吴恩达机器学习笔记:第 7 周-12支持向量机(Support Vector Machines)12.4-12.6
第 7 周 12、 支持向量机(Support Vector Machines)
12.4 核函数 1
回顾我们之前讨论过可以使用高级数的多项式模型来解决无法用直线进行分隔的分类
问题:
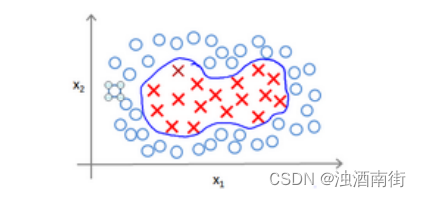
为了获得上图所示的判定边界,我们的模型可能是
θ
0
+
θ
1
x
1
+
θ
2
x
2
+
θ
3
x
1
x
2
+
θ
4
x
1
2
+
θ
5
x
2
2
+
⋯
θ_0 + θ_1x_1 + θ_2x_2 + θ_3x_1x_2 + θ_4x_1^2 +θ_5x_2^2 + ⋯
θ0+θ1x1+θ2x2+θ3x1x2+θ4x12+θ5x22+⋯的形式。
我们可以用一系列的新的特征 f 来替换模型中的每一项。例如令: f 1 = x 1 , f 2 = x 2 , f 3 = x 1 x 2 , f 4 = x 1 2 , f 5 = x 2 2 . . . f_1 = x_1, f_2 = x_2, f_3 =x_1x_2, f_4 = x_1^2, f_5 = x_2^2... f1=x1,f2=x2,f3=x1x2,f4=x12,f5=x22...得到ℎ𝜃(𝑥) = θ 1 f 1 + θ 2 f 2 + . . . + θ n f n θ_1f_1 + θ_2f_2+. . . +θ_nf_n θ1f1+θ2f2+...+θnfn。然而,除了对原有的特征进行组合以外,有没有更好的方法来构造𝑓1, 𝑓2, 𝑓3?我们可以利用核函数来计算出新的特征。
给定一个训练实例 𝑥 ,我们利用 𝑥 的各个特征与我们预先选定的地标(landmarks) l ( 1 ) , l ( 2 ) , l ( 3 ) l^{(1)}, l^{(2)}, l^{(3)} l(1),l(2),l(3)的近似程度来选取新的特征 f 1 , f 2 , f 3 f_1, f_2, f_3 f1,f2,f3。

上例中的𝑠𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦(
x
,
l
(
1
)
x, l^{(1)}
x,l(1))就是核函数,具体而言,这里是一个高斯核函数(Gaussian Kernel)。注:这个函数与正态分布没什么实际上的关系,只是看上去像而已。
这些地标的作用是什么?如果一个训练实例𝑥与地标𝐿之间的距离近似于 0,则新特征 f 近似于
e
−
0
=
1
e^{−0}= 1
e−0=1,如果训练实例𝑥与地标𝐿之间距离较远,则𝑓近似于
e
−
(
一个较大的数
)
e^{−(一个较大的数) }
e−(一个较大的数)= 0。
假设我们的训练实例含有两个特征[
x
1
x
2
x_1 x_2
x1x2],给定地标
l
(
1
)
l^{(1)}
l(1)与不同的𝜎值,见下图:
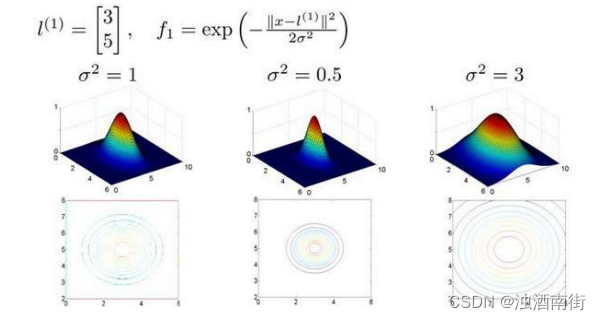
图中水平面的坐标为
x
1
,
x
2
x_1,x_2
x1,x2而垂直坐标轴代表𝑓。可以看出,只有当𝑥与
l
(
1
)
l^{(1)}
l(1)重合时f才具有最大值。随着𝑥的改变𝑓值改变的速率受到
σ
2
σ^2
σ2的控制。
在下图中,当实例处于洋红色的点位置处,因为其离
l
(
1
)
l^{(1)}
l(1)更近,但是离
l
(
2
)
l^{(2)}
l(2)和
l
(
3
)
l^{(3)}
l(3)较远,因此
f
1
f_1
f1接近 1,而
f
2
,
f
3
f_2,f_3
f2,f3接近 0。因此ℎ𝜃(𝑥) = θ_0 + θ_1f_1 + θ_2f_2 +θ_3f_3 > 0,因此预测𝑦 = 1。同理可以求出,对于离l^{(2)}$较近的绿色点,也预测𝑦 = 1,但是对于蓝绿色的点,因为其离三个地标都较远,预测𝑦 = 0。
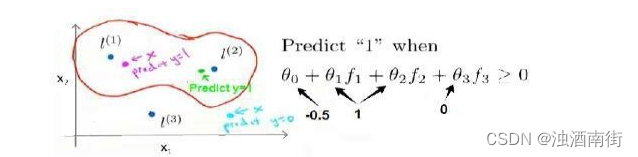
这样,图中红色的封闭曲线所表示的范围,便是我们依据一个单一的训练实例和我们选取的地标所得出的判定边界,在预测时,我们采用的特征不是训练实例本身的特征,而是通过核函数计算出的新特征 f 1 , f 2 , f 3 f_1, f_2, f_3 f1,f2,f3。
原文地址:https://blog.csdn.net/weixin_43597208/article/details/137782816
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!