【小白请绕道】Redis 的 I/O 多路复用技术,它是如何工作的?
Redis 的 I/O 多路复用技术是其高性能的关键之一。在单个线程中,Redis 可以同时处理多个网络连接,这是通过使用 I/O 多路复用技术实现的。这种技术允许 Redis 在单个线程中监听多个套接字,并在套接字准备好执行操作时(如读取或写入),执行相应的操作。
I/O 多路复用的工作方式
I/O 多路复用技术,如 select、poll、epoll(Linux 上的事件通知机制),kqueue(在 BSD 系统上)等,允许单个线程监视多个套接字。当套接字上的数据准备好读取或写入时,操作系统通知应用程序,然后应用程序可以执行相应的读取或写入操作。
I/O 多路复用是一种处理多个输入输出通道(通常是网络连接)的技术,它允许单个线程处理多个输入输出请求。这种方式在网络服务器和其他需要同时处理多个客户端请求的应用程序中非常有用。I/O 多路复用的关键优势是它能够在单个线程中管理多个连接,而不需要为每个连接创建一个新的线程,从而减少了资源消耗和上下文切换的开销。
工作方式
-
监听多个通道:服务器应用程序使用 I/O 多路复用技术来监听多个通道(例如,客户端的网络连接)。这些通道可以是套接字(socket)。
-
监控状态变化:I/O 多路复用技术监控这些通道的状态变化,例如是否有数据可读、是否可以写入数据等。
-
事件通知:当某个通道的状态发生变化,并且该事件符合应用程序设定的监控条件时,操作系统会通知应用程序。
-
事件处理:应用程序接收到通知后,会调用相应的事件处理函数来处理事件。例如,如果一个通道可读,应用程序可能会读取数据;如果一个通道可写,应用程序可能会写入数据。
-
非阻塞操作:在 I/O 多路复用模型中,通道通常被设置为非阻塞模式。这意味着当尝试读取或写入数据时,如果数据不可用,操作会立即返回,而不是等待。
I/O 多路复用技术
-
select:
select是最早的 I/O 多路复用技术之一。- 它允许应用程序监视一组文件描述符,以确定它们是否处于可读、可写或异常状态。
select有一个缺点,即它使用一个固定大小的位集合来跟踪文件描述符,这限制了它可以监视的文件描述符的数量。
-
poll:
poll与select类似,但它没有最大文件描述符数量的限制。poll不使用位集合,而是使用动态分配的数组来跟踪文件描述符。
-
epoll(Linux 特定):
epoll是 Linux 提供的一种高效的 I/O 多路复用技术。- 它不需要在每次调用时重复传递文件描述符集合,而是在初始化时创建一个
epoll文件,然后使用它来添加或删除要监视的文件描述符。 epoll能够更高效地处理大量文件描述符,因为它使用内核数据结构来跟踪状态变化。
-
kqueue(BSD 系统):
kqueue是在 BSD 系统(如 macOS 和 FreeBSD)上的一种高效的 I/O 多路复用技术。- 它允许应用程序注册要监视的事件,并且可以处理多种类型的事件,包括文件描述符事件和定时器事件。
工作流程
-
初始化:应用程序初始化一个 I/O 多路复用实例(例如,创建一个
epoll实例或设置一个select调用)。 -
注册文件描述符:应用程序将需要监视的文件描述符注册到 I/O 多路复用实例中。
-
等待事件:应用程序调用 I/O 多路复用函数(如
select、poll、epoll_wait或kevent),并等待事件的发生。 -
处理事件:当事件发生时,操作系统通知应用程序,应用程序根据事件类型调用相应的事件处理函数。
-
循环:应用程序在一个循环中重复执行上述步骤,以持续监听和处理事件。
I/O 多路复用技术是构建高性能网络服务器的关键,它使得服务器能够有效地处理大量并发连接,同时保持资源使用的高效性。
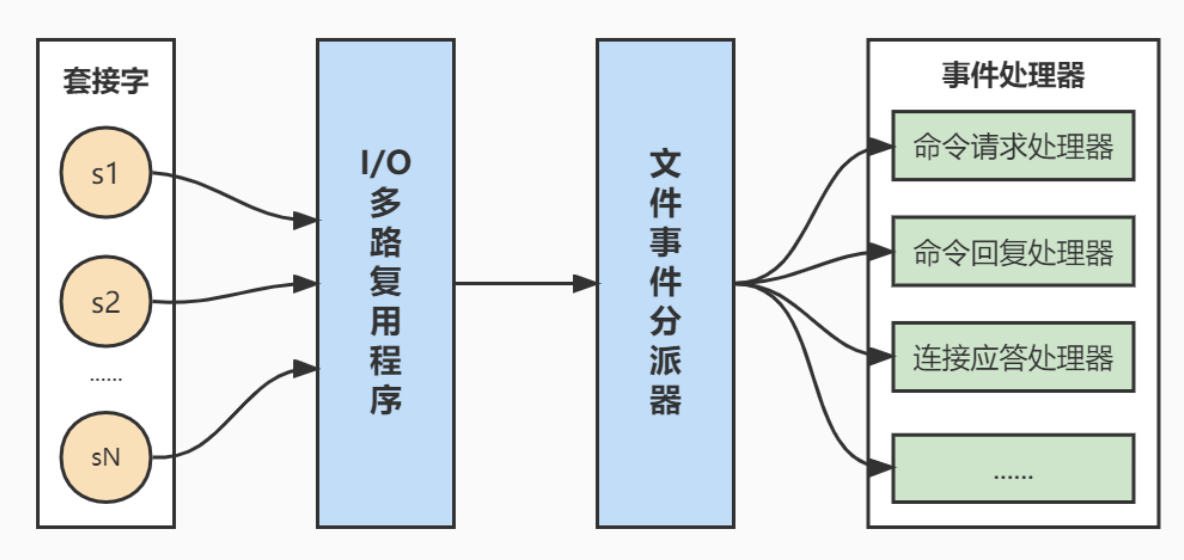
Redis 的 Reactor 模式
Redis 的 Reactor 模式是其高性能网络事件处理器的核心。这种模式基于事件驱动,使用非阻塞 I/O 多路复用技术来同时监控多个套接字,并在套接字准备好执行操作时(如读取或写入),执行相应的事件处理函数。
Reactor 模式的实现原理
-
事件分派器(Reactor):这是模式的核心,负责监听和分发事件。在 Redis 中,Reactor 通过 I/O 多路复用技术(如
epoll、select、kqueue)来监控多个套接字,并将发生的事件分派给相应的事件处理器。 -
事件处理器:这些是处理具体事件的函数,如读取客户端请求、发送响应等。在 Redis 中,事件处理器包括连接应答处理器、命令请求处理器和命令回复处理器。
-
事件创建器:用于添加新事件或删除不再需要的事件。
Reactor 模式的代码实现
在 Redis 中,Reactor 模式的实现代码主要在 ae.c 文件中。我们通过一个简化的示例,来解释使用 epoll 实现 Reactor 模式的基本工作流程,先来看一下整体,我们再分段解释:
int epfd = epoll_create1(0);
if (epfd == -1) {
perror("epoll_create1");
exit(EXIT_FAILURE);
}
struct epoll_event event, events[MAX_EVENTS];
// 设置事件
event.events = EPOLLIN | EPOLLET;
event.data.fd = STDIN_FILENO;
if (epoll_ctl(epfd, EPOLL_CTL_ADD, STDIN_FILENO, &event) == -1) {
perror("epoll_ctl");
exit(EXIT_FAILURE);
}
// 事件循环
while (1) {
int nfds = epoll_wait(epfd, events, MAX_EVENTS, -1);
if (nfds == -1) {
perror("epoll_wait");
exit(EXIT_FAILURE);
}
for (int n = 0; n < nfds; ++n) {
if (events[n].events & EPOLLIN) {
handle_read(events[n].data.fd);
}
}
}
close(epfd);
return 0;
在这个示例中,epoll_create1 创建一个新的 epoll 实例,epoll_ctl 用于添加需要监听的事件,epoll_wait 等待事件发生,并在事件发生时调用 handle_read 函数来处理读取操作。
下面来具体分段解释:
- 创建 epoll 实例:
int epfd = epoll_create1(0);
if (epfd == -1) {
perror("epoll_create1");
exit(EXIT_FAILURE);
}
epoll_create1(0)创建一个新的epoll实例,并返回一个文件描述符epfd,用于后续的事件管理。- 如果创建失败,打印错误信息并退出程序。
- 定义事件结构:
struct epoll_event event, events[MAX_EVENTS];
struct epoll_event是epoll事件的基本数据结构,用于描述要监视的事件及其相关数据。events数组用于存储epoll_wait返回的事件。
- 设置要监视的事件:
event.events = EPOLLIN | EPOLLET;
event.data.fd = STDIN_FILENO;
if (epoll_ctl(epfd, EPOLL_CTL_ADD, STDIN_FILENO, &event) == -1) {
perror("epoll_ctl");
exit(EXIT_FAILURE);
}
event.events设置为EPOLLIN | EPOLLET:EPOLLIN表示要监视可读事件。EPOLLET表示使用边缘触发(Edge Triggered)模式,只有在状态变化时才会通知。
event.data.fd设置为STDIN_FILENO,表示监视标准输入。epoll_ctl函数将标准输入的事件添加到epoll实例中。
- 事件循环:
while (1) {
int nfds = epoll_wait(epfd, events, MAX_EVENTS, -1);
if (nfds == -1) {
perror("epoll_wait");
exit(EXIT_FAILURE);
}
for (int n = 0; n < nfds; ++n) {
if (events[n].events & EPOLLIN) {
handle_read(events[n].data.fd);
}
}
}
epoll_wait阻塞地等待事件的发生,返回发生事件的数量nfds。- 如果
nfds为负,表示出错,打印错误信息并退出。 - 遍历
events数组,处理每个发生的事件:- 检查事件类型是否为可读事件(
EPOLLIN)。 - 调用
handle_read函数处理可读事件,通常用于读取数据。
- 检查事件类型是否为可读事件(
- 关闭 epoll 实例:
close(epfd);
return 0;
- 关闭
epoll文件描述符,释放资源。
实现逻辑和原理是这样的:
- I/O 多路复用:通过
epoll,程序可以在单个线程中同时监听多个文件描述符(如网络套接字),从而高效地处理并发连接。 - 事件驱动:当某个文件描述符的状态发生变化(如有数据可读),
epoll会通知应用程序,应用程序随后可以处理这些事件。 - 边缘触发模式:使用
EPOLLET使得应用程序在状态变化时才会被通知,减少了不必要的事件通知,提高了性能。 - 单线程处理:通过单线程模型,避免了多线程带来的上下文切换和同步开销,使得处理逻辑更加简单。
性能优化
在高并发场景下,可以通过以下方式优化 Lettuce 的性能(需要对Lettuce有认识哈):
-
连接池配置:合理配置连接池的大小,以适应并发需求。
-
使用 Pipeline:通过 Pipeline 批处理命令,减少网络往返次数。
-
集群支持:在 Redis 集群环境中,确保客户端配置正确,以优化性能。
-
监控和调优:使用监控工具跟踪性能指标,并根据需要调整配置。
通过这些机制,Redis 的 Reactor 模式能够在高并发场景下保持高性能,同时提供线程安全的操作和良好的用户体验。
总结
使用 I/O 多路复用技术,Redis 可以高效地处理大量并发连接,而不需要为每个连接创建新的线程,这减少了线程切换的开销,并提高了性能。此外,Redis 6.0 引入了多线程来处理客户端的请求和回复,进一步提高了性能。
Redis 的 I/O 多路复用技术是其高性能的关键因素之一。通过在单个线程中处理多个网络事件,Redis 能够以极高的效率服务于大量的客户端连接。这种技术的应用,使得 Redis 成为一个非常快速且可扩展的内存数据库解决方案。
原文地址:https://blog.csdn.net/finally_vince/article/details/142484481
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!