MMGPL: 多模态医学数据分析与图提示学习| 文献速递-基于深度学习的多模态数据分析与生存分析
Title
题目
MMGPL: Multimodal Medical Data Analysis with Graph Prompt Learning
MMGPL: 多模态医学数据分析与图提示学习
01
文献速递介绍
神经学障碍,包括自闭症谱系障碍(ASD)(Lord等,2018年)和阿尔茨海默病(AD)(Scheltens等,2021年),严重影响患者的社交、语言和认知能力,并已成为全球严重的公共健康问题(Feigin等,2020年)。不幸的是,对于大多数神经学障碍(例如ASD和AD),目前没有明确的治愈方法,因此迫切需要进行神经学障碍的诊断,以促进早期干预和延缓其恶化(Wingo等,2021年;Zhu等,2022年)。
在过去的十年里,研究人员(Wen等,2020年;Li等,2021年;Dvornek等,2019年)应用了各种机器学习方法,如卷积神经网络(CNN)(LeCun和Bengio,1995年)、图神经网络(GNN)(Kipf和Welling,2017年)和循环神经网络(RNN)(Schuster和Paliwal,1997年),来诊断神经学障碍。尽管这些方法取得了显著的进展,但由于这些方法直接在小规模且复杂的医学数据集上训练(Dinsdale等,2022年),深度学习模型的稳健性和有效性难以保证。
最近,训练在广泛数据集和多样任务上的多模态大型模型(Liu等,2023年;Driess等,2023年;Tu等,2023年;Wu等,2023年)展现出了显著的通用性和适应性。因此,多模态大型模型已成为医学数据分析领域的一个重要关注点。各个领域的研究人员已开发出不同的产品,如大型语言模型(例如GPT(OpenAI,2023年))和大型视觉模型(例如SAM(Kirillov等,2023年))。它们可以加速精确和稳健模型的开发,减少对大量标记数据的依赖(Zhang和Metaxas,2023年)。由于其通用性,多模态大型模型在解决神经学障碍的各种诊断任务中具有巨大潜力。
然而,将这些多模态大型模型应用于神经学障碍诊断领域面临着重大挑战,因为多模态医学数据的各种模态(例如PET和MRI)与自然图像差异很大。为了填补预训练任务与下游任务之间的差距,研究人员利用全面微调和提示学习等技术,对预训练的多模态大型模型进行特定医学领域下游任务的解决。
Abstract
摘要
在将多模态大型模型微调到广泛的下游任务中表现出令人印象深刻的效果。然而,将现有的提示学习方法应用于神经疾病的诊断仍然存在两个问题:(i) 现有方法通常平等对待所有图像块,尽管神经影像中只有少数图像块与疾病相关,(ii) 它们忽略了脑连接网络中固有的结构信息,这对于理解和诊断神经疾病至关重要。为了解决这些问题,我们引入了一种新的提示学习模型,在多模态模型的微调过程中学习图提示,用于诊断神经疾病。具体而言,我们首先利用GPT-4获取相关的疾病概念,并计算这些概念与所有图像块之间的语义相似性。其次,根据每个图像块与与疾病相关概念之间的语义相似性减少不相关图像块的权重。此外,我们基于这些概念构建了一个图,使用图卷积网络层提取图的结构信息,用于提示预训练的多模态模型,以诊断神经疾病。大量实验表明,我们的方法在神经疾病诊断方面相比最先进的方法表现出优越的性能,并得到了临床医生的验证。
Method
方法
Utilizing transformers (Vaswani et al., 2017) as the architectureof encoders to process multimodal data has become a popular choicein modern multimodal large models, as it can effectively integrateinformation from multiple modalities. For example, pre-trained visionlanguage models like CLIP (Radford et al., 2021) employ separatetransformer-based backbones (e.g., ViT) to encode images and textseparately. To obtain representations of the samples, the transformerarchitecture involves two key components: (i) Tokenization: convertingthe raw data into tokens. (ii) Encoding: performing attention-basedfeature extraction layers on all tokens.
在处理多模态数据的编码器架构中,利用Transformer(Vaswani等,2017年)已成为现代多模态大型模型中的流行选择,因为它能够有效地整合来自多个模态的信息。例如,像CLIP(Radford等,2021年)这样的预训练视觉语言模型采用了分别编码图像和文本的基于Transformer的主干(例如ViT)。为了获取样本的表示,Transformer架构包括两个关键组成部分:(i) 分词化:将原始数据转换为标记。(ii) 编码:对所有标记执行基于注意力的特征提取层。
Conclusion
结论
In this paper, we proposed a graph prompt learning fine-turningframework for neurological disorder diagnosis, by jointly considering the impact of irrelevant patches as well as the structural information among tokens in multimodal medical data. Specifically, weconduct concept learning, aiming to reduce the weights of irrelevant tokens according to the semantic similarity between each tokenand disease-related concepts. Moreover, we conducted graph promptlearning with concept embeddings, aiming to bridge the gap betweenmultimodal models and neurological disease diagnosis. Experimentalresults demonstrated the effectiveness of our proposed method, compared to state-of-the-art methods on neurological disease diagnosistasks.
在本论文中,我们提出了一种图提示学习微调框架,用于神经学障碍的诊断,同时考虑多模态医学数据中不相关图像块的影响以及标记之间的结构信息。具体而言,我们进行了概念学习,旨在根据每个标记与与疾病相关的概念之间的语义相似性减少不相关标记的权重。此外,我们进行了带有概念嵌入的图提示学习,旨在弥合多模态模型与神经学疾病诊断之间的差距。实验结果显示,与最先进的神经学疾病诊断方法相比,我们提出的方法在实验中表现出了显著的有效性。
Figure
图
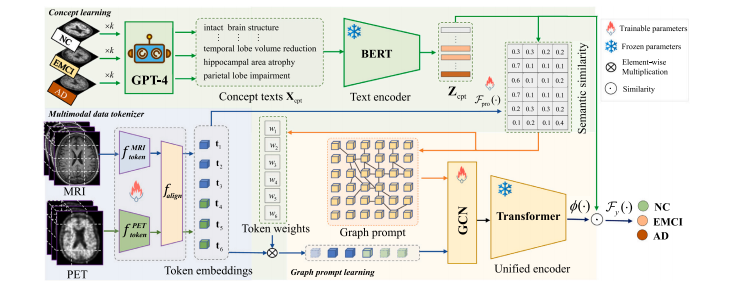
Fig. 1. The flowchart of the proposed MMGPL consists of three modules i.e., multimodal data tokenizer (light blue block), concept learning (light green block), and graph promptlearning (light yellow block). First, MMGPL divides the multimodal medical data into multiple patches and project them into a shared embedding space (Section 3.2). Second,MMGPL prompts the GPT-4 to generate disease-related concepts and further learn the weights of tokens based on the semantic similarity between tokens and concepts (Section 3.3).Third, MMGPL learns a graph among tokens and extracts structural information to prompt the unified encoder (Section 3.4). Finally, MMGPL obtains the output from the unifiedencoder and uses it to predict the label of the subject.
图 1. 提出的MMGPL流程图包括三个模块,即多模态数据分词器(浅蓝色块)、概念学习(浅绿色块)和图提示学习(浅黄色块)。首先,MMGPL将多模态医学数据分割成多个图像块,并投影到共享嵌入空间中(第3.2节)。其次,MMGPL提示GPT-4生成与疾病相关的概念,并根据各个图像块与概念之间的语义相似性进一步学习标记的权重(第3.3节)。第三,MMGPL在各个标记之间学习一个图,并提取结构信息以提示统一编码器(第3.4节)。最后,MMGPL从统一编码器获取输出,并用于预测受试者的标签。
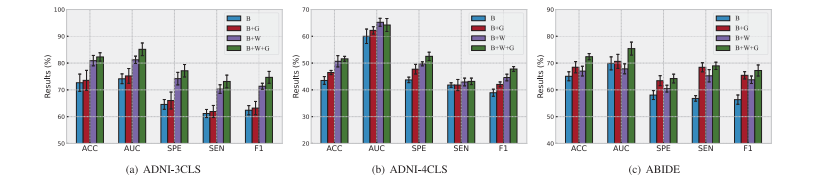
Fig. 2. Performance of MMGPL with different combinations of components on all datasets, i.e., ‘‘B’’ denotes baseline method, ‘‘B+G’’ denotes baseline method with graph promptlearning, ‘‘B+W’’ denotes baseline method with token weights, and ‘‘B+W+G’’ denotes baseline method with graph prompt learning and token weights.
图 2. MMGPL在所有数据集上使用不同组件组合的性能,即‘‘B’’表示基线方法,‘‘B+G’’表示基线方法与图提示学习,‘‘B+W’’表示基线方法与标记权重,‘‘B+W+G’’表示基线方法与图提示学习以及标记权重的组合。
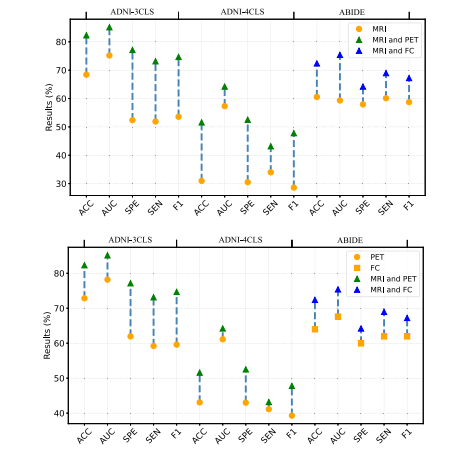
Fig. 3. Performance of MMGPL with different modalities.
图 3. MMGPL在不同模态下的性能表现。

Fig. 4. Heat maps generated by MMGPL on different subjects in ADNI dataset.
图 4. MMGPL在ADNI数据集中生成的热图,显示不同受试者的结果。
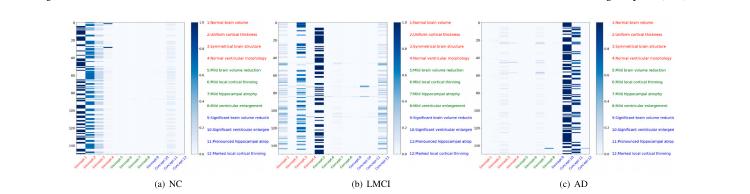
Fig. 5. The visualization of concept-similarity graph on the ADNI dataset. The horizontal and vertical axes represent concepts and tokens. Different colors represent conceptsbelonging to different categories. The red texts represent concepts related to NC, the green texts represent concepts related to LMCI, and the blue texts represent concepts relatedto AD.
图 5. 在ADNI数据集上显示的概念相似性图可视化。水平和垂直轴代表概念和标记。不同颜色表示属于不同类别的概念。红色文字表示与NC相关的概念,绿色文字表示与LMCI相关的概念,蓝色文字表示与AD相关的概念。
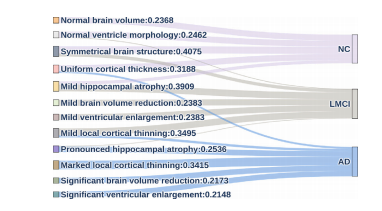
Fig. 6. The visualization of the quantified impact of different concepts on the ADNIdataset. The concepts are shown on the left side, while classes are shown on the rightside. The width of the lines corresponds to the magnitude of the weights, and thevalues indicate the specific weight values.
图 6. 在ADNI数据集上显示的不同概念对其影响的可视化。左侧显示概念,右侧显示类别。线条的宽度对应权重的大小,数值表示具体的权重数值。
Table
表
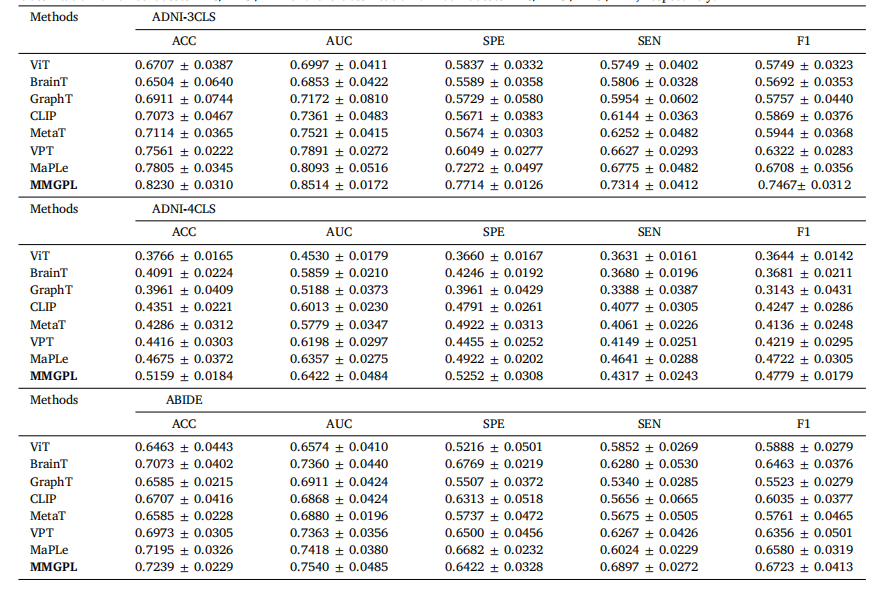
Table 1Diagnose performance (mean and standard deviation) of all methods on all datasets. Note that, ‘‘ADNI-3CLS’’ and ‘‘ADNI-4CLS’’ indicate theclassification on three classes ‘‘NC/LMCI/AD’’ and the classification on four classes ‘‘NC/EMCI/LMCI/AD’’, respectively.
表 1 各种方法在所有数据集上的诊断性能(均值和标准差)。注意,“ADNI-3CLS”和“ADNI-4CLS”分别表示在三类(“NC/LMCI/AD”)和四类(“NC/EMCI/LMCI/AD”)分类上的表现。

Table 2Comparison between MMGPL and related works on scalability. Note that, ✓(vanilla)indicates can only supports two modalities and is challenging to expand to supportsmore modalities.
表 2 MMGPL与相关工作在可扩展性上的比较。注意,✓(原始)表示只能支持两种模态,并且难以扩展以支持更多模态。
原文地址:https://blog.csdn.net/weixin_38594676/article/details/140301288
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!