YOLOv8模型调参---数据增强
目录
2.2.1离线增强(Offline Augmentation)
2.2.2 在线增强(Online Augmentation)
1.数据预处理
当数据顺利导入数据后,我们就可以依据图像的具体情况对图像进行预处理了。与机器学习中较为固定的预处理流程不同,图像的预处理基本完全与数据本身有关。从数据采集的瞬间开始,我们就需要考虑预处理的事项。如果我们的数据是自行从网络爬取或搜索引擎采集,我们可能需要对图像进行去重、删除无效样本等操作,如果数据是自行拍摄、实验提取,那可能也需要根据实验要求进行一些删除、增加的处理。当我们将所有有效数据导入后,至少需要确保:
1)全部样本的尺寸是一致的(同时,全部样本的通道数是一致的)
2)图像最终以Tensor形式被输入卷积网络
3)图像被恰当地归一化
其中,前两项是为了卷积神经网络能够顺利地运行起来,第三项是为了让训练过程变得更加流畅快速。在PyTorch中,所有的数据预处理都可以在导入数据的时候,通过transform参数来完成,我们通常在transform参数中填写torchvision.transforms这个模块下的类。在预处理时,我们需要使用的常规类如下所示:
Compose transforms专用的,类似于nn.Sequential的打包功能,可以将数个transforms下的类 打包,形成类似于管道的结构来统一执行。
CenterCrop 中心裁剪。需要输入最终希望得到的图像尺寸。
Resize 尺寸调整。需要输入最终希望得到的图像尺寸。注意区别于使用裁剪缩小尺寸或使 用填充放大尺寸。
Normalize 归一化(Tensor Only)。对每张图像的每个通道进行归一化,每个通道上的每个像素
会减去该通道像素值的均值,并除以该通道像素值的方差。
ToTensor (PIL Only)将任意图像转变为Tensor
无论使用怎样的卷积网络,我们都倾向于将图像调整到接近28x28或224x224的尺寸。当原图尺寸与目 标尺寸较为接近时,我们可以使用“裁剪”功能。裁剪是会按照我们输入的目标尺寸,将大于目标尺寸的 像素点丢弃的功能,因此使用裁剪必然会导致信息损失,过多的信息损失会导致卷积网络的结果变差。 当需要检测或识别的对象位于图像的中心时,可以使用中心裁剪。中心裁剪会以图像中心点为参照,按照输入的尺寸从外向内进行裁剪,被裁剪掉的像素会被直接丢弃。如果输入的尺寸大于原始图像尺寸, 则在原始图像外侧填充0,再进行中心裁剪。
当图像的尺寸与目标尺寸相差较大,我们不能接受如此多的信息被丢弃的时候,就需要使用尺寸调整的类Resize。Resize是使用像素聚类、像素插补等一定程度上对信息进行提取或选择、并按要求的尺寸重排像素点的功能。一般来说,Resize过后的图片会呈现出与原图较为相似的信息,但图片尺寸会得到缩放。如果原始图像尺寸很大,目标尺寸很小,我们一般会优先使用Resize将图像尺寸缩小到接近目标尺寸的程度,再用裁剪让图片尺寸完全等于目标尺寸。例如,对于600*800的图像,先Resize将尺寸降到 256x256,再裁剪至224x224。
2.数据增强
2.1 数据增强的作用
在目标检测模型的训练过程中,进行数据增强是非常关键的一个步骤,其主要作用体现在以下几个方面:
增加训练数据的多样性:
数据增强通过应用一系列随机变换(如翻转、裁剪、旋转、缩放、颜色调整、平移等)到原始训练图像上,生成大量具有不同视点、尺寸、光照条件和背景的新样本。这些变换模拟了现实世界中物体可能出现的各种形态和环境变化,使得模型在训练阶段就能接触到更多样化的场景,从而提高了模型对不同情况的适应性。
提高模型的泛化能力:
增加训练数据的多样性有助于防止模型过度拟合训练集,即避免模型对训练数据中的特定细节或噪声过于敏感,而忽视了更普遍、更本质的特征。通过数据增强,模型被迫学习更为通用的特征表示,使其在面对未见过的测试数据时,仍能准确地检测出目标物体,进而提高整体的泛化性能。
增强模型的鲁棒性:
数据增强引入的噪声和变化有助于模型在训练中应对各种潜在干扰因素。例如,添加轻微的模糊、亮度变化或色彩失真,可以使模型在实际应用中对图像质量的变化、光照条件的波动以及相机成像偏差等具有更强的抵抗能力。这样,即使在复杂或非理想的环境下,模型也能稳定地进行目标检测。
缓解样本不均衡问题:
在许多目标检测任务中,不同类别或不同大小的目标样本可能存在数量上的显著差异,导致训练过程中的类别不平衡问题。数据增强可以通过复制、合成或优先增强少数类样本的方法,帮助平衡各类别的数据分布,确保模型对所有目标类别都能给予适当的重视,提高整体检测性能,特别是对稀有类别或小目标的检测准确性。
优化模型对尺度变化的适应性:
特别是在目标检测任务中,物体的实际大小和距离摄像头的距离会导致目标在图像中呈现出不同的尺度。数据增强通过应用多尺度训练策略(如随机缩放、多尺度输入、多分辨率训练等),使模型能够更好地理解和处理不同尺度下的目标,提升对不同大小目标的检测效果。
减少对大量标注数据的依赖:
在实际应用中,获取大规模、高质量标注的目标检测数据集成本高昂且耗时。数据增强通过有效利用现有数据生成新的训练样本,能够在一定程度上弥补数据量不足的问题,使得有限的数据资源得以充分利用,降低对大规模标注数据集的硬性需求。
2.2 数据增强方式与适用场景
常见的数据增强方式主要有两种:在线增强(Online Augmentation)和离线增强(Offline Augmentation)。
以下是这两种方式的定义、增强方式以及适用场景的详细解释:
2.2.1离线增强(Offline Augmentation)
定义:
离线增强是指在模型训练前在计算机上一次性完成所有数据增强操作,将原始数据集转化为包含多种增强版本的扩充数据集,并将增强后的样本保存到磁盘或内存中,然后使用这个固定的扩充数据集进行训练。
适用场景:
离线增强适用于以下场景:
计算资源受限:离线增强只需在训练前进行一次计算,后续训练可以直接使用已增强好的数据,减少了实时计算需求,适合计算资源有限的环境。
模型对数据分布稳定有要求:对于需要保持训练数据分布稳定的模型或算法(如某些基于统计特征的模型),离线增强提供了固定且一致的数据分布。
训练时间紧张:当训练时间有限,需要快速启动训练过程时,离线增强避免了每次迭代时的实时增强计算,可以显著加快训练初期的速度。
数据集较小:对于小型数据集,离线增强可以生成大量多样化的样本,有效扩充数据集规模,有助于提高模型泛化能力。
2.2.2 在线增强(Online Augmentation)
定义:
在线增强是指在模型训练过程中模型会实时进行数据增强操作。每次迭代时,从原始数据集中抽取一个样本后,立即对其进行一系列随机的变换处理,生成新的增强样本,然后使用该增强样本进行当前批次的训练。
适用场景:
在线增强适用于以下场景:
计算资源充足:在线增强需要在训练过程中实时生成增强样本,可能会增加计算负担,因此更适合在计算资源充足的环境中使用。
模型对数据变化敏感:对于需要精细调整超参数或对数据分布变化敏感的模型,实时数据增强可以即时反馈增强效果,便于调整和优化。
实时性要求不高:在线增强适用于训练时间相对充裕、对预处理速度要求不高的场景。
总结来说,选择在线增强还是离线增强主要取决于计算资源状况、模型特性、训练时间要求以及数据集规模等因素。在线增强具有更高的灵活性和即时反馈优势,而离线增强则更适合资源有限、要求数据分布稳定的场景,并能节省训练初期的时间。实际应用中,有时也会结合两者的特点,采用混合策略进行数据增强。
3. 数据增强的具体方法
数据增强的具体方法包括但不限于:
几何变换:如水平/垂直翻转、随机裁剪、旋转、缩放、平移、透视变换等,改变目标物体的位置、方向和大小。
颜色空间变换:如亮度调整、对比度变化、饱和度调整、色调偏移、添加高斯噪声、椒盐噪声等,模拟光照条件、相机白平衡和图像质量的变化。
混合变换:如图像混合(如CutMix、MixUp)、样本拼接(如GridMask、RandomErasing)等,将多个样本的部分内容组合在一起,或随机擦除部分区域。
特定领域的增强:针对特定任务或数据类型设计的增强技术,如深度估计中的视点变换、医学影像中的纹理合成等。
4. YOLOv8的数据增强
4.1 YOLOv8默认使用的增强方式策略
1.1、 hsv_h
通过色轮的一小部分调整图像的色调,引入颜色可变性。帮助模型在不同的照明条件下进行概括。
默认数值为0.015,范围是0.0~1.0。
1.2、hsv_s
将图像的饱和度更改一小部分,从而影响颜色的强度。适用于模拟不同的环境条件。
默认数值为0.7,范围是0.0~1.0。
1.3、hsv_v
将图像的值(亮度)修改一小部分,有助于模型在各种照明条件下表现良好。
默认数值为0.4,范围是0.0~1.0。
1.4、translate
将图像水平和垂直方向平移图像的一小部分,有助于学习检测部分可见对象。
默认数值为0.1,范围是0.0~1.0。
1.5、translate
按增益因子缩放图像,模拟与摄影机相距不同距离的对象。
默认数值为0.5,范围是大于等于0.0都可以。
1.6、fliplr
以指定的概率将图像从左向右翻转(类似于左右镜像),这对于学习对称对象和增加数据集的多样性非常有用。
默认数值为0.5,范围是0.0~1.0。
1.7、mosaic
将四个训练图像组合为一个,模拟不同的场景组成和对象交互。YOLO最经典的数据增强方式。对复杂场景的理解非常有效。
默认数值为1.0,范围是0.0~1.0。
1.8、auto_augment
面向分类任务,自动应用预定义的增强策略(randaugment、autoaugment和augmix),通过使视觉特征多样化来优化分类任务。
默认数值为randaugment,范围是(randaugment、autoaugment和augmix)。
1.9、erasing
在分类训练过程中随机擦除图像的一部分,鼓励模型专注于不太明显的特征进行识别。
默认数值为0.4,范围是0.0~0.9。
1.10、crop_fraction
将分类图像裁剪到其大小的一小部分,以强调中心特征并适应对象比例,从而减少背景干扰。
默认数值为1.0,范围是0.1~1.0。
4.2 YOLOv8未使用的增强方式策略
2.1、degrees
在指定的度数范围内随机旋转图像,提高模型识别不同方向对象的能力。选择旋转角度后,在选择的旋转角度范围内进行数据随机旋转。
范围是-180~+180。
2.2、shear
以指定的角度剪切图像,模仿从不同角度观看对象的效果。选择角度后,在选择的角度范围内进行数据随机剪切。
范围是-180~+180。
2.3、perspective
将随机透视变换应用于图像,增强模型理解三维空间中对象的能力。
范围是0.0~0.001。
2.4、flipud
以指定的概率将图像倒置,在不影响对象特性的情况下增加数据的可变性。
范围是0.0~1.0。
2.5、bgr
以指定的概率将图像通道从RGB翻转到BGR,这有助于提高对不正确通道排序的鲁棒性。
范围是0.0~1.0。
2.6、mixup
混合两个图像及其标签,创建合成图像。通过引入标签噪声和视觉可变性来增强模型的泛化能力。
范围是0.0~1.0。
2.7、copy_paste
将对象从一个图像中复制并粘贴到另一个图像上,这对于增加对象实例和学习对象遮挡非常有用。
范围是0.0~1.0。
在进行训练时,直接加相对应的参数即可!例如添加使用flipud 增强策略:
model = YOLO(r"yolov8m-pose.pt") # 用于迁移训练的权重文件路径
results = model.train(data=r"E:\ultralytics-main\datasets\key-points.yaml",
imgsz=640, epochs=100, batch=4, flipud = 0.5, device = 0)
4.3 YOLOv8数据增强的源码位置
YOLOv8进行数据增强的源码位置在ultralytics/data/augment.py中的v8_transforms函数中:
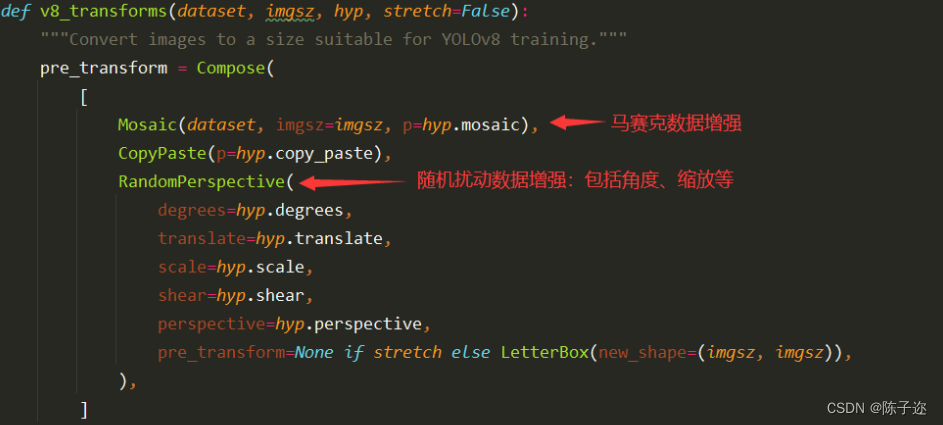
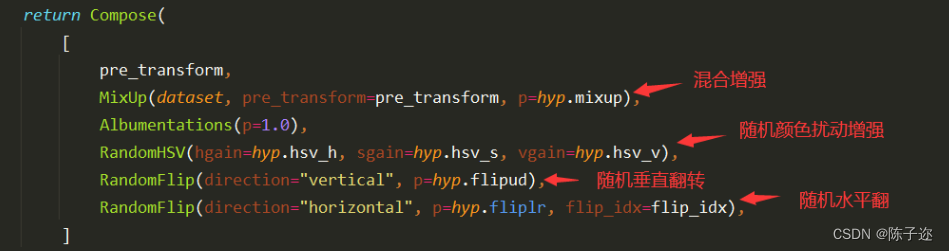
因此,在YOLOv8模型训练时:自己数据集数量不是特别少的情况下。一般为了节省训练时间,我们无需额外对数据集进行离线数据增强。YOLOv8模型会自动帮我们在训练时进行数据的在线数据增强主要包括:马赛克增强(Mosaic)、混合增强(Mixup)、随机扰动(random perspective )以及颜色扰动(HSV augment)等。以确保模型数据集的多样性与泛化能力。
以上数据增强策略均可用于目标检测,分割,骨干提取和分类等。有可能加了之后会导致结果指标下降,需要实际实验进行选取。
原文地址:https://blog.csdn.net/weixin_45303602/article/details/140170710
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!