重生之我们在ES顶端相遇第15 章 - ES 的心脏-倒排索引
前言
上一章,简单介绍了 ES 的节点类型。
本章,我们要介绍 ES 中非常重要的一个概念:倒排索引。
ES 的全文索引就是基于倒排索引实现的。
本章内容建议重点学习,因为面试也常问。
为什么叫倒排索引
倒排索引指的是将每一个关键字映射到它出现的文档中。如下图所示

因为结构是倒着的,因此被称为倒排索引。
数据结构
倒排索引分为 2 部分:一部分叫 term directory(term 词典),一部分叫 posting list(倒排列表)。如下图所示

-
term directory
term 字典,存放着每个单词到对应倒排列表的映射关系 -
posting list
Docs 是一个数组。其中 1:2:[2,6] 意思如下- 1:文档ID
- 2:词频(term frequency)
- [2,6]:出现在文档中的第 2,6 个 term。
如何生成
这里涉及到我们之前讲过的分词器。工作流程如下图所示

大体就包含2部分,根据分词器将文本分词,然后根据分词生成倒排索引。
如何查询
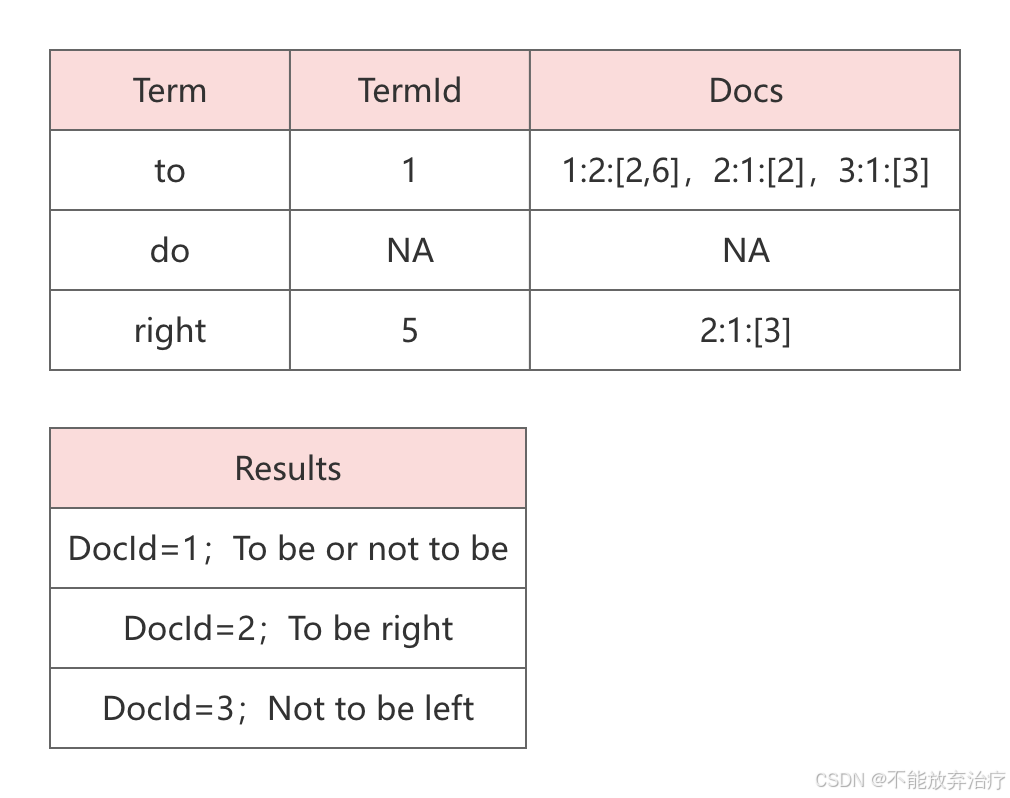
例如我们查询:To do right。
则该文本会先被分词为:to, do, right
对应的结果如下图所示:
TF、IDF
默认情况下,ES 会根据文档与搜索词的相关性得分对结果降序返回。相关性得分与以下 2 个概念有关(稍做了解,后续会出文章做更深入的介绍)
- Term Frequency(TF):term 在文档中出现的频率,得分正相关。出现频率越高,得分越高
- Inverted Document Frequency(IDF):term 在
所有文档中出现的频率,得分负相关。出现频率越高,得分越低。
参考文档
原文地址:https://blog.csdn.net/qq_32880923/article/details/142422157
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!