构建基于 DCGM-Exporter, Node exporter,PROMETHEUS 和 GRAFANA 构建算力监控系统
目录
引言
本文的是适用对象,是希望通过完全基于Docker ,实现对于一个较小的算力群,比如大学课题组的多台服务器,实现CPU和GPU的资源使用监控。
工具作用
概述
目前的大多数教程都倾向于详细讲解DCGM,Node exporter,PROMETHEUS 和 GRAFANA 的概念,设计和作用,使得这一系统的部署问题变得非常复杂。本文倾向于直接部署直接应用,所以不死磕原理,而直接概述其作用,能够基本认识到它们的作用,然后实现部署。
DCGM-Exporter
- GitHub: https://github.com/NVIDIA/dcgm-exporter
- 作用:DCGM-Exporter 主要用于收集主机或者节点上的GPU的数据,并且通过端口暴露数据。
Node exporter
- GitHub: https://github.com/prometheus/node_exporter
- 作用:Node exporter 主要用于收集主机或者节点上的CPU,内存,磁盘等硬件信息,并且通过端口暴露数据。
PROMETHEUS
- GitHub: https://github.com/prometheus/prometheus
- 作用:Prometheus 主要是作为数据库存储各个主机和节点所暴露出的数据。
GRAFANA
-GitHub: https://github.com/grafana/grafana
- 作用:grafana 则是通过面板将监控数据进行可视化或者其他操作。
小结
Node exporter 和 DCGM-Exporter 分别用于收集主机或者节点上的数据;而 PROMETHEUS 则负责存储这些数据;GRAFANA 最后将这些监控数据可视化呈现。
部署
单容器
我们可以通过docker命令在主机或者节点上部署容器实现对应的服务
DCGM-Exporter
对于DCGM-Exporter,参考 https://github.com/NVIDIA/dcgm-exporter,我们可以参考它的官方文档的命令予以部署
docker run -d --gpus all --rm -p 9400:9400 nvcr.io/nvidia/k8s/dcgm-exporter:3.3.8-3.6.0-ubuntu22.04
但是其实这个命令可以优化一下,加入自动重启的参数,因为对应的机器偶尔难免需要重启,每次人为的重启容器非常麻烦。同时也需要对应的配置Docker 重启,改进后的命令如下:
docker run -d --restart=always --gpus all -p 9400:9400 nvcr.io/nvidia/k8s/dcgm-exporter:3.3.6-3.4.2-ubuntu22.04
这样一来,DCGM-Exporter 的数据将通过主机的 9400端口暴露。
Node exporter
对于Node exporter,参考https://github.com/prometheus/node_exporter,文档所推荐的命令为
docker run -d \
--net="host" \
--pid="host" \
-v "/:/host:ro,rslave" \
quay.io/prometheus/node-exporter:latest \
--path.rootfs=/host
同样可以加入自动重启的参数,改进后的命令为
docker run -d --restart=always\
--net="host" \
--pid="host" \
-v "/:/host:ro,rslave" \
quay.io/prometheus/node-exporter:latest \
--path.rootfs=/host
这样一来,Node exporter 的数据将通过主机的 9100端口暴露。
PROMETHEUS
前面已经提到,DCGM-Exporter 和 Node exporter 暴露数据以后,我们需要 PROMETHEUS 将数据保存起来,所以我们需要通过配置文件告诉 PROMETHEUS 暴露数据的exporter 在哪里,
所以我们需要编写配置文件,以Node exporter 为例,我们可以编写 ·prometheus_cpu.yml· 的配置文件:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "NAME YOU LIKE"
static_configs:
- targets: ['1.1.1.1:9100']
labels:
instance: 'name1'
- targets: ['2.2.2.2:9100']
labels:
instance: 'name2'
- targets: ['3.3.3.3:9100']
labels:
instance: 'name3'
- targets: ['4.4.4.4:9100']
labels:
instance: 'name4'
因为 prometheus 是一个数据库容器,所以我们需要对它做数据持久化,把它的数据挂载在本地,所以我们可以运行如下命令进行部署
sudo docker run -d \
--restart=always \
--net="host" \
--pid="host" \
-v "/home/xxx/node_export_data:/host:ro,rslave" \
-v "./prometheus_cpu.yml:/etc/prometheus/prometheus.yml" \
-p 9090:9090
quay.io/prometheus/node-exporter:latest \
--path.rootfs=/host
对于 DCGM-Exporter 所对应的GPU的数据同理操作即可。
于是我们可以通过我们所配置的9090端口访问prometheus。
GRAFANA
在数据成功由 prometheus 保存以后,接下来我们需要使用面板将其可视化
此时可以部署GRAFANA 实现,按照官方文档的描述,可以通过运行
docker run -d -p 3000:3000 --name=grafana grafana/grafana-enterprise
来运行 GRAFANA ,然后访问对应的3000即可。
需要注意的是,对于不同的node exporter 需要使用不同的dashboard
- Node exporter:Node Exporter Full
- DCGM-Exporter: NVIDIA DCGM Exporter Dashboard
Node exporter

图源:https://grafana.com/api/dashboards/1860/images/7994/image
DCGM-Exporter
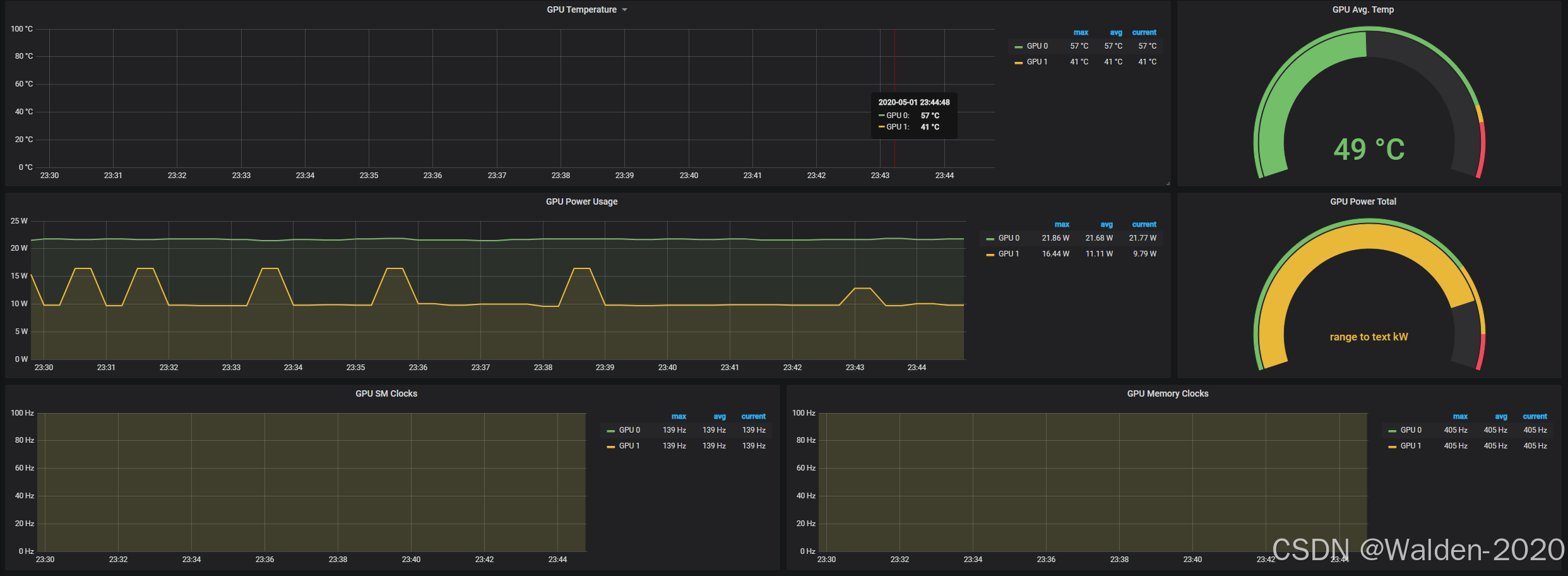
图源:https://grafana.com/api/dashboards/12239/images/8088/image
然后我们通过登录 GRAFANA ,配置prometheus数据源,选择不同的dashboard,即可实现监控数据的可视化;
多容器
事实上,当我们面对一个计算机集群部署时候,我们不太可能逐容器部署,我们往往会在需要监控的机器上部署DCGM-Exporter和Node exporter,而选择一台机器作为Server,来同时承担 PROMETHEUS 和 GRAFANA 的角色,并且这台机器本身可能也要部署 DCGM-Exporter和Node exporter,于是,我们需要使用Docker compose 实现多容器同时部署;
Node exporter
对于本机的 Node exporter,我们依然是单独部署,然后在配置prometheus时,使用主机IP地址
- targets: ['1.2.3.6:9100']
labels:
instance: 'localhost'
DCGM-Exporter
对于本机的DCGM-Exporter,则可以通过Docker compose 一次性部署;
假如我们在docker compose 里为 DCGM-Exporter 取的名字是gpu_exporter
则在编写prometheus_gpu.yml时,我们可以直接配置
- targets: ['gpu_exporter:9400']
labels:
instance: 'localhost'
Docker Compose
加入我们已经提前写好了 prometheus_cpu.yml 和 prometheus_gpu.yml
那么我们可以同时在一台机器上部署 DCGM-Exporter, PROMETHEUS 和 GRAFANA,docker-compose.yml的内容如下:
version: '3.8'
services:
prometheus_cpu:
image: prom/prometheus:latest
container_name: prometheus_cpu
user: root
volumes:
- /path/prometheus_cpu.yml:/etc/prometheus/prometheus.yml
- /path/prometheus_cpu_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus/'
- '--storage.tsdb.retention.time=45d'
ports:
- "9200:9090"
networks:
- monitoring
prometheus_gpu:
image: prom/prometheus:latest
container_name: prometheus_gpu
user: root
volumes:
- /path/prometheus_gpu.yml:/etc/prometheus/prometheus.yml
- /path/prometheus_gpu_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus/'
- '--storage.tsdb.retention.time=45d'
ports:
- "9800:9090"
networks:
- monitoring
depends_on:
- gpu_exporter
gpu_exporter:
image: nvidia/dcgm-exporter:3.3.6-3.4.2-ubuntu22.04
container_name: gpu_exporter
runtime: nvidia
environment:
- NVIDIA_VISIBLE_DEVICES=all
ports:
- "9400:9400"
networks:
- monitoring
deploy:
resources:
reservations:
devices:
- capabilities: [gpu]
networks:
monitoring:
driver: bridge
理论上来说,可以同时部署上 GRAFANA,但是因为我们在部署的时候并没有成功,后面把 GRAFANA 部署到另外一台机器上得以实现;
但是此处想重点表达的是 prometheus_cpu 和 prometheus_gpu 和 gpu_exporter 是可以实现一次性部署的。
此处可以给出一个由GitHub Copilot 协助完成的完整的docker-compose.yml 以供参考
version: '3.8'
services:
prometheus_cpu:
image: prom/prometheus:latest
container_name: prometheus_cpu
user: root
volumes:
- /path/prometheus_cpu.yml:/etc/prometheus/prometheus.yml
- /path/prometheus_cpu_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus/'
- '--storage.tsdb.retention.time=45d'
ports:
- "9200:9090"
networks:
- monitoring
prometheus_gpu:
image: prom/prometheus:latest
container_name: prometheus_gpu
user: root
volumes:
- /path/prometheus_gpu.yml:/etc/prometheus/prometheus.yml
- /path/prometheus_gpu_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus/'
- '--storage.tsdb.retention.time=45d'
ports:
- "9800:9090"
networks:
- monitoring
depends_on:
- gpu_exporter
gpu_exporter:
image: nvidia/dcgm-exporter:3.3.6-3.4.2-ubuntu22.04
container_name: gpu_exporter
runtime: nvidia
environment:
- NVIDIA_VISIBLE_DEVICES=all
ports:
- "9400:9400"
networks:
- monitoring
deploy:
resources:
reservations:
devices:
- capabilities: [gpu]
grafana:
image: grafana/grafana:latest
container_name: grafana
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin
volumes:
- grafana_data:/var/lib/grafana
networks:
- monitoring
depends_on:
- prometheus_cpu
- prometheus_gpu
networks:
monitoring:
driver: bridge
volumes:
grafana_data:
在编写完 docker-compose.yml 文件以后,在对应的文件下,执行命令:
docker-compose up
即可运行服务,至此,可完成对一个小的计算机群的算力资源的监控。
参考
原文地址:https://blog.csdn.net/weixin_43408232/article/details/143493895
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!