【深度学习】SSD 神经网络:彻底改变目标检测
一、说明
Single Shot MultiBox Detector (SSD) 是一项关键创新,尤其是在物体检测领域。在 SSD 出现之前,对象检测主要通过两阶段过程执行,首先识别感兴趣的区域,然后将这些区域分类为对象类别。这种方法虽然有效,但计算量大且速度慢,限制了其在实时场景中的适用性。SSD 的推出标志着一个重大的飞跃,提供了以前无法实现的速度、准确性和效率的融合。本文深入探讨了 SSD 神经网络的架构、优势、应用和影响,阐明了其在目标检测技术发展中作为基石的作用。
通过SSD的镜头,我们瞥见了人类好奇心的无限视野,每一项创新都不仅仅是一个答案,而是照亮广阔的未知可能性水域的灯塔。它提醒我们,发现的艺术不在于寻找新的风景,而在于拥有新的眼光。
二、架构上的创新
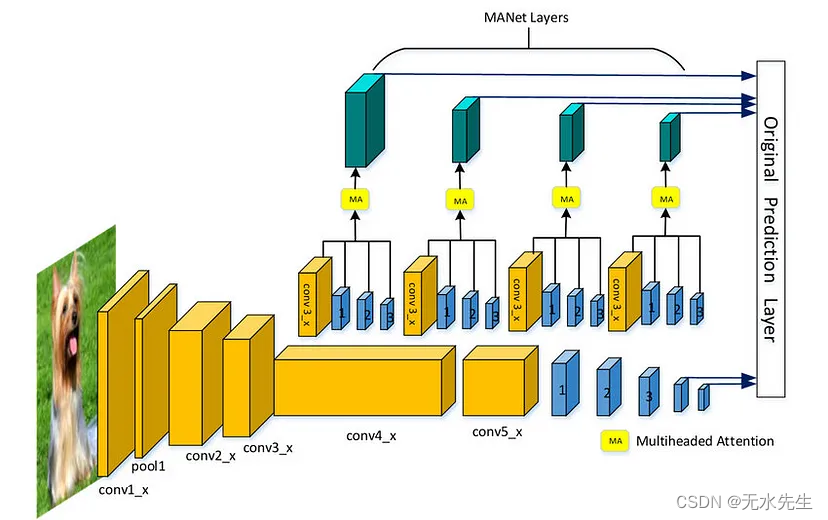
SSD 的架构经过巧妙设计,可在单次拍摄中执行对象检测,这意味着它可以通过网络一次性直接从输入图像中检测不同类别的对象。这是通过多尺度卷积神经网络实现的,该神经网络以各种分辨率处理输入图像,提取不同尺度的特征图。这些特征图中的每一个都负责检测不同大小的物体,使网络能够捕获各种物体尺寸和形状。
SSD 效率的核心是它在每个功能图位置使用默认边界框或锚点。对于这些锚点中的每一个,网络都会预测对象的类别和对锚点尺寸的调整,以更好地拟合检测到的对象。这种双重预测机制使SSD能够同时对物体进行定位和分类,从而大大减轻了计算负担,提高了检测速度。
2.1 与前代产品相比的优势
与传统的两相检测系统相比,SSD的单通道检测方法具有巨大的优势。首先,它的速度无与伦比,允许在视频流中实时检测物体,这是自动驾驶和监控等应用的关键要求。此外,SSD 保持高精度水平,通过其多尺度方法胜任处理各种尺寸的物体。这种速度和准确性的平衡确保了SSD可以部署在不同的场景中,从计算资源有限的嵌入式系统到处理复杂场景的高端GPU。
2.2 应用广泛
SSD 神经网络的多功能性为其在各个领域的采用铺平了道路。在自动驾驶汽车中,SSD 能够快速准确地检测行人、其他车辆和障碍物,这对于安全和导航至关重要。在监控领域,SSD能够实时监控拥挤的场景,有效地识别和跟踪感兴趣的物体。此外,在智能手机和相机等消费电子产品中,SSD 通过启用实时人脸检测和对象跟踪等高级功能来增强用户体验。
2.3 影响和未来方向
SSD 的推出激发了物体检测领域的创新浪潮,为性能和效率树立了新的标杆。它的影响超越了学术研究,影响了工业应用,并塑造了跨部门产品和服务的开发。SSD 的基本原理启发了后续架构,突破了计算机视觉的可能性。
展望未来,随着研究人员寻求进一步提高速度、准确性和处理更复杂检测场景的能力,SSD 及其衍生产品的发展仍在继续。网络设计、培训方法和硬件优化方面的创新有望增强基于 SSD 的系统的功能,确保其在面对不断增长的需求时的相关性和适用性。
三、参考代码
创建完整的 SSD(Single Shot MultiBox Detector)实现以及合成数据集、评估指标和绘图功能是一项全面的任务。下面,我将指导您使用 Python 完成此过程的简化版本,其中包括创建合成数据集、定义基本的 SSD 架构、训练模型、评估模型以及绘制结果。对于功能齐全且经过优化的 SSD 实现,您通常会使用 PyTorch 或 TensorFlow 等深度学习框架,并且需要对大规模数据集进行广泛的调整和训练。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import numpy as np
from PIL import Image, ImageDraw
import torchvision.models as models
# Dataset Definition
class SyntheticShapes(Dataset):
def __init__(self, num_samples=1000, image_size=(300, 300)):
self.num_samples = num_samples
self.image_size = image_size
self.shapes = ['circle', 'square']
def __len__(self):
return self.num_samples
def __getitem__(self, idx):
img = Image.new('RGB', self.image_size, 'white')
draw = ImageDraw.Draw(img)
shape_choice = np.random.choice(self.shapes)
margin = 50
x1, y1 = np.random.randint(margin, self.image_size[0]-margin), np.random.randint(margin, self.image_size[1]-margin)
x2, y2 = x1 + np.random.randint(margin, margin*2), y1 + np.random.randint(margin, margin*2)
if shape_choice == 'circle':
draw.ellipse([x1, y1, x2, y2], outline='black', fill='red')
label = 0
else:
draw.rectangle([x1, y1, x2, y2], outline='black', fill='blue')
label = 1
img = np.array(img) / 255.0
img = np.transpose(img, (2, 0, 1))
return torch.FloatTensor(img), torch.tensor(label, dtype=torch.long), torch.FloatTensor([x1, y1, x2, y2])
# Simplified SSD Model Definition
class SimplifiedSSD(nn.Module):
def __init__(self, num_classes=2):
super(SimplifiedSSD, self).__init__()
self.feature_extractor = models.vgg16(pretrained=True).features[:-1] # Removing the last maxpool layer
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512*7*7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
self.regressor = nn.Sequential(
nn.Linear(512*7*7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4), # 4 for bounding box [x1, y1, x2, y2]
)
def forward(self, x):
x = self.feature_extractor(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
class_preds = self.classifier(x)
bbox_preds = self.regressor(x)
return class_preds, bbox_preds
# Initialize Dataset, DataLoader, and Model
dataset = SyntheticShapes()
dataloader = DataLoader(dataset, batch_size=4, shuffle=True)
model = SimplifiedSSD()
# Training Setup
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
classification_criterion = nn.CrossEntropyLoss()
bbox_criterion = nn.SmoothL1Loss()
# Training Loop
num_epochs = 10
for epoch in range(num_epochs):
running_loss = 0.0
for inputs, class_labels, bbox_labels in dataloader:
optimizer.zero_grad()
class_preds, bbox_preds = model(inputs)
classification_loss = classification_criterion(class_preds, class_labels)
bbox_loss = bbox_criterion(bbox_preds, bbox_labels)
loss = classification_loss + bbox_loss
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch+1}, Loss: {running_loss / len(dataloader)}')

此代码为基于 SSD 的对象检测系统奠定了基础。对于实际应用,您需要更复杂的架构、全面的数据集和详细的评估指标。SSD 实现可用于流行的深度学习框架,其中包括多尺度检测、非最大值抑制等高级功能,以及可针对特定任务进行微调的广泛预训练模型。
四、结论
总之,SSD神经网络代表了目标检测领域的一个重要里程碑,提供了速度、准确性和计算效率的复杂组合。它的开发不仅解决了关键挑战,还扩大了计算机视觉领域可实现的视野。随着技术的进步,SSD的遗产无疑将继续影响未来几代物体检测系统,巩固其作为基础技术的地位,以寻求更智能、更灵敏的计算机视觉解决方案。
原文地址:https://blog.csdn.net/gongdiwudu/article/details/136245600
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!