政安晨:【深度学习实践】【使用 TensorFlow 和 Keras 为结构化数据构建和训练神经网络】(五)—— Dropout和批归一化
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: TensorFlow与Keras实战演绎
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
Dropout和批归一化是深度学习领域中常用的正则化技术,旨在提高模型的泛化能力和防止过拟合。
Dropout是由Hinton等人在2012年提出的一种正则化技术。它通过在训练过程中随机地将一部分神经元的输出设置为零,来减少神经网络中神经元之间的依赖关系。具体来说,对于每个训练样本,每个神经元都有一定的概率被丢弃,这样可以防止某些特定的神经元过于依赖于其他神经元,从而使得整个网络的泛化能力更强。在测试时,不再进行随机丢弃,而是将所有神经元的输出都保留下来,但要乘上一个与训练时丢弃概率成反比的因子,以保持输出值的期望不变。
批归一化是由Ioffe和Szegedy在2015年提出的一种归一化技术。它主要解决深度神经网络中的内部协变量转移问题,即前一层的参数更新会影响到后一层的输入分布,使得训练过程变得复杂。批归一化通过在每一层的输入上进行归一化操作,将每一层的输入都尽量保持在较小的范围内,可以加快训练速度并提高模型的泛化能力。具体来说,批归一化将每个特征维度的输入都减去其均值,并除以其标准差,然后再乘以一个可学习的缩放系数和位移系数。
总之,Dropout和批归一化是深度学习领域中常用的正则化技术。
Dropout在训练过程中随机丢弃神经元的输出,减少网络的依赖关系,提高泛化能力;
批归一化通过归一化每层的输入,解决内部协变量转移问题,加快训练速度并提高模型的泛化能力。
Dropout和批归一化的作用:添加这些特殊的层来防止过拟合并稳定训练。
前言
深度学习的世界远不止稠密层(dense layer)。您可以在模型中添加几十种不同类型的层(layer)。(尝试浏览一下Keras文档来了解一些示例!)有些层类似于稠密层,用于定义神经元之间的连接,而其他类型的层则可以进行预处理或其他形式的转换操作。
在本文中,我们将学习两种特殊的层,它们本身不包含任何神经元,但可以为模型添加一些功能,有时可以以各种方式受益。这两种层在现代架构中经常使用。
Dropout
其中一种层是“dropout层”,它可以帮助纠正过拟合。
在上一篇文章中,我们讨论了过拟合是由网络在训练数据中学习到的虚假模式引起的。为了识别这些虚假模式,网络通常会依赖于非常特定的权重组合,一种“诱骗”权重。由于非常特定,它们往往很脆弱:去除其中一个,“诱骗”就会瓦解。
这就是Dropout的理念。为了打破这些诱骗,我们在训练的每一步中随机丢弃一部分层的输入单元,使网络更难学习训练数据中的那些虚假模式。相反,它必须搜索广泛、普遍的模式,这些模式的权重模式往往更加稳定。
(在这里,在两个隐藏层之间添加了50%的Dropout。)
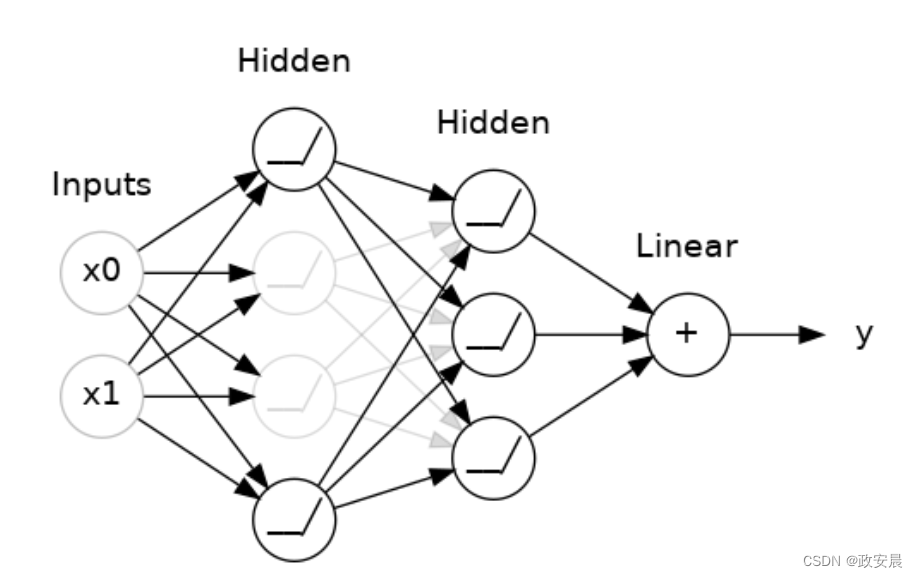
你也可以将dropout看作是创建了一种网络集合。
预测不再由一个大网络完成,而是由一组较小的网络委员会完成。委员会中的个体往往会犯不同类型的错误,但同时也会做出正确的判断,使得整个委员会的性能比任何一个个体网络都要好。(如果你熟悉随机森林作为决策树的集合,那就是相同的思想。)
增加 Dropout
在Keras中,dropout率参数rate定义了要关闭的输入单元的百分比。
将Dropout层放在希望应用dropout的层之前:
keras.Sequential([
# ...
layers.Dropout(rate=0.3), # apply 30% dropout to the next layer
layers.Dense(16),
# ...
])批归一化
下一个我们要看的特殊层是执行“批量归一化”(或“batchnorm”)的层,它可以帮助纠正训练过程中的缓慢或不稳定的问题。
在神经网络中,通常将所有数据放在一个共同的尺度上是一个好主意,例如使用scikit-learn的StandardScaler或MinMaxScaler。原因是SGD会按照数据产生的激活大小的比例来调整网络权重。产生非常不同大小激活的特征可能导致训练不稳定。
现在,如果在数据进入网络之前归一化是好的,那么在网络内部也进行归一化可能会更好!事实上,我们有一种特殊的层可以实现这一点,即批量归一化层。批量归一化层在每个批次进来时,首先使用自己的均值和标准差对批次进行归一化,然后还用两个可训练的重新缩放参数将数据放在一个新的尺度上。批量归一化实际上执行了一种协调的输入尺度调整。
大多数情况下,批量归一化被添加为优化过程的辅助手段(尽管它有时也可以帮助预测性能)。具有批量归一化的模型通常需要更少的轮次来完成训练。此外,批量归一化还可以修复导致训练“陷入困境”的各种问题。如果在训练过程中遇到问题,考虑将批量归一化添加到您的模型中。
增加批量归一化
批量标准化似乎可以在网络的几乎任何位置使用。
可以将其放在一个层之后...
layers.Dense(16, activation='relu'),
layers.BatchNormalization(),...或者在一层和其激活函数之间:
layers.Dense(16),
layers.BatchNormalization(),
layers.Activation('relu'),如果你将它添加为网络的第一层,它可以充当一种自适应的预处理器,类似于Sci-Kit Learn的StandardScaler。
示例 - 使用Dropout和批归一化
在看TensorFlow和Keras的例子之前,我们先对比看一下pyTorch的例子:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义神经网络模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(10, 20)
self.dropout = nn.Dropout(0.2)
self.fc2 = nn.Linear(20, 10)
self.bn = nn.BatchNorm1d(10)
self.fc3 = nn.Linear(10, 1)
def forward(self, x):
x = self.fc1(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.bn(x)
x = self.fc3(x)
return x
# 定义训练和测试数据
train_data = torch.randn(100, 10)
train_labels = torch.randn(100, 1)
test_data = torch.randn(10, 10)
test_labels = torch.randn(10, 1)
# 初始化模型和优化器
model = Net()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练模型
model.train()
for epoch in range(100):
optimizer.zero_grad()
output = model(train_data)
loss = nn.MSELoss()(output, train_labels)
loss.backward()
optimizer.step()
# 测试模型
model.eval()
with torch.no_grad():
test_output = model(test_data)
test_loss = nn.MSELoss()(test_output, test_labels)
print("Test Loss:", test_loss.item())
在上面这个示例中,我们定义了一个简单的神经网络模型。在模型的定义中,我们添加了一个Dropout层和一个批归一化层。在训练过程中,我们使用了随机梯度下降优化器和均方误差损失函数对模型进行训练。在测试过程中,我们使用了带有梯度的测试数据来评估模型的性能。
通过使用Dropout和批归一化,我们可以有效地避免过拟合和梯度消失问题,提高模型的性能和泛化能力。在实际应用中,可以根据具体情况调整Dropout和批归一化的参数以获得更好的效果。
接下来,我正式看一下TF与Keras的例子:
我们继续开发前面文章的红酒模型。现在我们将进一步增加容量,但添加丢弃以控制过拟合,并添加批归一化来加速优化。这次,我们还将不标准化数据,以展示批归一化如何稳定训练。
# Setup plotting
import matplotlib.pyplot as plt
plt.style.use('seaborn-whitegrid')
# Set Matplotlib defaults
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
import pandas as pd
red_wine = pd.read_csv('../input/dl-course-data/red-wine.csv')
# Create training and validation splits
df_train = red_wine.sample(frac=0.7, random_state=0)
df_valid = red_wine.drop(df_train.index)
# Split features and target
X_train = df_train.drop('quality', axis=1)
X_valid = df_valid.drop('quality', axis=1)
y_train = df_train['quality']
y_valid = df_valid['quality']当添加dropout时,可能需要增加密集层中的神经元数量。
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(1024, activation='relu', input_shape=[11]),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1024, activation='relu'),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1024, activation='relu'),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1),
])这次我们在训练设置上没有任何改变。
model.compile(
optimizer='adam',
loss='mae',
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=256,
epochs=100,
verbose=0,
)
# Show the learning curves
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot();
如果在训练之前对数据进行标准化,通常可以获得更好的性能。然而,我们能够使用原始数据,显示了批量归一化在更困难的数据集上的有效性。
练习:Dropout与批量归一化
介绍
在这个练习中,你将给咱们前面文章练习中的Spotify模型添加dropout,并看看批量归一化如何使你能够成功地训练困难的数据集上的模型。
前面文章:
政安晨:【深度学习实践】【使用 TensorFlow 和 Keras 为结构化数据构建和训练神经网络】(四)—— 过拟合和欠拟合![]() https://blog.csdn.net/snowdenkeke/article/details/136919080小伙们拉到最后来看示例代码。
https://blog.csdn.net/snowdenkeke/article/details/136919080小伙们拉到最后来看示例代码。
现在,我们继续:
# Setup plotting
import matplotlib.pyplot as plt
plt.style.use('seaborn-whitegrid')
# Set Matplotlib defaults
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
plt.rc('animation', html='html5')
# Setup feedback system
from learntools.core import binder
binder.bind(globals())
from learntools.deep_learning_intro.ex5 import *首先加载Spotify数据集。
import pandas as pd
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import make_column_transformer
from sklearn.model_selection import GroupShuffleSplit
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import callbacks
spotify = pd.read_csv('../input/dl-course-data/spotify.csv')
X = spotify.copy().dropna()
y = X.pop('track_popularity')
artists = X['track_artist']
features_num = ['danceability', 'energy', 'key', 'loudness', 'mode',
'speechiness', 'acousticness', 'instrumentalness',
'liveness', 'valence', 'tempo', 'duration_ms']
features_cat = ['playlist_genre']
preprocessor = make_column_transformer(
(StandardScaler(), features_num),
(OneHotEncoder(), features_cat),
)
def group_split(X, y, group, train_size=0.75):
splitter = GroupShuffleSplit(train_size=train_size)
train, test = next(splitter.split(X, y, groups=group))
return (X.iloc[train], X.iloc[test], y.iloc[train], y.iloc[test])
X_train, X_valid, y_train, y_valid = group_split(X, y, artists)
X_train = preprocessor.fit_transform(X_train)
X_valid = preprocessor.transform(X_valid)
y_train = y_train / 100
y_valid = y_valid / 100
input_shape = [X_train.shape[1]]
print("Input shape: {}".format(input_shape))1. 为Spotify Model增加Dropout
这是上篇文章练习中的最后一个模型。在具有128个单元的Dense层之后添加一个dropout层,并在具有64个单元的Dense层之后再添加一个dropout层。将两个dropout层的丢弃率都设为0.3。
# YOUR CODE HERE: Add two 30% dropout layers, one after 128 and one after 64
model = keras.Sequential([
layers.Dense(128, activation='relu', input_shape=input_shape),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
# Check your answer
q_1.check()# Lines below will give you a hint or solution code
#q_1.hint()
#q_1.solution()现在您可以运行下一个代码来训练模型并观察添加dropout的效果。
model.compile(
optimizer='adam',
loss='mae',
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=512,
epochs=50,
verbose=0,
)
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot()
print("Minimum Validation Loss: {:0.4f}".format(history_df['val_loss'].min()))2.评估Dropout
再次回顾一下上篇文章的练习,这个模型在第5个epoch附近容易过拟合数据。这次添加dropout似乎有助于防止过拟合吗?
# View the solution (Run this cell to receive credit!)
q_2.check()现在,我们将切换话题,探讨批标准化如何解决训练中的问题。
加载混凝土数据集。这次我们不进行任何标准化处理。这将使批标准化的效果更加明显。
import pandas as pd
concrete = pd.read_csv('../input/dl-course-data/concrete.csv')
df = concrete.copy()
df_train = df.sample(frac=0.7, random_state=0)
df_valid = df.drop(df_train.index)
X_train = df_train.drop('CompressiveStrength', axis=1)
X_valid = df_valid.drop('CompressiveStrength', axis=1)
y_train = df_train['CompressiveStrength']
y_valid = df_valid['CompressiveStrength']
input_shape = [X_train.shape[1]]运行以下代码来对非标准化的混凝土数据进行网络训练。
model = keras.Sequential([
layers.Dense(512, activation='relu', input_shape=input_shape),
layers.Dense(512, activation='relu'),
layers.Dense(512, activation='relu'),
layers.Dense(1),
])
model.compile(
optimizer='sgd', # SGD is more sensitive to differences of scale
loss='mae',
metrics=['mae'],
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=64,
epochs=100,
verbose=0,
)
history_df = pd.DataFrame(history.history)
history_df.loc[0:, ['loss', 'val_loss']].plot()
print(("Minimum Validation Loss: {:0.4f}").format(history_df['val_loss'].min()))你最后得到了一张空白图吗?试图在这个数据集上训练这个网络通常会失败。即使它收敛了(因为有了幸运的权重初始化),它也倾向于收敛到一个非常大的数值。
3. 添加批归一化层
批量归一化可以帮助纠正这类问题。
在每个全连接层之前添加四个批量归一化层。(记得将input_shape参数移到新的第一层。)
# YOUR CODE HERE: Add a BatchNormalization layer before each Dense layer
model = keras.Sequential([
layers.Dense(512, activation='relu', input_shape=input_shape),
layers.Dense(512, activation='relu'),
layers.Dense(512, activation='relu'),
layers.Dense(1),
])
# Check your answer
q_3.check()# Lines below will give you a hint or solution code
#q_3.hint()
#q_3.solution()运行一下代码,看看批量归一化是否能让我们训练模型。
model.compile(
optimizer='sgd',
loss='mae',
metrics=['mae'],
)
EPOCHS = 100
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=64,
epochs=EPOCHS,
verbose=0,
)
history_df = pd.DataFrame(history.history)
history_df.loc[0:, ['loss', 'val_loss']].plot()
print(("Minimum Validation Loss: {:0.4f}").format(history_df['val_loss'].min()))4. 评估批量归一化
您可以通过反复对比,观察批量归一化对您的模型改善是否有用。
# View the solution (Run this cell to receive credit!)
q_4.check()原文地址:https://blog.csdn.net/snowdenkeke/article/details/136926860
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!