Hadoop安装部署-单机版
Apache Hadoop是一个使用HDFS(Hadoop Distributed File System)分布式文件系统执行可靠的、规模化的分布式计算的开源项目,Hadoop是使用Java语言开发,其运行在Linux操作系统上集群规模最大支持几千个分布式节点,本文主要描述Hadoop单机版的安装部署。
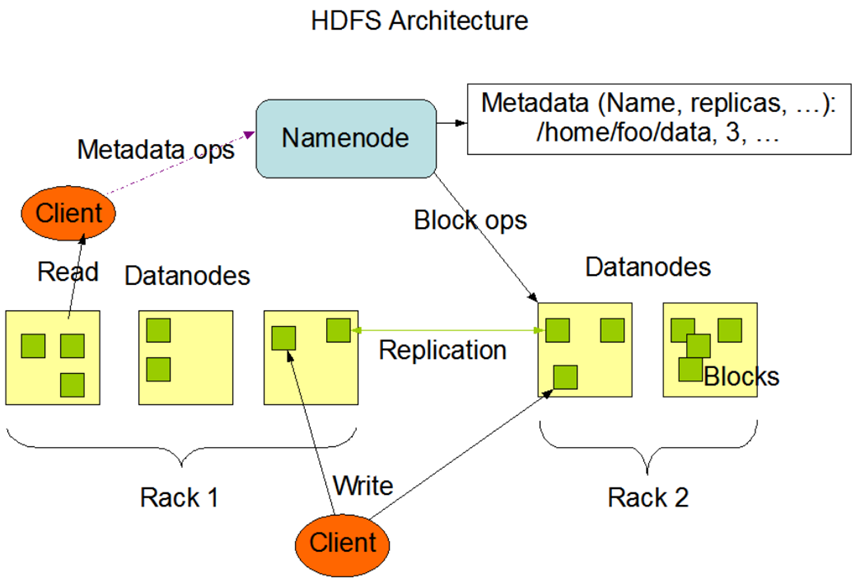
如上所示,HDFS分布式文件系统的架构图,其中,Namenode节点主要提供数据文件索引服务,Datanode节点主要提供数据分片的存储服务,Namenode服务支持多节点的高可用性部署,Datanode支持大规模的分布式集群部署,数据分片实现备份复制的高可用性机制
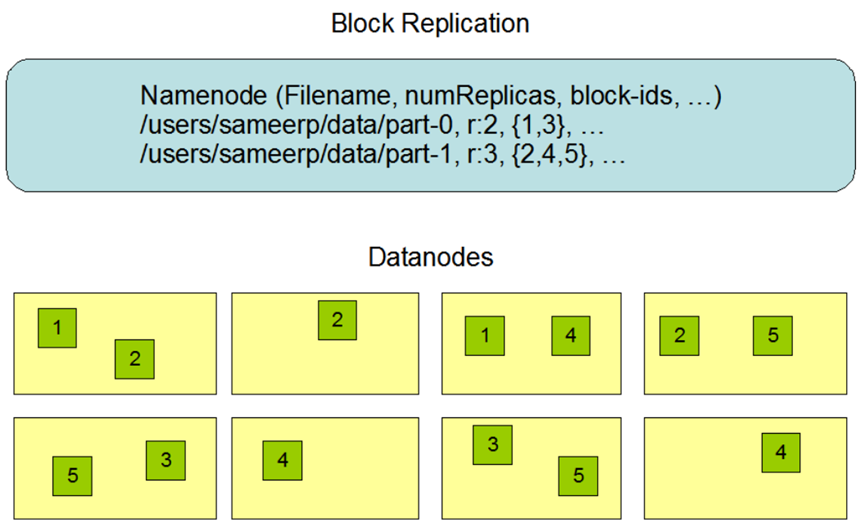
如上所示,一个用户数据文件可分为多个数据块存储在多个Datanode中,每个数据块拥有一个ID标识,每个数据块以备份复制的方式存储在不同的Datanode中实现高可用性,part-0文件分为1、3的数据块,每个数据块复制2份,part-1文件分为2、4、5的数据块,每个数据块复制3份,读取part-0文件的时候分别读取1、3数据块合并成完整的文件,读取part-1文件的时候分别读取2、4、5数据块合并成完整的文件

如上所示,从OpenJDK官方下载JDK8版本、从Hadoop官方下载最新的稳定版本
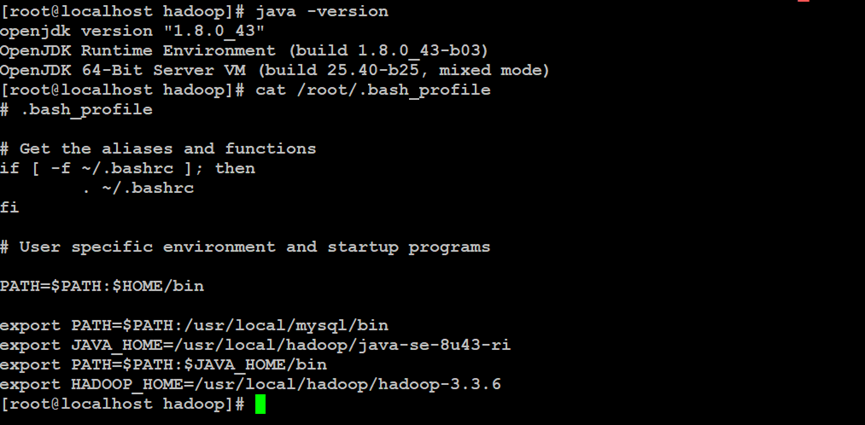

如上所示,安装与配置OpenJDK8
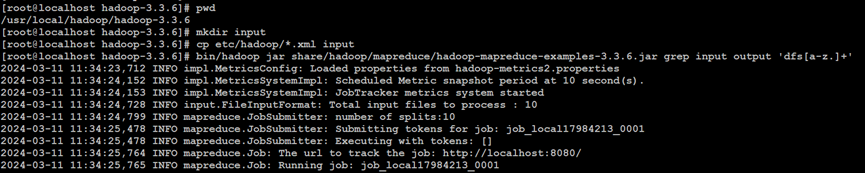

如上所示,使用Hadoop的样例MapReduce算法统计input文件夹的文件列表中,包含有匹配dfs[a-z.]+正则表达式的字符串的统计信息,该正则表达式匹配以字符串dfs为前缀、以a到z小写英文字母以及点号的任意组合为后缀的字符串,文件夹output输出中显示包括一个字符串dfsadmin
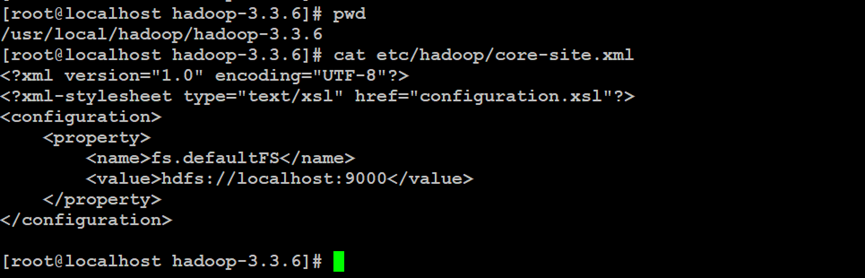
如上所示,设置Hadoop分布式文件系统的接口访问的地址
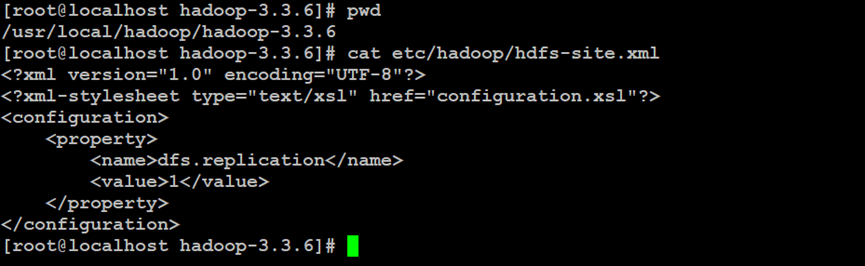
如上所示,设置Hadoop分布式文件系统的复制备份策略
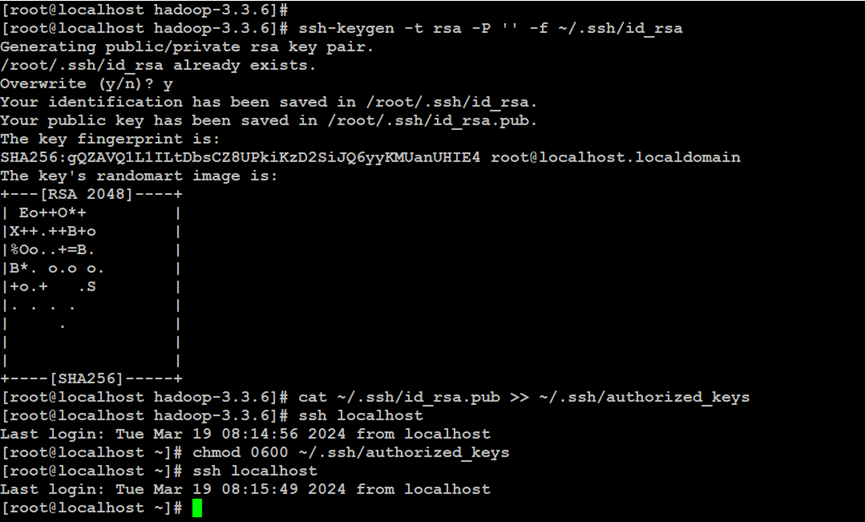
如上所示,设置Hadoop分布式集群节点的ssh免密登录
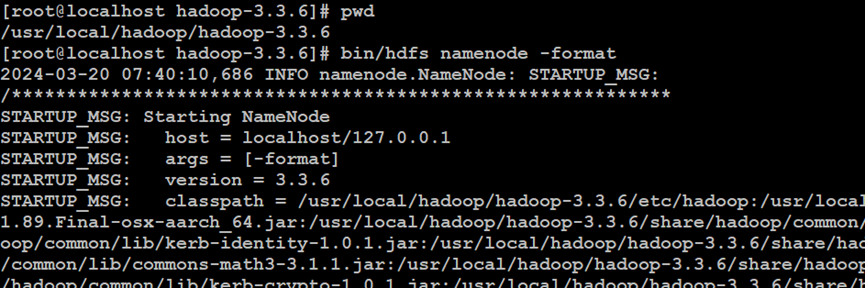
如上所示,格式化Hadoop分布式文件系统
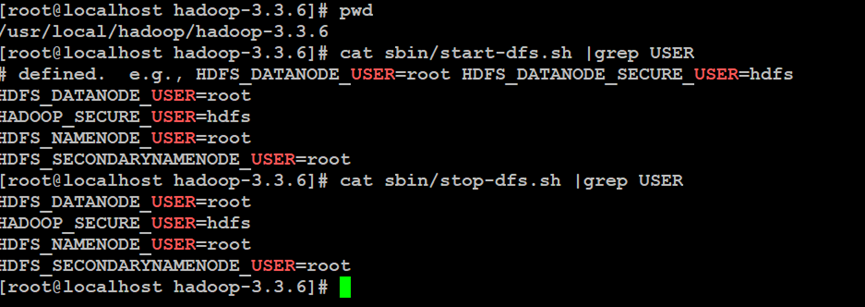
如上所示,配置Hadoop分布式文件系统的用户环境变量
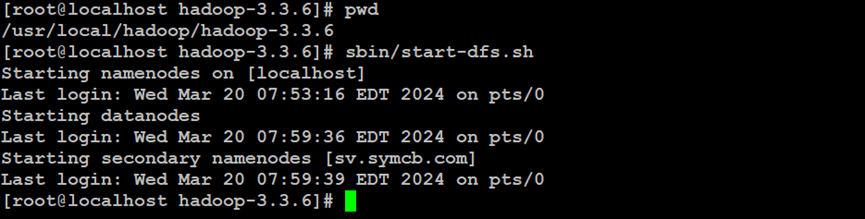
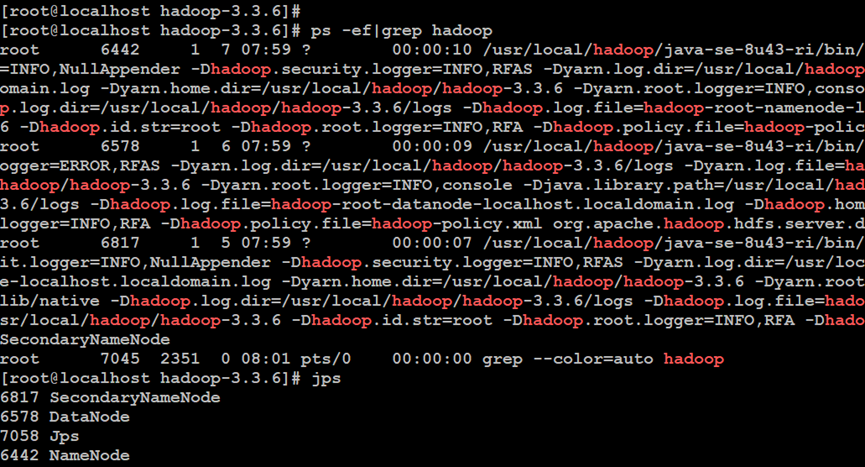
如上所示,启动Hadoop分布式文件系统服务,其中,包括NameNode服务以及DataNode服务
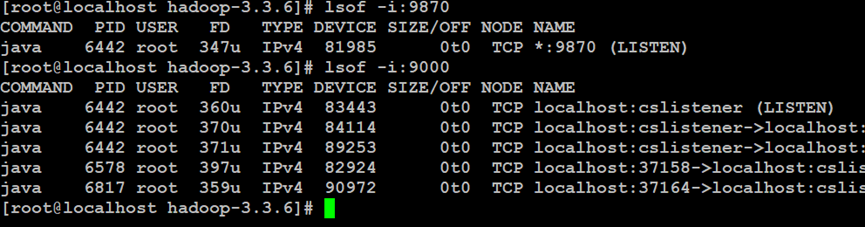

如上所示,查看Hadoop分布式文件系统服务的端口使用,其中,9870端口是web平台服务,9000端口是分布式文件系统的平台服务,9866端口是DataNode提供的服务
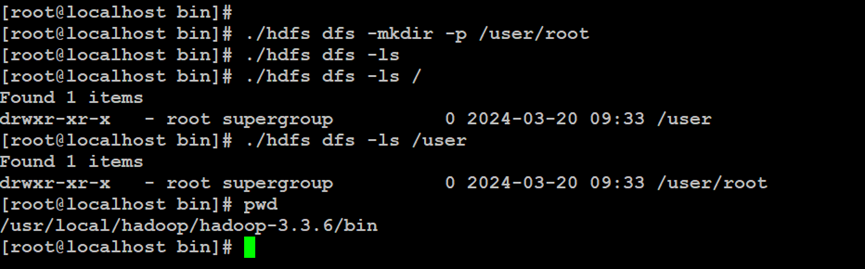
如上所示,在Hadoop分布式文件系统中新建用户目录


如上所示,在Hadoop分布式文件系统中执行MapReduce计算,输出到output文件夹中
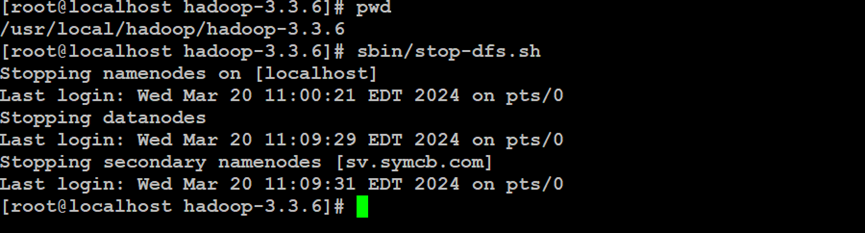
如上所示,停止Hadoop分布式文件系统服务
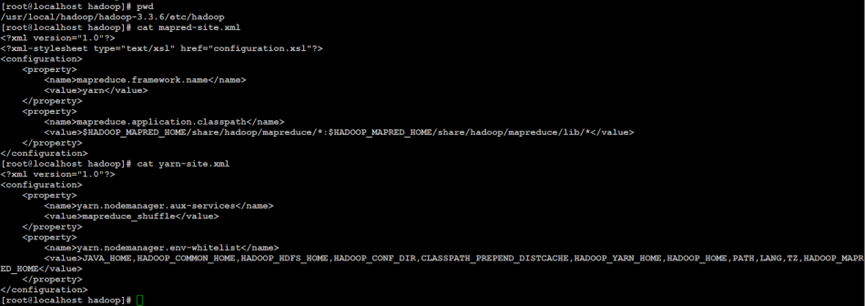
如上所示,配置Hadoop分布式文件系统的YARN资源管理器
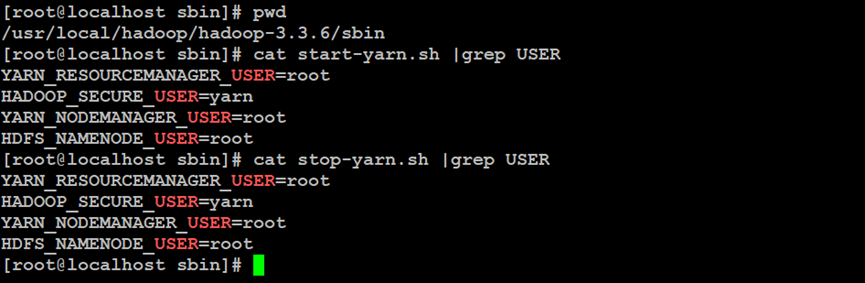
如上所示,配置Hadoop分布式文件系统的YARN资源管理器的用户环境变量
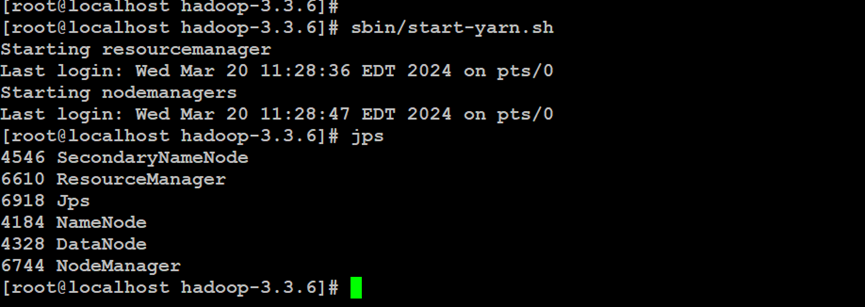
如上所示,启动Hadoop分布式文件系统的YARN资源管理器服务
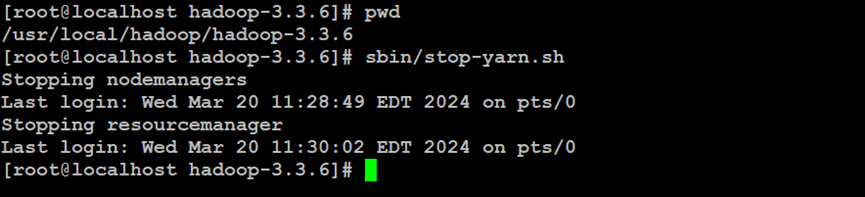
如上所示,停止Hadoop分布式文件系统的YARN资源管理器服务
原文地址:https://blog.csdn.net/uesowys/article/details/136905303
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!