yolov8学习笔记(二)模型训练
目录
2、模型训练(标记数据集、参数设置、跟踪模型随时间的性能变化)
2.3、看训练时的参数(有条件,就使用TensorBoard)
yolov8的模型训练
训练demo:windows使用YOLOv8训练自己的模型(0基础保姆级教学)_windows10使用yolov8常见问题-CSDN博客
1、制作数据集(标记数据集)
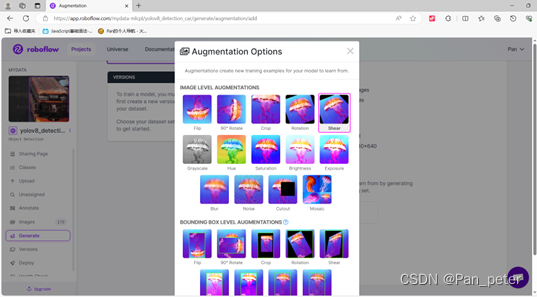
数据集——增强与制作:
yolov8标签制作,数据增强指定网站。
使用教程:
注意:他这个网站标记的标签,是按照英语字母的顺序排的(所以我们平时也要养成好习惯,按照英语字母排类别)
比如:
bus、car、van——这样就可以了~(bus索引为0,car为1,van为2,以此类推~)
在这里顺便记录简单标记标签的开源项目:labelimg(使用方法)
蓝奏云下载链接:labelImg-master.zip - 蓝奏云
github项目链接:labelImg - GitHub
W是标记快捷键
A是切换为上一张
D是切换位下一张
记得自动保存~
记得去predefined_classes.txt里面修改自己需要的类别
再进阶的话,就用其他好用的工具
2、模型训练(标记数据集、参数设置、跟踪模型随时间的性能变化)
2.0用自己电脑的GPU训练:
多GPU训练
苹果M1和M2 MPS训练
恢复中断的训练
在训练YOLOv8模型时,跟踪模型随时间的性能变化可能非常有价值。
Ultralytics的YOLO提供对三种类型记录器的支持 : Comet、ClearML和TensorBoard。
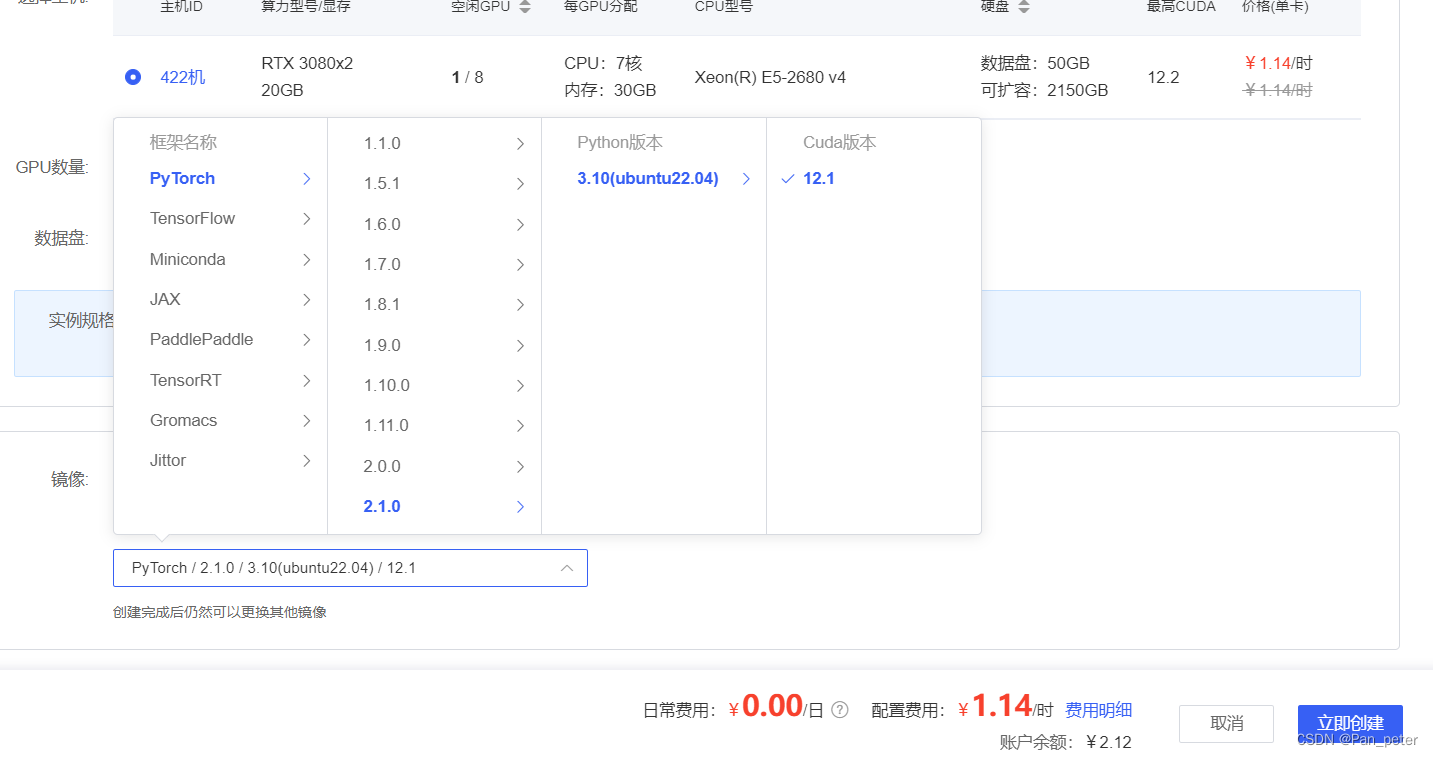
2.1、租服务器训练
使用教程:云服务器训练YOLOv8-训练&改进教程_哔哩哔哩_bilibili
- 训练网址:AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDLAutoDL为您提供专业的GPU租用服务,秒级计费、稳定好用,高规格机房,7x24小时服务。更有算法复现社区,一键复现算法。
https://www.autodl.com (找到适合的Torch版本,自带Conda)现在需要最新的yolov8需要 torch>=2.0.0 for deterministic training.
- 购买服务器(yolo训练一般显卡4G就够了,不过那里面一般都是12G以上)
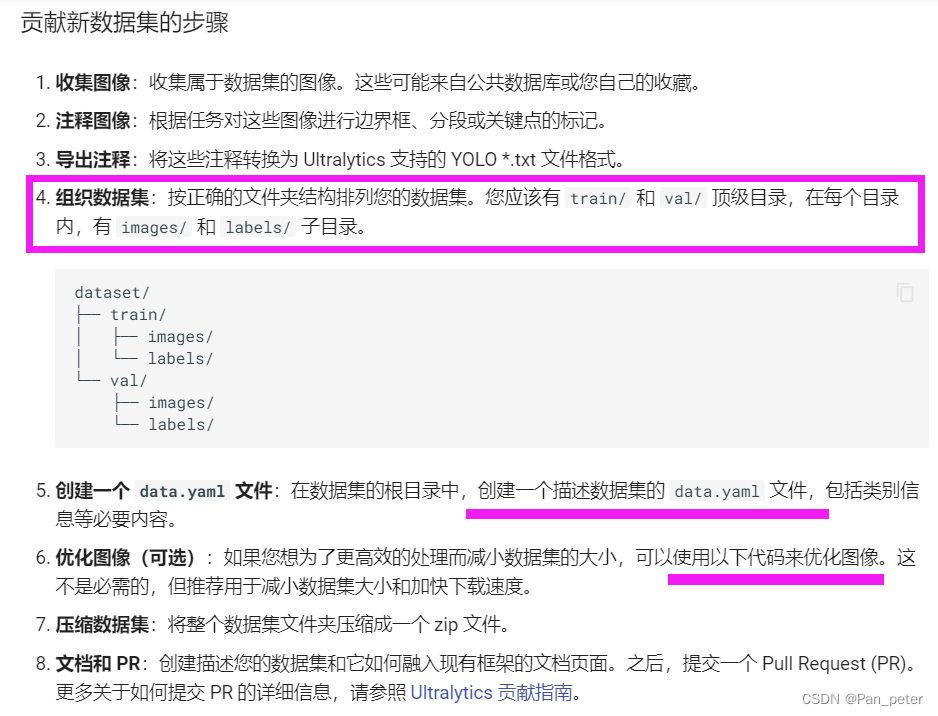
- 上传训练文件(yolo固定版本库、data数据集、原始模型、train.py)
- 执行python xxx.py (缺少什么库直接下载就行,缺不了什么,一般就是cv,np,pandas、scipy、seaborn)
- 如果缺少cv,np,pandas会无法训练
- 如果缺少scipy、seaborn会无法生成一些结果!
注意:可以用【后台运行python】的方法(防止我们远程断网,导致训练中断!)
可以看看这个文章:
pip install numpy
pip install opencv-python
pip install pandas
pip install scipy
pip install seaborn
2.2、加训练参数
data: 训练数据集的配置文件路径,一般为.yaml格式,包含了数据集路径、类别数、训练和验证集的划分等信息。
epochs(训练的轮数): 对于新数据集,可以逐渐增加轮数,以找到更佳的性能。
patience(早停的等待轮数): 用于控制在训练过程中是否进行早停,防止过拟合。
device(训练运行的设备): 指定模型训练所使用的设备,如GPU或CPU。
workers(数据加载时的工作线程数): 在数据加载过程中,可以使用多个线程并行地加载数据,以提高数据读取速度。
batch(每个批次中的图像数量): 一般认为越大越好,但受限于显存空间。
imgsz(输入图像的尺寸): 如果数据集中存在大量小对象,增大输入图像的尺寸可以使得这些小对象从高分辨率中受益,更好的被检测出。一般为正方形,常见大小为416、512、640等。
save、save_period(保存检查点的频率): 用于保存训练的检查点和预测结果,在训练不稳定中断后可以通过resume重新启动。
cache(数据加载时是否使用缓存): 控制数据加载时是否使用缓存,以提高训练过程中的数据读取速度。
seed: 随机种子,用于实现可重复性。通过设置相同的随机种子,可以使得每次运行时的随机过程保持一致,以便于结果的复现
name: 实验名称。该参数为当前训练任务指定一个名称,以便于标识和区分不同的实验。
optimizer: 选择要使用的优化器。优化器是深度学习中用于调整模型参数以最小化损失函数的算法。
deterministic: 是否启用确定性模式。启用确定性模式后,保证在相同的输入下,每次运行的结果是确定的,不会受到随机性的影响。
rect: 使用矩形训练,每个批次进行最小填充。设置为 True 后,训练过程中使用矩形形状的图像批次,并进行最小化填充。
cos_lr: 使用余弦学习率调度器。如果设置为 True,将使用余弦函数调整学习率的变化情况。
close_mosaic: 禁用mosaic增强的最后第几个轮次。可以指定一个整数值,表示在训练的最后第几个轮次中禁用mosaic增强。
2.3、看训练时的参数(有条件,就使用TensorBoard)
主要是TensorBoard还阔以看【网络结构~】
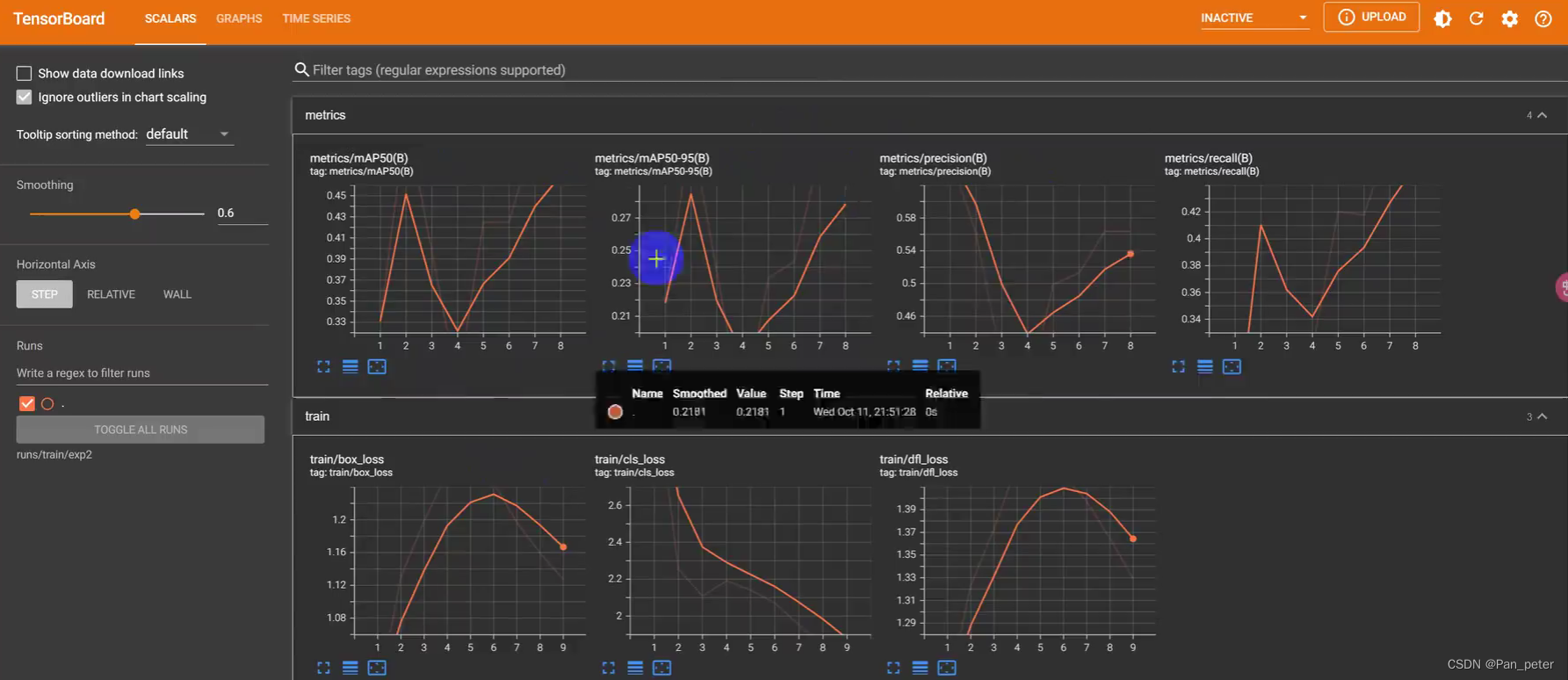

- Epoch:表示当前正在进行的训练轮数。每个 epoch 表示模型已经使用整个训练数据集进行了一次完整的训练。
- GPu mem:表示当前 GPU 的内存使用情况,以 GB 为单位。这个参数可以告诉你模型在训练期间所使用的 GPU 内存量。如果内存使用过高,可能需要调整模型或减少批量大小。
- box loss:表示当前训练轮次中物体检测(bounding box)的损失值。物体检测损失是通过比较模型预测的边界框位置与实际边界框位置之间的差异来计算的。
- cls loss:表示当前训练轮次中的分类损失值。分类损失是通过比较模型预测的类别标签与实际类别标签之间的差异来计算的。
- dfl loss:表示当前训练轮次中的关键点检测(landmark detection)的损失值。关键点检测损失是通过比较模型预测的关键点位置与实际关键点位置之间的差异来计算的。
- Instances:表示当前训练轮次中处理的实例数量。这个参数用于衡量训练过程中处理的图像或样本数量。
- Class:表示目标类别的名称。
- Images:表示测试集中包含该类别的图像数量。
- Instances:表示测试集中该类别的实例数量。
- Box(P):表示该类别的目标检测精确率(Precision),即正确预测的边界框数量与预测的边界框总数之间的比例。
- R:表示该类别的目标检测召回率(Recall),即正确预测的边界框数量与实际边界框总数之间的比例。
- mAP50:表示该类别的平均精确度(mean Average Precision)值,计算方式是在 IoU 阈值为 0.5 的条件下,对每个类别进行精确度的平均计算。
- mAP50-95:表示该类别的平均精确度值,在 IoU 阈值从 0.5 到 0.95 变化时,对每个类别进行精确度的平均计算。
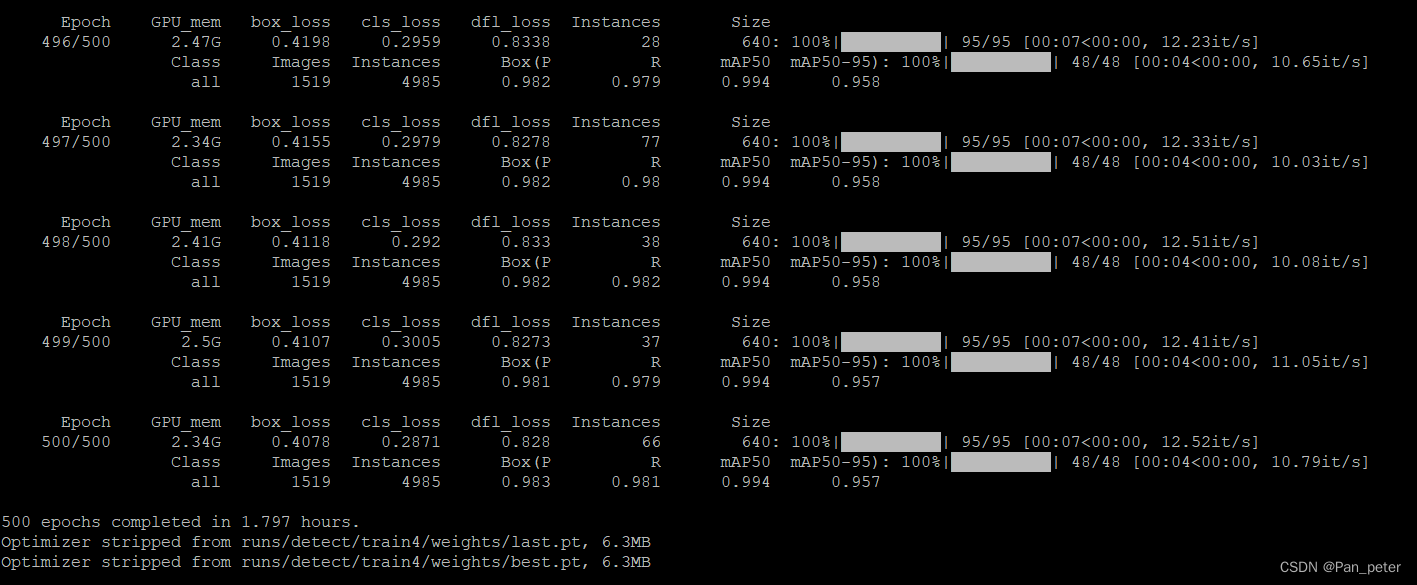
训练完成:
2.4、断续训练
用训练出来的last.pt继续训练
就是在参数中加入:resume=True
model = YOLO('./last.pt') # load a partially trained model # Train the model model.train(data='./data/data.yaml', epochs=500, imgsz=640, workers=0, name='car', batch=32, resume=True)
3、模型验证
在机器学习流程中,验证是一个关键步骤,让您能够评估训练模型的质量。

4、使用模型进行推理预测(视频、图像、视频流等)
YOLOv8 可以处理推理输入的不同类型,如下表所示。来源包括静态图像、视频流和各种数据格式。
5、模型转换(pt转为onnx等)
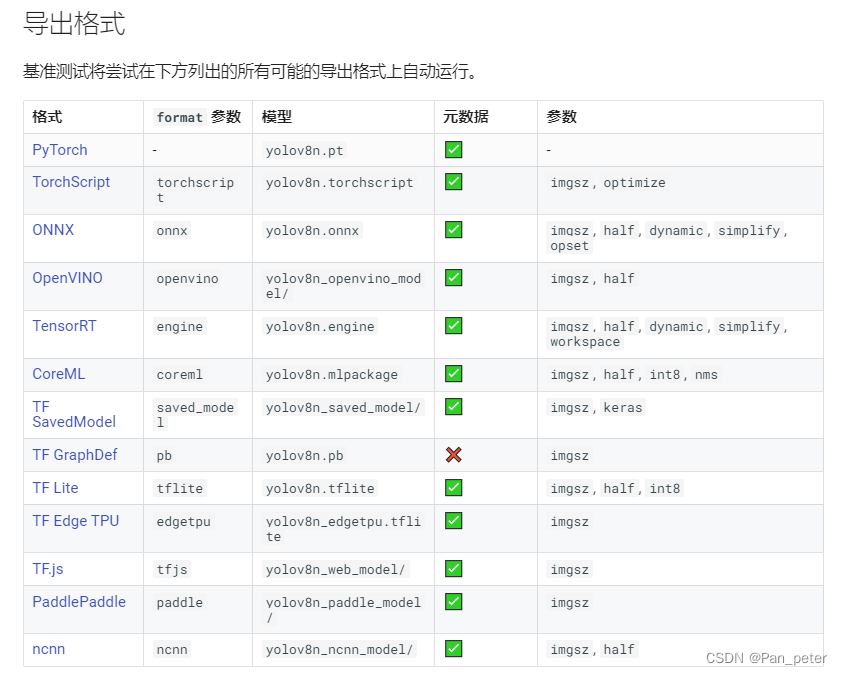
6、基准测试

7、评估训练结果
评估训练结果:
笔记下载
https://wwm.lanzout.com/isyZD1p3puyj
密码:hoab
原文地址:https://blog.csdn.net/Pan_peter/article/details/136280825
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!