基于YOLOv8深度学习的水果智能检测系统【python源码+Pyqt5界面+数据集+训练代码】深度学习实战、目标检测、卷积神经网络
《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
基本功能演示
基于YOLOv8深度学习的水果智能检测系统【python源码+Pyqt5界面+数据集+训练代码】深度学习实战、目标检测、卷积神经网络
摘要:
水果种类检测系统是一项关键的技术,它能够在自动化水平高的现代食品供应链中,确保水果分类的准确性和效率。本文基于YOLOv8深度学习框架,通过2269张5种不同的水果相关图片,训练了一个进行水果种类目标检测的模型,可以对'苹果', '香蕉', '猕猴桃', '橙子', '梨'这5种不同的水果进行实时检测。并基于此模型开发了一款带UI界面的水果智能检测系统,更便于进行功能的展示。该系统是基于python与PyQT5开发的,支持图片、视频以及摄像头进行目标检测,并保存检测结果。本文提供了完整的Python代码和使用教程,给感兴趣的小伙伴参考学习,完整的代码资源文件获取方式见文末。
文章目录
前言
水果种类检测系统是一项关键的技术,它能够在自动化水平高的现代食品供应链中,确保水果分类的准确性和效率。采用YOLOv8深度学习框架的水果种类检测系统能够实时识别和区分不同种类的水果,这对于提高分类作业的速度和准确性,减少人工劳动并优化整个物流流程非常重要。
其主要应用场景包括:
自动化采摘:在农业生产中,精确识别和分类成熟水果,增加采摘的效率。
加工与包装:在食品加工厂中自动对水果进行排序和包装,减少人工错误并提高速度。
库存管理:对仓库中水果的种类进行实时监控,优化库存管理和补货流程。
零售识别:帮助零售环节在自助结账系统中自动识别水果种类,提升客户体验。
质量控制:通过检测水果外形和尺寸,评估其质量,确保符合标准。
消费者教育:在教育应用中,帮助消费者学习和识别不同种类的水果。
总结来说,水果种类检测系统通过应用先进的深度学习技术,实现了对水果种类的快速和精确识别,大大提升了产业链上各个环节的工作效率和产品质量。未来随着技术的发展和应用的深入,这一系统有望进一步优化生产流程,改善消费体验,并助力食品供应链的智能化发展。
博主通过搜集实际场景中的不同水果相关数据图片,根据YOLOv8的目标检测技术,基于python与Pyqt5开发了一款界面简洁的水果智能检测系统,可支持图片、视频以及摄像头检测,同时可以将图片或者视频检测结果进行保存。
软件初始界面如下图所示:

检测结果界面如下:

一、软件核心功能介绍及效果演示
软件主要功能
1. 可用于实际场景中5种不同水果的目标检测,分别是'苹果', '香蕉', '猕猴桃', '橙子', '梨';
2. 支持图片、视频及摄像头进行检测,同时支持图片的批量检测;
3. 界面可实时显示目标位置、目标总数、置信度、用时等信息;
4. 支持图片或者视频的检测结果保存;
界面参数设置说明

置信度阈值:也就是目标检测时的conf参数,只有检测出的目标置信度大于该值,结果才会显示;
交并比阈值:也就是目标检测时的iou参数,只有目标检测框的交并比大于该值,结果才会显示;
检测结果说明

显示标签名称与置信度:表示是否在检测图片上标签名称与置信度,显示默认勾选,如果不勾选则不会在检测图片上显示标签名称与置信度;
显示标签名称与置信度结果如下:

不显示标签名称与置信度结果如下:

总目标数:表示画面中检测出的目标数目;
目标选择:可选择单个目标进行位置信息、置信度查看。
目标位置:表示所选择目标的检测框,左上角与右下角的坐标位置。默认显示的是置信度最大的一个目标信息;
主要功能说明
功能视频演示见文章开头,以下是简要的操作描述。
(1)图片检测说明
点击打开图片按钮,选择需要检测的图片,或者点击打开文件夹按钮,选择需要批量检测图片所在的文件夹,操作演示如下:
点击目标下拉框后,可以选定指定目标的结果信息进行显示。
点击保存按钮,会对检测结果进行保存,存储路径为:save_data目录下。
注:1.右侧目标位置默认显示置信度最大一个目标位置,可用下拉框进行目标切换。所有检测结果均在左下方表格中显示。
(2)视频检测说明
点击视频按钮,打开选择需要检测的视频,就会自动显示检测结果,再次点击可以关闭视频。
点击保存按钮,会对视频检测结果进行保存,存储路径为:save_data目录下。
(3)摄像头检测说明
点击打开摄像头按钮,可以打开摄像头,可以实时进行检测,再次点击,可关闭摄像头。
(4)保存图片与视频检测说明
点击保存按钮后,会将当前选择的图片【含批量图片】或者视频的检测结果进行保存,对于图片图片检测还会保存检测结果为csv文件,方便进行查看与后续使用。检测的图片与视频结果会存储在save_data目录下。
【注:暂不支持视频文件的检测结果保存为csv文件格式。】
保存的检测结果文件如下:

图片文件保存的csv文件内容如下,包括图片路径、目标在图片中的编号、目标类别、置信度、目标坐标位置。
注:其中坐标位置是代表检测框的左上角与右下角两个点的x、y坐标。

二、模型的训练、评估与推理
1.YOLOv8的基本原理
YOLOv8是一种前沿的目标检测技术,它基于先前YOLO版本在目标检测任务上的成功,进一步提升了性能和灵活性,在精度和速度方面都具有尖端性能。在之前YOLO 版本的基础上,YOLOv8 引入了新的功能和优化,使其成为广泛应用中各种物体检测任务的理想选择。主要的创新点包括一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,可以在从 CPU 到 GPU 的各种硬件平台上运行。
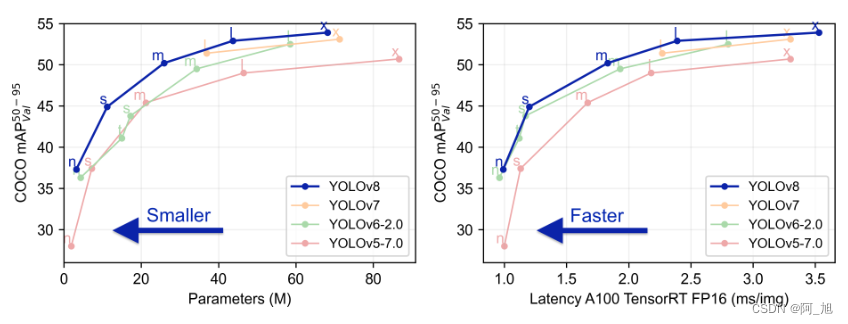
YOLO各版本性能对比:
YOLOv8网络结构如下:

2. 数据集准备与训练
通过网络上搜集关于不同水果的相关图片,并使用Labelimg标注工具对每张图片进行标注。数据集一共包含2269张图片,其中训练集包含1586张图片,验证集包含453张图片、测试集包含230张图片。
部分图像及标注如下图所示:



模型训练
图片数据的存放格式如下,在项目目录中新建datasets目录,同时将检测的图片分为训练集与验证集放入Data目录下。

同时我们需要新建一个data.yaml文件,用于存储训练数据的路径及模型需要进行检测的类别。YOLOv8在进行模型训练时,会读取该文件的信息,用于进行模型的训练与验证。data.yaml的具体内容如下:
train: D:\2MyCVProgram\2DetectProgram\FruitDetection_v8\datasets\data\train
val: D:\2MyCVProgram\2DetectProgram\FruitDetection_v8\datasets\data\valid
test: D:\2MyCVProgram\2DetectProgram\FruitDetection_v8\datasets\data\test
nc: 5
names: ['Apple', 'Banana', 'Kiwi', 'Orange', 'Pear']
注:train与val后面表示需要训练图片的路径,建议直接写自己文件的绝对路径。
数据准备完成后,通过调用train.py文件进行模型训练,epochs参数用于调整训练的轮数,batch参数用于调整训练的批次大小【根据内存大小调整,最小为1】,代码如下:
#coding:utf-8
from ultralytics import YOLO
import matplotlib
matplotlib.use('TkAgg')
# 模型配置文件
model_yaml_path = "ultralytics/cfg/models/v8/yolov8.yaml"
#数据集配置文件
data_yaml_path = 'datasets/Data/data.yaml'
#预训练模型
pre_model_name = 'yolov8n.pt'
if __name__ == '__main__':
#加载预训练模型
model = YOLO(model_yaml_path).load(pre_model_name)
#训练模型
results = model.train(data=data_yaml_path,
epochs=150, # 训练轮数
batch=4, # batch大小
name='train_v8', # 保存结果的文件夹名称
optimizer='SGD') # 优化器
3. 训练结果评估
在深度学习中,我们通常用损失函数下降的曲线来观察模型训练的情况。YOLOv8在训练时主要包含三个方面的损失:定位损失(box_loss)、分类损失(cls_loss)和动态特征损失(dfl_loss),在训练结束后,可以在runs/目录下找到训练过程及结果文件,如下所示:

各损失函数作用说明:
定位损失box_loss:预测框与标定框之间的误差(GIoU),越小定位得越准;
分类损失cls_loss:计算锚框与对应的标定分类是否正确,越小分类得越准;
动态特征损失(dfl_loss):DFLLoss是一种用于回归预测框与目标框之间距离的损失函数。在计算损失时,目标框需要缩放到特征图尺度,即除以相应的stride,并与预测的边界框计算Ciou Loss,同时与预测的anchors中心点到各边的距离计算回归DFLLoss。
本文训练结果如下:

我们通常用PR曲线来体现精确率和召回率的关系,本文训练结果的PR曲线如下。mAP表示Precision和Recall作为两轴作图后围成的面积,m表示平均,@后面的数表示判定iou为正负样本的阈值。mAP@.5:表示阈值大于0.5的平均mAP,可以看到本文模型目标检测的mAP@0.5值为0.989,结果还是十分不错的。

4. 检测结果识别
模型训练完成后,我们可以得到一个最佳的训练结果模型best.pt文件,在runs/train/weights目录下。我们可以使用该文件进行后续的推理检测。
图片检测代码如下:
#coding:utf-8
from ultralytics import YOLO
import cv2
# 所需加载的模型目录
path = 'models/best.pt'
# 需要检测的图片地址
img_path = "TestFiles/fruit21_mp4-15_jpg.rf.c3be143dba8bb171c20a2a767ccb6a91.jpg"
# 加载预训练模型
model = YOLO(path, task='detect')
# 检测图片
results = model(img_path)
print(results)
res = results[0].plot()
# res = cv2.resize(res,dsize=None,fx=0.5,fy=0.5,interpolation=cv2.INTER_LINEAR)
cv2.imshow("YOLOv8 Detection", res)
cv2.waitKey(0)
执行上述代码后,会将执行的结果直接标注在图片上,结果如下:

以上便是关于此款水果智能检测系统的原理与代码介绍。基于此模型,博主用python与Pyqt5开发了一个带界面的软件系统,即文中第二部分的演示内容,能够很好的支持图片、视频及摄像头进行检测,同时支持检测结果的保存。
关于该系统涉及到的完整源码、UI界面代码、数据集、训练代码、测试图片视频等相关文件,均已打包上传,感兴趣的小伙伴可以通过下载链接自行获取。
【获取方式】
本文涉及到的完整全部程序文件:包括python源码、数据集、训练好的结果文件、训练代码、UI源码、测试图片视频等(见下图),获取方式见文末:

注意:该代码基于Python3.9开发,运行界面的主程序为
MainProgram.py,其他测试脚本说明见上图。为确保程序顺利运行,请按照程序运行说明文档txt配置软件运行所需环境。
结束语
以上便是博主开发的基于YOLOv8深度学习的水果智能检测系统的全部内容,由于博主能力有限,难免有疏漏之处,希望小伙伴能批评指正。
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!
觉得不错的小伙伴,感谢点赞、关注加收藏哦!
原文地址:https://blog.csdn.net/qq_42589613/article/details/140512810
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!