ARM CACHE汇总
1. 背景
1.1 CACHE的作用
高速缓存是位于核心和主内存之间的小而快速的内存块。它在主内存中保存项目的副本。对高速缓冲存储器的访问比对主存储器的访问快得多。每当内核读取或写入特定地址时,它首先会在缓存中查找。如果它在高速缓存中找到地址,它就使用高速缓存中的数据,而不是执行对主存储器的访问。通过减少缓慢的外部存储器访问时间的影响,这显着提高了系统的潜在性能。通过避免驱动外部信号的需要,它还降低了系统的功耗。

1.2 软件怎么处理CACHE
什么时候需要软件维护cache:
(1)、当有其它的Master改变的external memory,如DMA操作
(2)、MMU的enable或disable的整个区间的内存访问,如REE enable了mmu,TEE disable了mmu.
针对第(2)点,cache怎么和mmu扯上关系了呢?那是因为:mmu的开启和关闭,影响了内存的permissions, cache policies。
ARM提供了操作cache的指令, 软件维护操作cache的指令有三类:
Invalidation:其实就是修改valid bit,让cache无效,主要用于读
Cleaning: 其实就是所说的flush cache,这里会将cache数据回写到内存,并清除dirty标志
Zero:将cache中的数据清0, 这里其实是我们所说的clean cache.
2. Cache基本概念
2.1 多级CACHE
cache是多级的,一个系统中可能会看到L1、L2、L3, 当然越靠近core就越小,也是越昂贵。
2.2 cache和MMU的关系
很多时候cache都是和MMU一起使用的(即同时开启或同时关闭),因为MMU页表的entry的属性中控制着内存权限和cache缓存策略等。
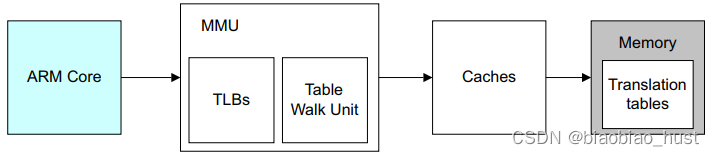
在ARM架构中,L1 cache都是VIPT的,也就是当有一个虚拟地址送进来,MMU在开始进行地址翻译的时候,Virtual Index就可以去L1 cache中查询了,MMU查询和L1 cache的index查询同时进行的。如果L1 Miss了,则再去查询L2,L2还找不到则再去查询L3。 注意在arm架构中,仅仅L1是VIPT,L2和L3都是PIPT。
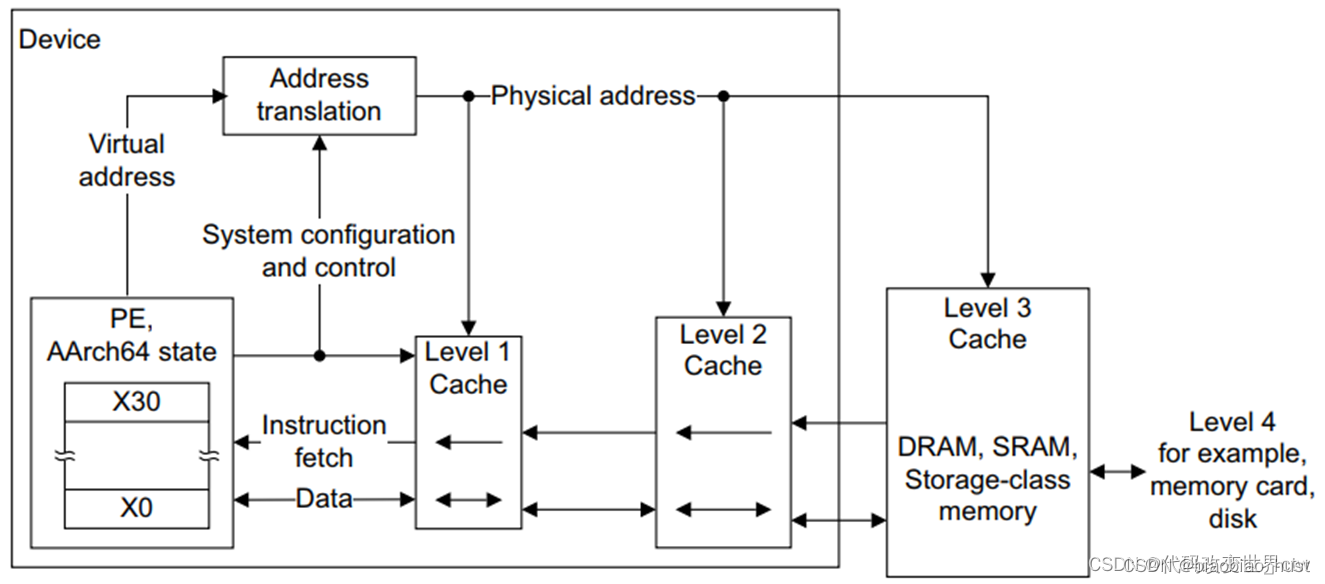
2.3 bit-LITTLE架构 和 DynamIQ架构 的cache是有区别的
2.3.1 bit-LITTLE架构的cache
在bit-LITTLE的架构中,L1是core中,L1又分为L1 data cache和 L1 Instruction cache, L2 在cluster中,L3则在BUS总线上。bit-LITTLE的架构的一个cache层级关系图如下所示:
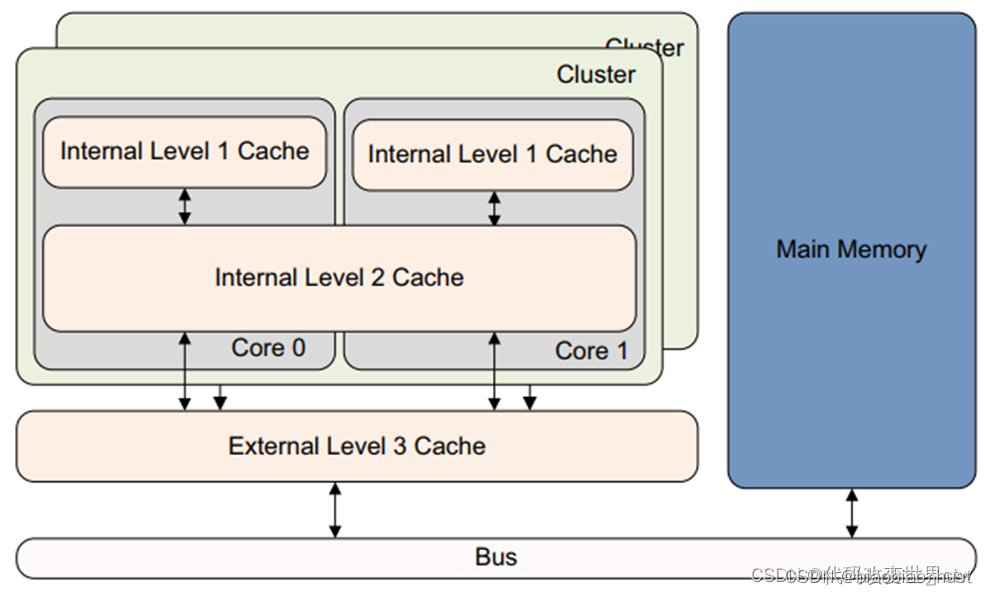
2.3.2 DynamIQ架构架构的cache
随着时代的发展科技的进步,除了了DynamIQ架构后,整个系统的system memory架构也在悄然无息的发生了变化。刚开始的架构如下所示:L1/L2在core中,L3在DSU中,DSU对外是ACE接口,结合CCI 来维护多cluster之间的缓存一致性。
但是在后来,随着CHI的越来越成熟,又变成了:L1/L2在core中,L3在DSU中,DSU对外是CHI接口,结合CMN来维护多cluster之间的缓存一致性。
2.4 cache的组成形式
cache的组织形式有:
- 直接相连
- 多路组相连(如4路组相连)
- 全相连
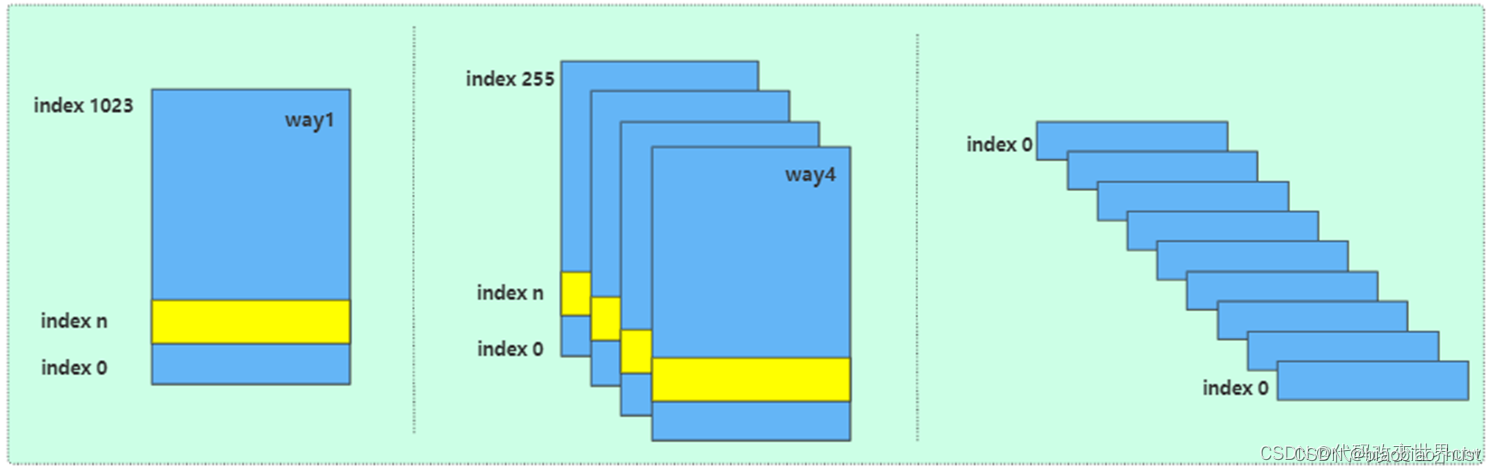
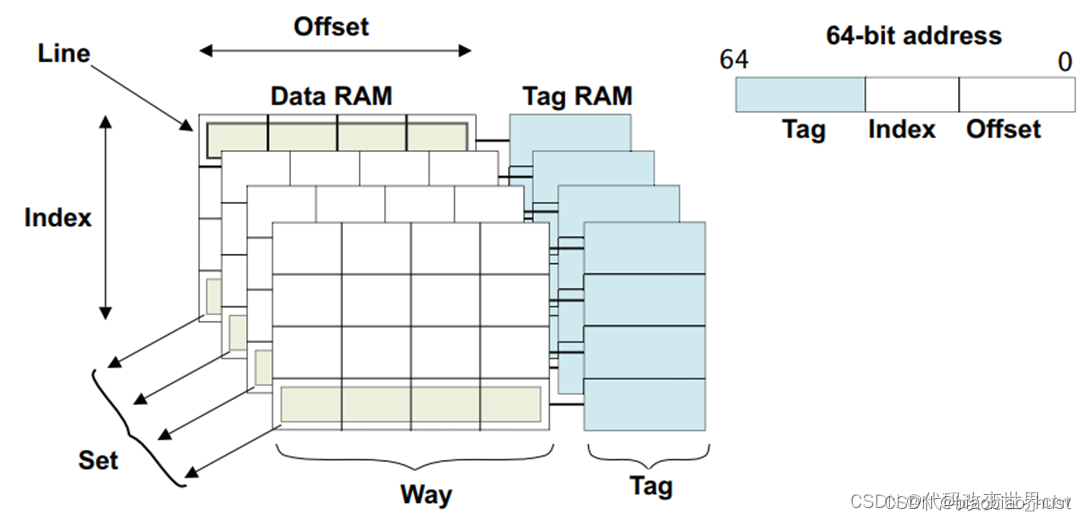
因为有了多路组相连这个cache,所以也就有了这些术语概念:
index : 用白话理解,其实就是在一块cache中,一行一行的编号(事实是没有编号/地址的)
Set :用index查询到的cache line可能是多个,这些index值一样的cacheline称之为一个set
way:用白话来说,将cache分成了多个块(多路),每一块是一个way
cache TAG :查询到了一行cache后,cachelne由 TAG + DATA组成
cache Data :查询到了一行cache后,cachelne由 TAG + DATA组成
cache Line 和 entry 是一个概念
2.5 cache的分配策略
读分配(read allocation):当CPU读数据时,发生cache缺失,这种情况下都会分配一个cache line缓存从主存读取的数据。默认情况下,cache都支持读分配。
写分配(write allocation):当CPU写数据发生cache缺失时,才会考虑写分配策略。当我们不支持写分配的情况下,写指令只会更新主存数据,然后就结束了。当支持写分配的时候,我们首先从主存中加载数据到cache line中(相当于先做个读分配动作),然后会更新cache line中的数据。
写直通(write through):当CPU执行store指令并在cache命中时,我们更新cache中的数据并且更新主存中的数据。cache和主存的数据始终保持一致。
写回(write back):当CPU执行store指令并在cache命中时,我们只更新cache中的数据。并且每个cache line中会有一个bit位记录数据是否被修改过,称之为dirty bit。我们会将dirty bit置位。主存中的数据只会在cache line被替换或者显示的clean操作时更新。因此,主存中的数据可能是未修改的数据,而修改的数据躺在cache中。cache和主存的数据可能不一致。
2.6 内存类型
在arm架构中,将物理内存分成了device和normal两种类型:
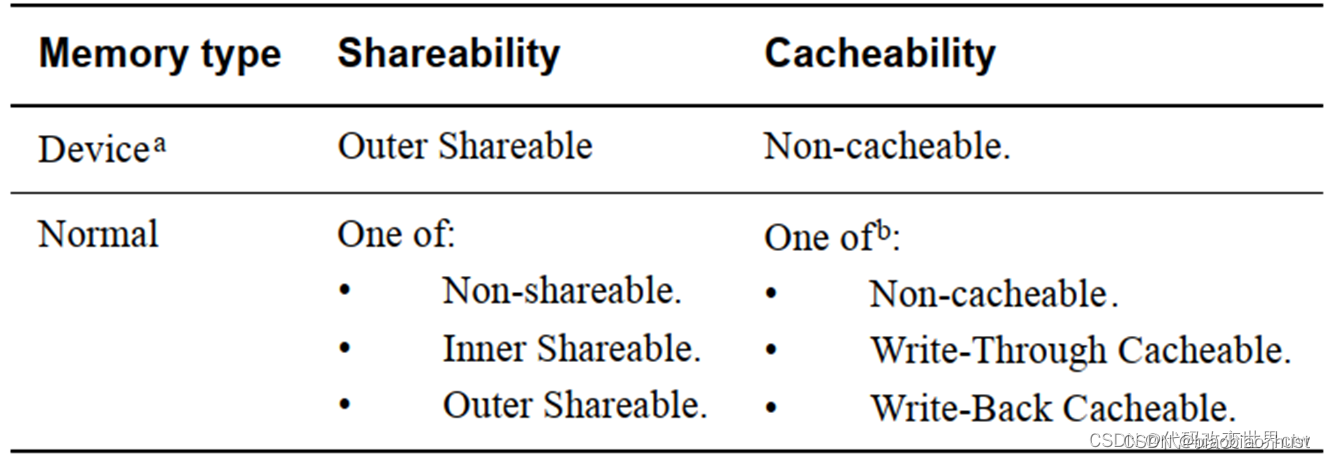
而是每种的内存下(device和normal)又分出了多种属性。ARM提供一个MAIR寄存器, 将一个64位的寄存器分成8个attr属性域,每个attr属性域有8个比特,可配置成不同的内存属性。也就是说,在一个arm core,最多支持8中物理内存类型。
3. cache的查询原理
高速缓存控制器(cache controller )是负责管理高速缓存内存的硬件块,其方式对程序来说在很大程度上是不可见的。它自动将代码或数据从主存写入缓存。它从core接收读取和写入内存请求,并对高速缓存或外部存储器执行必要的操作。
当它收到来自core的请求时,它必须检查是否能在缓存中找到所请求的地址。称为缓存查找(cache look-up)。通过将请求的地址位的subset(index)与与缓存中的physical TAG 进行比较。如果存在匹配,称为命中(hit),并且该行被标记为有效,则使用高速缓存进行读取或写入。
当core从特定地址请求指令或数据,但与缓存标签不匹配或标签无效时,会导致缓存未命中,请求必须传递到内存层次结构的下一层,即 L2缓存或外部存储器。它还可能导致缓存行填充。缓存行填充会导致将一块主内存的内容复制到缓存中。同时,请求的数据或指令被流式传输到core。这个过程软件开发人员不能直接看到。在使用数据之前,core不需要等待 linefill 完成。高速缓存控制器通常首先访问高速缓存行内的关键字。例如,如果您执行的加载指令在缓存中未命中并触发缓存行填充,则内核首先检索缓存行中包含所请求数据的那部分。这些关键数据被提供给core流水线,而缓存硬件和外部总线接口随后在后台读取缓存线的其余部分。
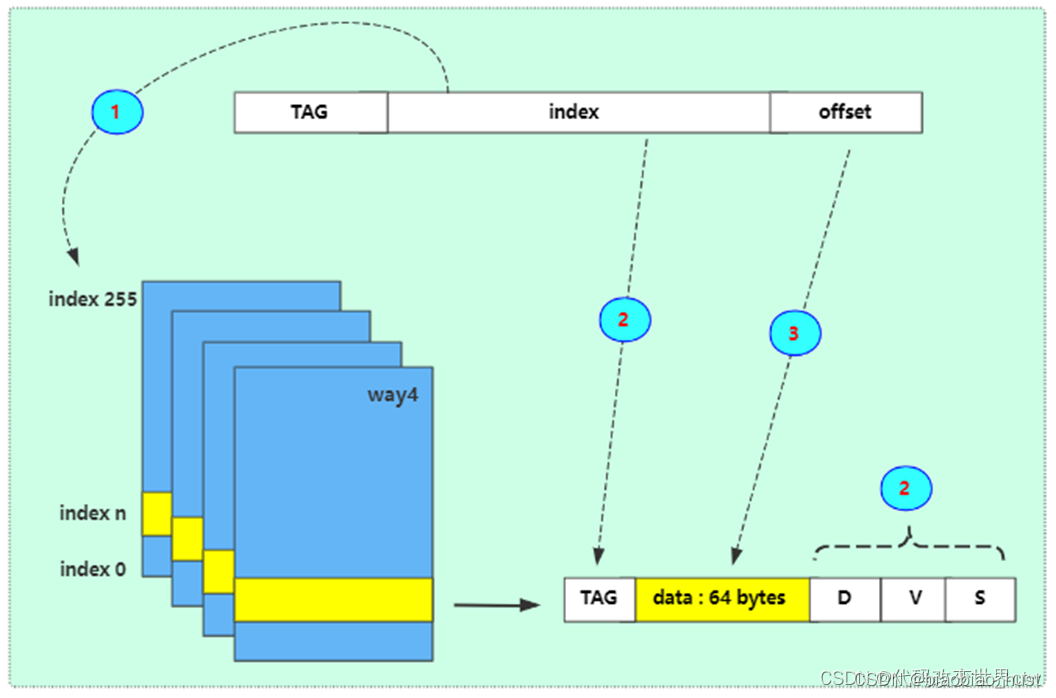
总结一下就是:先使用index去查询cache,然后再比较TAG,比较TAG之后再检查valid标志位。但是这里要注意:TAG包含了不仅仅是物理地址,还有很多其它的东西,如NS比特位等,这些都是在比较TAG的时候完成。
4. 多核多cluster多系统之间缓存一致性
4.1 bit.LITTLE架构 和 DynamIQ架构 的系统中的缓存一致性
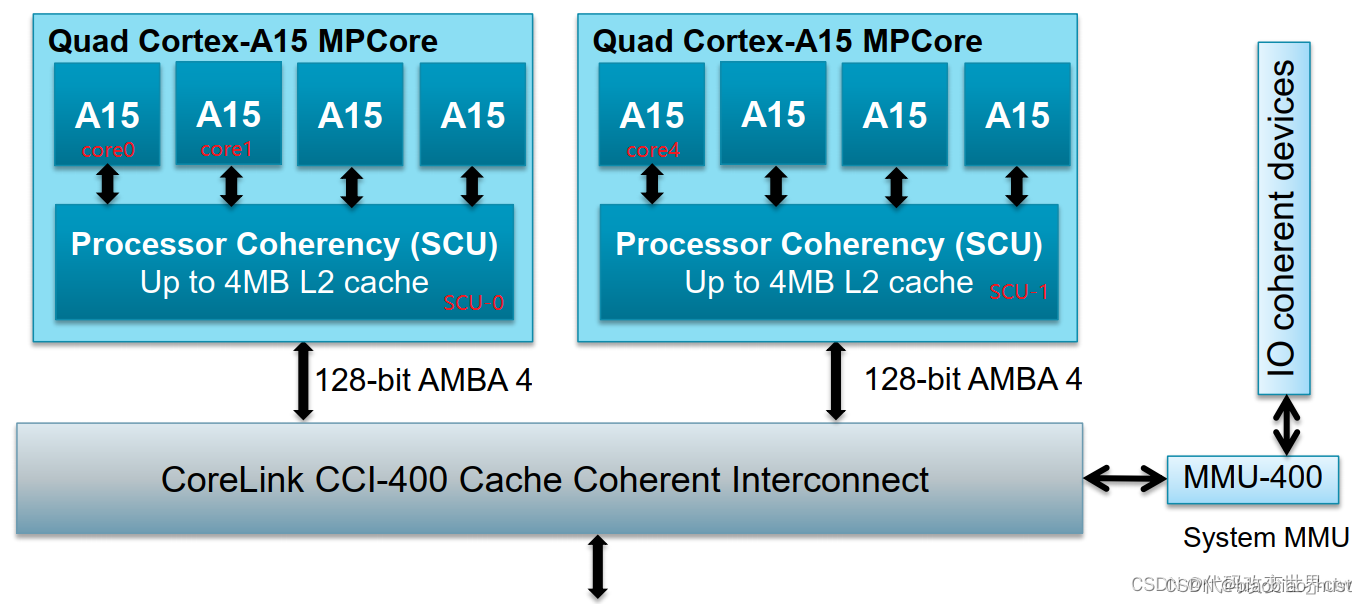
我们先看一张bit.LITTLE架构的吧:
- core0、core1的cache的一致性,是由SCU-0来维护的(至于这里是不是遵守了MESI协议,答案:YES)
- cluster0、cluster1的cache的一致性,是由于CCI-400来维护的(至于这里是不是遵守了MESI协议,答案:NO)
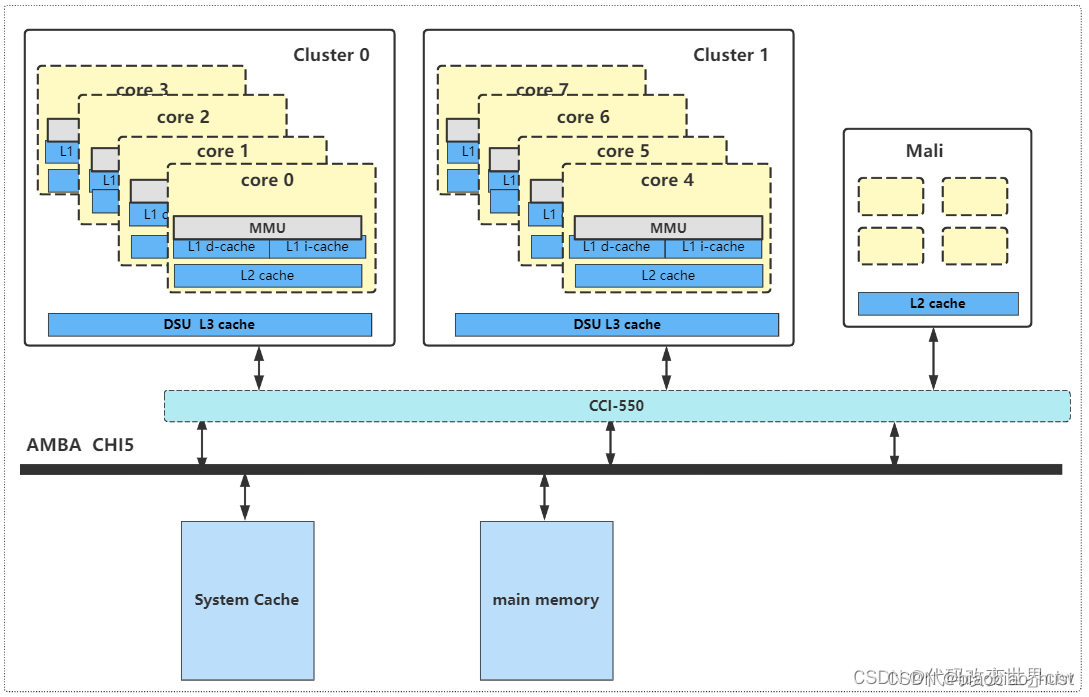
再看一张DynamIQ架构的吧:
1. core0的cache(含L1/L2)、core1的cache(含L1/L2)的一致性 由DSU-0来维护(至于这里是不是遵守了MESI协议,答案: YES)
2.cluster0的 L3 cache、cluster1的 L3 cache、Mali的L2 cache的一致性是由于CCI-550来维护的(至于这里是不是遵守了MESI协议,NO)
4.2 MESI、MOESI 的介绍
一般来讲,在core cache之间的一致性是要遵从MESI/MOESI协议的,由SCU(或DSU)硬件来执行维护该协议的。在ARM架构中,也并非所有的缓存都遵从MESI/MOESI协议,仅仅只是在一个cluster中的core cache中,才需要遵从MESI/MOESI协议。而对于不同的core,又遵从着不同的协议,具体请查略你的core TRM手册。 接下来我们就来看一下MESI协议部分。
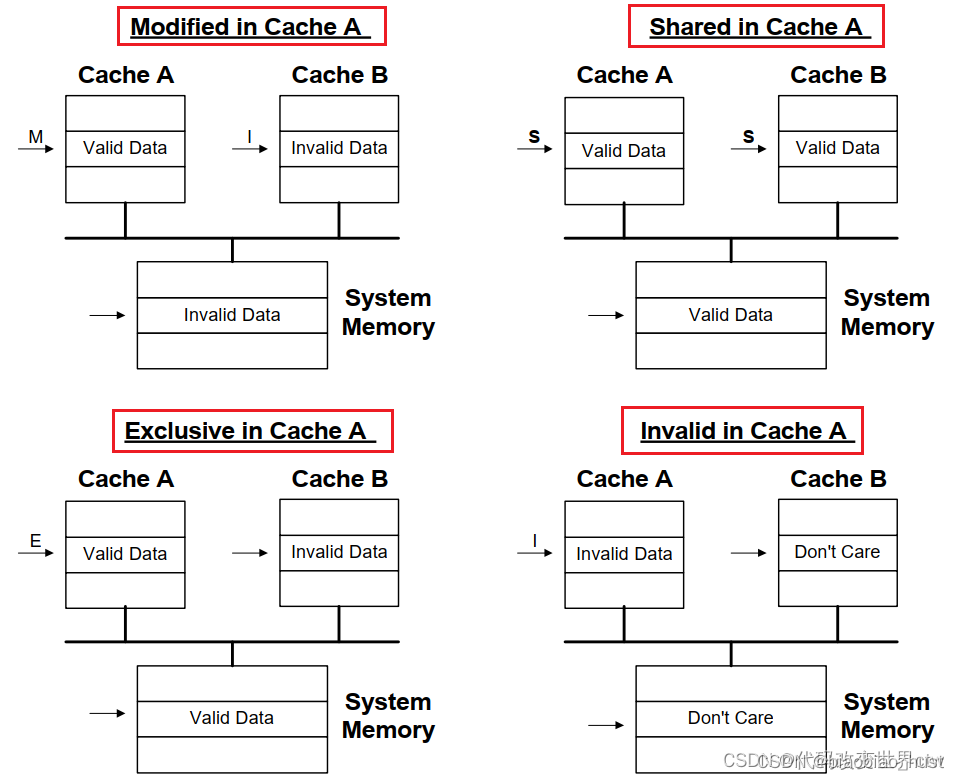
首先是Modified Exclusive Shared Invalid (MESI) 协议中定义了4个状态:
| MESI State | Definition |
| Modified (M) | 这行数据有效,数据已被修改,和内存中的数据不一致,数据只存在于该高速缓存中 |
| Exclusive (E) | 这行数据有效,数据和内存中数据一致,数据只存在于该高速缓存中 |
| Shared (S) | 这行数据有效,数据和内存中数据一致,多个高速缓存有这行数据的副本 |
| Invalid (I) | 这行数据无效 |
其次,在ARM的部分的core中,定义了第五种状态Shared Modified,这种称之为MOESI协议.
然后我们通过数据流图的方式,观看下MESI这四种状态的情况:
4.3 总结
- 我们学习cache一致性,我们最大的困惑或瓶颈应该还是对架构的理解和认知。需要去学习cache硬件基础、cache TAG、DSU、CCI-550原理吧。
- 多核之间的缓存一致性,由SCU(DSU)硬件来执行维护,使用MESI协议
- 多cluster之间的缓存一致性,由 CCI/CMN 来执行维护,没有使用MESI协议
5. 多级cache之间的替换策略
5.1 DynamIQ架构中L1 cache的替换策略(以cortex-A710为例)
我们先看一下DynamIQ架构中的cache中新增的几个概念:
- Strictly inclusive: 所有存在L1 cache中的数据,必然也存在L2 cache中
- Weakly inclusive: 当miss的时候,数据同时缓存到L1和L2,但之后,L2中数据可能会被替换
- Fully exclusive: 当miss的时候,数据只会缓存到L1
其实inclusive/exclusive属性描述的正是是 L1和L2之间的替换策略,这部分是硬件定死的,软件不可更改的。我们再去查阅 ARMV9 cortex-A710 trm手册,查看该core的cache类型,得知:
- L1 I-cache和L2之间是 weakly inclusive的
- L1 D-cache和L2之间是 strictly inclusive的
再次总结 : L1 和 L2之间的cache的替换策略,I-cache和D-cache可以是不同的策略,每一个core都有每一个core的做法,请查阅你使用core的手册。
5.2 core cache的替换策略(以cortex-A710为例)
为了能够将DynamIQ架构和bit.LITTLE架构的cache放在一起介绍,我们将DynamIQ架构中的L1/L2 cache看做成一个单元统称Core cache,bit.LITTLE架构中的L1 Cache也称之为core cache。DynamIQ架构中DSU中的L3 cache称之为cluster cache,bit.LITTLE架构中SCU中的L2 cache也称之为cluster cache。
L1 data cache:在L1 data cache TAG中,有记录MESI相关比特, 然后将一个core内的cache看做是一个整体,core与core之间的缓存一致性,就由DSU执行MESI协议来维护。
L1 Instruction cache:因为对于Instruction cache来说,都是只读的,cpu不会改写I-cache中的数据,所以也就不需要硬件维护多核之间缓存的不一致。
5.3 cluster cache 之间的替换策略
说实话,core cache / cluster cache / 这个名字可能不好,感觉叫private cache 和 share cache也会更好,我也不知道官方一般使用哪个,反正我们能理解其意思即可吧。
我们知道MMU的页表中的表项中,管理者每一块内存的属性,其实就是cache属性,也就是缓存策略。其中就有cacheable和shareable、Inner和Outer的概念。如下是针对 DynamIQ 架构做出的总结。
- Non-cacheable:那么数据就不会被缓存到cache,那么所有observer看到的内存是一致的,也就说此时也相当于Outer Shareable。其实官方文档,也有这一句的描述: “Data accesses to memory locations are coherent for all observers in the system, and correspondingly are treated as being Outer Shareable”
-
write-through cacheable 或 write-back cacheable:那么数据会被缓存cache中。write-through和write-back是缓存策略。
| Non-cacheable | write-through cacheable | write-back cacheable | |
| non-shareable | 数据不会缓存到cache (对于观察则而言,又相当于outer-shareable | core0访问该内存时,数据缓存的到Core0的L1 D-cache / L2 cache (将L1/L2看做一个整体,直接说数据会缓存到core0的private cache更好),不会缓存到其它cache中 | 同左侧 |
| inner-shareable | 数据不会缓存到cache (对于观察则而言,又相当于outer-shareable) | core0访问该内存时,数据只会缓存到core 0的L1 D-cache / L2 cache和 DSU L3 cache,不会缓存到System Cache中(当然如果有system cache的话 ) , (注意这里MESI协议其作用了)此时core0的cache TAG中的MESI状态是E, 接着如果这个时候core1也去读该数据,那么数据也会被缓存core1的L1 D-cache / L2 cache 和DSU0的L3 cache, 此时core0和core1的MESI状态都是S | 同左侧 |
| outer-shareable | 数据不会缓存到cache (对于观察则而言,又相当于outer-shareable) | core0访问该内存时,数据会缓存到core 0的L1 D-cache / L2 cache 、cluster0的DSU L3 cache 、 System Cache中, core0的MESI状态为E。如果core1再去读的话,则也会缓存到core1的L1 D-cache / L2 cache,此时core0和core1的MESI都是S 思考:那么此时core7去读取会怎样? | 同左侧 |
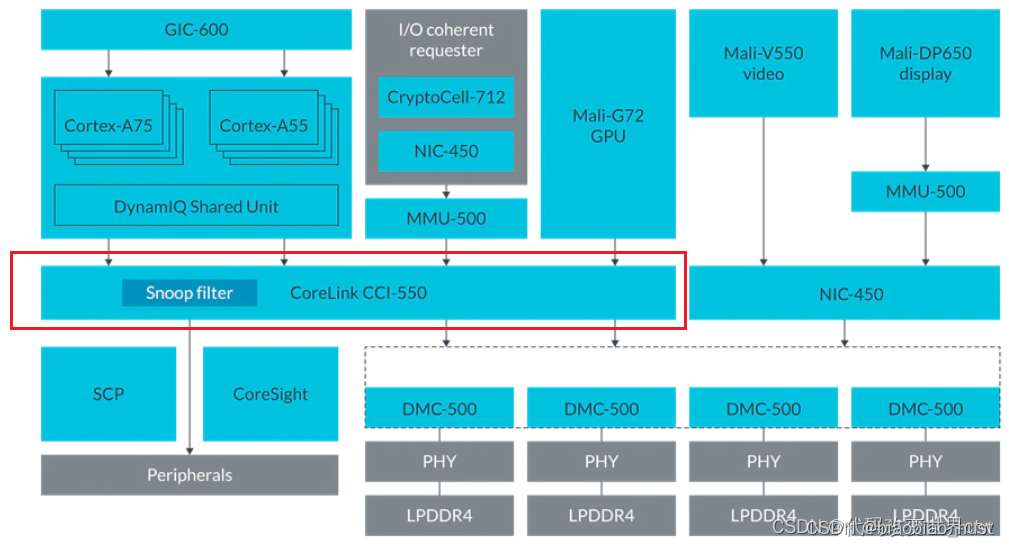
5.4 CCI简介
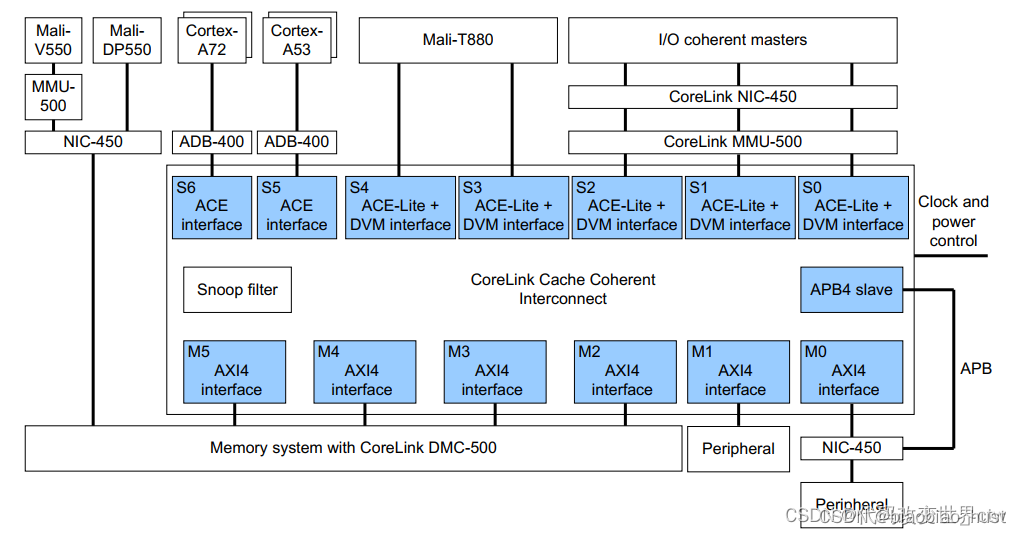
CCI-550 包含一个包容性监听过滤器(snoop filter),用于记录存储在ACE 主缓存。侦听过滤器可以在未命中的情况下响应侦听事务,并侦听适当的主控只有在命中的情况下。Snoop 过滤器条目通过观察来自 ACE 主节点的事务来维护以确定何时必须分配和取消分配条目。
侦听过滤器可以响应多个一致性请求,而无需向所有人广播ACE 接口。例如,如果地址不在任何缓存中,则监听过滤器会以未命中和将请求定向到内存。如果地址在处理器缓存中,则请求被视为命中,并且指向在其缓存中包含该地址的 ACE 端口。
5.5 总结
- dynamIQ 架构中 L1和L2之间的替换策略,是由core的inclusive/exclusive的硬件特性决定的,软无法更改
- core cache之间的替换策略,是由SCU(或DSU)执行的MESI协议中定义的,软件也无法更改。
- cluster cache之间的替换策略,是由于MMU页表中的内存属性定义的(innor/outer/cacheable/shareable),软件可以修改
原文地址:https://blog.csdn.net/weixin_50518899/article/details/135597890
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!