DRF requets源码分析
【四】requets源码分析
【1】查看request传递的数据
(1)视图层
- 编写传输数据的接口查看request方法的参数
class BookAPIView(APIView):
def get(self, request, *args, **kwargs):
return Response({'body': request.body, 'data': request.data, 'post': request.POST})
def post(self, request, *args, **kwargs):
return Response({'body': request.body, 'data': request.data, 'post': request.POST})
def put(self, request, *args, **kwargs):
return Response({'body': request.body, 'data': request.data, 'post': request.POST})
def delete(self, request, *args, **kwargs):
return Response({'body': request.body, 'data': request.data, 'post': request.POST})
(2)Postman接口测试
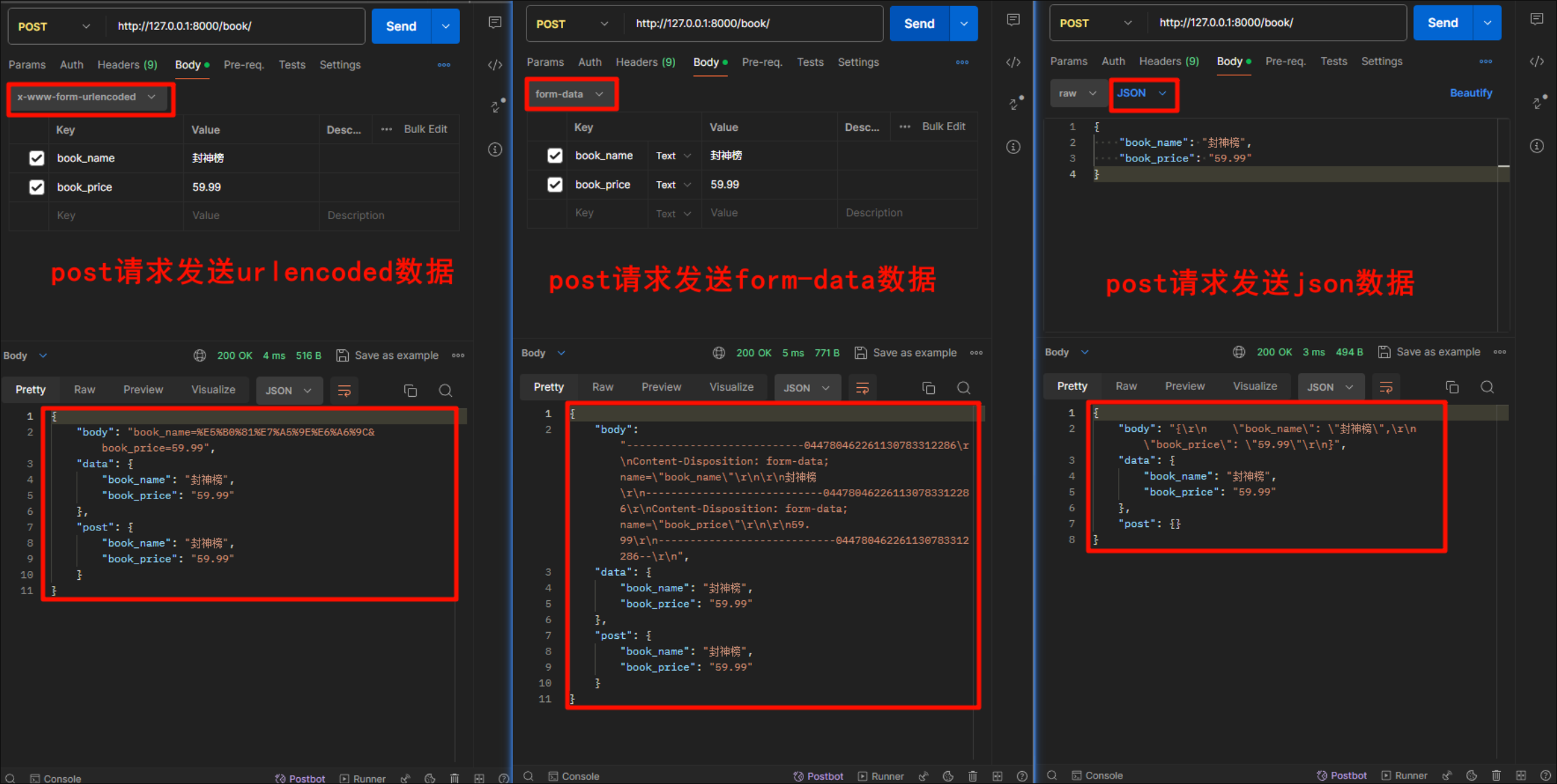
- 首先是POST方法
- 可以看到request的data中,无论传输的什么格式数据,最终都是拿到了一个字典格式
- 可以看到requets的POST中,在发送json格式的数据时是拿不到数据的
- 可以看到request的body中,无论哪种传输格式,都可以拿到数据,但是具体样式都不统一
- 然后查看PUT方法
- 可以看到request的data中,无论传输的什么格式数据,最终都是拿到了一个字典格式
- 可以看到requets的POST中,在发送json格式的数据时是拿不到数据的
- 可以看到request的body中,无论哪种传输格式,都可以拿到数据,但是具体样式都不统一
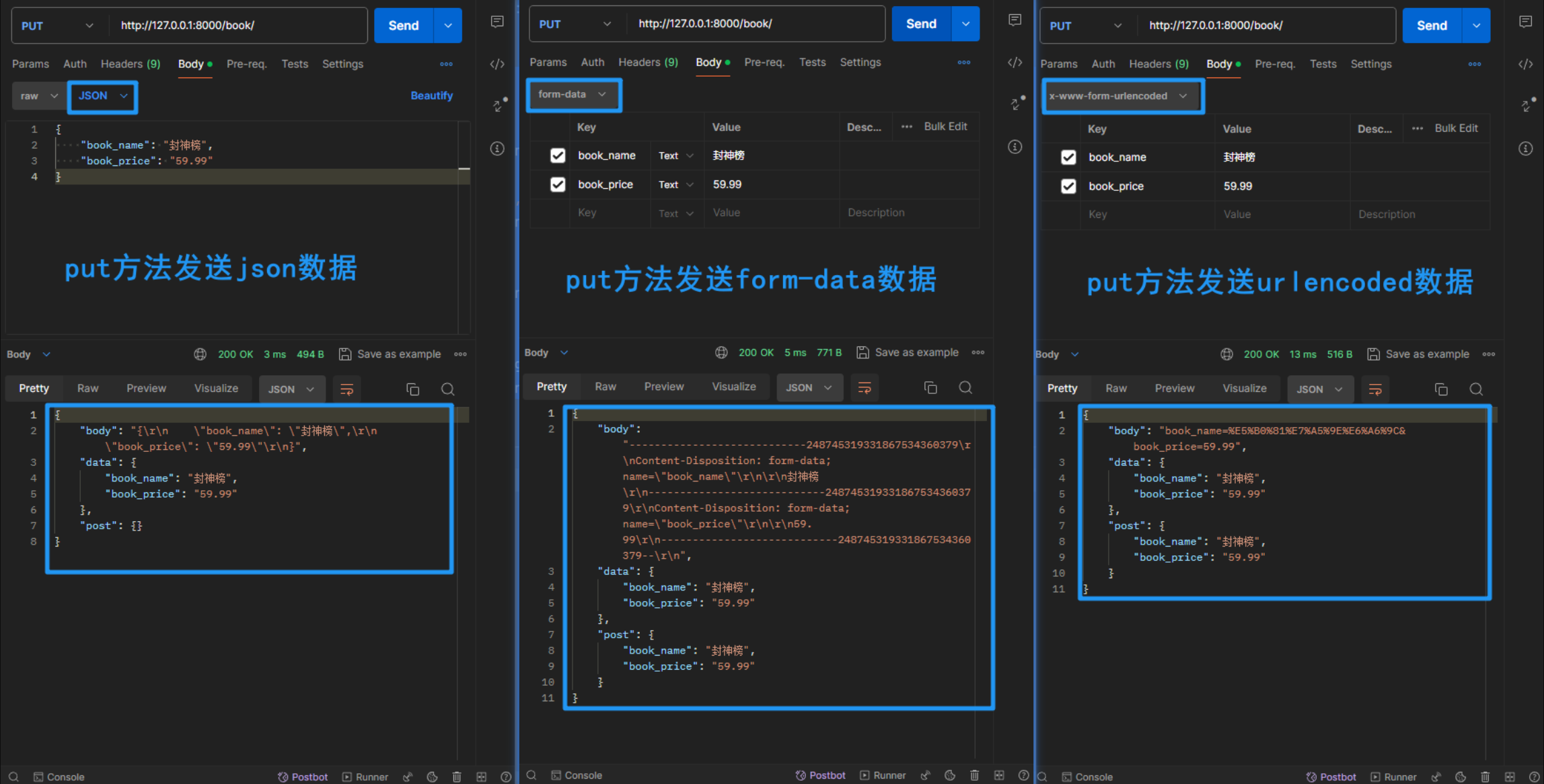
- 小结:
- 无论是什么请求方式,还是什么数据格式,都可以在request的data中拿到传输的数据,并且是字典形式
- 无论是什么请求方式,只要传递的数据编码方式改变了,那么在body中的样式都会不一样
- 在
request.POST中,有时会拿不到传输的数据
【2】编写装饰器
(1)任务要求
-
写一个装饰器,装饰视图函数
FBV -
使得request有data属性,无论哪种编码和请求方式,都是字典
(2)思路和答案
- 因为无论什么传输格式、无论什么传输方法,body中都可以拿到数据,所以以body为主,处理数据
- 首先从request.META中拿取传输格式CONTENT_TYPE
- 然后根据不同的CONTENT_TYPE处理不同的数据
- json格式直接使用json的反序列化即可
- urlencoded格式数据,是&分隔多个参数,是=分隔键值对的,所以对数据进行切分处理
- formdata格式数据,对计算机友好,对开发者极其不友好,输出的样式极其的丑,数据不好切分,所以采用正则处理
def wrapper(func):
def inner(request, *args, **kwargs):
data = None
content_type = request.META.get('CONTENT_TYPE')
if 'json' in content_type:
data = json.loads(request.body)
elif 'urlencoded' in content_type:
data = request.body.decode('utf8')
data = {i[0]: unquote(i[-1]) for i in [info.split('=') for info in data.split('&')]}
elif 'form-data' in content_type:
data = request.body.decode('utf8')
pattern = r'Content-Disposition: form-data; name="([^"]+)"\s*\r\n\s*\r\n(.*?)(?=\r\n|--.*?--|\Z)'
res = re.findall(pattern, string=data)
data = {i[0]: i[1] for i in res}
setattr(request, 'data', data)
res = func(*args, **kwargs)
return res
return inner
【3】面向对象知识准备
(1)魔法方法__getattr__和__getattribute__
-
__getattribute__方法:__getattribute__方法会在尝试访问对象的任何属性时被调用,无论这个属性是否存在。- 如果覆盖了
__getattribute__方法但没有正确地处理所有属性访问,那么即使对于存在的属性也可能导致错误,因为默认的__getattribute__实现会被覆盖。 - 如果
__getattribute__方法引发异常并且没有捕获该异常,那么解释器不会尝试调用__getattr__方法作为后备机制。因此,如果覆盖了__getattribute__方法,需要确保它能正确处理所有可能的属性访问,包括不存在的属性。
-
__getattr__方法:__getattr__方法仅在__getattribute__方法引发AttributeError时被调用,即当尝试访问的属性不存在时。这是__getattr__方法作为后备机制存在的原因。- 如果没有覆盖
__getattribute__方法,那么__getattr__会在属性不存在时自动被调用。但是,如果覆盖了__getattribute__方法而没有显式地处理不存在的属性,那么__getattr__将不会被调用。
-
简而言之:
-
__getattribute__总是被调用,无论属性是否存在。 __getattr__仅在__getattribute__失败(即引发AttributeError)并且没有覆盖__getattribute__方法时被调用,用于处理不存在的属性。
-
class A:
class_name = 'A'
def __getattr__(self, item):
print('执行了getattr')
return super().__getattr__(item)
a = A()
a.class_name # 没有任何输出
a.name # 执行了getattribute 并报错
(2)魔法方法进阶
class DjangoRequest: # django的request
def method(self): # django特有的方法method
print(f'{self}--method')
class DrfRequest(object): # drf的request
def __init__(self, req):
self._request = req # 组合将传入的对象作为一个属性
self.data = dict() # drf_request特有的属性dict
def __getattr__(self, attr): # 重写了魔法方法__getattr__
try:
return getattr(self._request, attr) # 从定义的属性中找这个属性里面的属性
except AttributeError:
return self.__getattribute__(attr) # 触发异常没有这个属性
django_req = DjangoRequest()
drf_req = DrfRequest(django_req)
# 问题一:
print(drf_req.data)
# 问题二:
drf_req._request.method()
# 问题三
drf_req.method()
# 问题四:
drf_req.xxx
- 问题一:
print(drf_req.data)的执行流程- 非常的简单,直接在
drf_req中找到实例属性data,直接输出即可
- 非常的简单,直接在
- 问题二:
drf_req._request.method()的执行流程- 首先找到
drf_req中找到实例属性_request,这个很简单直接找到了 - 由于这个属性是
DjangoRequest()得到的实例django_req,所以可以继续从这个实例中找属性 - 继续找
method这个属性,在django_req实例中,并且这个属性是个方法,所以可以加括号直接执行 - 最终输出
<__main__.DjangoRequest object at 0x00000203E4B67FD0>--method
- 首先找到
- 问题三:
drf_req.method()的执行流程- 首先找到
drf_req中找到实例属性method,这次并没有找到,所以将触发魔法方法__getattr__ - 首先执行
getattr反射方法,从self._request这个实例中找attr属性,即从django_req实例中找method属性 - 能够找到,所以直接执行
method方法
- 首先找到
- 问题四:
drf_req.xxx的执行流程- 首先找到
drf_req中找到实例属性xxx,这次任没有找到,所以将触发魔法方法__getattr__ - 首先执行
getattr反射方法,从self._request这个实例中找attr属性,即从django_req实例中找xxx属性 - 并没有找到这个
xxx属性,且反射方法第三个参数为空,即没有找到的情况下,将会报错AttributeError - 通过异常捕获执行
object的__getattribute__方法,抛出了异常
- 首先找到
【4】request源码重点部分分析
(1)前言:
-
这里不对data进行分析,主要是分析如何保留源来的request方法
-
在前面已经对APIView的源码进行分析过了,所以这里也仅对这request进行分析
(2)重要代码分析
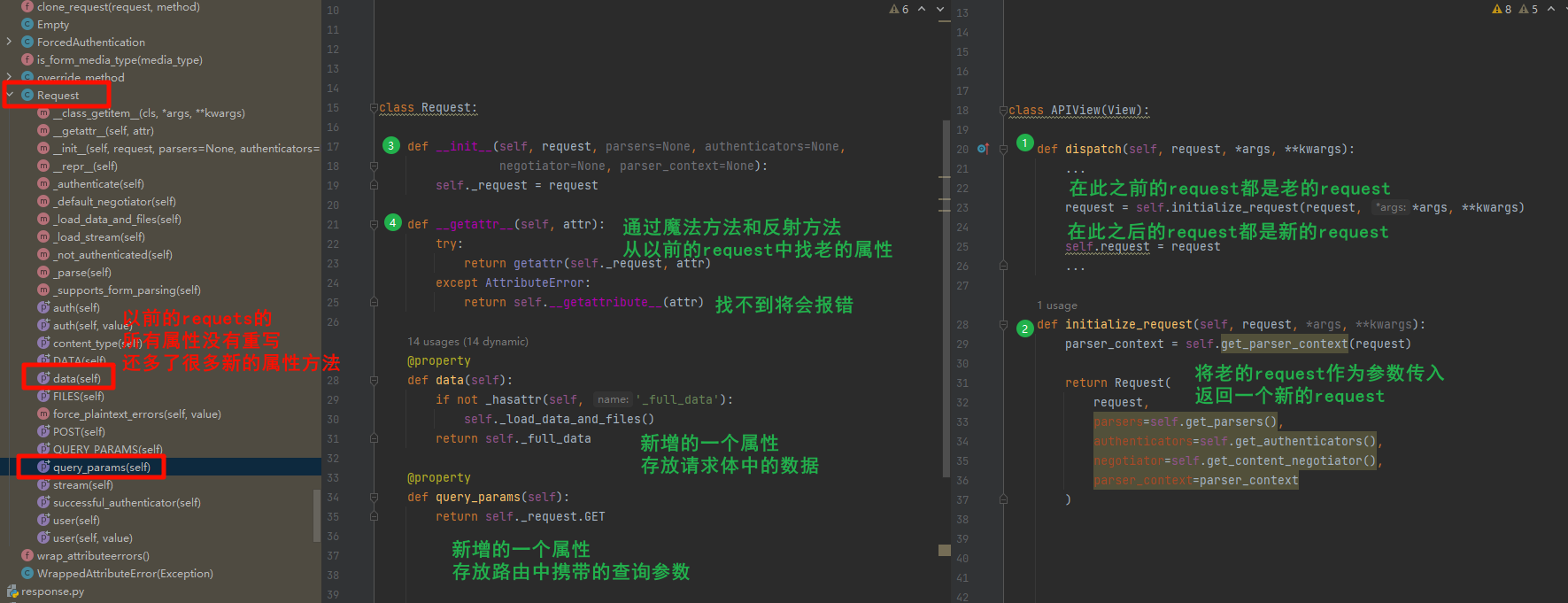
-
现在代码执行到了APIView的dispatch方法
- 在执行
initialize_request之前的request是普通的request - 但是在这步之后的request就是强大的request了,它将完美继承普通request的所有属性方法,还有自己的一套属性方法
- 在执行
-
执行了
initialize_request- 将request作为一个参数传入了Request类中,当然这个里还有其他的参数,但是不是重点,不做过多赘述
-
来到Request中
- 如果看懂了魔法进阶中的内容方法,看这里的话,将毫无压力
- 首先将传入的request参数作为属性,放在了
_request这个属性中 - 然后可以看到
__getattr__魔法方法- 当调用封装以后的
request的时候,首先会在自己的属性中找需要的内容 - 当找不到的时候,就会来到这里先执行反射方法
- 在_request中进行反射,查找这个属性,所以通过包装以后的request方法时,是可以完美继承以前request的所有属性方法的
- 当找不到的时候,又因为反射方法
getattr没有第三个参数,所以将会抛出异常,被捕获以后又执行object的方法进行捕获,最终抛出异常
- 当调用封装以后的
-
还可以看到Request类中
- 是没有老的request的method、POST、get等属性的,所以从新版的request中确实找到的是老版本的属性
- 还可以看到一个伪装成属性的data
- 这个data就是新版,它将所有所有传入的数据,无论是什么格式,无论是什么请求,都将数据放在这个data中,并且是一个普通的字典,方便开发者使用
- 还可以看到一个伪装成属性的query_params
query_params属性通常用于访问请求的查询参数- 在DRF的视图中,可以使用它来提取URL中的查询参数
- 例如
?param1=value1¶m2=value2中的param1和param2。
- 例如
(3)小结
- request之前的所有属性和方法,是被完美继承的,老的东西任然可以使用
- request._request 就是老的request
request.data:将请求体中的数据(无论是什么方法,还是什么格式的数据)都将放在一个字典中request.query_params:将访问请求的查询参数分装在这个属性中,方便提取URL参数,贴合restful规范
【5】补充requets.META
(1)介绍
-
首先通过观察,发现在
Request中是没有这个属性的- 即这个是老版本的request的属性
-
在Django框架中,每个传入的HTTP请求都会由一个
HttpRequest对象表示。 -
这个对象包含了很多关于当前请求的信息,其中
META属性是一个Python字典,包含了所有可用的HTTP头部信息。META字典中的键都是字符串,但它们的值可能是字符串或列表(如果HTTP头部有多个值)。
(2)常用属性
PATH_INFO:一个字符串,表示请求的路径。例如,对于URLhttp://www.example.com/myapp/,PATH_INFO的值将是/myapp/。REMOTE_ADDR:客户端的IP地址。注意,如果使用了代理或负载均衡器,这个值可能不是最终用户的真实IP。HTTP_HOST:请求的Host头部信息,即客户端发送请求时指定的域名和端口(如果有的话)。HTTP_USER_AGENT:用户代理字符串,通常包含了关于客户端浏览器或其他发送请求的软件的信息。HTTP_ACCEPT:客户端能够处理的内容类型列表。HTTP_ACCEPT_LANGUAGE:客户端的首选语言。HTTP_ACCEPT_ENCODING:客户端接受的内容编码。HTTP_REFERER:在之前的web页面中用户点击链接来访问当前页面的地址(如果存在的话)。HTTP_X_FORWARDED_FOR:如果使用了HTTP代理或负载均衡器,这个头部可能包含客户端的原始IP地址。但请注意,这个头部可以被伪造,因此不能完全信任它。CSRF_TOKEN:Django的CSRF保护机制使用的令牌。在表单提交时,这个令牌会被包含在请求中,以验证请求是否来自受信任的来源。
- 请注意,
META字典中的键都是大写,并且以HTTP_开头(除了上面提到的几个特殊键)。 - 这是因为HTTP头部是大小写不敏感的,但在Python字典中键是大小写敏感的。所以,为了保持一致性,Django将所有HTTP头部的键转换为大写,并在前面加上
HTTP_前缀。- 例如,HTTP头部的
Content-Type在META字典中将以HTTP_CONTENT_TYPE的形式出现。
- 例如,HTTP头部的
原文地址:https://blog.csdn.net/weixin_48183870/article/details/137893879
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!