FSRCNN:加速超分辨率卷积神经网络,SRCNN的加速版
目录
1. 动机
作者此前提出的SRCNN证明了CNN在图像超分领域的有效性。然而,SRCNN计算效率较低,不能达到实时性能。因此,该作者重新设计了SRCNN的网络,以提升推理速度。
改进点包括三个方面:
- 1)在网络末端引入了一个反卷积层,用于将原始分辨率的feature map映射到高分辨率图像;
- 2) 引入了沙漏型body网络,输入特征的通道维度先缩小再扩大,以降低计算量;
- 3) 采用更小的卷积核,但层次更深了;
所提出的网络能够提速40倍,同时SR质量也更好。
2. 方法
原始SRCNN有一个预处理步骤,即先将原图上采样,然后再送入网络,这无疑增加了计算量。在FSRCNN中,去掉了这个步骤,直接从原始分辨率开始,最终得到高分辨率结果。此外,如何缩小计算量也是FSRCNN重点考虑的问题,原始SRCNN虽然层数较少,但卷积核较大(9*9),因此FSRCNN探索了更小的卷积核,同时增加网络深度,整体的计算量能够降低不少。
根据上述观察,我们研究了一种更简洁、更高效的网络结构,用于快速准确的图像SR。为了解决第一个问题,我们采用反卷积层来代替双三次插值。为了进一步减轻计算负担,我们在网络的末端放置了反卷积层1,那么计算复杂度仅与原始LR图像的空间大小成正比。值得注意的是,反褶积层不等于传统插值核的简单替代,如FCN[13],或像[14]这样的“unpooling+convolution”。相反,它由各种自动学习的上采样核(见图3)组成,它们共同工作生成最终的HR输出,并用均匀插值核替换这些反卷积滤波器将导致PSNR急剧下降(例如,对于×3,Set5数据集[15]上至少0.9 dB)。
对于第二个问题,我们分别在映射层的开头和结尾添加一个收缩层和扩展层,以限制低维特征空间中的映射。此外,我们将单个宽映射层分解为几个具有固定滤波器大小为 3 × 3 的层。
FSRCNN整体网络结构如下:

FSRCNN可以分解为特征提取、收缩、映射、扩展和反卷积五个部分。前四个部分是卷积层,最后一个是反卷积层。为了更好地理解,我们将卷积层表示为 Conv(fi, ni, ci),将反卷积层表示为 DeConv(fi, ni, ci),其中变量 fi, ni, ci 分别表示滤波器大小、滤波器数量和通道数。
- Feature extraction: 这部分类似于 SRCNN 的第一部分,但在输入图像上不同。FSRCNN 在原始 LR 图像上执行特征提取,无需插值;而且,卷积核大小从9变成了5。
- Shrinking:使用1*1卷积将通道数降低;
- Non-linear mapping:使用3*3卷积进行特征映射;
- Expanding: 将通道维度再恢复回去;
- Deconvolution:反卷积层,这一层用于对先前的特征进行上采样和聚合,得到高分辨率结果。
3. 代码对比
首先看看SRCNN的代码:
from torch import nn
class SRCNN(nn.Module):
def __init__(self, num_channels=1):
super(SRCNN, self).__init__()
self.conv1 = nn.Conv2d(num_channels, 64, kernel_size=9, padding=9 // 2)
self.conv2 = nn.Conv2d(64, 32, kernel_size=5, padding=5 // 2)
self.conv3 = nn.Conv2d(32, num_channels, kernel_size=5, padding=5 // 2)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
x = self.conv3(x)
return x再来看FSRCNN的代码:
import math
from torch import nn
class FSRCNN(nn.Module):
def __init__(self, scale_factor, num_channels=1, d=56, s=12, m=4):
super(FSRCNN, self).__init__()
self.first_part = nn.Sequential(
nn.Conv2d(num_channels, d, kernel_size=5, padding=5//2),
nn.PReLU(d)
)
self.mid_part = [nn.Conv2d(d, s, kernel_size=1), nn.PReLU(s)]
for _ in range(m):
self.mid_part.extend([nn.Conv2d(s, s, kernel_size=3, padding=3//2), nn.PReLU(s)])
self.mid_part.extend([nn.Conv2d(s, d, kernel_size=1), nn.PReLU(d)])
self.mid_part = nn.Sequential(*self.mid_part)
self.last_part = nn.ConvTranspose2d(d, num_channels, kernel_size=9, stride=scale_factor, padding=9//2,
output_padding=scale_factor-1)
self._initialize_weights()
def _initialize_weights(self):
for m in self.first_part:
if isinstance(m, nn.Conv2d):
nn.init.normal_(m.weight.data, mean=0.0, std=math.sqrt(2/(m.out_channels*m.weight.data[0][0].numel())))
nn.init.zeros_(m.bias.data)
for m in self.mid_part:
if isinstance(m, nn.Conv2d):
nn.init.normal_(m.weight.data, mean=0.0, std=math.sqrt(2/(m.out_channels*m.weight.data[0][0].numel())))
nn.init.zeros_(m.bias.data)
nn.init.normal_(self.last_part.weight.data, mean=0.0, std=0.001)
nn.init.zeros_(self.last_part.bias.data)
def forward(self, x):
x = self.first_part(x)
x = self.mid_part(x)
x = self.last_part(x)
return x
可以看出,FSRCNN网络结构更复杂了,但通过去掉预处理过程中的上采样、缩小卷积核、收缩映射过程中的通道数,最终可以得到更深却更轻量的网络,从而达到速度更快、效果更好的结果。
下表展示了从SRCNN到FSRCNN的变化过程:
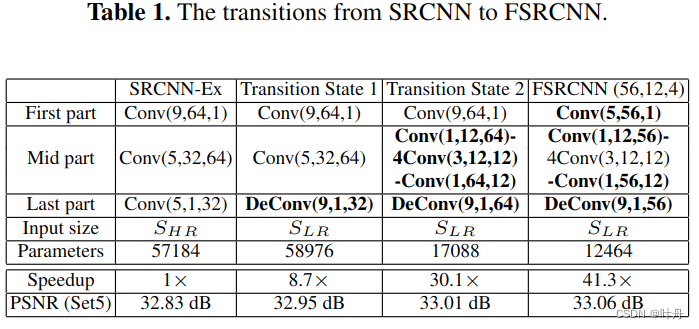
4. 实验结果




原文地址:https://blog.csdn.net/oYeZhou/article/details/137466482
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!