Spark内核的设计原理
导读:
本期是DataFun深入浅出Apache Spark第一期的分享,主讲老师耿嘉安开场介绍了自己的从业经历,当前就职的数新网络与Spark相关的两款产品赛博数智引擎CyberEngine和赛博数据智能平台CyberData。
本次分享题目为《Spark内核的设计原理》,主要介绍:
-
初识Spark
-
Spark有哪些特点
-
Spark基本概念
-
Spark的核心功能
-
Spark模型设计
-
Spark部署架构
▌初识Spark
Spark是一个通用的并行计算框架,由加州伯克利大学的AMP实验室在2009年开发,并且在2010年以0.6版本开源,2013年左右成为Apache旗下在大数据领域最活跃的开源项目之一。

▌Spark有哪些特点
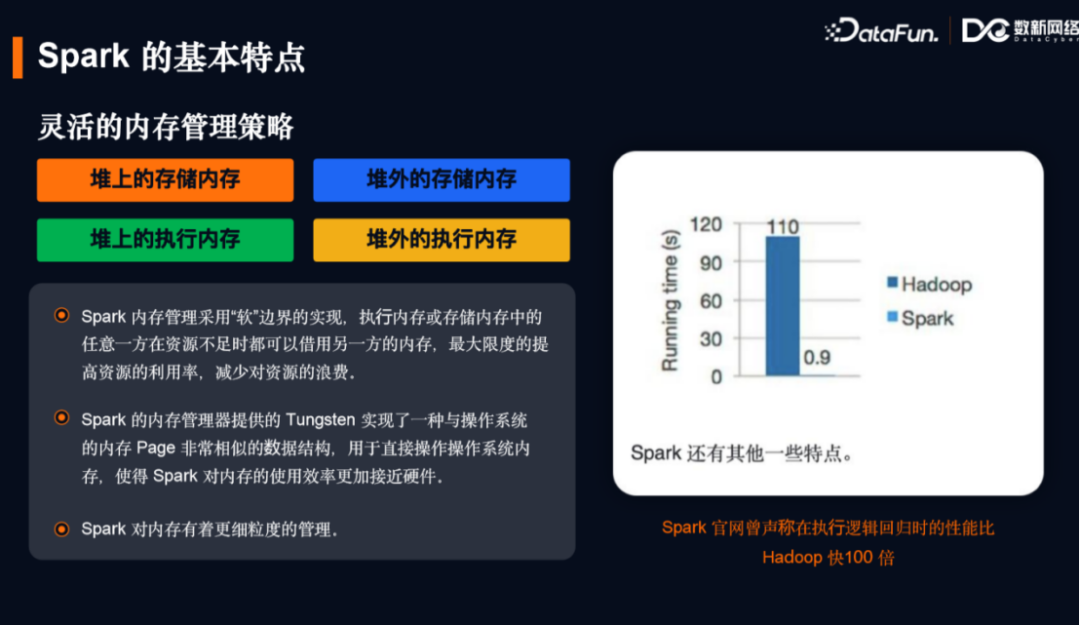
Spark的基本特点可归纳为以下五点:灵活的内存管理,灵活的并行度控制,可选的Shuffle排序,避免重新计算,减少磁盘I/O。

1.灵活的内存管理
减少了内存溢出的问题,用逻辑规划将JVM内存按照堆内/堆外,存储/计算分为四个象限。其中执行和存储内存的边界并不固定,通过逻辑规划来进行约定,可以相互借用,以此来提高内存资源的利用率,减少资源的浪费。Spark 1.4版本在内存管理器上通过“钨丝计划(Tungsten)”实现了一种与操作系统内存页非常相似的数据结构,内存管理可以直接向操作系统申请/释放内存,避免了JVM额外的开销,使得内存分配效率更加接近硬件。同时Spark有任务级别的内存管理,任务的计算属于执行内存的一部分。
2.灵活的并行度控制
Spark通过Shuffle依赖的关系把不同的环节抽象为Stage的概念,允许多个Stage既可以串行执行,又可以并行执行提升并行度。同时Stage内部由一系列的RDD组成,RDD允许用户自定义自身的并行度,能够更加有效应对海量数据的场景。
3.科学的Shuffle排序
Hadoop早期的MR在Shuffle之前会有固定的排序,便于后期Reduce端拉取数据。对于Spark这点是可选步骤,根据场景特点可在Shuffle之前的Map端或者之后的Reduce端进行排序。
4.避免重新计算
从Stage构建出来的DAG血缘关系能够在执行失败的时候重新调度,加上对检查点的支持可以避免重复计算,这点对于大数据量场景下的稳定运行非常关键。
5.减少磁盘I/O
最早期的时候,Spark和MapReduce类似,在Map端生成中间数据时,会针对每个Reduce端生成文件,从而产生很多小文件。后期Spark版本优化引入分区索引,Map端不会为下游Reduce端单独生成小文件,而是通过索引构建文件的方式,用偏移量为下游Reduce端拉取数据做服务。每个分区是顺序写的方式,在Reduce端读数据的时候也是顺序读取,避免了随机读,减少了大量的磁盘I/O开销。同时Spark Driver端支持把通过spark-submit命令提交的jar包等资源文件缓存到本地服务内存中,在Executor端执行的时候可以直接通过Netty拉过去,也是一个节省I/O方面的改进。
6.Spark的其他特点
包括检查点支持,易于使用(支持Java,Scala,Python等编程语言),交互式(Spark Shell)和SQL分析(借鉴了ANSI SQL等标准的实用语法和功能),批流一体,丰富的数据支持,高可用,丰富的文件格式支持


▌Spark基本概念
1. 弹性分布式数据集RDD
-
Spark的转换(transform)API可以将RDD封装为一系列具有血缘关系(DAG)的RDD。
-
Spark的动作(action)API会将RDD及其DAG提交到DAGScheduler。
-
转换API和动作API总归都是在处理数据,因此RDD的祖先一定是一个跟数据源相关的RDD,负责从数据源迭代读取数据。
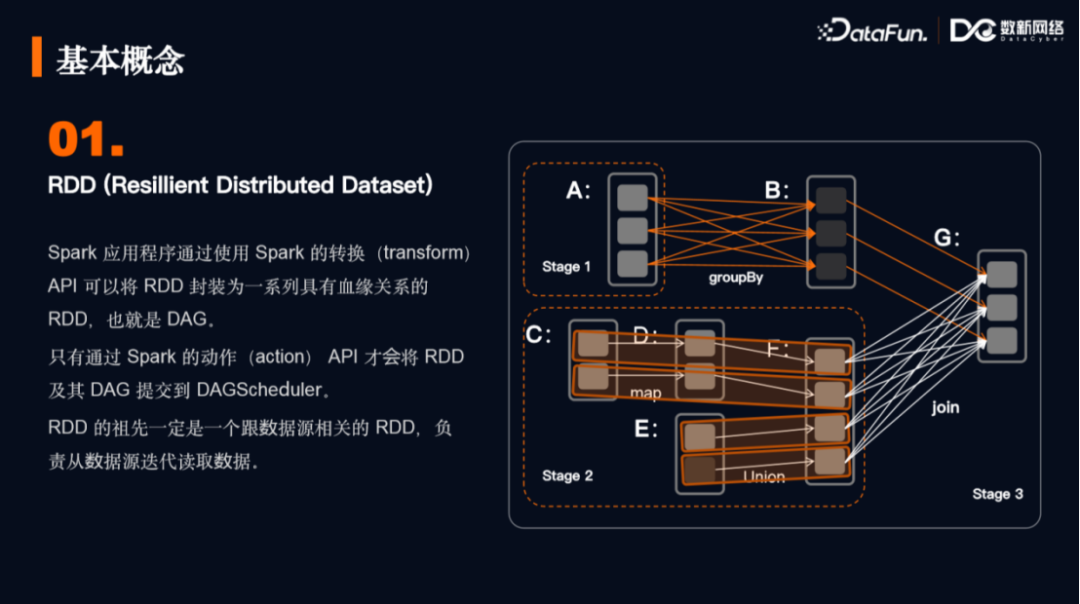
上图展示了Stage抽象和RDD分区的概念,体现了并行性;同时也展示了宽窄依赖的关系:图内的map和union是窄依赖,join和groupby是宽依赖。
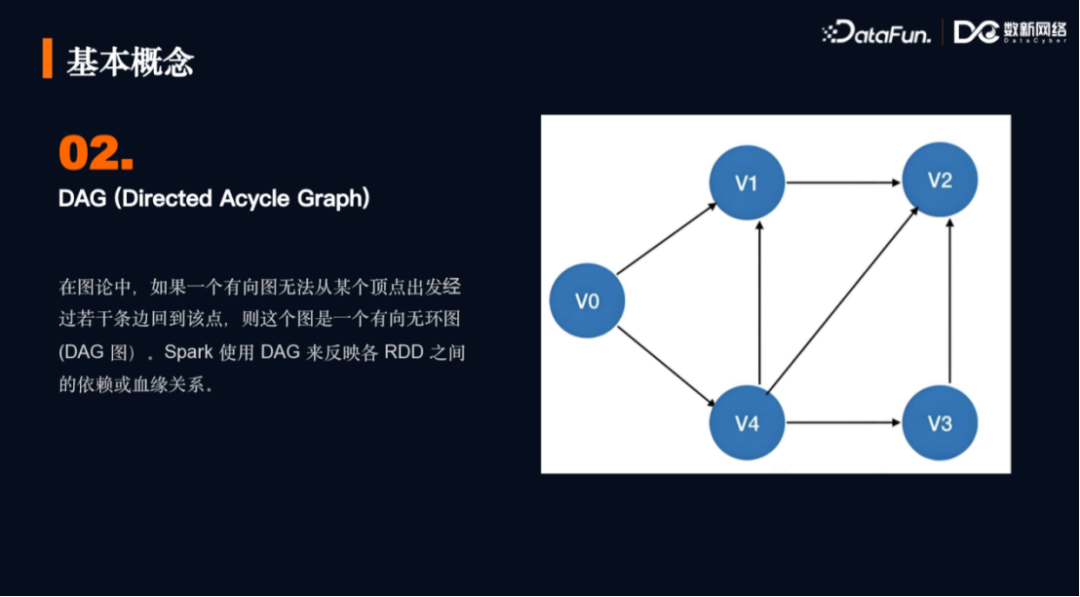
2. 有向无环图DAG
在图论中,如何一个有向图无法从某个顶点出发经过若干条边回到该点,则这个图是一个有向无环图(DAG图)。Spark使用DAG来反映各RDD之间的依赖或血缘关系。
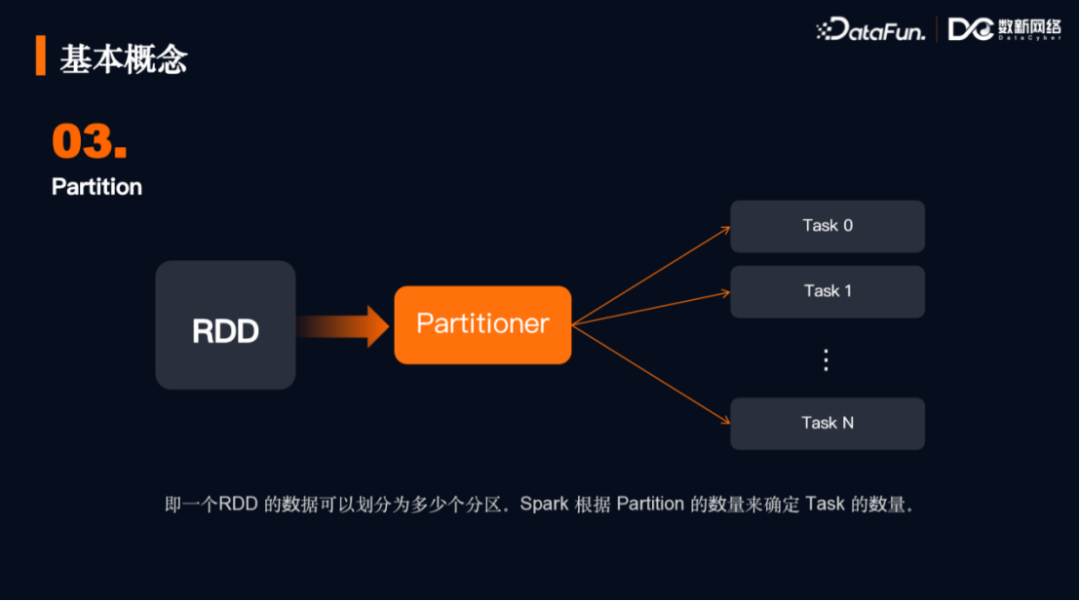
3. 分区Partition

上图A RDD有三个分区(Partition),通过分区器(Partitioner)(用户可以自定义)来进行区分,这样在Stage内部来进一步实现并行。
4. 宽窄依赖Dependency
-
Narrow Dependency为窄依赖:子RDD依赖于父RDD中固定的Partition。分为OneToOne Dependency和 Range Dependency两种;
-
Shuffle Dependency为宽依赖:子RDD对父RDD中所有的Partition都可能产生依赖。子RDD对父RDD各个Partition的依赖将取决与分区计算器(Partitioner)的算法。

5. Job/Stage/Task
执行一个动作API产生一个Job。Spark会在DAGscheduler阶段来划分不同的Stage,Stage分为ShuffleMapStage和ResultStage两种。每个Stage中都会按照RDD的Partition数量创建多个Task。ShuffleMapStage中的Task为ShuffleMapTask。ResultStage中的Task为ResultTask,类似于Hadoop中的Map任务和Reduce任务。

6.Spark为什么用Scala(vs Java)
相比早期的Java,Scala能更好的支持面向函数的编程。同时对比Java,Scala拥有丰富的类型推断,丰富的语法糖和更现代的语法特性。但是同时其学习成本较高,可读性也不如Java。

▌Spark核心功能
1.基础设施
-
SparkConf:用于管理Spark应用程序的各种配置信息;
-
Spark内置的RPC框架:用于跨机器节点不同组件间的通信,使用Netty实现,有同步和异步的多种方式,Spark各个组件的通信都依赖于此RPC框架。
-
事件总线:SparkContext内部各个组件是如何通信的;
-
度量系统:由Spark中的多种度量源(Source)和多种度量输出(Sink)构成,完成对整个Spark集群中各个组件运行状态的监控。

2.SparkContext
内部隐藏了网络通信,分布式部署,消息通信,存储体系,计算引擎,度量系统,文件服务,Web UI等内容,应用程序开发者只需要使用SparkConext提供的API完成功能开发。
3.SparkEnv
是Spark中的Task运行所必须的组件,内部封装了RPC环境(RPCEnv),序列化管理器(Spark可以参数指定序列化方式),广播管理器(BroadcastManager),map任务输出跟踪器(MapOutputTracker),存储体系,度量系统(MetricsSystem),输出提交协调器(OutputCommitCoordinator)等Task运行所需的各种组件。

4.存储体系
Spark优先考虑使用内存,在内存不足时才会考虑使用磁盘,在大数据场景下有性能提升。执行和存储内存之间是软边界,可以互相借用。同时通过钨丝计划可以更有效的利用系统的内存资源。在Spark早期还提供了以内存为中心的高容错的分布式文件系统Alluxio(原名Tachyon)供用户选择,除了JVM内存和磁盘,用户还可以写入Alluxio。这个支持才从原码里被移除前,用户可以从Spark外围比如S3把数据加载到Alluxio,使Alluxio和Spark之间可以更好的进行配合。

5. 调度系统
-
DAG调度(DAGScheduler)负责创建Job,将DAG中的RDD划分到不同的Stage,给Stage创建对应的Task,抽象成Taskset,并将Taskset批量提交给TaskScheduler。
-
Task调度(TaskScheduler)负责按照FIFO或者FAIR等调度算法对批量Task进行调度;TaskScheduler的资源来自外部的调度系统(如Standalone,Yarn或者K8s),外部调度系统分配过资源后,TaskScheduler会进一步把资源分配给Task;同时将Task发送到集群管理器,分配给当前应用的executor,由executor负责执行工作。 以Yarn为例,Yarn把资源分配给Spark Driver后,Spark Driver与Yarn的NodeManager进行通信,NodeManager会帮Spark启动对应的Executor,之后Spark Diver会分发任务到Executor上,Executor会在本地的JVM中经过反序列化之后去调用对应的方法函数。

6. 计算引擎
-
内存管理器:分为堆外/堆内,计算/存储;
-
任务内存管理器:计算内存被Task分享,每个Task会有自己的任务内存管理器;
-
Tungten(钨丝):除了JVM内存外,可以将计算和存储在堆外去进行开辟;
-
外部排序器:根据任务的不同,可以在Map端或者Reduce端对ShuffleMapTask计算的中间结果进行排序聚合等操作;
-
Shuffle管理器:用于将各个分区对应的ShuffleMapTask产生的中介结果持久化到磁盘,并在Reduce端按照分区远程拉取ShuffleMapTask产生的中间结果。

▌Spark的模型设计
-
编程模型

如上图word count的代码,通过动作API触发提交到Driver里,Driver环境下有一些类,比如DAGScheduler会进行任务的划分,血缘的构建;TaskScheduler进行资源的调度;BlockManager管理需要存储的任务;RpcEnv进行通信。Driver环境与集群资源管理器交互来进行资源的申请,并分发任务到对应的工作节点比如Yarn的NodeManager,节点帮助拉起Executor去执行计算,Executor的中间或最终结果会访问存储。
2. RDD计算模型
RDD的每个分区(Partition)是靠分区计算器(Partitioner)得到,他们可以在多个节点的多个Executor上并行的执行。


▌Spark的部署架构
1. 集群管理器(Cluster Manager)
资源需要稳健的平台进行管理,不管是Spark自带的Standalone还是Yarn或者K8s都有自己自带的多节点分布式的管理能力,同时支持故障容错等功能。

2. Worker
在拉起Executor的过程中,不同的集群管理器会选择不同的Worker;比如Standalone的Worker,Yarn的NodeManager,K8s的Node。Cluster和Worker在技术选型阶段让Spark提交到哪种集群上就已经确定了。

3. Executor 和 4. Driver
Executor是在集群内拉起;Driver对于Yarn和K8s可以选择在集群外或者内部执行。
5. Application
举个例子:用户写了一个类,其中的main方法调了一批Spark API,把这个打成jar包,用spark-submit命令提交,运行在客户端,即为应用程序。如果Driver运行在客户端,Driver是应用程序JVM进程的一部分。 如果Driver运行在集群上,Driver的进程和应用程序的JVM进程是分开的。在资源分配上,集群管理器分配给应用程序/Driver的是一级资源,拉起Executor将资源分配给任务是二级分配。

▌公司简介
浙江数新网络有限公司是一家专注于多云数据智能平台和数据价值流通的服务商。公司总部位于杭州,在上海、北京、深圳等各地设有分支机构,服务网络覆盖全国各区域,客户遍布全球 50+城市。数新网络自成立以来就在人工智能领域进行了深入的探索,已有成熟的产品、基于场景的解决方案及不同行业的成功案例。帮助金融、能源电力等行业相关企业实现数字化、智能化转型,提升企业新质生产力。
数新网络自主研发的一站式多云数据智能平台,主要包括赛博数智引擎CyberEngine、赛博数据平台CyberData、赛博智能平台CyberAI,可提供基于大数据的大模型调优、深度学习、价值流通等多种服务。数新网络自主研发的赛博数智引擎CyberEngine基于开源开放的设计理念,兼容开源引擎并进行深度优化,开放式架构支持主流引擎生态,支持多元异构引擎灵活插拔,支持流批一体、湖仓一体、数智一体等场景化能力。在此基础上,CyberEngine以Spark、Flink作为主计算引擎,以Spark为例,基于Spark实现数新网络的流批引擎、统一查询引擎,在性能、稳定性、云原生化等方面全面优于社区开源版本。
▌数新网络高级架构专家 Spark Committer
耿嘉安
2014 阿里巴巴御膳房主力开发
2016 软件开发&大数据开发,出版畅销书籍《深入理解 Spark 》
2016 艺龙网大数据架构师,主导开发大数据平台
2017 360大数据专家,出版畅销书籍《 Spark 内核设计的艺术》
2018 360高级大数据专家,主导开发XSQL查询平台
2020 麒麟高级性能专家,主导 Kylin 执行引擎加速
2024 数新网络高级架构专家
分享嘉宾|耿嘉安 数新网络高级架构专家 Spark Committer
编辑整理|董晨
内容校对|李瑶 耿嘉安 包卓娜 王妍
出品社区|DataFun
原文地址:https://blog.csdn.net/datacreating/article/details/140555604
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!