【Redis】主从复制分析-基础
1 主从节点运行数据的存储
在主从复制中, 对于主节点, 从节点就是自身的一个客户端, 所以和普通的客户端一样, 会被组织为一个 client 的结构体。
typedef struct client {
// 省略
} client;
同时无论是从节点, 还是主节点, 在运行中的数据都存放在一个 redisServer 的结构体中, 定义如下:
struct redisServer {
// 省略
};
在主从复制中的 client 和 redisServer 都是用来存储运行中的一些数据。
具体里面存储的数据是什么, 在后面的源码分析中, 逐渐了解。
2 主从节点复制中的状态枚举
2.1 从节点自身状态的状态枚举
整个主从复制是一个复杂的过程, 所以在从节点中, 维护了一套状态, 通过状态来判断下一步的流程 (有点像状态模式)
// 没有开启主从复制功能, 默认的状态
#define REPL_STATE_NONE 0
// 开启了主从复制, 但是还没连接上主节点
// 执行了 slaveof/replicaof 命令时, 从节点的切换成的状态
#define REPL_STATE_CONNECT 1
// 正在连接主节点, 从节点开始连接主节点
#define REPL_STATE_CONNECTING 2
/* --- 握手阶段的状态开始, 整个握手过程必须按照下面的顺序进行 --- */
// 从节点发送了 ping, 等待主节点 pong 应答 (正常情况, 主节点会回复一个 pong)
#define REPL_STATE_RECEIVE_PONG 3
// 准备发送认证密码给主节点
#define REPL_STATE_SEND_AUTH 4
// 等待主节点响应认证结果应答
#define REPL_STATE_RECEIVE_AUTH 5
// 准备发送从节点的监听的端口
#define REPL_STATE_SEND_PORT 6
// 等待主节点响应收到从节点端口
#define REPL_STATE_RECEIVE_PORT 7
// 发送主从复制配置的监听的 IP 地址
#define REPL_STATE_SEND_IP 8
// 等待主节点响应收到从节点的 IP 地址
#define REPL_STATE_RECEIVE_IP 9
// 准备发送从节点支持的同步能力
#define REPL_STATE_SEND_CAPA 10
// 等待主节点响应收到支持的同步能力的应答
#define REPL_STATE_RECEIVE_CAPA 11
// 向主节点发送 psync 命令, 请求同步复制
#define REPL_STATE_SEND_PSYNC 12
// 等待 psync 应答
#define REPL_STATE_RECEIVE_PSYNC 13
/* --- 握手阶段的状态结束 --- */
// 正在接收从主节点发送过来的 RDB 文件
#define REPL_STATE_TRANSFER 14
// 已经连接状态
#define REPL_STATE_CONNECTED 15
2.2 主节点保存从节点的状态枚举
对于主节点而言, 需要知道从节点当前的状态的, 好进行对应的操作, 但是不需要那么详细, 主节点也维护了一套从节点运行时的状态
// 等待 bgsave (生成 RDB 文件的函数) 的开始
#define SLAVE_STATE_WAIT_BGSAVE_START 6
// 等待 bgsave 的结束, 也就是 RDB 文件的创建结束
#define SLAVE_STATE_WAIT_BGSAVE_END 7
// 发送一个 RDB 文件到从节点
#define SLAVE_STATE_SEND_BULK 8
// 从节点在线
#define SLAVE_STATE_ONLINE 9
3 从节点复制能力
3.1 全量复制和部分复制
整个主从复制, 大体可以概括为 3 种情况
- 一开始, 主从节点建立连接, 这时候主节点需要将自身所有的数据全部同步给从节点
- 运行中, 主节点需要将自己处理的命令, 发送一份给从节点, 这样才能保证主从的一致
- 运行中, 出现了网络波动, 服务重启等情况, 重新恢复正常时, 主从需要重新通过复制, 让彼此的数据重新保持一致
第一步
主从建立了连接, 主节点会将自身所有的数据生成为一个 RDB 的文件, 然后以 EOF 的流格式发送给从节点。
当然, Redis 在 2.8.18 版本开始支持无盘复制, 子进程直接将 RDB 通过网络发送给从服务器, 不使用磁盘作为中间存储。
主要是防止比较低速的磁盘, 写入缓慢, 影响到整个应用。
这个主节点将所有数据发送给从节点的操作, 叫做全量复制。
第二步
在运行中, 主节点处理完了命令, 会遍历自身维护的所有的从节点, 将自身执行的命令发送给所有状态符合的从节点, 保证数据的一致。
可以看出来, 第一, 二步的操作是一个比较简单的过程, 而第三步, 在兼容性能的情况下, 将会是一个复杂的过程。
第三步
主从节点之间出现网络波动, 从节点重启等行为后, 主从之间就可能出现数据不一致。
在 Reids 2.8 版本之前, Reids 的操作就是通过在来一次全量复制, 保证了主从节点数据的一致性。
全量复制 我们可以很容易就想到这是一个耗时, 耗资源的过程, 比如 fork 子进程, RDB 文件生成, 数据发送。
所以为了尽量避免全量复制的出现, 在 Redis 2.8 版本, 引入了一个复制积压缓冲区的缓存区, 主节点执行的命令, 会先保存一份到这个缓存区
(这个缓存区是一个环形的数组, 从头写到尾, 写满了, 重新回到头, 继续写, 新的数据覆盖掉旧的, 同时所有的从节点共用一个缓冲区)。
大体的实现如下
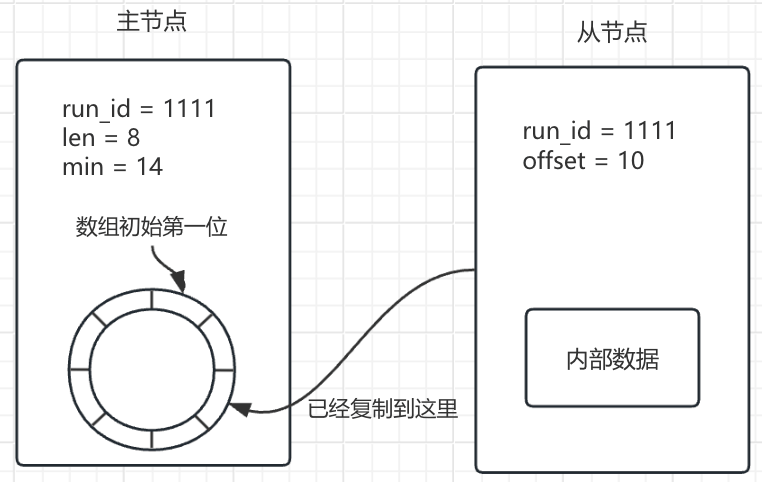
- 主节点启动的时候, 会生成一个 run_id (用来确保复制的主节点的唯一性)
- 同时生成一个复制积压缓冲区, 并且有一个变量, 记录着缓冲区中当前最旧的数据的位置, 假设为 min, 假设复制积压缓冲区的容量为 len
- 从节点保存着主节点生成的 run_id, 同时维持着一个变量, 当前自身最新的数据在复制积压缓冲区的哪个位置, 也就是复制偏移量, 假设为 offset
- 当前主从复制出现问题时, 主从重新建立连接后, 从节点会将 run_id 和 offset 发送给主节点
- 主节点收到后, 如果 run_id 和自身的一致, 同时 min <= offset <= min + len, 也就是需要开始复制的位置的数据, 可以在缓存区中找到, 那么从这个位置进行部分复制
- 主节点如果收到的 run_id 不一致, 或者 offset < min 或者 offset > min + len, 也就是需要开始复制的位置不在缓冲区中, 直接进行全量复制
这个的功能叫做 psync, 可以理解为 部分复制, 这个功能可以减少全量复制的发生。
但是这个功能有些问题, 就是从节点需要维护好 run_id, run_id 需要和从节点的一致, 同时 offset 需要在复制积压缓存中, 这其中
- slave 维护性重启, run_id 和 offset 会丢失
- 主节点故障转移, run_id 会改变
都会导致从节点直接全量复制
所以在 Redis 4.0 针对上面的 2 种情况进行了优化, 使其在上面说的情况下, 可以进行使用部分复制, 这个升级的功能也被叫做 psync2。
涉及的几个名词
- replid1, 每个 Redis 实例启动就会自动产生的一个 id, 这个实例变成从节点, 会被替换为主节点的 replid1
- replid2, 默认初始为 0, 用于存储上次主节点的 replid1
当然还要其他的情况, 会导致部分复制的失效
- 直接重启主节点, 这是复制积压缓冲区的数据丢了, 没法部分复制
所以 psync2 只是针对上面的 2 种情况进行了优化, 其他的情况, 还是会直接进入到全量复制
3.2 从节点重启的部分复制
在 Redis 4.0 中
- Redis 关闭时, 会把复制相关的信息 replid1 和 offset 作为辅助信息保存到 RDB 文件
- Redis 重启时, 会将从 RDB 文件中重新加载对应的复制信息到对应的字段
- 在进行同步时, 将 replid 和 offset 发送给主节点, 尝试进行部分复制
3.3 主节点故障转移的部分复制
当前的场景主要是在 Redis Cluster 中的故障转移情景的分析, 在直接使用主从复制中, 主节点重启, 挂了等, 都无法避免全量复制。
在 Redis 4.0 中
- 使用了 2 组 replid 和 offset
- 从节点也会开启复制积压缓冲区功能, 以便从节点故障切换变化为主节点后, 其他落后的从节点可以进行同步
- 第一组 replid 和 offset, 如果是主节点, 表示的是自己的 replid 和复制偏移量 offset, 从节点表示的是主节点的 replid (确保级联时, replid 都是一致的) 和自身同步主节点的赋值偏移量
- 第二组 replid 和 offset, 无论是主从, 都表示自己的上次主节点的 replid 和 offset, 没有则默认为 0 和 -1
- 主节点发生了故障切换时, 会将自身的第一组 replid 和 offset 复制给第二组 replid 和 offset
- 这时候, 无论是一主一次还是一主多从, 都会有一个自身的从节点变为主节点, 自身变为从节点, 后面故障恢复了, 可以根据自身的第二组 replid 和 offset 进行恢复
- 当然不只是主从关系, 级联复制, 也适用
上面说的 3 个版本的复制能力, 在代码中分别叫做 EOF, psync1, psync2。
复制能力的定义如下:
// 什么能力都不支持
#define SLAVE_CAPA_NONE 0
// 支持 EOF, 支持全量复制, 可以解析 RDB EOF 流式处理格式
#define SLAVE_CAPA_EOF (1<<0)
// 支持 psync2, 支持部分复制
#define SLAVE_CAPA_PSYNC2 (1<<1)
对于 Redis 从节点, 可能因为版本问题, 存在着复制能力不一致的情况, 所以在主从复制开始的阶段, 从节点需要将自身支持的复制能力发送给主节点,
主节点才能以正确的方式同步数据给从节点。
4 参考
原文地址:https://blog.csdn.net/LCN29/article/details/140615618
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!