C++从入门到出门
C++ 概述
c++ 融合了3中不同的编程方式:
- C语言代表的过程性语言
- C++ 在C语言基础上添加的类代表的面向对象语言
- C++ 模板支持的泛型编程
1、在c语言中头文件使用扩展名.h,将其作为一种通过名称标识文件类型的简单方式。但是c++得用法改变了,c++头文件没有扩展名。但是有些c语言的头文件被转换为c+ +的头文件这些文件被重新命名,丢掉了扩展名.h(使之成为c++风格头文件),并在文件名称前面加上前缀c(表明来自c语言)。例如c++版本的math.h为cmath
2、namespace是指标识符的各种可见范围。命名空间用关键字namespace 来定义。命名空间是C++的一种机制,用来把单个标识符下的大量有逻辑联系的程序实体组合到一起。此标识符作为此组群的名字。
std就是命名空间(名字空间)的名字, 命名空间的作用主要是为了解决日益严重的名称冲突问题。随着可重用代码的增多,各种不同的代码体系中的标识符之间同名的情况就会显著增多解决的办法就是将不同的代码库放到不同的名字空间中。
思考:假如在项目中需要定义两个函数func,并且都能够被其他文件所访问到该怎么办?
3、cout是c++中的标准输出流,endl是输出换行并刷新缓冲区。
C++ 标准
一种描述C++ 的一些语法规则的代码准则
C++11
C++ 应用
- 游戏
- C++ 效率是一个很重要的原因,绝大部分游戏殷勤都是C++写的
- 网络软件
- c++拥有很多成熟的用于网络通信的库,其中最具有代表性的是跨平台的、重量级的ACE库,该库可以说是C++ 语言最重要的成果之一。
- 操作系统
- 在该领域,c语言是主要的编程语言,但是c++凭借对c的兼容性,面向对象也开始应用在该领域
- 嵌入式系统
C++ 编译器安装
C++ 基础
命名空间
- 创建名字是程序设计过程中的基本活动,当一个项目很大的时候,名字会大量重叠,c++允许我们对名字的产生和名字的可见性进行控制
- 我们之前在学习c语言可以通过static关键字来是的名字只在本编译单元内课件,在c++ 中我们通过一种命名空间来控制对名字的访问。
- c++中,名称(name)可以是符号常量、变量、宏、函数、结构、枚举、类、对象…
- std是c++ 标准命名空间,c++标准程序库中的所有标识符都被定义在std中,比如标准库中的类iosstream、vectore等都定义在该命名空间中,使得要加上using声明或者using指示
-
命名空间的使用:
命名空间定义:
namespace 名称 { // 定义变量、函数、类型、对象 }命名空间 ( 全局范围内定义 ) 访问:
#include <iostream> ussing namspace std; namespace A { int a = 10; } namespace B { int b = 20; } int main(){ count << "a:" << A::a << endl; count << "b:" << B::b << endl; return 0; }
注意事项:
命名空间只能在
全局范围内定义。
引用
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它与引用的变量共用同一块内存空间。
引用的本质:
- C++ 编译器在编译过程中使用常量指针作为引用的内部实现,因此引用所占用的空间大小与指针相同,只是这个过程是编译器内部实现,用户不可见
Type& ref = val; // Type* const ref = & val;

1、引用可以看作是一个一定义变量的别名
2、引用的语法:Type& name = vars;
注意:
1 & 再次不是求地址运算,而是起标识作用
2、类型标识符是指目标变量的类型
3、必须在声明引用变量时
4、引用初始化之后不能改变
5、不能有null引用,必须确保引用是和一块合法的存储单元关联
6、一个变量可以有多个引用(相当于一个变量有好几个别名)
- 错误写法
int main(){
int a = 10;
int& b = a;
// 定义没有初始化
int& x;
// 没有空引用
int& y = NULL;
// 没有所谓的二级引用
int&& c = 1;
}
交换2个变量的数值: 使用引用来做
#include <iostream>
using namespace std;
void my_swap (int& a,int& b)
{
int tmp = a;
a = b;
b = tmp;
}
int main ()
{
int x = 10, y = 20;my_swap(x,y) ;
cout << " x = " << x<< " y = " << y << endl;
// x = 20 y = 10
return 0;
}
总而言之:
引用本身是一个变量,但是这个变量又仅仅是另外一个变量一个别名,它不占用内存空间,它不是指针哦!仅仅是一个别名!
引用和指针的区别:
1、语法层面的区别
-
从语法规则上讲,指针变量存储某个实例(变量或对象)的地址;(引用是某个实例的别名。)
-
程序为指针变量分配内存区域;而不为引用分配内存区域。
int main() { int a = 10; int* ip = &a; int& b = a; \\b是a的别名 并没有分配新的空间 } -
解引用是指针使用时要在前加“*”;引用可以直接使用。
int main() { int a = 10; int* ip = &a; int& b = a; *ip = 100;//对于指针使用加“*” b = 200; //引用不需要“*” } -
指针变量的值可以发生改变,存储不同实例的地址;
引用在定义时就被初始化,之后无法改变(不能是其他实例的引用)。int main() { int a = 10,b = 20; int* ip = &a; ip = &b ; int& c = a; c = b; //b的值给c实则是把b的值给a,将a的值改为20 } -
指针变量的值可以为空(NULL,nullptr);没有空引用。
-
指针变量作为形参时需要测试它的合法性(判空NULL);【引用不需要判空。】
-
对指针变量使用"sizeof"得到的是指针变量的大小
-
对引用变量使用"sizeof"得到的是变量的大小
int main() { double dx = 10; double* dp = &dx; double& a = dx; printf("sizeof(dp):%d\n", sizeof(dp)); // 4 printf("sizeof(a):%d", sizeof(a)); // 8 } -
理论上指针的级数没有限制;但引用只有一级。
即不存在引用的引用,但可以有指针的指针。 -
++引用与++指针的效果不一样。
int main() ( int ar[5] = { 1,2,3,4,5 }; int* ip = ar; //数组首元素地址 int& b = ar[O]; //数组首元素的别名叫b ++ip; //由0下标的地址指向1下标的地址 ++b; //由0下标指向1下标 }
更多细节:参考引用单独详解 | 和指针区别
内联函数
特性
- 内联函数不能声明与定义分离,如果分离,必会发生链接错误。
- C++ 推荐使用内联函数替代宏代码片段
- 内联函数在最终生成的代码中是没有定义的,C++ 编译器直接将函数体插入在函数嗲用的地方,内联函数没有普通函数调用时的额外开销( 压栈、跳转、返回 )
- 因为内联函数在最终生成的代码中时没有定义的,所以内联函数的作用域可以理解成只在定义的文件中。加入在a.cpp中定义了
inline int func ( int a ) { return ++a; }. 如果在b.c 中需要调用func函数,则在b.cpp中需要重新定义内联函数inline int func( int a ) { return ++a; } - inline 只是对编译器的一个内联请求,c+++ 内联编译会有一些限制,一下情况编译器可能不会考虑将函数进行内联编译:
- 存在任何形式的循环语句
- 存在果果的条件判断语句
- 函数体过于庞大
- 对函数进行取址操作
因此,内联仅仅只是给编译器一个建议,编译器不一定会接受这种建议,如果你没有将函数声明为内联函数,那么编译器也可能将此函数做内联编译。一个好的编译器将会内联小的、简单的函数。
函数默认参数
这里参考前端里面的Typscript 默认参数语法
函数重载
概念:
- 同一个函数名定义的不同函数
- 当函数名和不同的参数搭配时函数的含义不同
条件
- 同一个作用域
- 参数个数不同
- 参数类型不同
- 参数顺序不同
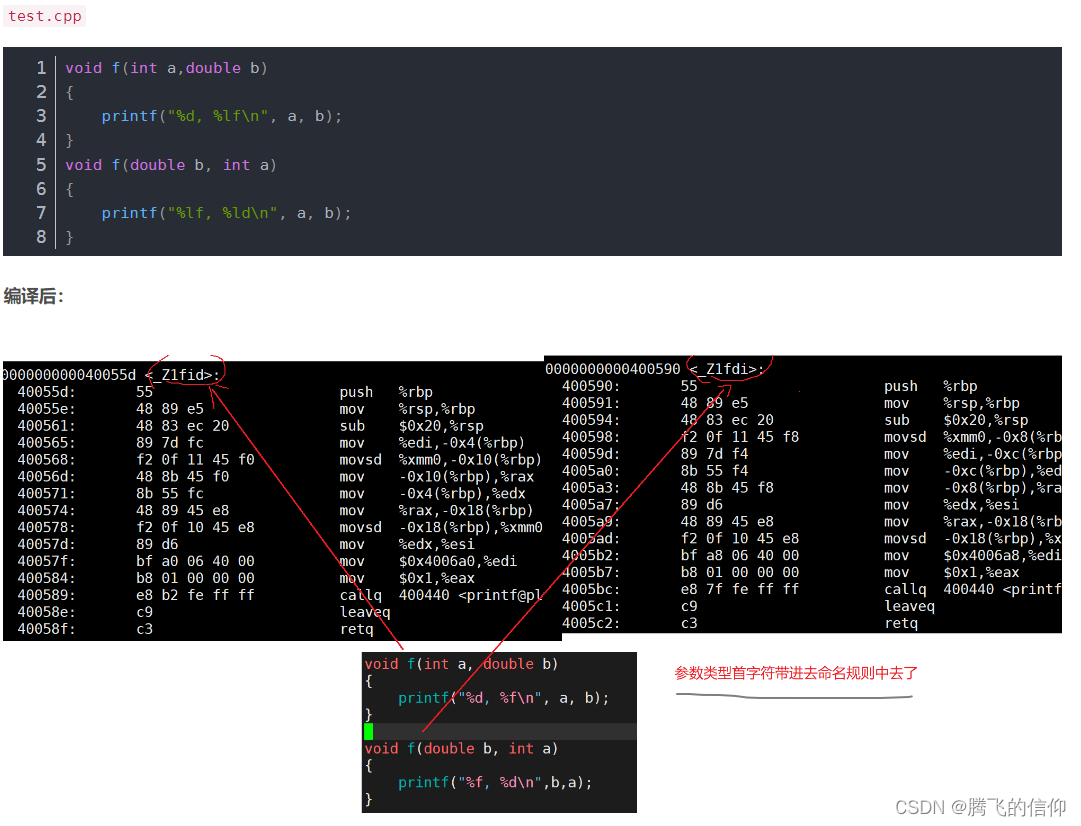
函数重载的本质原理:(g++ 编译器,编译成了多个函数地址)
类 、对象
基本概念
1、现实世界的事物都具有的共性就是每个事物都具有本身的属性,一些自身具有的行为,例如一个学生有姓名、性别、年龄等属性,吃饭睡觉等行为。
2、类对于某个事物的描述起始还是抽象的,例如有一类事物有姓名、性别、年龄等属性,可以吃饭睡觉玩游戏等。如果只是描述的话起始我们还是不知道这个事物具体是什么样,因为这个类没有告诉我们每个属性具体的值是多少(这个事物的姓名是什么,年龄是多少),所以类只是对某一类事物的一个描述而已。实际应用中我们需要操作某类事物中的一个或者多个具体的事物。那么这个具体的事物我们就称之为对象。
3、类是抽象的,对象是具象的。
4、对象是怎么来的呢? 由类实例化来,因此我们也说通过一个类实例化一个对象。
1、在C++中可以给成员变量和成员函数定义访问级别。
- ·
public公有的,修饰成员变量和成员函数可以在类的内部和类的外部被访问 - ·
private私有的,修饰成员变量和成员函数只能在类的内部被访问 ·protected被保护的,修饰成员变量和函数只能在类的内部被访问
//student.h
#ifndef _STUDENT_H_
#define _STUDENT_H_
#include <iostream>
using namespace std;
class Student
{
public:
int GetAge() {
return m_age;
}; //声明类的成员函数,在函数的其它地方实现
int SetAge(int age) {
// 参数合法性限制
if(age < 0 || age > 200 ) return;
m_age = age;
};
private:
int m_age;
char m_name[32];
};
#endif
如果某些属性不想被外部修复访问、则可以设置成private 关键字,继续保护
不过类提供一种机制来实现内部成员变量的修改和访问,就是通过·public· 声明的函数,来供类外部进行访问,修改。
面向过程 | 对象
-
面向过程
- 数据结构 + 算法
- 用户需求简单而固定
- 特点:
- 分析解决问题所需步骤
- 利用函数实现各个步骤
- 依次调用函数解决问题
-
面向对象程序设计 【 由现实世界建立软件模型 】
- 属性:静态特征,可以用某种数据来描述
- 方法:动态特征,对象所表县的行为或者具有的功能
将现实世界的事物直接映射到程序中,可直接满足用户需求 - 特点
- 直接分析用户需求中设计的各个实体
- 在代码中描述现实世界中的实体
- 在代码中关联各个实体协同工作解决问题
- 优势:
- 构建的软件能够适应用户需求的不断变化
-
面向对象三大特征
- 封装
- 将变量(属性)个函数(操作)合成一个整体,封装在一个类中
- 尽可能屏蔽对象的内部细节,对外形成一个边界,值保留有限的对外接口使之与外部发生联系
- 继承
- 多态
- 封装
参考文章
原文地址:https://blog.csdn.net/qq_19343801/article/details/138011936
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!