MySQL:表结构设计、char 和 varchar、索引数据结构、事务隔离级别、分表设计
设计MySQL的表结构要考虑什么问题?
-
主键设计要合理:主键设计的话,最好不要与业务逻辑有所关联。有些业务上的字段,比如身份证,虽然是唯一的,一些开发者喜欢用它来做主键,但是不是很建议哈。主键最好是毫无意义的一串独立不重复的数字,比如UUID,又或者Auto_increment自增的主键,或者是雪花算法生成的主键等等;
-
优先考虑逻辑删除,而不是物理删除:给数据添加一个字段,比如is_deleted,以标记该数据已经逻辑删除,最好不要进行物理删除,因为恢复数据很困难,而且物理删除会使自增主键不再连续。
-
一张表的字段不宜过多:张表的字段不宜过多哈,一般尽量不要超过 20 个字段,果一张表的字段过多,表中保存的数据可能就会很大,查询效率就会很低。当表的字段数非常多时,可以将表分成两张表,一张作为条件查询表,一张作为详细内容表。
-
尽可能使用 not null 定义字段:首先,NOT NULL 可以防止出现空指针问题。其次,NULL值存储也需要额外的空间的,它也会导致比较运算更为复杂,使优化器难以优化 SQL。NULL值有可能会导致索引失效
-
设计表时,评估哪些字段需要加索引:区分度不高的字段,不能加索引,如性别等。索引也不要建得太多,一般单表索引个数不要超过5个。因为创建过多的索引,会降低写得速度。索引创建完后,还是要注意避免索引失效的情况,如使用 mysql 的内置函数,会导致索引失效的。索引过多的话,可以通过联合索引的话方式来优化。然后的话,索引还有一些规则,如覆盖索引,最左匹配原则等等。
MySQL的char和varchar 有什么区别?
- CHAR是固定长度的字符串类型,定义时需要指定固定长度,存储时会在末尾补足空格。 CHAR适合存储长度固定的数据,如固定长度的代码、状态等,存储空间固定,对于短字符串效率较高。
- VARCHAR是可变长度的字符串类型,定义时需要指定最大长度,实际存储时根据实际长度占用存储空间。 VARCHAR适合存储长度可变的数据,如用户输入的文本、备注等,节约存储空间。
索引的底层数据结构有哪些实现方式?了解hash索引吗?
MySQL 常见索引有 B+Tree 索引、HASH 索引、Full-Text 索引。
- B+Tree 索引:是 MySQL 默认存储引擎 InnoDB 采用索引数据结构,所有数据都存储在叶子节点中,非叶子节点只存储索引,提高范围查询的性能和减少磁盘IO开销,千万级的数据量 b+树的树高只需要 3 层。
- Full-Text 索引:全文索引用于对文本内容进行搜索,采用倒排索引等数据结构来实现全文搜索功能,支持关键字搜索和模糊查询。
- 哈希索引:哈希索引通过哈希函数计算键的存储位置,适用于等值查找,速度快但不支持范围查找。
为什么用B+树呢?
- B+Tree vs 二叉树:对于有 N 个叶子节点的 B+Tree,其搜索复杂度为O(logdN),其中 d 表示节点允许的最大子节点个数为 d 个。在实际的应用当中, d 值是大于100的,这样就保证了,即使数据达到千万级别时,B+Tree 的高度依然维持在 3~ 4 层左右,也就是说一次数据查询操作只需要做 3~4 次的磁盘 I/O 操作就能查询到目标数据。而二叉树的每个父节点的儿子节点个数只能是 2 个,意味着其搜索复杂度为 O(logN),这已经比 B+Tree 高出不少,因此二叉树检索到目标数据所经历的磁盘 I/O 次数要更多。
- B+Tree vs Hash:Hash 在做等值查询的时候效率贼快,搜索复杂度为 O(1)。但是 Hash 表不适合做范围查询,它更适合做等值的查询,这也是 B+Tree 索引要比 Hash 表索引有着更广泛的适用场景的原因。
- B+Tree vs B Tree:B+Tree 只在叶子节点存储数据,而 B 树 的非叶子节点也要存储数据,所以 B+Tree 的单个节点的数据量更小,在相同的磁盘 I/O 次数下,就能查询更多的节点。另外,B+Tree 叶子节点采用的是双链表连接,适合 MySQL 中常见的基于范围的顺序查找,而 B 树无法做到这一点。
事务的隔离级别有哪些?
四个隔离级别如下:
- 读未提交,指一个事务还没提交时,它做的变更就能被其他事务看到;
- 读提交,指一个事务提交之后,它做的变更才能被其他事务看到;
- 可重复读,指一个事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,MySQL InnoDB 引擎的默认隔离级别;
- 串行化;会对记录加上读写锁,在多个事务对这条记录进行读写操作时,如果发生了读写冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行;
按隔离水平高低排序如下:
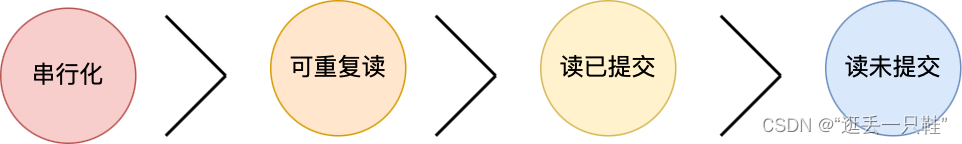
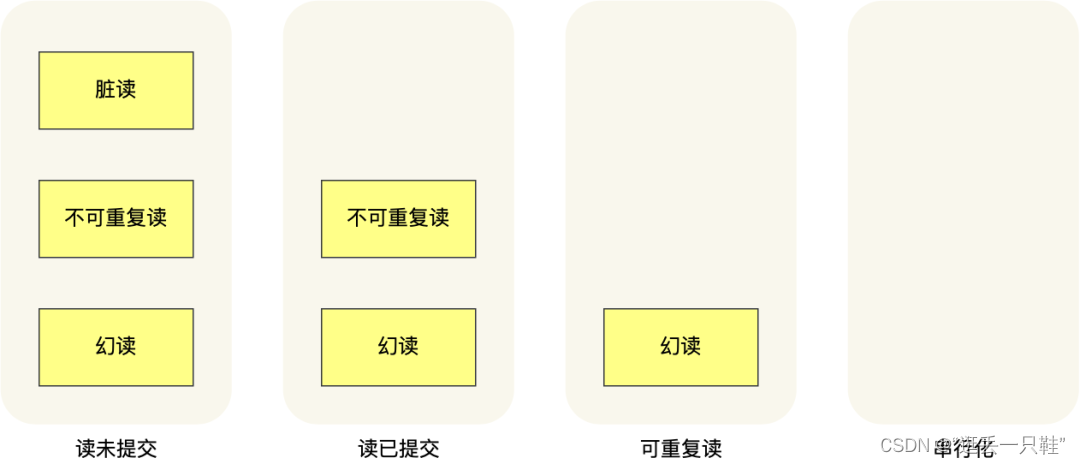
针对不同的隔离级别,并发事务时可能发生的现象也会不同。
当前读和快照读有什么区别?
- 当前读可以读取其他事务最新已经提交的事务,执行的过程中会通过加行级锁的方式保证事务的隔离性,比如 select for update、update、 delete 都属于当前读。
- 快照读是无锁的, 主要是基于mvcc机制实现的,可重复读和读已提交的 select 都属于快照读。
- 「可重复读」隔离级别是启动事务时生成一个 Read View,然后整个事务期间都在用这个 Read View,这样就保证了在事务期间读到的数据都是事务启动前的记录。
- 「读提交」隔离级别是在每个 select 都会生成一个新的 Read View,也意味着,事务期间的多次读取同一条数据,前后两次读的数据可能会出现不一致,因为可能这期间另外一个事务修改了该记录,并提交了事务。
MySQL分表怎么设计?
一般可以采用以下几种常见的分表策略:
-
按时间分表:根据数据的时间特征,按照时间范围(如年、月、日)将数据分散存储到不同的表中,便于数据归档和查询。
-
按业务分表:根据业务需求将数据按照业务逻辑进行分表,可以根据不同的业务属性将数据分散到不同的表中,实现逻辑上的分离。
-
按哈希分表:通过对数据的哈希计算,将数据均匀分布到多个表中,避免单表数据量过大导致性能问题。
-
按范围分表:根据数据的某个范围属性(如用户ID、地区ID等)将数据分散到不同的表中,便于查询和管理特定范围的数据。
-
按数据量分表:当单表数据量过大时,可以按照一定的规则将数据拆分到多个表中,避免单表数据量过大导致性能下降。
原文地址:https://blog.csdn.net/szm1234/article/details/136714434
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!