LoRA技术详解---附实战代码
LoRA技术详解—附实战代码
引言
随着大语言模型规模的不断扩大,如何高效地对这些模型进行微调成为了一个重要的技术挑战。Low-Rank Adaptation(LoRA)技术应运而生,它通过巧妙的低秩分解方法,显著减少了模型微调时需要训练的参数数量,同时保持了良好的性能表现。本文将深入介绍LoRA的原理,并通过详细的PyTorch代码实现来展示其工作机制。
LoRA的核心原理
基本思想
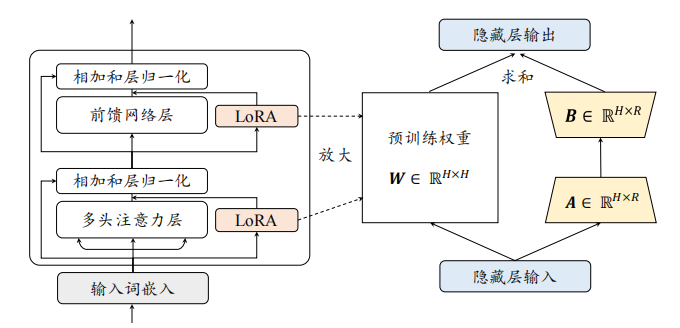
LoRA的核心思想是:在保持预训练模型权重不变的情况下,通过向每个转换器层添加低秩矩阵来实现模型的适应性调整。具体来说,对于原始的权重矩阵 W 0 ∈ R d × k W_0 \in \mathbb{R}^{d \times k} W0∈Rd×k,LoRA引入了如下的更新机制:
W = W 0 + Δ W = W 0 + B A W = W_0 + \Delta W = W_0 + BA W=W0+ΔW=W0+BA
其中:
- B ∈ R d × r B \in \mathbb{R}^{d \times r} B∈Rd×r
- A ∈ R r × k A \in \mathbb{R}^{r \times k} A∈Rr×k
- r r r 是一个远小于 d d d 和 k k k 的秩
关键特征
- 参数高效性:通过引入低秩分解,LoRA显著减少了需要训练的参数量。
- 初始化策略: Δ W \Delta W ΔW 在训练开始时被初始化为零矩阵,确保了模型从原始性能开始逐步调整。
- 可扩展性:可以轻松应用于不同类型的层,如线性层和嵌入层。
实现细节分析
1. 初始化策略
LoRA的初始化策略非常关键:
- 对于线性层,矩阵A使用kaiming均匀初始化
- 对于嵌入层,矩阵A使用正态分布初始化
- 两种情况下,矩阵B都初始化为零,确保训练开始时 Δ W = B A = 0 \Delta W = BA = 0 ΔW=BA=0
2. 缩放因子
缩放因子 α r \frac{\alpha}{r} rα的引入有两个主要作用:
- 控制LoRA更新的幅度
- 使得不同秩r的实验结果更具可比性
3. 前向传播
在前向传播中,LoRA的更新通过以下步骤实现:
- 计算原始层的输出
- 计算低秩更新: ( x @ A T @ B T ) ∗ α r (x @ A^T @ B^T) * \frac{\alpha}{r} (x@AT@BT)∗rα
- 将两部分结果相加
PyTorch实现详解
LoRA线性层实现
class Linear(nn.Module):
def __init__(self, in_features: int, out_features: int, bias: bool,
r: int, alpha: int = None):
super().__init__()
self.in_features = in_features
self.out_features = out_features
# 设置缩放因子
if alpha is None:
alpha = r
self.scaling = alpha / r
# 原始权重(冻结)
self.weight = nn.Parameter(torch.empty((out_features, in_features)))
self.weight.requires_grad = False
# 偏置项处理
if bias:
self.bias = nn.Parameter(torch.empty(out_features))
self.bias.requires_grad = False
else:
self.bias = None
# LoRA参数初始化
self.lora_a = nn.Parameter(torch.empty((r, in_features)))
self.lora_b = nn.Parameter(torch.empty((out_features, r)))
# 初始化
with torch.no_grad():
nn.init.kaiming_uniform_(self.lora_a, a=5 ** 0.5)
nn.init.zeros_(self.lora_b)
def forward(self, x: torch.Tensor):
# 原始线性变换
result = nn.functional.linear(x, self.weight, bias=self.bias)
# 添加LoRA部分
result += (x @ self.lora_a.T @ self.lora_b.T) * self.scaling
return result
LoRA嵌入层实现
class Embedding(nn.Module):
def __init__(self, num_embeddings: int, embedding_dim: int,
r: int, alpha: int = None):
super().__init__()
# 设置缩放因子
if alpha is None:
alpha = r
self.scaling = alpha / r
# 原始嵌入权重(冻结)
self.weight = nn.Parameter(torch.empty((num_embeddings, embedding_dim)))
self.weight.requires_grad = False
# LoRA参数初始化
self.lora_a = nn.Parameter(torch.empty((r, num_embeddings)))
self.lora_b = nn.Parameter(torch.empty((embedding_dim, r)))
# 初始化
with torch.no_grad():
nn.init.normal_(self.lora_a)
nn.init.zeros_(self.lora_b)
def forward(self, x: torch.Tensor):
# 原始嵌入查找
result = nn.functional.embedding(x, self.weight)
# 添加LoRA部分
result += (nn.functional.embedding(x, self.lora_a.T) @ self.lora_b.T) * self.scaling
return result
原文地址:https://blog.csdn.net/qq_42896106/article/details/142767768
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!