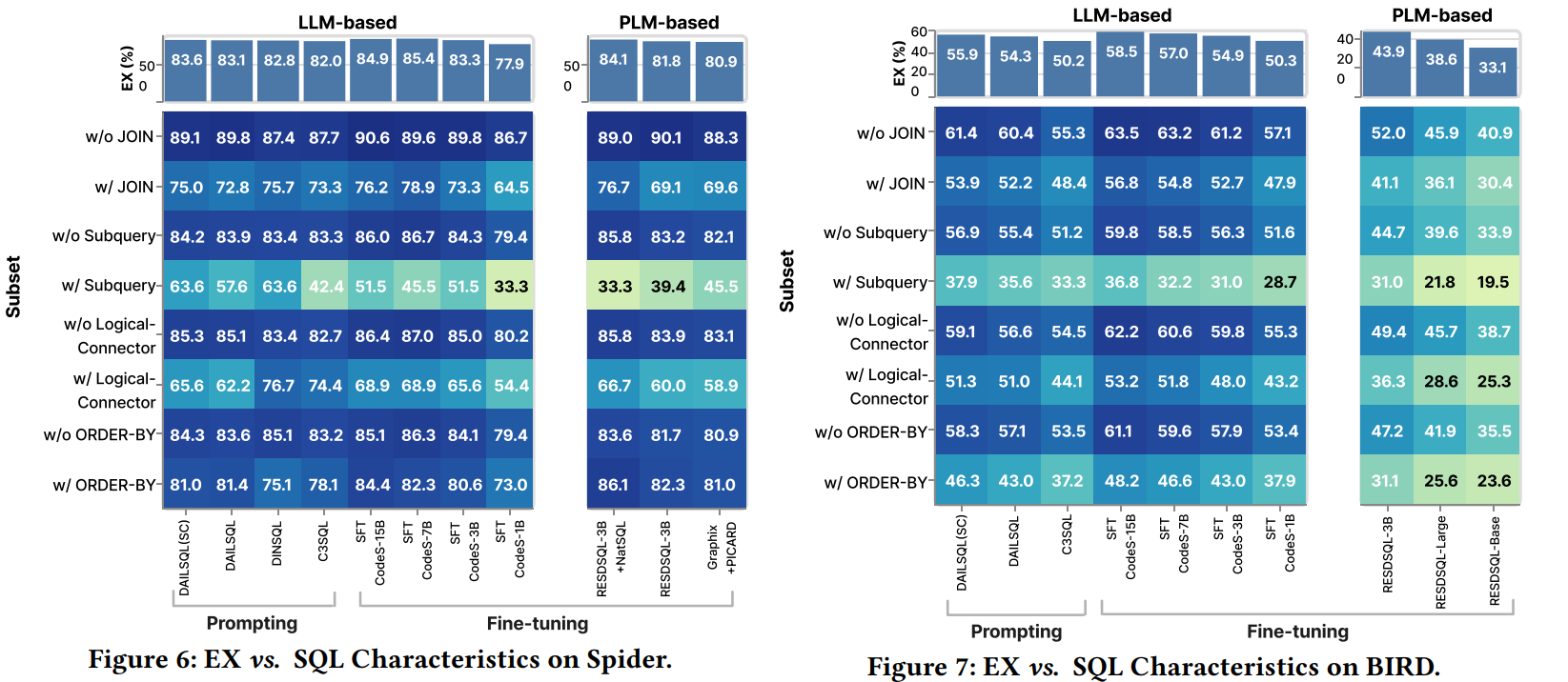 * **子查询(Subquery)**:如图5、图6和图7所示,所有方法在处理子查询时表现最差,但基于LLM的方法在有子查询的场景中总体上优于基于PLM的方法,尤其是使用 GPT-4 的方法表现更好,这表明模型的内在推理能力对处理子查询至关重要。 * **逻辑连接器(Logical Connector)**:在需要逻辑连接器的场景中,基于LLM 的方法优于基于PLM的方法。 * **JOIN操作**:在涉及JOIN操作的场景中,基于LLM的方法也表现出优势,将NatSQL作为中间表示可以降低预测JOIN操作的复杂性并可能提高模型性能。 * **ORDER BY**:在有ORDER BY子句的场景中,基于PLM和LLM的方法在不同数据集上的性能有所不同,一般来说基于LLM的方法具有更强的泛化能力。 - **查询方差测试**: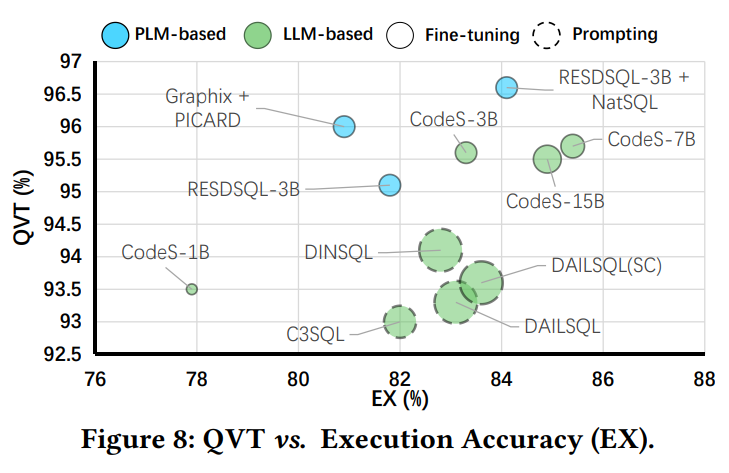从图8可以看出,在查询方差测试(QVT)指标上,基于LLM和基于PLM的方法没有明显的胜者,但微调后的LLM通常比提示的LLM具有更高的QVT,这可能是由于微调后模型输入与特定数据分布对齐,减少了自然语言变化对性能的影响。 - **数据库领域适应性**: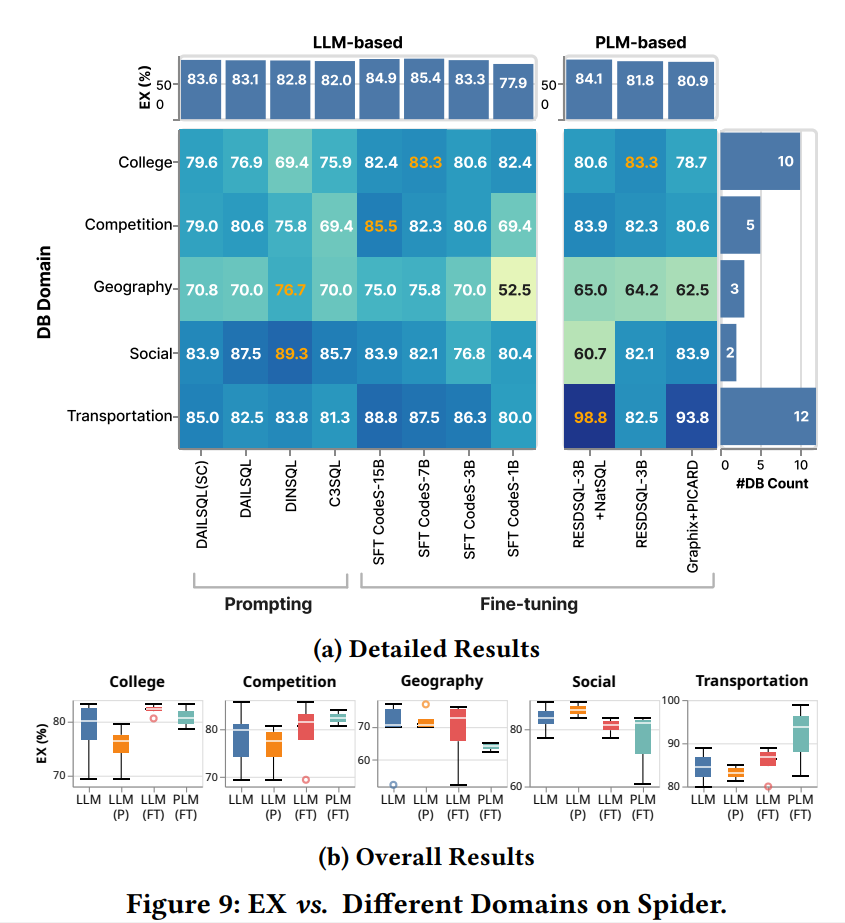如图9所示,不同的 nl2sql 方法对不同领域表现出不同的偏向,基于LLM和基于PLM的方法之间没有明显的胜者。但微调后的方法在有更多训练数据库的领域表现更好,而提示的方法在训练数据库较少的领域表现出色,这表明微调过程中的领域内数据对特定领域的模型性能至关重要。 3. **效率实验结果** - **基于LLM的方法的经济性**:从表5可以看出,基于提示的LLM方法中,调用GPT-3.5-turbo的方法在执行准确率与平均成本的比率上更高,具有更高的成本效益。虽然 DAILSQL(SC)在执行准确率上有所提高,但成本也增加,降低了成本效益。 - **基于PLM的方法的效率**:从表6可以看出,随着模型大小的增加,GPU内存和延迟也会增加。不同的基于PLM的方法在执行准确率、延迟和GPU内存使用方面表现不同,模型选择应考虑延迟和硬件资源。三、nl2sql设计空间探索与SuperSQL模型
(一)设计空间探索
1. **预处理(Pre - Processing)** 包括模式链接和数据库内容模块。模式链接将自然语言查询引用映射到数据库模式元素,增强跨领域通用性和复杂查询生成;数据库内容模块将查询条件与数据库内容对齐。 2. **提示策略(Prompting Strategy)** 分为 zero-shot和 few-shot策略。PLM-based方法通常使用 zero-shot,而 LLM-based 方法则有所不同,如C3SQL采用 zero-shot,DAILSQL和DINSQL使用 few-shot。 3. **SQL生成策略(SQL Generation Strategy)** 包括多步、解码策略和中间表示三个关键方面。不同的方法采用不同的策略,如PLM - based的RESDSQL采用“sql skeleton-sql”的多步策略,LLM-based的 DINSQL 采用“Subquery-sql”的多步策略;PLM-based 的 PICARD 采用强制 SQL 语法合规的解码策略,而 LLM-based 方法缺乏这种解码级别的限制;一些方法采用 NatSQL 作为中间表示来解决自然语言到 SQL 翻译的不匹配问题。 4. **后处理(Post - Processing)** 包括自我纠正、自我一致性、执行引导的SQL选择器和 N-best重排器等策略。(二)NL2SQL360 - AAS 算法与 SuperSQL 模型
1. **NL2SQL360 - AAS 算法** 受到神经架构搜索(NAS)算法的启发,在 NL2SQL360 框架内设计了 nl2sql 自动化架构搜索算法(NL2SQL360 - AAS)。该算法包括初始化、个体选择、nl2sql 模块交换和 nl2sql 模块突变四个主要步骤,旨在自动探索 nl2sql 解决方案的预定义设计空间,以找到更好的 nl2sql 个体。 2. **SuperSQL模型** 通过 NL2SQL360 - AAS 算法在 Spider 开发集上搜索得到的 SuperSQL 模型,其组成如下: - **预处理**:采用 RESDSQL 的模式链接和 BRIDGE v2 的数据库内容模块。 - **提示**:使用 DAILSQL的 Few-shot模块按相似性选择上下文示例。 - **SQL生成**:采用OpenAI的贪婪解码策略,不使用多步或NatSQL。 - **后处理**:采用DAILSQL的自我一致性策略。 SuperSQL在Spider和BIRD测试集上分别取得了87.0%和62.66%的执行准确率,在执行准确率、效率和经济性等方面均表现出色,优于其设计空间内的所有基线模型。四、研究机会与未来方向
(一)提高nl2sql方法的可信度
1. **处理模糊的自然语言查询** 可以探索查询重写器自动优化自然语言查询,以及查询自动完成帮助用户制定查询的策略。 2. **解释nl2sql解决方案** 开发nl2sql调试器检测错误的SQL查询,以及SQL和查询结果解释方法帮助用户评估结果是否符合要求。(二)开发具有成本效益的nl2sql方法
基于LLM的nl2sql方法在令牌消耗方面成本较高,探索模块化nl2sql解决方案和多智能体框架,结合LLM优化准确性和效率是未来的研究方向。(三)自适应训练数据生成
nl2sql方法的有效性很大程度上取决于训练数据的质量和覆盖范围,动态生成(nl,sql)对使用模型评估反馈是一个有前途的研究方向,可以解决领域适应问题并确保训练数据的多样性和高质量。五、结论
本文提出了NL2SQL360评估框架,从多个角度对nl2sql方法进行了评估和分析。通过实验研究得出了一系列关于nl2sql方法性能的新发现,并利用NL2SQL360探索了nl2sql解决方案的设计空间,自动搜索得到了SuperSQL模型。SuperSQL模型在不同的数据集和测试指标上表现出色,为nl2sql任务提供了一种有效的解决方案。同时,本文还指出了未来nl2sql研究的几个方向,包括提高方法的可信度、开发成本效益高的方法和自适应训练数据生成等。这些研究成果为nl2sql领域的进一步发展提供了重要的参考和指导。:::info
论文地址:https://arxiv.org/pdf/2406.01265
The Dawn of Natural Language to SQL: Are We Fully Ready?
代码地址:https://github.com/HKUSTDial/NL2SQL360
原文链接:https://mp.weixin.qq.com/s/BCxFZ2EV1xh-VlYYyR1FgQ
:::
希望这篇文章能让您对论文的核心内容有更深入的了解,如果您有任何问题或建议,欢迎在评论区留言。

原文地址:https://blog.csdn.net/u014021753/article/details/142763195
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!