【R语言】概率密度图
概率密度图是用来表示连续型数据的分布情况的一种图形化方法。它通过在数据的取值范围内绘制一条曲线来描述数据的分布情况,曲线下的面积代表了在该范围内观察到某一数值的概率。具体来说,对于给定的连续型数据,概率密度图会使用核密度估计(Kernel Density Estimation,KDE)等方法来估计数据的概率密度函数。然后,在数据的取值范围内绘制一条平滑的曲线,曲线在不同取值处的高度表示了该取值出现的概率密度,即在该取值附近观察到数据点的频率。
概率密度图通常用于比较不同组或不同条件下连续型数据的分布情况。在这个图中,不同组或条件的密度曲线以不同的颜色或图案进行区分,使得用户可以直观地比较它们的分布形状、中心趋势以及离散程度。
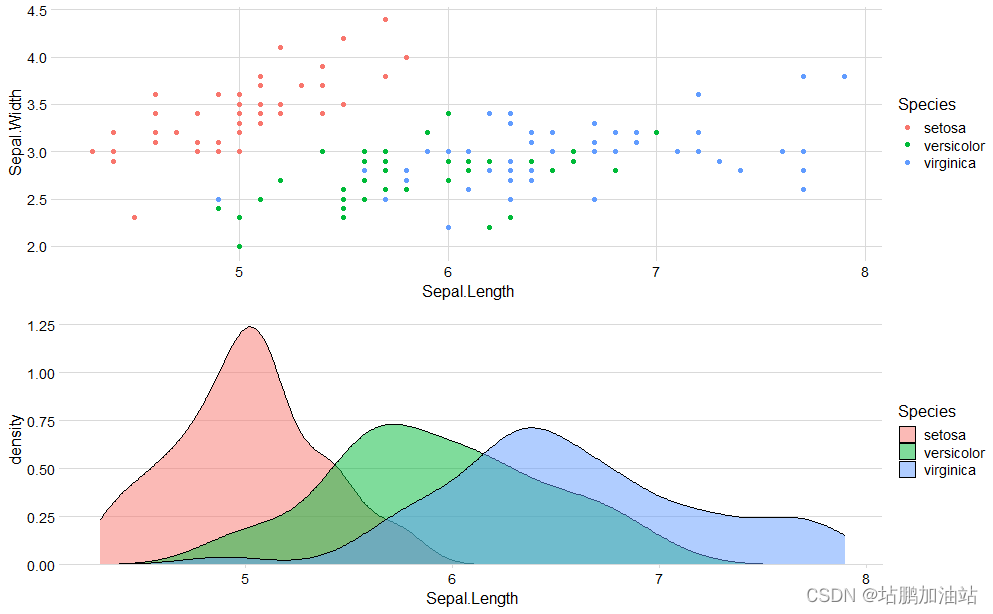
代码如下:
library(ggplot2)
library(cowplot)
library(gridExtra)
# 第一个图,绘制了 iris 数据集中 Sepal.Length 与 Sepal.Width 的散点图,根据 Species 分组着色
plot1 <- ggplot(iris, aes(Sepal.Length, Sepal.Width, color = Species)) +
geom_point() +
theme_minimal_grid(12)
# 第二个图,绘制了 iris 数据集中 Sepal.Length 的密度图,根据 Species 填充颜色
plot2 <- ggplot(iris, aes(Sepal.Length, fill = Species)) +
geom_density(alpha = 0.5) +
scale_y_continuous(expand = expansion(mult = c(0, 0.05))) +
theme_minimal_hgrid(12)
# 使用 grid.arrange() 函数将 plot1 和 plot2 组合在一起。nrow 参数指定了行数为 2,即两个图形将竖直排列。heights 参数指定了每行的高度,这里使用了相等的高度
combined_plot <- grid.arrange(plot1, plot2, nrow = 2, heights = c(1, 1))
# 展示组合后的图
combined_plot原文地址:https://blog.csdn.net/a11113112/article/details/137891594
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!