MyBatis 源码分析 - SQL 的执行过程
MyBatis 源码分析 - SQL 的执行过程
* 本文速览
本篇文章较为详细的介绍了 MyBatis 执行 SQL 的过程。该过程本身比较复杂,牵涉到的技术点比较多。包括但不限于 Mapper 接口代理类的生成、接口方法的解析、SQL 语句的解析、运行时参数的绑定、查询结果自动映射、延迟加载等。本文对所列举的技术点,以及部分未列举的技术点都做了较为详细的分析。全文篇幅很大,需要大家耐心阅读。下面来看一下本文的目录:

源码分析类文章通常比较枯燥。因此,我在分析源码的过程中写了一些示例,同时也绘制了一些图片。希望通过这些示例和图片,帮助大家理解 MyBatis 的源码。

本篇文章篇幅很大,全文字数约 26000 字,阅读时间预计超过 100 分钟。通读本文可能会比较累,大家可以分次阅读。好了,本文的速览就先到这,下面进入正文。
1.简介
在前面的文章中,我分析了配置文件和映射文件的解析过程。经过前面复杂的解析过程后,现在,MyBatis 已经进入了就绪状态,等待使用者发号施令。本篇文章我将分析MyBatis 执行 SQL 的过程,该过程比较复杂,涉及的技术点很多。包括但不限于以下技术点:
- 为 mapper 接口生成实现类
- 根据配置信息生成 SQL,并将运行时参数设置到 SQL 中
- 一二级缓存的实现
- 插件机制
- 数据库连接的获取与管理
- 查询结果的处理,以及延迟加载等
如果大家能掌握上面的技术点,那么对 MyBatis 的原理将会有很深入的理解。若将以上技术点一一展开分析,会导致文章篇幅很大,因此我打算将以上知识点分成数篇文章进行分析。本篇文章将分析以上列表中的第1个、第2个以及第6个技术点,其他技术点将会在随后的文章中进行分析。好了,其他的就不多说了,下面开始我们的源码分析之旅。
2.SQL 执行过程分析
2.1 SQL 执行入口分析
在单独使用 MyBatis 进行数据库操作时,我们通常都会先调用 SqlSession 接口的 getMapper 方法为我们的 Mapper 接口生成实现类。然后就可以通过 Mapper 进行数据库操作。比如像下面这样:
ArticleMapper articleMapper = session.getMapper(ArticleMapper.class);
Article article = articleMapper.findOne(1);
如果大家对 MyBatis 较为理解,会知道 SqlSession 是通过 JDK 动态代理的方式为接口生成代理对象的。在调用接口方法时,方法调用会被代理逻辑拦截。在代理逻辑中可根据方法名及方法归属接口获取到当前方法对应的 SQL 以及其他一些信息,拿到这些信息即可进行数据库操作。
上面是一个简版的 SQL 执行过程,省略了很多细节。下面我们先按照这个简版的流程进行分析,首先我们来看一下 Mapper 接口的代理对象创建过程。
2.1.1 为 Mapper 接口创建代理对象
本节,我们从 DefaultSqlSession 的 getMapper 方法开始看起,如下:
public <T> T getMapper(Class<T> type) {
return configuration.<T>getMapper(type, this);
}
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
return mapperRegistry.getMapper(type, sqlSession);
}
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
如上,经过连续的调用,Mapper 接口代理对象的创建逻辑初现端倪。如果没看过我前面的分析文章,大家可能不知道 knownMappers 集合中的元素是何时存入的。这里再说一遍吧,MyBatis 在解析配置文件的 节点的过程中,会调用 MapperRegistry 的 addMapper 方法将 Class 到 MapperProxyFactory 对象的映射关系存入到 knownMappers。具体的代码就不分析了,大家可以阅读我之前写的文章,或者自行分析相关的代码。
在获取到 MapperProxyFactory 对象后,即可调用工厂方法为 Mapper 接口生成代理对象了。相关逻辑如下:
public T newInstance(SqlSession sqlSession) {
final MapperProxy<T> mapperProxy = new MapperProxy<T>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
protected T newInstance(MapperProxy<T> mapperProxy) {
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[]{mapperInterface}, mapperProxy);
}
上面的代码首先创建了一个 MapperProxy 对象,该对象实现了 InvocationHandler 接口。然后将对象作为参数传给重载方法,并在重载方法中调用 JDK 动态代理接口为 Mapper 生成代理对象。
到此,关于 Mapper 接口代理对象的创建过程就分析完了。现在我们的 ArticleMapper 接口指向的代理对象已经创建完毕,下面就可以调用接口方法进行数据库操作了。由于接口方法会被代理逻辑拦截,所以下面我们把目光聚焦在代理逻辑上面,看看代理逻辑会做哪些事情。
2.1.2 执行代理逻辑
在 MyBatis 中,Mapper 接口方法的代理逻辑实现的比较简单。该逻辑首先会对拦截的方法进行一些检测,以决定是否执行后续的数据库操作。对应的代码如下:
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else if (isDefaultMethod(method)) {
return invokeDefaultMethod(proxy, method, args);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
final MapperMethod mapperMethod = cachedMapperMethod(method);
return mapperMethod.execute(sqlSession, args);
}
如上,代理逻辑会首先检测被拦截的方法是不是定义在 Object 中的,比如 equals、hashCode 方法等。对于这类方法,直接执行即可。除此之外,MyBatis 从 3.4.2 版本开始,对 JDK 1.8 接口的默认方法提供了支持,具体就不分析了。完成相关检测后,紧接着从缓存中获取或者创建 MapperMethod 对象,然后通过该对象中的 execute 方法执行 SQL。在分析 execute 方法之前,我们先来看一下 MapperMethod 对象的创建过程。MapperMethod 的创建过程看似普通,但却包含了一些重要的逻辑,所以不能忽视。
2.1.2.1 创建 MapperMethod 对象
本节来分析一下 MapperMethod 的构造方法,看看它的构造方法中都包含了哪些逻辑。如下:
public class MapperMethod {
private final SqlCommand command;
private final MethodSignature method;
public MapperMethod(Class<?> mapperInterface, Method method, Configuration config) {
this.command = new SqlCommand(config, mapperInterface, method);
this.method = new MethodSignature(config, mapperInterface, method);
}
}
如上,MapperMethod 构造方法的逻辑很简单,主要是创建 SqlCommand 和 MethodSignature 对象。这两个对象分别记录了不同的信息,这些信息在后续的方法调用中都会被用到。下面我们深入到这两个类的构造方法中,探索它们的初始化逻辑。
① 创建 SqlCommand 对象
前面说了 SqlCommand 中保存了一些和 SQL 相关的信息,那具体有哪些信息呢?答案在下面的代码中。
public static class SqlCommand {
private final String name;
private final SqlCommandType type;
public SqlCommand(Configuration configuration, Class<?> mapperInterface, Method method) {
final String methodName = method.getName();
final Class<?> declaringClass = method.getDeclaringClass();
MappedStatement ms = resolveMappedStatement(mapperInterface, methodName, declaringClass, configuration);
if (ms == null) {
if (method.getAnnotation(Flush.class) != null) {
name = null;
type = SqlCommandType.FLUSH;
} else {
throw new BindingException("Invalid bound statement (not found): "
+ mapperInterface.getName() + "." + methodName);
}
} else {
name = ms.getId();
type = ms.getSqlCommandType();
if (type == SqlCommandType.UNKNOWN) {
throw new BindingException("Unknown execution method for: " + name);
}
}
}
}
如上,SqlCommand 的构造方法主要用于初始化它的两个成员变量。代码不是很长,逻辑也不难理解,就不多说了。继续往下看。
② 创建 MethodSignature 对象
MethodSignature 即方法签名,顾名思义,该类保存了一些和目标方法相关的信息。比如目标方法的返回类型,目标方法的参数列表信息等。下面,我们来分析一下 MethodSignature 的构造方法。
public static class MethodSignature {
private final boolean returnsMany;
private final boolean returnsMap;
private final boolean returnsVoid;
private final boolean returnsCursor;
private final Class<?> returnType;
private final String mapKey;
private final Integer resultHandlerIndex;
private final Integer rowBoundsIndex;
private final ParamNameResolver paramNameResolver;
public MethodSignature(Configuration configuration, Class<?> mapperInterface, Method method) {
Type resolvedReturnType = TypeParameterResolver.resolveReturnType(method, mapperInterface);
if (resolvedReturnType instanceof Class<?>) {
this.returnType = (Class<?>) resolvedReturnType;
} else if (resolvedReturnType instanceof ParameterizedType) {
this.returnType = (Class<?>) ((ParameterizedType) resolvedReturnType).getRawType();
} else {
this.returnType = method.getReturnType();
}
this.returnsVoid = void.class.equals(this.returnType);
this.returnsMany = configuration.getObjectFactory().isCollection(this.returnType) || this.returnType.isArray();
this.returnsCursor = Cursor.class.equals(this.returnType);
this.mapKey = getMapKey(method);
this.returnsMap = this.mapKey != null;
this.rowBoundsIndex = getUniqueParamIndex(method, RowBounds.class);
this.resultHandlerIndex = getUniqueParamIndex(method, ResultHandler.class);
this.paramNameResolver = new ParamNameResolver(configuration, method);
}
}
上面的代码用于检测目标方法的返回类型,以及解析目标方法参数列表。其中,检测返回类型的目的是为避免查询方法返回错误的类型。比如我们要求接口方法返回一个对象,结果却返回了对象集合,这会导致类型转换错误。关于返回值类型的解析过程先说到这,下面分析参数列表的解析过程。
public class ParamNameResolver {
private static final String GENERIC_NAME_PREFIX = "param";
private final SortedMap<Integer, String> names;
public ParamNameResolver(Configuration config, Method method) {
final Class<?>[] paramTypes = method.getParameterTypes();
final Annotation[][] paramAnnotations = method.getParameterAnnotations();
final SortedMap<Integer, String> map = new TreeMap<Integer, String>();
int paramCount = paramAnnotations.length;
for (int paramIndex = 0; paramIndex < paramCount; paramIndex++) {
if (isSpecialParameter(paramTypes[paramIndex])) {
continue;
}
String name = null;
for (Annotation annotation : paramAnnotations[paramIndex]) {
if (annotation instanceof Param) {
hasParamAnnotation = true;
name = ((Param) annotation).value();
break;
}
}
if (name == null) {
if (config.isUseActualParamName()) {
name = getActualParamName(method, paramIndex);
}
if (name == null) {
name = String.valueOf(map.size());
}
}
map.put(paramIndex, name);
}
names = Collections.unmodifiableSortedMap(map);
}
}
以上就是方法参数列表的解析过程,解析完毕后,可得到参数下标到参数名的映射关系,这些映射关系最终存储在 ParamNameResolver 的 names 成员变量中。这些映射关系将会在后面的代码中被用到,大家留意一下。
下面写点代码测试一下 ParamNameResolver 的解析逻辑。如下:
public class ParamNameResolverTest {
@Test
public void test() throws NoSuchMethodException, NoSuchFieldException, IllegalAccessException {
Configuration config = new Configuration();
config.setUseActualParamName(false);
Method method = ArticleMapper.class.getMethod("select", Integer.class, String.class, RowBounds.class, Article.class);
ParamNameResolver resolver = new ParamNameResolver(config, method);
Field field = resolver.getClass().getDeclaredField("names");
field.setAccessible(true);
Object names = field.get(resolver);
System.out.println("names: " + names);
}
class ArticleMapper {
public void select(@Param("id") Integer id, @Param("author") String author, RowBounds rb, Article article) {}
}
}
测试结果如下:
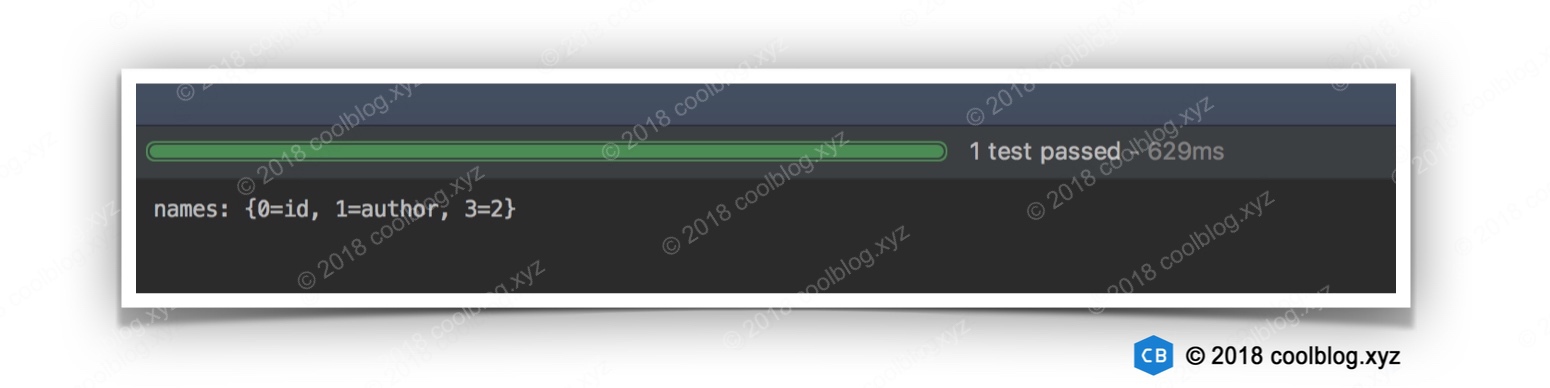
参数索引与名称映射图如下:

到此,关于 MapperMethod 的初始化逻辑就分析完了,继续往下分析。
2.1.2.2 执行 execute 方法
前面已经分析了 MapperMethod 的初始化过程,现在 MapperMethod 创建好了。那么,接下来要做的事情是调用 MapperMethod 的 execute 方法,执行 SQL。代码如下:
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
switch (command.getType()) {
case INSERT: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT:
if (method.returnsVoid() && method.hasResultHandler()) {
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) {
result = executeForCursor(sqlSession, args);
} else {
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);
}
break;
case FLUSH:
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType()
+ ").");
}
return result;
}
如上,execute 方法主要由一个 switch 语句组成,用于根据 SQL 类型执行相应的数据库操作。该方法的逻辑清晰,不需要太多的分析。不过在上面的方法中 convertArgsToSqlCommandParam 方法出现次数比较频繁,这里分析一下:
public Object convertArgsToSqlCommandParam(Object[] args) {
return paramNameResolver.getNamedParams(args);
}
public Object getNamedParams(Object[] args) {
final int paramCount = names.size();
if (args == null || paramCount == 0) {
return null;
} else if (!hasParamAnnotation && paramCount == 1) {
return args[names.firstKey()];
} else {
final Map<String, Object> param = new ParamMap<Object>();
int i = 0;
for (Map.Entry<Integer, String> entry : names.entrySet()) {
param.put(entry.getValue(), args[entry.getKey()]);
final String genericParamName = GENERIC_NAME_PREFIX + String.valueOf(i + 1);
if (!names.containsValue(genericParamName)) {
param.put(genericParamName, args[entry.getKey()]);
}
i++;
}
return param;
}
}
如上,convertArgsToSqlCommandParam 是一个空壳方法,该方法最终调用了 ParamNameResolver 的 getNamedParams 方法。getNamedParams 方法的主要逻辑是根据条件返回不同的结果,该方法的代码不是很难理解,我也进行了比较详细的注释,就不多说了。
分析完 convertArgsToSqlCommandParam 的逻辑,接下来说说 MyBatis 对哪些 SQL 指令提供了支持,如下:
- 查询语句:SELECT
- 更新语句:INSERT/UPDATE/DELETE
- 存储过程:CALL
在上面的列表中,我刻意对 SELECT/INSERT/UPDATE/DELETE 等指令进行了分类,分类依据指令的功能以及 MyBatis 执行这些指令的过程。这里把 SELECT 称为查询语句,INSERT/UPDATE/DELETE 等称为更新语句。接下来,先来分析查询语句的执行过程。
2.2 查询语句的执行过程分析
查询语句对应的方法比较多,有如下几种:
- executeWithResultHandler
- executeForMany
- executeForMap
- executeForCursor
这些方法在内部调用了 SqlSession 中的一些 select* 方法,比如 selectList、selectMap、selectCursor 等。这些方法的返回值类型是不同的,因此对于每种返回类型,需要有专门的处理方法。以 selectList 方法为例,该方法的返回值类型为 List。但如果我们的 Mapper 或 Dao 的接口方法返回值类型为数组,或者 Set,直接将 List 类型的结果返回给 Mapper/Dao 就不合适了。execute* 等方法只是对 select* 等方法做了一层简单的封装,因此接下来我们应该把目光放在这些 select* 方法上。下面我们来分析一下 selectOne 方法的源码,如下:
2.2.1 selectOne 方法分析
本节选择分析 selectOne 方法,而不是其他的方法,大家或许会觉得奇怪。前面提及了 selectList、selectMap、selectCursor 等方法,这里却分析一个未提及的方法。这样做并没什么特别之处,主要原因是 selectOne 在内部会调用 selectList 方法。这里分析 selectOne 方法是为了告知大家,selectOne 和 selectList 方法是有联系的,同时分析 selectOne 方法等同于分析 selectList 方法。如果你不信的话,那我们看源码吧,源码面前了无秘密。
public <T> T selectOne(String statement, Object parameter) {
List<T> list = this.<T>selectList(statement, parameter);
if (list.size() == 1) {
return list.get(0);
} else if (list.size() > 1) {
throw new TooManyResultsException(
"Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
return null;
}
}
如上,selectOne 方法在内部调用 selectList 了方法,并取 selectList 返回值的第1个元素作为自己的返回值。如果 selectList 返回的列表元素大于1,则抛出异常。上面代码比较易懂,就不多说了。下面我们来看看 selectList 方法的实现。
public <E> List<E> selectList(String statement, Object parameter) {
return this.selectList(statement, parameter, RowBounds.DEFAULT);
}
private final Executor executor;
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
如上,这里要来说说 executor 变量,该变量类型为 Executor。Executor 是一个接口,它的实现类如下:
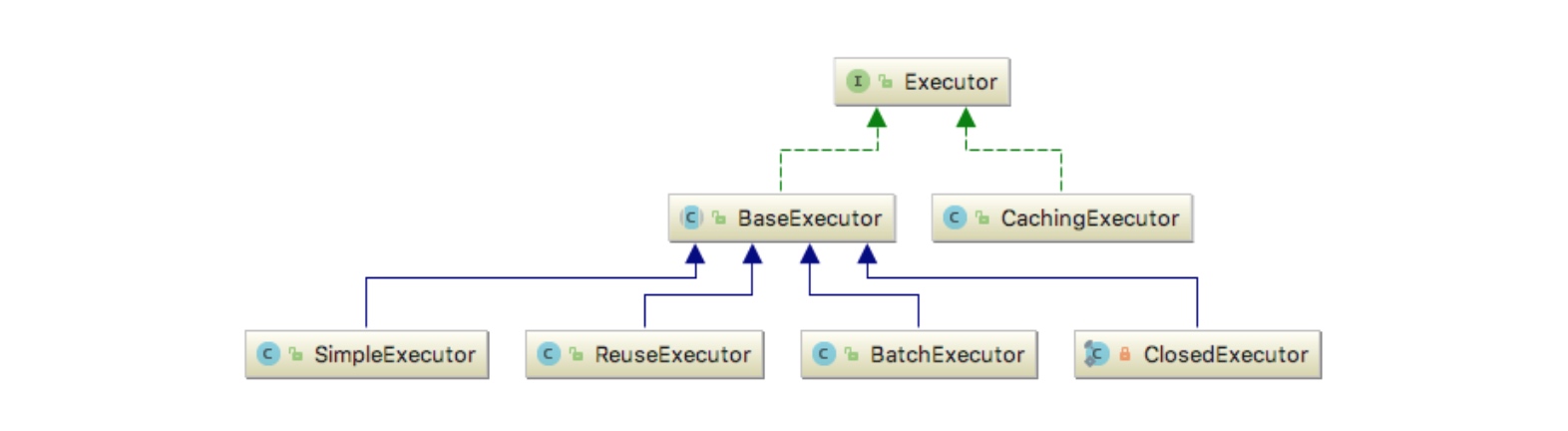
如上,Executor 有这么多的实现类,大家猜一下 executor 变量对应哪个实现类。要弄清楚这个问题,需要大家到源头去查证。这里提示一下,大家可以跟踪一下 DefaultSqlSessionFactory 的 openSession 方法,很快就能发现executor 变量创建的踪迹。限于篇幅原因,本文就不分析 openSession 方法的源码了。好了,下面我来直接告诉大家 executor 变量对应哪个实现类吧。默认情况下,executor 的类型为 CachingExecutor,该类是一个装饰器类,用于给目标 Executor 增加二级缓存功能。那目标 Executor 是谁呢?默认情况下是 SimpleExecutor。
现在大家搞清楚 executor 变量的身份了,接下来继续分析 selectOne 方法的调用栈。先来看看 CachingExecutor 的 query 方法是怎样实现的。如下:
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameterObject);
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
上面的代码用于获取 BoundSql 对象,创建 CacheKey 对象,然后再将这两个对象传给重载方法。关于 BoundSql 的获取过程较为复杂,我将在下一节进行分析。CacheKey 以及接下来即将出现的一二级缓存将会独立成文进行分析。
上面的方法和 SimpleExecutor 父类 BaseExecutor 中的实现没什么区别,有区别的地方在于这个方法所调用的重载方法。我们继续往下看。
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
Cache cache = ms.getCache();
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.<E>query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list);
}
return list;
}
}
return delegate.<E>query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
上面的代码涉及到了二级缓存,若二级缓存为空,或未命中,则调用被装饰类的 query 方法。下面来看一下 BaseExecutor 的中签名相同的 query 方法是如何实现的。
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
clearLocalCache();
}
}
return list;
}
如上,上面的方法主要用于从一级缓存中查找查询结果。若缓存未命中,再向数据库进行查询。在上面的代码中,出现了一个新的类 DeferredLoad,这个类用于延迟加载。该类的实现并不复杂,但是具体用途让我有点疑惑。这个我目前也未完全搞清楚,就不强行分析了。接下来,我们来看一下 queryFromDatabase 方法的实现。
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds,
ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
上面的代码仍然不是 selectOne 方法调用栈的终点,抛开缓存操作,queryFromDatabase 最终还会调用 doQuery 进行查询。下面我们继续进行跟踪。
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.<E>query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
上面的方法中仍然有不少的逻辑,完全看不到即将要到达终点的趋势,不过这离终点又近了一步。接下来,我们先跳过 StatementHandler 和 Statement 创建过程,这两个对象的创建过程会在后面进行说明。这里,我们以 PreparedStatementHandler 为例,看看它的 query 方法是怎样实现的。如下:
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
return resultSetHandler.<E>handleResultSets(ps);
}
到这里似乎看到了希望,整个调用过程总算要结束了。不过先别高兴的太早,SQL 执行结果的处理过程也很复杂,稍后将会专门拿出一节内容进行分析。
以上就是 selectOne 方法的执行过程,尽管我已经简化了代码分析,但是整个过程看起来还是很复杂的。查询过程涉及到了很多方法调用,不把这些调用方法搞清楚,很难对 MyBatis 的查询过程有深入的理解。所以在接下来的章节中,我将会对一些重要的调用进行分析。如果大家不满足于泛泛而谈,那么接下来咱们一起进行更为深入的探索吧。
2.2.2 获取 BoundSql
我们在执行 SQL 时,一个重要的任务是将 SQL 语句解析出来。我们都知道 SQL 是配置在映射文件中的,但由于映射文件中的 SQL 可能会包含占位符 #{},以及动态 SQL 标签,比如 、 等。因此,我们并不能直接使用映射文件中配置的 SQL。MyBatis 会将映射文件中的 SQL 解析成一组 SQL 片段。如果某个片段中也包含动态 SQL 相关的标签,那么,MyBatis 会对该片段再次进行分片。最终,一个 SQL 配置将会被解析成一个 SQL 片段树。形如下面的图片:

我们需要对片段树进行解析,以便从每个片段对象中获取相应的内容。然后将这些内容组合起来即可得到一个完成的 SQL 语句,这个完整的 SQL 以及其他的一些信息最终会存储在 BoundSql 对象中。下面我们来看一下 BoundSql 类的成员变量信息,如下:
private final String sql;
private final List<ParameterMapping> parameterMappings;
private final Object parameterObject;
private final Map<String, Object> additionalParameters;
private final MetaObject metaParameters;
下面用一个表格列举各个成员变量的含义。
| 变量名 | 类型 | 用途 |
|---|---|---|
| sql | String | 一个完整的 SQL 语句,可能会包含问号 ? 占位符 |
| parameterMappings | List | 参数映射列表,SQL 中的每个 #{xxx} 占位符都会被解析成相应的 ParameterMapping 对象 |
| parameterObject | Object | 运行时参数,即用户传入的参数,比如 Article 对象,或是其他的参数 |
| additionalParameters | Map | 附加参数集合,用于存储一些额外的信息,比如 datebaseId 等 |
| metaParameters | MetaObject | additionalParameters 的元信息对象 |
以上对 BoundSql 的成员变量做了简要的说明,部分参数的用途大家现在可能不是很明白。不过不用着急,这些变量在接下来的源码分析过程中会陆续的出现。到时候对着源码多思考,或是写点测试代码调试一下,即可弄懂。
好了,现在准备工作已经做好。接下来,开始分析 BoundSql 的构建过程。我们源码之旅的第一站是 MappedStatement 的 getBoundSql 方法,代码如下:
public BoundSql getBoundSql(Object parameterObject) {
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings == null || parameterMappings.isEmpty()) {
boundSql = new BoundSql(configuration, boundSql.getSql(), parameterMap.getParameterMappings(), parameterObject);
}
return boundSql;
}
如上,MappedStatement 的 getBoundSql 在内部调用了 SqlSource 实现类的 getBoundSql 方法。处理此处的调用,余下的逻辑都不是重要逻辑,就不啰嗦了。接下来,我们把目光转移到 SqlSource 实现类的 getBoundSql 方法上。SqlSource 是一个接口,它有如下几个实现类:
- DynamicSqlSource
- RawSqlSource
- StaticSqlSource
- ProviderSqlSource
- VelocitySqlSource
在如上几个实现类中,我们应该选择分析哪个实现类的逻辑呢?如果大家分析过 MyBatis 映射文件的解析过程,或者阅读过我上一篇的关于MyBatis 映射文件分析的文章,那么这个问题不难回答。好了,不卖关子了,我来回答一下这个问题吧。首先我们把最后两个排除掉,不常用。剩下的三个实现类中,仅前两个实现类会在映射文件解析的过程中被使用。当 SQL 配置中包含 ${}(不是 #{})占位符,或者包含 、 等标签时,会被认为是动态 SQL,此时使用 DynamicSqlSource 存储 SQL 片段。否则,使用 RawSqlSource 存储 SQL 配置信息。相比之下 DynamicSqlSource 存储的 SQL 片段类型较多,解析起来也更为复杂一些。因此下面我将分析 DynamicSqlSource 的 getBoundSql 方法。弄懂这个,RawSqlSource 也不在话下。好了,下面开始分析。
public BoundSql getBoundSql(Object parameterObject) {
DynamicContext context = new DynamicContext(configuration, parameterObject);
rootSqlNode.apply(context);
SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings());
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
for (Map.Entry<String, Object> entry : context.getBindings().entrySet()) {
boundSql.setAdditionalParameter(entry.getKey(), entry.getValue());
}
return boundSql;
}
如上,DynamicSqlSource 的 getBoundSql 方法的代码看起来不多,但是逻辑却并不简单。该方法由数个步骤组成,这里总结一下:
- 创建 DynamicContext
- 解析 SQL 片段,并将解析结果存储到 DynamicContext 中
- 解析 SQL 语句,并构建 StaticSqlSource
- 调用 StaticSqlSource 的 getBoundSql 获取 BoundSql
- 将 DynamicContext 的 ContextMap 中的内容拷贝到 BoundSql 中
如上5个步骤中,第5步为常规操作,就不多说了,其他步骤将会在接下来章节中一一进行分析。按照顺序,我们先来分析 DynamicContext 的实现。
2.2.2.1 DynamicContext
DynamicContext 是 SQL 语句构建的上下文,每个 SQL 片段解析完成后,都会将解析结果存入 DynamicContext 中。待所有的 SQL 片段解析完毕后,一条完整的 SQL 语句就会出现在 DynamicContext 对象中。下面我们来看一下 DynamicContext 类的定义。
public class DynamicContext {
public static final String PARAMETER_OBJECT_KEY = "_parameter";
public static final String DATABASE_ID_KEY = "_databaseId";
private final ContextMap bindings;
private final StringBuilder sqlBuilder = new StringBuilder();
public DynamicContext(Configuration configuration, Object parameterObject) {
if (parameterObject != null && !(parameterObject instanceof Map)) {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
bindings = new ContextMap(metaObject);
} else {
bindings = new ContextMap(null);
}
bindings.put(PARAMETER_OBJECT_KEY, parameterObject);
bindings.put(DATABASE_ID_KEY, configuration.getDatabaseId());
}
}
如上,上面只贴了 DynamicContext 类的部分代码。其中 sqlBuilder 变量用于存放 SQL 片段的解析结果,bindings 则用于存储一些额外的信息,比如运行时参数 和 databaseId 等。bindings 类型为 ContextMap,ContextMap 定义在 DynamicContext 中,是一个静态内部类。该类继承自 HashMap,并覆写了 get 方法。它的代码如下:
static class ContextMap extends HashMap<String, Object> {
private MetaObject parameterMetaObject;
public ContextMap(MetaObject parameterMetaObject) {
this.parameterMetaObject = parameterMetaObject;
}
@Override
public Object get(Object key) {
String strKey = (String) key;
if (super.containsKey(strKey)) {
return super.get(strKey);
}
if (parameterMetaObject != null) {
return parameterMetaObject.getValue(strKey);
}
return null;
}
}
DynamicContext 对外提供了两个接口,用于操作 sqlBuilder。分别如下:
public void appendSql(String sql) {
sqlBuilder.append(sql);
sqlBuilder.append(" ");
}
public String getSql() {
return sqlBuilder.toString().trim();
}
以上就是对 DynamicContext 的简单介绍,DynamicContext 的源码不难理解,这里就不多说了。继续往下分析。
2.2.2.2 解析 SQL 片段
对于一个包含了 ${} 占位符,或 、 等标签的 SQL,在解析的过程中,会被分解成多个片段。每个片段都有对应的类型,每种类型的片段都有不同的解析逻辑。在源码中,片段这个概念等价于 sql 节点,即 SqlNode。SqlNode 是一个接口,它有众多的实现类。其继承体系如下:

上图只画出了部分的实现类,还有一小部分没画出来,不过这并不影响接下来的分析。在众多实现类中,StaticTextSqlNode 用于存储静态文本,TextSqlNode 用于存储带有 ${} 占位符的文本,IfSqlNode 则用于存储 节点的内容。MixedSqlNode 内部维护了一个 SqlNode 集合,用于存储各种各样的 SqlNode。接下来,我将会对 MixedSqlNode 、StaticTextSqlNode、TextSqlNode、IfSqlNode、WhereSqlNode 以及 TrimSqlNode 等进行分析,其他的实现类请大家自行分析。Talk is cheap,show you the code.
public class MixedSqlNode implements SqlNode {
private final List<SqlNode> contents;
public MixedSqlNode(List<SqlNode> contents) {
this.contents = contents;
}
@Override
public boolean apply(DynamicContext context) {
for (SqlNode sqlNode : contents) {
sqlNode.apply(context);
}
return true;
}
}
MixedSqlNode 可以看做是 SqlNode 实现类对象的容器,凡是实现了 SqlNode 接口的类都可以存储到 MixedSqlNode 中,包括它自己。MixedSqlNode 解析方法 apply 逻辑比较简单,即遍历 SqlNode 集合,并调用其他 SalNode 实现类对象的 apply 方法解析 sql。那下面我们来看看其他 SalNode 实现类的 apply 方法是怎样实现的。
public class StaticTextSqlNode implements SqlNode {
private final String text;
public StaticTextSqlNode(String text) {
this.text = text;
}
@Override
public boolean apply(DynamicContext context) {
context.appendSql(text);
return true;
}
}
StaticTextSqlNode 用于存储静态文本,所以它不需要什么解析逻辑,直接将其存储的 SQL 片段添加到 DynamicContext 中即可。StaticTextSqlNode 的实现比较简单,看起来很轻松。下面分析一下 TextSqlNode。
public class TextSqlNode implements SqlNode {
private final String text;
private final Pattern injectionFilter;
@Override
public boolean apply(DynamicContext context) {
GenericTokenParser parser = createParser(new BindingTokenParser(context, injectionFilter));
context.appendSql(parser.parse(text));
return true;
}
private GenericTokenParser createParser(TokenHandler handler) {
return new GenericTokenParser("${", "}", handler);
}
private static class BindingTokenParser implements TokenHandler {
private DynamicContext context;
private Pattern injectionFilter;
public BindingTokenParser(DynamicContext context, Pattern injectionFilter) {
this.context = context;
this.injectionFilter = injectionFilter;
}
@Override
public String handleToken(String content) {
Object parameter = context.getBindings().get("_parameter");
if (parameter == null) {
context.getBindings().put("value", null);
} else if (SimpleTypeRegistry.isSimpleType(parameter.getClass())) {
context.getBindings().put("value", parameter);
}
Object value = OgnlCache.getValue(content, context.getBindings());
String srtValue = (value == null ? "" : String.valueOf(value));
checkInjection(srtValue);
return srtValue;
}
}
}
如上,GenericTokenParser 是一个通用的标记解析器,用于解析形如 ${xxx},#{xxx} 等标记。GenericTokenParser 负责将标记中的内容抽取出来,并将标记内容交给相应的 TokenHandler 去处理。BindingTokenParser 负责解析标记内容,并将解析结果返回给 GenericTokenParser,用于替换 ${xxx} 标记。举个例子说明一下吧,如下。
我们有这样一个 SQL 语句,用于从 article 表中查询某个作者所写的文章。如下:
SELECT * FROM article WHERE author = '${author}'
假设我们我们传入的 author 值为 tianxiaobo,那么该 SQL 最终会被解析成如下的结果:
SELECT * FROM article WHERE author = 'tianxiaobo'
一般情况下,使用 ${author} 接受参数都没什么问题。但是怕就怕在有人不怀好意,构建了一些恶意的参数。当用这些恶意的参数替换 ${author} 时就会出现灾难性问题 – SQL 注入。比如我们构建这样一个参数 author = tianxiaobo'; DELETE FROM article;# ,然后我们把这个参数传给 TextSqlNode 进行解析。得到的结果如下:
SELECT * FROM article WHERE author = 'tianxiaobo'; DELETE FROM article;#'
看到没,由于传入的参数没有经过转义,最终导致了一条 SQL 被恶意参数拼接成了两条 SQL。更要命的是,第二天 SQL 会把 article 表的数据清空,这个后果就很严重了(从删库到跑路)。这就是为什么我们不应该在 SQL 语句中是用 ${} 占位符,风险太大。
分析完 TextSqlNode 的逻辑,接下来,分析 IfSqlNode 的实现。
public class IfSqlNode implements SqlNode {
private final ExpressionEvaluator evaluator;
private final String test;
private final SqlNode contents;
public IfSqlNode(SqlNode contents, String test) {
this.test = test;
this.contents = contents;
this.evaluator = new ExpressionEvaluator();
}
@Override
public boolean apply(DynamicContext context) {
if (evaluator.evaluateBoolean(test, context.getBindings())) {
contents.apply(context);
return true;
}
return false;
}
}
IfSqlNode 对应的是 节点, 节点是日常开发中使用频次比较高的一个节点。它的具体用法我想大家都很熟悉了,这里就不多啰嗦。IfSqlNode 的 apply 方法逻辑并不复杂,首先是通过 ONGL 检测 test 表达式是否为 true,如果为 true,则调用其他节点的 apply 方法继续进行解析。需要注意的是 节点中也可嵌套其他的动态节点,并非只有纯文本。因此 contents 变量遍历指向的是 MixedSqlNode,而非 StaticTextSqlNode。
关于 IfSqlNode 就说到这,接下来分析 WhereSqlNode 的实现。
public class WhereSqlNode extends TrimSqlNode {
private static List<String> prefixList = Arrays.asList("AND ", "OR ", "AND\n", "OR\n", "AND\r", "OR\r", "AND\t", "OR\t");
public WhereSqlNode(Configuration configuration, SqlNode contents) {
super(configuration, contents, "WHERE", prefixList, null, null);
}
}
在 MyBatis 中,WhereSqlNode 和 SetSqlNode 都是基于 TrimSqlNode 实现的,所以上面的代码看起来很简单。WhereSqlNode 对应于 节点,关于该节点的用法以及它的应用场景,大家请自行查阅资料。我在分析源码的过程中,默认大家已经知道了该节点的用途和应用场景。
接下来,我们把目光聚焦在 TrimSqlNode 的实现上。
public class TrimSqlNode implements SqlNode {
private final SqlNode contents;
private final String prefix;
private final String suffix;
private final List<String> prefixesToOverride;
private final List<String> suffixesToOverride;
private final Configuration configuration;
@Override
public boolean apply(DynamicContext context) {
FilteredDynamicContext filteredDynamicContext = new FilteredDynamicContext(context);
boolean result = contents.apply(filteredDynamicContext);
filteredDynamicContext.applyAll();
return result;
}
}
如上,apply 方法首选调用了其他 SqlNode 的 apply 方法解析节点内容,这步操作完成后,FilteredDynamicContext 中会得到一条 SQL 片段字符串。接下里需要做的事情是过滤字符串前缀后和后缀,并添加相应的前缀和后缀。这个事情由 FilteredDynamicContext 负责,FilteredDynamicContext 是 TrimSqlNode 的私有内部类。我们去看一下它的代码。
private class FilteredDynamicContext extends DynamicContext {
private DynamicContext delegate;
private boolean prefixApplied;
private boolean suffixApplied;
private StringBuilder sqlBuffer;
public void applyAll() {
sqlBuffer = new StringBuilder(sqlBuffer.toString().trim());
String trimmedUppercaseSql = sqlBuffer.toString().toUpperCase(Locale.ENGLISH);
if (trimmedUppercaseSql.length() > 0) {
applyPrefix(sqlBuffer, trimmedUppercaseSql);
applySuffix(sqlBuffer, trimmedUppercaseSql);
}
delegate.appendSql(sqlBuffer.toString());
}
private void applyPrefix(StringBuilder sql, String trimmedUppercaseSql) {
if (!prefixApplied) {
prefixApplied = true;
if (prefixesToOverride != null) {
for (String toRemove : prefixesToOverride) {
if (trimmedUppercaseSql.startsWith(toRemove)) {
sql.delete(0, toRemove.trim().length());
break;
}
}
}
if (prefix != null) {
sql.insert(0, " ");
sql.insert(0, prefix);
}
}
}
private void applySuffix(StringBuilder sql, String trimmedUppercaseSql) {...}
}
在上面的代码中,我们重点关注 applyAll 和 applyPrefix 方法,其他的方法大家自行分析。applyAll 方法的逻辑比较简单,首先从 sqlBuffer 中获取 SQL 字符串。然后调用 applyPrefix 和 applySuffix 进行过滤操作。最后将过滤后的 SQL 字符串添加到被装饰的类中。applyPrefix 方法会首先检测 SQL 字符串是不是以 "AND ","OR ",或 “AND\n”, “OR\n” 等前缀开头,若是则将前缀从 sqlBuffer 中移除。然后将前缀插入到 sqlBuffer 的首部,整个逻辑就结束了。下面写点代码简单验证一下,如下:
public class SqlNodeTest {
@Test
public void testWhereSqlNode() throws IOException {
String sqlFragment = "AND id = #{id}";
MixedSqlNode msn = new MixedSqlNode(Arrays.asList(new StaticTextSqlNode(sqlFragment)));
WhereSqlNode wsn = new WhereSqlNode(new Configuration(), msn);
DynamicContext dc = new DynamicContext(new Configuration(), new ParamMap<>());
wsn.apply(dc);
System.out.println("解析前:" + sqlFragment);
System.out.println("解析后:" + dc.getSql());
}
}
测试结果如下:

2.2.2.3 解析 #{} 占位符
经过前面的解析,我们已经能从 DynamicContext 获取到完整的 SQL 语句了。但这并不意味着解析过程就结束了,因为当前的 SQL 语句中还有一种占位符没有处理,即 #{}。与 ${} 占位符的处理方式不同,MyBatis 并不会直接将 #{} 占位符替换为相应的参数值。#{} 占位符的解析逻辑这里先不多说,等相应的源码分析完了,答案就明了了。
#{} 占位符的解析逻辑是包含在 SqlSourceBuilder 的 parse 方法中,该方法最终会将解析后的 SQL 以及其他的一些数据封装到 StaticSqlSource 中。下面,一起来看一下 SqlSourceBuilder 的 parse 方法。
public SqlSource parse(String originalSql, Class<?> parameterType, Map<String, Object> additionalParameters) {
ParameterMappingTokenHandler handler = new ParameterMappingTokenHandler(configuration, parameterType, additionalParameters);
GenericTokenParser parser = new GenericTokenParser("#{", "}", handler);
String sql = parser.parse(originalSql);
return new StaticSqlSource(configuration, sql, handler.getParameterMappings());
}
如上,GenericTokenParser 的用途上一节已经介绍过了,就不多说了。接下来,我们重点关注 #{} 占位符处理器 ParameterMappingTokenHandler 的逻辑。
public String handleToken(String content) {
parameterMappings.add(buildParameterMapping(content));
return "?";
}
ParameterMappingTokenHandler 的 handleToken 方法看起来比较简单,但实际上并非如此。GenericTokenParser 负责将 #{} 占位符中的内容抽取出来,并将抽取出的内容传给 handleToken 方法。handleToken 方法负责将传入的参数解析成对应的 ParameterMapping 对象,这步操作由 buildParameterMapping 方法完成。下面我们看一下 buildParameterMapping 的源码。
private ParameterMapping buildParameterMapping(String content) {
Map<String, String> propertiesMap = parseParameterMapping(content);
String property = propertiesMap.get("property");
Class<?> propertyType;
if (metaParameters.hasGetter(property)) {
propertyType = metaParameters.getGetterType(property);
} else if (typeHandlerRegistry.hasTypeHandler(parameterType)) {
propertyType = parameterType;
} else if (JdbcType.CURSOR.name().equals(propertiesMap.get("jdbcType"))) {
propertyType = java.sql.ResultSet.class;
} else if (property == null || Map.class.isAssignableFrom(parameterType)) {
propertyType = Object.class;
} else {
MetaClass metaClass = MetaClass.forClass(parameterType, configuration.getReflectorFactory());
if (metaClass.hasGetter(property)) {
propertyType = metaClass.getGetterType(property);
} else {
propertyType = Object.class;
}
}
ParameterMapping.Builder builder = new ParameterMapping.Builder(configuration, property, propertyType);
Class<?> javaType = propertyType;
String typeHandlerAlias = null;
for (Map.Entry<String, String> entry : propertiesMap.entrySet()) {
String name = entry.getKey();
String value = entry.getValue();
if ("javaType".equals(name)) {
javaType = resolveClass(value);
builder.javaType(javaType);
} else if ("jdbcType".equals(name)) {
builder.jdbcType(resolveJdbcType(value));
} else if ("mode".equals(name)) {...}
else if ("numericScale".equals(name)) {...}
else if ("resultMap".equals(name)) {...}
else if ("typeHandler".equals(name)) {
typeHandlerAlias = value;
}
else if ("jdbcTypeName".equals(name)) {...}
else if ("property".equals(name)) {...}
else if ("expression".equals(name)) {
throw new BuilderException("Expression based parameters are not supported yet");
} else {
throw new BuilderException("An invalid property '" + name + "' was found in mapping #{" + content
+ "}. Valid properties are " + parameterProperties);
}
}
if (typeHandlerAlias != null) {
builder.typeHandler(resolveTypeHandler(javaType, typeHandlerAlias));
}
return builder.build();
}
如上,buildParameterMapping 代码很多,逻辑看起来很复杂。但是它做的事情却不是很多,只有3件事情。如下:
- 解析 content
- 解析 propertyType,对应分割线之上的代码
- 构建 ParameterMapping 对象,对应分割线之下的代码
buildParameterMapping 代码比较多,不太好理解,下面写个示例演示一下。如下:
public class SqlSourceBuilderTest {
@Test
public void test() {
String sql = "SELECT * FROM Author WHERE age = #{age,javaType=int,jdbcType=NUMERIC}";
SqlSourceBuilder sqlSourceBuilder = new SqlSourceBuilder(new Configuration());
SqlSource sqlSource = sqlSourceBuilder.parse(sql, Author.class, new HashMap<>());
BoundSql boundSql = sqlSource.getBoundSql(new Author());
System.out.println(String.format("SQL: %s\n", boundSql.getSql()));
System.out.println(String.format("ParameterMappings: %s", boundSql.getParameterMappings()));
}
}
public class Author {
private Integer id;
private String name;
private Integer age;
}
测试结果如下:
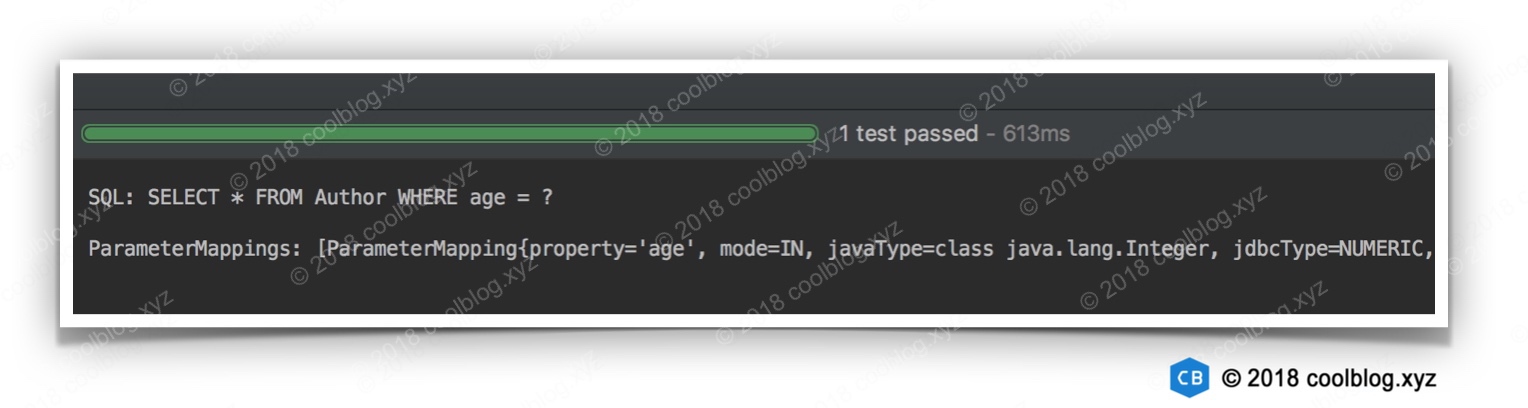
正如测试结果所示,SQL 中的 #{age, …} 占位符被替换成了问号 ?。#{age, …} 也被解析成了一个 ParameterMapping 对象。
本节的最后,我们再来看一下 StaticSqlSource 的创建过程。如下:
public class StaticSqlSource implements SqlSource {
private final String sql;
private final List<ParameterMapping> parameterMappings;
private final Configuration configuration;
public StaticSqlSource(Configuration configuration, String sql) {
this(configuration, sql, null);
}
public StaticSqlSource(Configuration configuration, String sql, List<ParameterMapping> parameterMappings) {
this.sql = sql;
this.parameterMappings = parameterMappings;
this.configuration = configuration;
}
@Override
public BoundSql getBoundSql(Object parameterObject) {
return new BoundSql(configuration, sql, parameterMappings, parameterObject);
}
}
上面代码没有什么太复杂的地方,从上面代码中可以看出 BoundSql 的创建过程也很简单。正因为前面经历了这么复杂的解析逻辑,BoundSql 的创建过程才会如此简单。到此,关于 BoundSql 构建的过程就分析完了,稍作休息,我们进行后面的分析。
2.2.3 创建 StatementHandler
在 MyBatis 的源码中,StatementHandler 是一个非常核心接口。之所以说它核心,是因为从代码分层的角度来说,StatementHandler 是 MyBatis 源码的边界,再往下层就是 JDBC 层面的接口了。StatementHandler 需要和 JDBC 层面的接口打交道,它要做的事情有很多。在执行 SQL 之前,StatementHandler 需要创建合适的 Statement 对象,然后填充参数值到 Statement 对象中,最后通过 Statement 对象执行 SQL。这还不算完,待 SQL 执行完毕,还要去处理查询结果等。这些过程看似简单,但实现起来却很复杂。好在,这些过程对应的逻辑并不需要我们亲自实现,只需要耐心看一下,难度降低了不少。好了,其他的就不多说了。下面我们来看一下 StatementHandler 的继承体系。
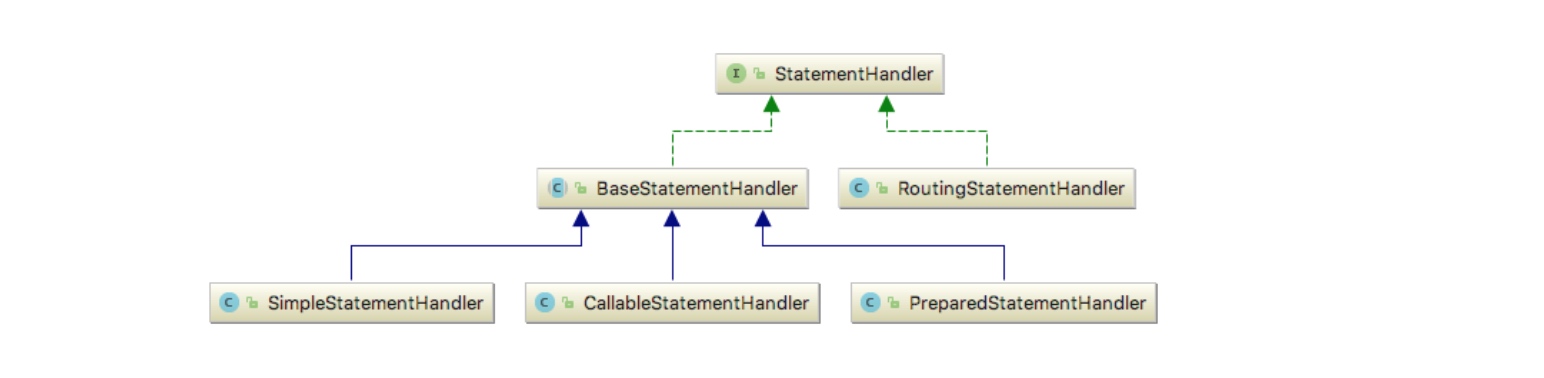
上图中,最下层的三种 StatementHandler 实现类与三种不同的 Statement 进行交互,这个不难看出来。但 RoutingStatementHandler 则是一个奇怪的存在,因为 JDBC 中并不存在 RoutingStatement。那它有什么用呢?接下来,我们到代码中寻找答案。
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement,
Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
如上,newStatementHandler 方法在创建 StatementHandler 之后,还会应用插件到 StatementHandler 上。关于 MyBatis 的插件机制,后面独立成文进行讲解,这里就不分析了。下面分析一下 RoutingStatementHandler。
public class RoutingStatementHandler implements StatementHandler {
private final StatementHandler delegate;
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds,
ResultHandler resultHandler, BoundSql boundSql) {
switch (ms.getStatementType()) {
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}
}
如上,RoutingStatementHandler 的构造方法会根据 MappedStatement 中的 statementType 变量创建不同的 StatementHandler 实现类。默认情况下,statementType 值为 PREPARED。关于 StatementHandler 创建的过程就先分析到这,StatementHandler 创建完成了,后续要做到事情是创建 Statement,以及将运行时参数和 Statement 进行绑定。接下里,就来分析这一块的逻辑。
2.2.4 设置运行时参数到 SQL 中
JDBC 提供了三种 Statement 接口,分别是 Statement、PreparedStatement 和 CallableStatement。他们的关系如下:

上面三个接口的层级分明,其中 Statement 接口提供了执行 SQL,获取执行结果等基本功能。PreparedStatement 在此基础上,对 IN 类型的参数提供了支持。使得我们可以使用运行时参数替换 SQL 中的问号 ? 占位符,而不用手动拼接 SQL。CallableStatement 则是 在 PreparedStatement 基础上,对 OUT 类型的参数提供了支持,该种类型的参数用于保存存储过程输出的结果。
本节,我将分析 PreparedStatement 的创建,以及设置运行时参数到 SQL 中的过程。其他两种 Statement 的处理过程,大家请自行分析。Statement 的创建入口是在 SimpleExecutor 的 prepareStatement 方法中,下面从这个方法开始进行分析。
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt);
return stmt;
}
如上,上面代码的逻辑不复杂,总共包含三个步骤。如下:
- 获取数据库连接
- 创建 Statement
- 为 Statement 设置 IN 参数
上面三个步骤看起来并不难实现,实际上如果大家愿意写,也能写出来。不过 MyBatis 对着三个步骤进行拓展,实现上也相对复杂一下。以获取数据库连接为例,MyBatis 并未没有在 getConnection 方法中直接调用 JDBC DriverManager 的 getConnection 方法获取获取连接,而是通过数据源获取获取连接。MyBatis 提供了两种基于 JDBC 接口的数据源,分别为 PooledDataSource 和 UnpooledDataSource。创建或获取数据库连接的操作最终是由这两个数据源执行。限于篇幅问题,本节不打算分析以上两种数据源的源码,相关分析会在下一篇文章中展开。
接下来,我将分析 PreparedStatement 的创建,以及 IN 参数设置的过程。按照顺序,先来分析 PreparedStatement 的创建过程。如下:
public Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException {
Statement statement = null;
try {
statement = instantiateStatement(connection);
setStatementTimeout(statement, transactionTimeout);
setFetchSize(statement);
return statement;
} catch (SQLException e) {
closeStatement(statement);
throw e;
} catch (Exception e) {
closeStatement(statement);
throw new ExecutorException("Error preparing statement. Cause: " + e, e);
}
}
protected Statement instantiateStatement(Connection connection) throws SQLException {
String sql = boundSql.getSql();
if (mappedStatement.getKeyGenerator() instanceof Jdbc3KeyGenerator) {
String[] keyColumnNames = mappedStatement.getKeyColumns();
if (keyColumnNames == null) {
return connection.prepareStatement(sql, PreparedStatement.RETURN_GENERATED_KEYS);
} else {
return connection.prepareStatement(sql, keyColumnNames);
}
} else if (mappedStatement.getResultSetType() != null) {
return connection.prepareStatement(sql, mappedStatement.getResultSetType().getValue(), ResultSet.CONCUR_READ_ONLY);
} else {
return connection.prepareStatement(sql);
}
}
如上,PreparedStatement 的创建过程没什么复杂的地方,就不多说了。下面分析运行时参数是如何被设置到 SQL 中的过程。
public void parameterize(Statement statement) throws SQLException {
parameterHandler.setParameters((PreparedStatement) statement);
}
public class DefaultParameterHandler implements ParameterHandler {
private final TypeHandlerRegistry typeHandlerRegistry;
private final MappedStatement mappedStatement;
private final Object parameterObject;
private final BoundSql boundSql;
private final Configuration configuration;
public void setParameters(PreparedStatement ps) {
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings != null) {
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
TypeHandler typeHandler = parameterMapping.getTypeHandler();
JdbcType jdbcType = parameterMapping.getJdbcType();
if (value == null && jdbcType == null) {
jdbcType = configuration.getJdbcTypeForNull();
}
try {
typeHandler.setParameter(ps, i + 1, value, jdbcType);
} catch (TypeException e) {
throw new TypeException(...);
} catch (SQLException e) {
throw new TypeException(...);
}
}
}
}
}
}
如上代码,分割线以上的大段代码用于获取 #{xxx} 占位符属性所对应的运行时参数。分割线以下的代码则是获取 #{xxx} 占位符属性对应的 TypeHandler,并在最后通过 TypeHandler 将运行时参数值设置到 PreparedStatement 中。关于 TypeHandler 的用途,我在本系列文章的导读一文介绍过,这里就不赘述了。大家若不熟悉,可以去看看。
2.2.5 #{} 占位符的解析与参数的设置过程梳理
前面两节的内容比较多,本节我将对前两节的部分内容进行梳理,以便大家能够更好理解这两节内容之间的联系。假设我们有这样一条 SQL 语句:
SELECT * FROM author WHERE name = #{name} AND age = #{age}
这个 SQL 语句中包含两个 #{} 占位符,在运行时这两个占位符会被解析成两个 ParameterMapping 对象。如下:
ParameterMapping{property='name', mode=IN, javaType=class java.lang.String, jdbcType=null, ...}
和
ParameterMapping{property='age', mode=IN, javaType=class java.lang.Integer, jdbcType=null, ...}
#{} 占位符解析完毕后,得到的 SQL 如下:
SELECT * FROM Author WHERE name = ? AND age = ?
这里假设下面这个方法与上面的 SQL 对应:
Author findByNameAndAge(@Param("name") String name, @Param("age") Integer age)
该方法的参数列表会被 ParamNameResolver 解析成一个 map,如下:
{
0: "name",
1: "age"
}
假设该方法在运行时有如下的调用:
findByNameAndAge("tianxiaobo", 20)
此时,需要再次借助 ParamNameResolver 力量。这次我们将参数名和运行时的参数值绑定起来,得到如下的映射关系。
{
"name": "tianxiaobo",
"age": 20,
"param1": "tianxiaobo",
"param2": 20
}
下一步,我们要将运行时参数设置到 SQL 中。由于原 SQL 经过解析后,占位符信息已经被擦除掉了,我们无法直接将运行时参数 SQL 中。不过好在,这些占位符信息被记录在了 ParameterMapping 中了,MyBatis 会将 ParameterMapping 会按照 #{} 的解析顺序存入到 List 中。这样我们通过 ParameterMapping 在列表中的位置确定它与 SQL 中的哪个 ? 占位符相关联。同时通过 ParameterMapping 中的 property 字段,我们到“参数名与参数值”映射表中查找具体的参数值。这样,我们就可以将参数值准确的设置到 SQL 中了,此时 SQL 如下:
SELECT * FROM Author WHERE name = "tianxiaobo" AND age = 20
整个流程如下图所示。

当运行时参数被设置到 SQL 中 后,下一步要做的事情是执行 SQL,然后处理 SQL 执行结果。对于更新操作,数据库一般返回一个 int 行数值,表示受影响行数,这个处理起来比较简单。但对于查询操作,返回的结果类型多变,处理方式也很复杂。接下来,我们就来看看 MyBatis 是如何处理查询结果的。
2.2.6 处理查询结果
MyBatis 可以将查询结果,即结果集 ResultSet 自动映射成实体类对象。这样使用者就无需再手动操作结果集,并将数据填充到实体类对象中。这可大大降低开发的工作量,提高工作效率。在 MyBatis 中,结果集的处理工作由结果集处理器 ResultSetHandler 执行。ResultSetHandler 是一个接口,它只有一个实现类 DefaultResultSetHandler。结果集的处理入口方法是 handleResultSets,下面来看一下该方法的实现。
public List<Object> handleResultSets(Statement stmt) throws SQLException {
final List<Object> multipleResults = new ArrayList<Object>();
int resultSetCount = 0;
ResultSetWrapper rsw = getFirstResultSet(stmt);
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
validateResultMapsCount(rsw, resultMapCount);
while (rsw != null && resultMapCount > resultSetCount) {
ResultMap resultMap = resultMaps.get(resultSetCount);
handleResultSet(rsw, resultMap, multipleResults, null);
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
String[] resultSets = mappedStatement.getResultSets();
if (resultSets != null) {...}
return collapseSingleResultList(multipleResults);
}
private ResultSetWrapper getFirstResultSet(Statement stmt) throws SQLException {
ResultSet rs = stmt.getResultSet();
while (rs == null) {
if (stmt.getMoreResults()) {
rs = stmt.getResultSet();
} else {
if (stmt.getUpdateCount() == -1) {
break;
}
}
}
return rs != null ? new ResultSetWrapper(rs, configuration) : null;
}
如上,该方法首先从 Statement 中获取第一个结果集,然后调用 handleResultSet 方法对该结果集进行处理。一般情况下,如果我们不调用存储过程,不会涉及到多结果集的问题。由于存储过程并不是很常用,所以关于多结果集的处理逻辑我就不分析了。下面,我们把目光聚焦在单结果集的处理逻辑上。
private void handleResultSet(ResultSetWrapper rsw, ResultMap resultMap, List<Object> multipleResults, ResultMapping parentMapping) throws SQLException {
try {
if (parentMapping != null) {
handleRowValues(rsw, resultMap, null, RowBounds.DEFAULT, parentMapping);
} else {
if (resultHandler == null) {
DefaultResultHandler defaultResultHandler = new DefaultResultHandler(objectFactory);
handleRowValues(rsw, resultMap, defaultResultHandler, rowBounds, null);
multipleResults.add(defaultResultHandler.getResultList());
} else {
handleRowValues(rsw, resultMap, resultHandler, rowBounds, null);
}
}
} finally {
closeResultSet(rsw.getResultSet());
}
}
在上面代码中,出镜率最高的 handleRowValues 方法,该方法用于处理结果集中的数据。下面来看一下这个方法的逻辑。
public void handleRowValues(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler,
RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {
if (resultMap.hasNestedResultMaps()) {
ensureNoRowBounds();
checkResultHandler();
handleRowValuesForNestedResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
} else {
handleRowValuesForSimpleResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
}
}
如上,handleRowValues 方法中针对两种映射方式进行了处理。一种是嵌套映射,另一种是简单映射。本文所说的嵌套查询是指 中嵌套了一个 ,关于此种映射的处理方式本文就不进行分析了。下面我将详细分析简单映射的处理逻辑,如下:
private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap,
ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {
DefaultResultContext<Object> resultContext = new DefaultResultContext<Object>();
skipRows(rsw.getResultSet(), rowBounds);
while (shouldProcessMoreRows(resultContext, rowBounds) && rsw.getResultSet().next()) {
ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(rsw.getResultSet(), resultMap, null);
Object rowValue = getRowValue(rsw, discriminatedResultMap);
storeObject(resultHandler, resultContext, rowValue, parentMapping, rsw.getResultSet());
}
}
上面方法的逻辑较多,这里简单总结一下。如下:
- 根据 RowBounds 定位到指定行记录
- 循环处理多行数据
- 使用鉴别器处理 ResultMap
- 映射 ResultSet,得到映射结果 rowValue
- 存储结果
在如上几个步骤中,鉴别器相关的逻辑就不分析了,不是很常用。第2步的检测逻辑比较简单,就不分析了。下面分析第一个步骤对应的代码逻辑。如下:
private void skipRows(ResultSet rs, RowBounds rowBounds) throws SQLException {
if (rs.getType() != ResultSet.TYPE_FORWARD_ONLY) {
if (rowBounds.getOffset() != RowBounds.NO_ROW_OFFSET) {
rs.absolute(rowBounds.getOffset());
}
} else {
for (int i = 0; i < rowBounds.getOffset(); i++) {
rs.next();
}
}
}
MyBatis 默认提供了 RowBounds 用于分页,从上面的代码中可以看出,这并非是一个高效的分页方式。除了使用 RowBounds,还可以使用一些第三方分页插件进行分页。关于第三方的分页插件,大家请自行查阅资料,这里就不展开说明了。下面分析一下 ResultSet 的映射过程,如下:
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap) throws SQLException {
final ResultLoaderMap lazyLoader = new ResultLoaderMap();
Object rowValue = createResultObject(rsw, resultMap, lazyLoader, null);
if (rowValue != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {
final MetaObject metaObject = configuration.newMetaObject(rowValue);
boolean foundValues = this.useConstructorMappings;
if (shouldApplyAutomaticMappings(resultMap, false)) {
foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, null) || foundValues;
}
foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, null) || foundValues;
foundValues = lazyLoader.size() > 0 || foundValues;
rowValue = foundValues || configuration.isReturnInstanceForEmptyRow() ? rowValue : null;
}
return rowValue;
}
在上面的方法中,重要的逻辑已经注释出来了。分别如下:
- 创建实体类对象
- 检测结果集是否需要自动映射,若需要则进行自动映射
- 按 中配置的映射关系进行映射
这三处代码的逻辑比较复杂,接下来按顺序进行分节说明。首先分析实体类的创建过程。
2.2.6.1 创建实体类对象
在我们的印象里,创建实体类对象是一个很简单的过程。直接通过 new 关键字,或通过反射即可完成任务。大家可能会想,把这么简单过程也拿出来说说,怕是有凑字数的嫌疑。实则不然,MyBatis 的维护者写了不少逻辑,以保证能成功创建实体类对象。如果实在无法创建,则抛出异常。下面我们来看一下 MyBatis 创建实体类对象的过程。
private Object createResultObject(ResultSetWrapper rsw, ResultMap resultMap, ResultLoaderMap lazyLoader, String columnPrefix) throws SQLException {
this.useConstructorMappings = false;
final List<Class<?>> constructorArgTypes = new ArrayList<Class<?>>();
final List<Object> constructorArgs = new ArrayList<Object>();
Object resultObject = createResultObject(rsw, resultMap, constructorArgTypes, constructorArgs, columnPrefix);
if (resultObject != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {
final List<ResultMapping> propertyMappings = resultMap.getPropertyResultMappings();
for (ResultMapping propertyMapping : propertyMappings) {
if (propertyMapping.getNestedQueryId() != null && propertyMapping.isLazy()) {
resultObject = configuration.getProxyFactory()
.createProxy(resultObject, lazyLoader, configuration, objectFactory, constructorArgTypes, constructorArgs);
break;
}
}
}
this.useConstructorMappings =
resultObject != null && !constructorArgTypes.isEmpty();
return resultObject;
}
如上,创建实体类对象的过程被封装在了 createResultObject 的重载方法中了,关于该方法,待会再分析。创建完实体类对后,还需要对 中配置的映射信息进行检测。若发现有关联查询,且关联查询结果的加载方式为延迟加载,此时需为实体类生成代理类。举个例子说明一下,假设有如下两个实体类:
public class Author {
private Integer id;
private String name;
private Integer age;
private Integer sex;
}
public class Article {
private Integer id;
private String title;
private Author author;
private String content;
}
如上,Article 对象中的数据由一条 SQL 从 article 表中查询。Article 类有一个 author 字段,该字段的数据由另一条 SQL 从 author 表中查出。我们在将 article 表的查询结果填充到 Article 类对象中时,并不希望 MyBaits 立即执行另一条 SQL 查询 author 字段对应的数据。而是期望在我们调用 article.getAuthor() 方法时,MyBaits 再执行另一条 SQL 从 author 表中查询出所需的数据。若如此,我们需要改造 getAuthor 方法,以保证调用该方法时可让 MyBaits 执行相关的 SQL。关于延迟加载后面将会进行详细的分析,这里先说这么多。下面分析 createResultObject 重载方法的逻辑,如下:
private Object createResultObject(ResultSetWrapper rsw, ResultMap resultMap, List<Class<?>> constructorArgTypes, List<Object> constructorArgs, String columnPrefix) throws SQLException {
final Class<?> resultType = resultMap.getType();
final MetaClass metaType = MetaClass.forClass(resultType, reflectorFactory);
final List<ResultMapping> constructorMappings = resultMap.getConstructorResultMappings();
if (hasTypeHandlerForResultObject(rsw, resultType)) {
return createPrimitiveResultObject(rsw, resultMap, columnPrefix);
} else if (!constructorMappings.isEmpty()) {
return createParameterizedResultObject(rsw, resultType, constructorMappings, constructorArgTypes, constructorArgs, columnPrefix);
} else if (resultType.isInterface() || metaType.hasDefaultConstructor()) {
return objectFactory.create(resultType);
} else if (shouldApplyAutomaticMappings(resultMap, false)) {
return createByConstructorSignature(rsw, resultType, constructorArgTypes, constructorArgs, columnPrefix);
}
throw new ExecutorException("Do not know how to create an instance of " + resultType);
}
如上,createResultObject 方法中包含了4种创建实体类对象的方式。一般情况下,若无特殊要求,MyBatis 会通过 ObjectFactory 调用默认构造方法创建实体类对象。ObjectFactory 是一个接口,大家可以实现这个接口,以按照自己的逻辑控制对象的创建过程。到此,实体类对象已经创建好了,接下里要做的事情是将结果集中的数据映射到实体类对象中。
2.2.6.2 结果集映射
在 MyBatis 中,结果集自动映射有三种等级。三种等级官方文档上有所说明,这里直接引用一下。如下:
NONE- 禁用自动映射。仅设置手动映射属性PARTIAL- 将自动映射结果除了那些有内部定义内嵌结果映射的(joins)FULL- 自动映射所有
除了以上三种等级,我们还可以显示配置 节点的 autoMapping 属性,以启用或者禁用指定 ResultMap 的自定映射设定。下面,来看一下自动映射相关的逻辑。
private boolean shouldApplyAutomaticMappings(ResultMap resultMap, boolean isNested) {
if (resultMap.getAutoMapping() != null) {
return resultMap.getAutoMapping();
} else {
if (isNested) {
return AutoMappingBehavior.FULL == configuration.getAutoMappingBehavior();
} else {
return AutoMappingBehavior.NONE != configuration.getAutoMappingBehavior();
}
}
}
如上,shouldApplyAutomaticMappings 方法用于检测是否应为当前结果集应用自动映射。检测结果取决于 节点的 autoMapping 属性,以及全局自动映射行为。上面代码的逻辑不难理解,就不多说了。接下来分析 MyBatis 如何进行自动映射。
private boolean applyAutomaticMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, String columnPrefix) throws SQLException {
List<UnMappedColumnAutoMapping> autoMapping = createAutomaticMappings(rsw, resultMap, metaObject, columnPrefix);
boolean foundValues = false;
if (!autoMapping.isEmpty()) {
for (UnMappedColumnAutoMapping mapping : autoMapping) {
final Object value = mapping.typeHandler.getResult(rsw.getResultSet(), mapping.column);
if (value != null) {
foundValues = true;
}
if (value != null || (configuration.isCallSettersOnNulls() && !mapping.primitive)) {
metaObject.setValue(mapping.property, value);
}
}
}
return foundValues;
}
applyAutomaticMappings 方法的代码不多,逻辑也不是很复杂。首先是获取 UnMappedColumnAutoMapping 集合,然后遍历该集合,并通过 TypeHandler 从结果集中获取数据,最后再将获取到的数据设置到实体类对象中。虽然逻辑上看起来没什么复杂的东西,但如果不清楚 UnMappedColumnAutoMapping 的用途,是无法理解上面代码的逻辑的。所以下面简单介绍一下 UnMappedColumnAutoMapping 的用途。
UnMappedColumnAutoMapping 用于记录未配置在 节点中的映射关系。该类定义在 DefaultResultSetHandler 内部,它的代码如下:
private static class UnMappedColumnAutoMapping {
private final String column;
private final String property;
private final TypeHandler<?> typeHandler;
private final boolean primitive;
public UnMappedColumnAutoMapping(String column, String property, TypeHandler<?> typeHandler, boolean primitive) {
this.column = column;
this.property = property;
this.typeHandler = typeHandler;
this.primitive = primitive;
}
}
如上,以上就是 UnMappedColumnAutoMapping 类的所有代码,没什么逻辑,仅用于记录映射关系。下面看一下获取 UnMappedColumnAutoMapping 集合的过程,如下:
private List<UnMappedColumnAutoMapping> createAutomaticMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, String columnPrefix) throws SQLException {
final String mapKey = resultMap.getId() + ":" + columnPrefix;
List<UnMappedColumnAutoMapping> autoMapping = autoMappingsCache.get(mapKey);
if (autoMapping == null) {
autoMapping = new ArrayList<UnMappedColumnAutoMapping>();
final List<String> unmappedColumnNames = rsw.getUnmappedColumnNames(resultMap, columnPrefix);
for (String columnName : unmappedColumnNames) {
String propertyName = columnName;
if (columnPrefix != null && !columnPrefix.isEmpty()) {
if (columnName.toUpperCase(Locale.ENGLISH).startsWith(columnPrefix)) {
propertyName = columnName.substring(columnPrefix.length());
} else {
continue;
}
}
final String property = metaObject.findProperty(propertyName, configuration.isMapUnderscoreToCamelCase());
if (property != null && metaObject.hasSetter(property)) {
if (resultMap.getMappedProperties().contains(property)) {
continue;
}
final Class<?> propertyType = metaObject.getSetterType(property);
if (typeHandlerRegistry.hasTypeHandler(propertyType, rsw.getJdbcType(columnName))) {
final TypeHandler<?> typeHandler = rsw.getTypeHandler(propertyType, columnName);
autoMapping.add(new UnMappedColumnAutoMapping(columnName, property, typeHandler, propertyType.isPrimitive()));
} else {
configuration.getAutoMappingUnknownColumnBehavior()
.doAction(mappedStatement, columnName, property, propertyType);
}
} else {
configuration.getAutoMappingUnknownColumnBehavior()
.doAction(mappedStatement, columnName, (property != null) ? property : propertyName, null);
}
}
autoMappingsCache.put(mapKey, autoMapping);
}
return autoMapping;
}
上面的代码有点多,不过不用太担心,耐心看一下,还是可以看懂的。下面我来总结一下这个方法的逻辑。
- 从 ResultSetWrapper 中获取未配置在 中的列名
- 遍历上一步获取到的列名列表
- 若列名包含列名前缀,则移除列名前缀,得到属性名
- 将下划线形式的列名转成驼峰式
- 获取属性类型
- 获取类型处理器
- 创建 UnMappedColumnAutoMapping 实例
以上步骤中,除了第一步,其他都是常规操作,无需过多说明。下面来分析第一个步骤的逻辑,如下:
public List<String> getUnmappedColumnNames(ResultMap resultMap, String columnPrefix) throws SQLException {
List<String> unMappedColumnNames = unMappedColumnNamesMap.get(getMapKey(resultMap, columnPrefix));
if (unMappedColumnNames == null) {
loadMappedAndUnmappedColumnNames(resultMap, columnPrefix);
unMappedColumnNames = unMappedColumnNamesMap.get(getMapKey(resultMap, columnPrefix));
}
return unMappedColumnNames;
}
private void loadMappedAndUnmappedColumnNames(ResultMap resultMap, String columnPrefix) throws SQLException {
List<String> mappedColumnNames = new ArrayList<String>();
List<String> unmappedColumnNames = new ArrayList<String>();
final String upperColumnPrefix = columnPrefix == null ? null : columnPrefix.toUpperCase(Locale.ENGLISH);
final Set<String> mappedColumns = prependPrefixes(resultMap.getMappedColumns(), upperColumnPrefix);
for (String columnName : columnNames) {
final String upperColumnName = columnName.toUpperCase(Locale.ENGLISH);
if (mappedColumns.contains(upperColumnName)) {
mappedColumnNames.add(upperColumnName);
} else {
unmappedColumnNames.add(columnName);
}
}
mappedColumnNamesMap.put(getMapKey(resultMap, columnPrefix), mappedColumnNames);
unMappedColumnNamesMap.put(getMapKey(resultMap, columnPrefix), unmappedColumnNames);
}
如上,已映射列名与未映射列名的分拣逻辑并不复杂。我简述一下这个逻辑,首先是从当前数据集中获取列名集合,然后获取 中配置的列名集合。之后遍历数据集中的列名集合,并判断列名是否被配置在了 节点中。若配置了,则表明该列名已有映射关系,此时该列名存入 mappedColumnNames 中。若未配置,则表明列名未与实体类的某个字段形成映射关系,此时该列名存入 unmappedColumnNames 中。这样,列名的分拣工作就完成了。分拣过程示意图如下:
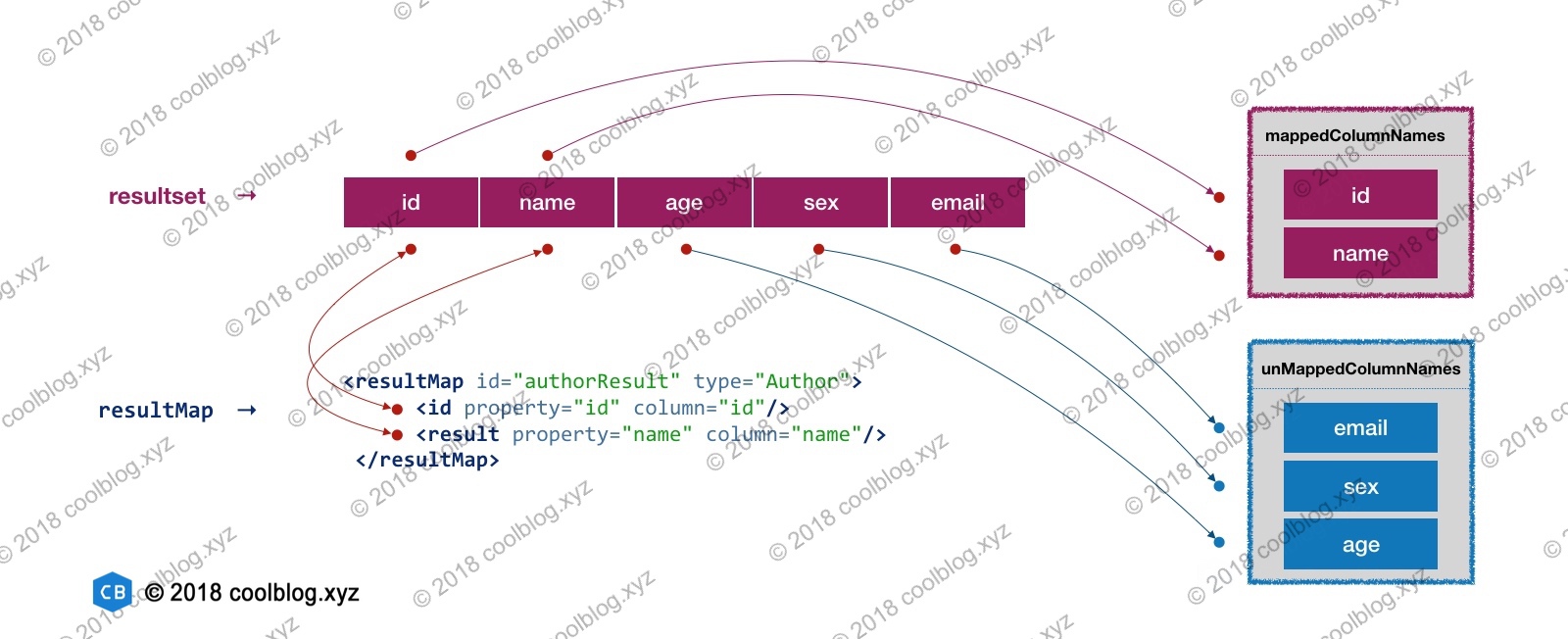
如上图所示,实体类 Author 的 id 和 name 字段与列名 id 和 name 被配置在了 中,它们之间形成了映射关系。列名 age、sex 和 email 未配置在 中,因此未与 Author 中的字段形成映射,所以他们最终都被放入了 unMappedColumnNames 集合中。弄懂了未映射列名获取的过程,自动映射的代码逻辑就不难懂了。好了,关于自动映射的分析就先到这,接下来分析一下 MyBatis 是如何将结果集中的数据填充到已映射的实体类字段中的。
private boolean applyPropertyMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject,ResultLoaderMap lazyLoader, String columnPrefix) throws SQLException {
final List<String> mappedColumnNames = rsw.getMappedColumnNames(resultMap, columnPrefix);
boolean foundValues = false;
final List<ResultMapping> propertyMappings = resultMap.getPropertyResultMappings();
for (ResultMapping propertyMapping : propertyMappings) {
String column = prependPrefix(propertyMapping.getColumn(), columnPrefix);
if (propertyMapping.getNestedResultMapId() != null) {
column = null;
}
if (propertyMapping.isCompositeResult()
|| (column != null && mappedColumnNames.contains(column.toUpperCase(Locale.ENGLISH)))
|| propertyMapping.getResultSet() != null) {
Object value = getPropertyMappingValue(rsw.getResultSet(), metaObject, propertyMapping, lazyLoader, columnPrefix);
final String property = propertyMapping.getProperty();
if (property == null) {
continue;
} else if (value == DEFERED) {
foundValues = true;
continue;
}
if (value != null) {
foundValues = true;
}
if (value != null || (configuration.isCallSettersOnNulls() && !metaObject.getSetterType(property)
.isPrimitive())) {
metaObject.setValue(property, value);
}
}
}
return foundValues;
}
private Object getPropertyMappingValue(ResultSet rs, MetaObject metaResultObject, ResultMapping propertyMapping,ResultLoaderMap lazyLoader, String columnPrefix) throws SQLException {
if (propertyMapping.getNestedQueryId() != null) {
return getNestedQueryMappingValue(rs, metaResultObject, propertyMapping, lazyLoader, columnPrefix);
} else if (propertyMapping.getResultSet() != null) {
addPendingChildRelation(rs, metaResultObject, propertyMapping);
return DEFERED;
} else {
final TypeHandler<?> typeHandler = propertyMapping.getTypeHandler();
final String column = prependPrefix(propertyMapping.getColumn(), columnPrefix);
return typeHandler.getResult(rs, column);
}
}
如上,applyPropertyMappings 方法首先从 ResultSetWrapper 中获取已映射列名集合 mappedColumnNames,从 ResultMap 获取映射对象 ResultMapping 集合。然后遍历 ResultMapping 集合,再此过程中调用 getPropertyMappingValue 获取指定指定列的数据,最后将获取到的数据设置到实体类对象中。到此,基本的结果集映射过程就分析完了。
结果集映射相关的代码比较多,结果集的映射过程比较复杂的,需要一定的耐心去阅读和理解代码。好了,稍作休息,稍后分析关联查询相关的逻辑。
2.2.6.3 关联查询与延迟加载
我们在学习 MyBatis 框架时,会经常碰到一对一,一对多的使用场景。对于这样的场景,通常我们可以用一条 SQL 进行多表查询完成任务。当然我们也可以使用关联查询,将一条 SQL 拆成两条去完成查询任务。MyBatis 提供了两个标签用于支持一对一和一对多的使用场景,分别是 和 。下面我来演示一下如何使用 完成一对一的关联查询。先来看看实体类的定义:
public class Author {
private Integer id;
private String name;
private Integer age;
private Integer sex;
private String email;
}
public class Article {
private Integer id;
private String title;
private Author author;
private String content;
private Date createTime;
}
相关表记录如下:

接下来看一下 Mapper 接口与映射文件的定义。
public interface ArticleDao {
Article findOne(@Param("id") int id);
Author findAuthor(@Param("id") int authorId);
}
<mapper namespace="xyz.coolblog.dao.ArticleDao">
<resultMap id="articleResult" type="Article">
<result property="createTime" column="create_time"/>
<association property="author" column="author_id" javaType="Author" select="findAuthor"/>
</resultMap>
<select id="findOne" resultMap="articleResult">
SELECT
id, author_id, title, content, create_time
FROM
article
WHERE
id = #{id}
</select>
<select id="findAuthor" resultType="Author">
SELECT
id, name, age, sex, email
FROM
author
WHERE
id = #{id}
</select>
</mapper>
好了,必要在的准备工作做完了,下面可以写测试代码了。如下:
public class OneToOneTest {
private SqlSessionFactory sqlSessionFactory;
@Before
public void prepare() throws IOException {
String resource = "mybatis-one-to-one-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
inputStream.close();
}
@Test
public void testOne2One() {
SqlSession session = sqlSessionFactory.openSession();
try {
ArticleDao articleDao = session.getMapper(ArticleDao.class);
Article article = articleDao.findOne(1);
Author author = article.getAuthor();
article.setAuthor(null);
System.out.println("\narticles info:");
System.out.println(article);
System.out.println("\nauthor info:");
System.out.println(author);
} finally {
session.close();
}
}
}
测试结果如下:

如上,从上面的输出结果中可以看出,我们在调用 ArticleDao 的 findOne 方法时,MyBatis 执行了两条 SQL,完成了一对一的查询需求。理解了上面的例子后,下面就可以深入到源码中,看看 MyBatis 是如何实现关联查询的。接下里从 getNestedQueryMappingValue 方法开始分析,如下:
private Object getNestedQueryMappingValue(ResultSet rs, MetaObject metaResultObject, ResultMapping propertyMapping, ResultLoaderMap lazyLoader, String columnPrefix) throws SQLException {
final String nestedQueryId = propertyMapping.getNestedQueryId();
final String property = propertyMapping.getProperty();
final MappedStatement nestedQuery = configuration.getMappedStatement(nestedQueryId);
final Class<?> nestedQueryParameterType = nestedQuery.getParameterMap().getType();
final Object nestedQueryParameterObject = prepareParameterForNestedQuery(rs, propertyMapping, nestedQueryParameterType, columnPrefix);
Object value = null;
if (nestedQueryParameterObject != null) {
final BoundSql nestedBoundSql = nestedQuery.getBoundSql(nestedQueryParameterObject);
final CacheKey key = executor.createCacheKey(nestedQuery, nestedQueryParameterObject, RowBounds.DEFAULT, nestedBoundSql);
final Class<?> targetType = propertyMapping.getJavaType();
if (executor.isCached(nestedQuery, key)) {
executor.deferLoad(nestedQuery, metaResultObject, property, key, targetType);
value = DEFERED;
} else {
final ResultLoader resultLoader = new ResultLoader(configuration, executor, nestedQuery, nestedQueryParameterObject, targetType, key, nestedBoundSql);
if (propertyMapping.isLazy()) {
lazyLoader.addLoader(property, metaResultObject, resultLoader);
value = DEFERED;
} else {
value = resultLoader.loadResult();
}
}
}
return value;
}
如上,上面对关联查询进行了比较多的注释,导致该方法看起来有点复杂。当然,真实的逻辑确实有点复杂,因为它还调用了其他的很多方法。下面先来总结一下该方法的逻辑:
- 根据 nestedQueryId 获取 MappedStatement
- 生成参数对象
- 获取 BoundSql
- 检测一级缓存中是否有关联查询的结果,若有,则将结果设置到实体类对象中
- 若一级缓存未命中,则创建结果加载器 ResultLoader
- 检测当前属性是否需要进行延迟加载,若需要,则添加延迟加载相关的对象到 loaderMap 集合中
- 如不需要延迟加载,则直接通过结果加载器加载结果
如上,getNestedQueryMappingValue 的中逻辑多是都是和延迟加载有关。除了延迟加载,以上流程中针对一级缓存的检查是十分有必要的,若缓存命中,可直接取用结果,无需再在执行关联查询 SQL。若缓存未命中,接下来就要按部就班执行延迟加载相关逻辑,接下来,分析一下 MyBatis 延迟加载是如何实现的。首先我们来看一下添加延迟加载相关对象到 loaderMap 集合中的逻辑,如下:
public void addLoader(String property, MetaObject metaResultObject, ResultLoader resultLoader) {
String upperFirst = getUppercaseFirstProperty(property);
if (!upperFirst.equalsIgnoreCase(property) && loaderMap.containsKey(upperFirst)) {
throw new ExecutorException("Nested lazy loaded result property '" + property +
"' for query id '" + resultLoader.mappedStatement.getId() +
" already exists in the result map. The leftmost property of all lazy loaded properties must be unique within a result map.");
}
loaderMap.put(upperFirst, new LoadPair(property, metaResultObject, resultLoader));
}
如上,addLoader 方法的参数最终都传给了 LoadPair,该类的 load 方法会在内部调用 ResultLoader 的 loadResult 方法进行关联查询,并通过 metaResultObject 将查询结果设置到实体类对象中。那 LoadPair 的 load 方法由谁调用呢?答案是实体类的代理对象。下面我们修改一下上面示例中的部分代码,演示一下延迟加载。首先,我们需要在 MyBatis 配置文件的 节点中加入或覆盖如下配置:
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="aggressiveLazyLoading" value="false"/>
<setting name="lazyLoadTriggerMethods" value="equals,hashCode"/>
上面三个配置 MyBatis 官方文档中有较为详细的介绍,大家可以参考官方文档,我就不详细介绍了。下面修改一下测试类的代码:
public class OneToOneTest {
private SqlSessionFactory sqlSessionFactory;
@Before
public void prepare() throws IOException {...}
@Test
public void testOne2One() {
SqlSession session = sqlSessionFactory.openSession();
try {
ArticleDao articleDao = session.getMapper(ArticleDao.class);
Article article = articleDao.findOne(1);
System.out.println("\narticles info:");
System.out.println(article);
System.out.println("\n延迟加载 author 字段:");
Author author = article.getAuthor();
System.out.println("\narticles info:");
System.out.println(article);
System.out.println("\nauthor info:");
System.out.println(author);
} finally {
session.close();
}
}
}
测试结果如下:
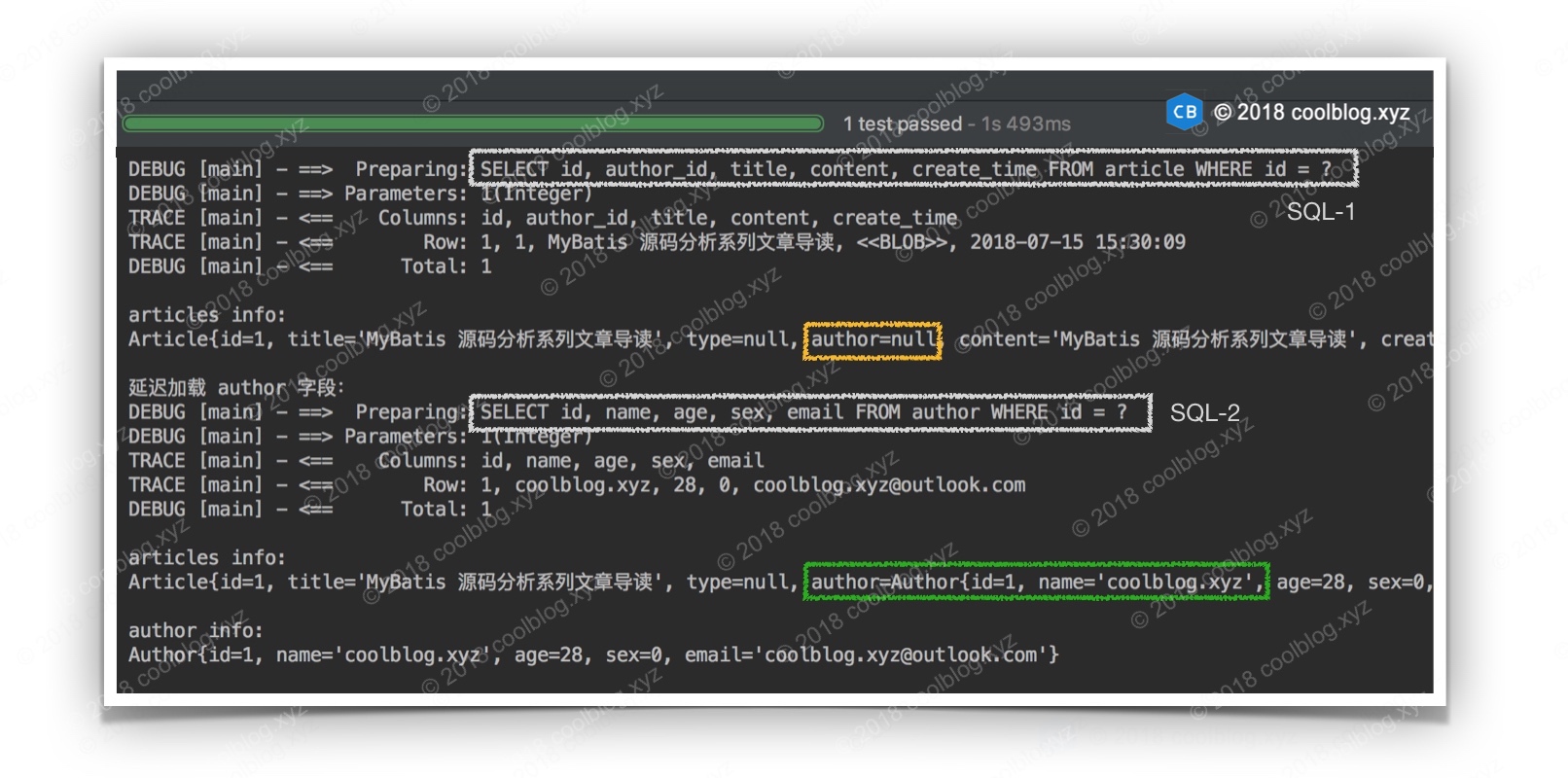
从上面结果中可以看出,我们在未调用 getAuthor 方法时,Article 对象中的 author 字段为 null。调用该方法后,再次输出 Article 对象,发现其 author 字段有值了,表明 author 字段的延迟加载逻辑被触发了。既然调用 getAuthor 可以触发延迟加载,那么该方法一定被做过手脚了,不然该方法应该返回 null 才是。如果大家还记得 2.2.6.1 节中的内容,大概就知道是怎么回事了 - MyBatis 会为需要延迟加载的类生成代理类,代理逻辑会拦截实体类的方法调用。默认情况下,MyBatis 会使用 Javassist 为实体类生成代理,代理逻辑封装在 JavassistProxyFactory 类中,下面一起看一下。
public Object invoke(Object enhanced, Method method, Method methodProxy, Object[] args) throws Throwable {
final String methodName = method.getName();
try {
synchronized (lazyLoader) {
if (WRITE_REPLACE_METHOD.equals(methodName)) {
} else {
if (lazyLoader.size() > 0 && !FINALIZE_METHOD.equals(methodName)) {
if (aggressive || lazyLoadTriggerMethods.contains(methodName)) {
lazyLoader.loadAll();
} else if (PropertyNamer.isSetter(methodName)) {
final String property = PropertyNamer.methodToProperty(methodName);
lazyLoader.remove(property);
} else if (PropertyNamer.isGetter(methodName)) {
final String property = PropertyNamer.methodToProperty(methodName);
if (lazyLoader.hasLoader(property)) {
lazyLoader.load(property);
}
}
}
}
}
return methodProxy.invoke(enhanced, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
如上,代理方法首先会检查 aggressive 是否为 true,如果不满足,再去检查 lazyLoadTriggerMethods 是否包含当前方法名。这里两个条件只要一个为 true,当前实体类中所有需要延迟加载。aggressive 和 lazyLoadTriggerMethods 两个变量的值取决于下面的配置。
<setting name="aggressiveLazyLoading" value="false"/>
<setting name="lazyLoadTriggerMethods" value="equals,hashCode"/>
现在大家知道上面两个配置是如何在代码中使用的了,比较简单,就不多说了。
回到上面的代码中,如果执行线程未进入第一个条件分支,那么紧接着,代理逻辑会检查使用者是不是调用了实体类的 setter 方法,如果调用了,就将该属性对应的 LoadPair 从 loaderMap 中移除。为什么要这么做呢?答案是:使用者既然手动调用 setter 方法,说明使用者想自定义某个属性的值。此时,延迟加载逻辑不应该再修改该属性的值,所以这里从 loaderMap 中移除属性对于的 LoadPair。
最后如果使用者调用的是某个属性的 getter 方法,且该属性配置了延迟加载,此时延迟加载逻辑就会被触发。那接下来,我们来看看延迟加载逻辑是怎样实现的的。
public boolean load(String property) throws SQLException {
LoadPair pair = loaderMap.remove(property.toUpperCase(Locale.ENGLISH));
if (pair != null) {
pair.load();
return true;
}
return false;
}
public void load() throws SQLException {
if (this.metaResultObject == null) {
throw new IllegalArgumentException("metaResultObject is null");
}
if (this.resultLoader == null) {
throw new IllegalArgumentException("resultLoader is null");
}
this.load(null);
}
public void load(final Object userObject) throws SQLException {
if (this.metaResultObject == null || this.resultLoader == null) {...}
if (this.serializationCheck == null) {
final ResultLoader old = this.resultLoader;
this.resultLoader = new ResultLoader(old.configuration, new ClosedExecutor(), old.mappedStatement, old.parameterObject, old.targetType, old.cacheKey, old.boundSql);
}
this.metaResultObject.setValue(property, this.resultLoader.loadResult());
}
上面的代码比较多,但是没什么特别的逻辑,我们重点关注最后一行有效代码就行了。下面看一下 ResultLoader 的 loadResult 方法逻辑是怎样的。
public Object loadResult() throws SQLException {
List<Object> list = selectList();
resultObject = resultExtractor.extractObjectFromList(list, targetType);
return resultObject;
}
private <E> List<E> selectList() throws SQLException {
Executor localExecutor = executor;
if (Thread.currentThread().getId() != this.creatorThreadId || localExecutor.isClosed()) {
localExecutor = newExecutor();
}
try {
return localExecutor.<E>query(mappedStatement, parameterObject, RowBounds.DEFAULT,
Executor.NO_RESULT_HANDLER, cacheKey, boundSql);
} finally {
if (localExecutor != executor) {
localExecutor.close(false);
}
}
}
如上,我们在 ResultLoader 中终于看到了执行关联查询的代码,即 selectList 方法中的逻辑。该方法在内部通过 Executor 进行查询。至于查询结果的抽取过程,并不是本节所关心的点,因此大家自行分析吧。到此,关于关联查询与延迟加载就分析完了。最后我们来看一下映射结果的存储过程是怎样的。
2.2.6.4 存储映射结果
存储映射结果是“查询结果”处理流程中的最后一环,实际上也是查询语句执行过程的最后一环。本节内容分析完,整个查询过程就分析完了,那接下来让我们带着喜悦的心情来分析映射结果存储逻辑。
private void storeObject(ResultHandler<?> resultHandler, DefaultResultContext<Object> resultContext,Object rowValue, ResultMapping parentMapping, ResultSet rs) throws SQLException {
if (parentMapping != null) {
linkToParents(rs, parentMapping, rowValue);
} else {
callResultHandler(resultHandler, resultContext, rowValue);
}
}
private void callResultHandler(ResultHandler<?> resultHandler, DefaultResultContext<Object> resultContext, Object rowValue) {
resultContext.nextResultObject(rowValue);
((ResultHandler<Object>) resultHandler).handleResult(resultContext);
}
如上,上面方法显示将 rowValue 设置到 ResultContext 中,然后再将 ResultContext 对象作为参数传给 ResultHandler 的 handleResult 方法。下面我们分别看一下 ResultContext 和 ResultHandler 的实现类。如下:
public class DefaultResultContext<T> implements ResultContext<T> {
private T resultObject;
private int resultCount;
private boolean stopped;
@Override
public boolean isStopped() {
return stopped;
}
public void nextResultObject(T resultObject) {
resultCount++;
this.resultObject = resultObject;
}
@Override
public void stop() {
this.stopped = true;
}
}
如上,DefaultResultContext 中包含了一个状态字段,表明结果上下文的状态。在处理多行数据时,MyBatis 会检查该字段的值,已决定是否需要进行后续的处理。该类的逻辑比较简单,不多说了。下面再来看一下 DefaultResultHandler 的源码。
public class DefaultResultHandler implements ResultHandler<Object> {
private final List<Object> list;
public DefaultResultHandler() {
list = new ArrayList<Object>();
}
@Override
public void handleResult(ResultContext<? extends Object> context) {
list.add(context.getResultObject());
}
public List<Object> getResultList() {
return list;
}
}
如上,DefaultResultHandler 默认使用 List 存储结果。除此之外,如果 Mapper (或 Dao)接口方法返回值为 Map 类型,此时则需要另一种 ResultHandler 实现类处理结果,即 DefaultMapResultHandler。关于 DefaultMapResultHandler 的源码大家自行分析吧啊,本节就不展开了。
2.3 更新语句的执行过程分析
在上一节中,我较为完整的分析了查询语句的执行过程。尽管有些地方一笔带过了,但多数细节都分析到了。如果大家搞懂了查询语句的执行过程,那么理解更新语句的执行过程也将不在话下。执行更新语句所需处理的情况较之查询语句要简单不少,两者最大的区别更新语句的执行结果类型单一,处理逻辑要简单不是。除此之外,两者在缓存的处理上也有比较大的区别。更新过程会立即刷新缓存,而查询过程则不会。至于其他的不同点,就不一一列举了。下面开始分析更新语句的执行过程。
2.3.1 更新语句执行过程全貌
首先,我们还是从 MapperMethod 的 execute 方法开始看起。
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
switch (command.getType()) {
case INSERT: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT:
break;
case FLUSH:
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {...}
return result;
}
如上,插入、更新以及删除操作最终都调用了 SqlSession 接口中的方法。这三个方法返回值均是受影响行数,是一个整型值。rowCountResult 方法负责处理这个整型值,该方法的逻辑暂时先不分析,放在最后分析。接下来,我们往下层走一步,进入 SqlSession 实现类 DefaultSqlSession 的代码中。
public int insert(String statement, Object parameter) {
return update(statement, parameter);
}
public int delete(String statement, Object parameter) {
return update(statement, parameter);
}
public int update(String statement, Object parameter) {
try {
dirty = true;
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.update(ms, wrapCollection(parameter));
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error updating database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
如上,insert 和 delete 方法最终都调用了同一个 update 方法,这就是为什么我把他们归为一类的原因。既然它们最终调用的都是同一个方法,那么MyBatis 为什么还要在 SqlSession 中提供这么多方法呢,难道只提供 update 方法不行么?答案是:只提供一个 update 方法从实现上完全可行,但是从接口的语义化的角度来说,这样做并不好。一般情况下,使用者觉得 update 接口方法应该仅负责执行 UPDATE 语句,如果它还兼职执行其他的 SQL 语句,会让使用者产生疑惑。对于对外的接口,接口功能越单一,语义越清晰越好。在日常开发中,我们为客户端提供接口时,也应该这样做。比如我之前写过一个文章评论的开关接口,我写的接口如下:
Result openComment();
Result closeComment();
上面接口语义比较清晰,同时没有参数,后端不用校验参数,客户端同学也不用思考传什么值。如果我像下面这样定义接口:
Result updateCommentStatus(Integer status);
首先这个方法没有上面两个方法语义清晰,其次需要传入一个整型状态值,客户端需要注意传值,后端也要进行校验。好了,关于接口语义化就先说这么多。扯多了,回归正题,下面分析 Executor 的 update 方法。如下:
public int update(MappedStatement ms, Object parameterObject) throws SQLException {
flushCacheIfRequired(ms);
return delegate.update(ms, parameterObject);
}
public int update(MappedStatement ms, Object parameter) throws SQLException {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
clearLocalCache();
return doUpdate(ms, parameter);
}
如上,Executor 实现类中的方法在进行下一步操作之前,都会先刷新各自的缓存。默认情况下,insert、update 和 delete 操作都会清空一二级缓存。清空缓存的逻辑不复杂,大家自行分析。下面分析 doUpdate 方法,该方法是一个抽象方法,因此我们到 BaseExecutor 的子类 SimpleExecutor 中看看该方法是如何实现的。
public int doUpdate(MappedStatement ms, Object parameter) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(this, ms, parameter, RowBounds.DEFAULT, null, null);
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.update(stmt);
} finally {
closeStatement(stmt);
}
}
StatementHandler 和 Statement 的创建过程前面已经分析过,这里就不重复分析了。下面分析 PreparedStatementHandler 的 update 方法。
public int update(Statement statement) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
int rows = ps.getUpdateCount();
Object parameterObject = boundSql.getParameterObject();
KeyGenerator keyGenerator = mappedStatement.getKeyGenerator();
keyGenerator.processAfter(executor, mappedStatement, ps, parameterObject);
return rows;
}
PreparedStatementHandler 的 update 方法的逻辑比较清晰明了了,更新语句的 SQL 会在此方法中被执行。执行结果为受影响行数,对于 insert 语句,有时候我们还想获取自增主键的值,因此我们需要进行一些额外的操作。这些额外操作的逻辑封装在 KeyGenerator 的实现类中,下面我们一起看一下 KeyGenerator 的实现逻辑。
2.3.2 KeyGenerator
KeyGenerator 是一个接口,目前它有三个实现类,分别如下:
- Jdbc3KeyGenerator
- SelectKeyGenerator
- NoKeyGenerator
Jdbc3KeyGenerator 用于获取插入数据后的自增主键数值。某些数据库不支持自增主键,需要手动填写主键字段,此时需要借助 SelectKeyGenerator 获取主键值。至于 NoKeyGenerator,这是一个空实现,没什么可说的。下面,我将分析 Jdbc3KeyGenerator 的源码,至于 SelectKeyGenerator,大家请自行分析。下面看源码吧。
public void processBefore(Executor executor, MappedStatement ms, Statement stmt, Object parameter) {
}
public void processAfter(Executor executor, MappedStatement ms, Statement stmt, Object parameter) {
processBatch(ms, stmt, getParameters(parameter));
}
public void processBatch(MappedStatement ms, Statement stmt, Collection<Object> parameters) {
ResultSet rs = null;
try {
rs = stmt.getGeneratedKeys();
final Configuration configuration = ms.getConfiguration();
final TypeHandlerRegistry typeHandlerRegistry = configuration.getTypeHandlerRegistry();
final String[] keyProperties = ms.getKeyProperties();
final ResultSetMetaData rsmd = rs.getMetaData();
TypeHandler<?>[] typeHandlers = null;
if (keyProperties != null && rsmd.getColumnCount() >= keyProperties.length) {
for (Object parameter : parameters) {
if (!rs.next()) {
break;
}
final MetaObject metaParam = configuration.newMetaObject(parameter);
if (typeHandlers == null) {
typeHandlers = getTypeHandlers(typeHandlerRegistry, metaParam, keyProperties, rsmd);
}
populateKeys(rs, metaParam, keyProperties, typeHandlers);
}
}
} catch (Exception e) {
throw new ExecutorException(...);
} finally {...}
}
private Collection<Object> getParameters(Object parameter) {
Collection<Object> parameters = null;
if (parameter instanceof Collection) {
parameters = (Collection) parameter;
} else if (parameter instanceof Map) {
Map parameterMap = (Map) parameter;
if (parameterMap.containsKey("collection")) {
parameters = (Collection) parameterMap.get("collection");
} else if (parameterMap.containsKey("list")) {
parameters = (List) parameterMap.get("list");
} else if (parameterMap.containsKey("array")) {
parameters = Arrays.asList((Object[]) parameterMap.get("array"));
}
}
if (parameters == null) {
parameters = new ArrayList<Object>();
parameters.add(parameter);
}
return parameters;
}
Jdbc3KeyGenerator 的 processBefore 方法是一个空方法,processAfter 则是一个空壳方法,只有一行代码。Jdbc3KeyGenerator 的重点在 processBatch 方法中,由于存在批量插入的情况,所以该方法的名字类包含 batch 单词,表示可处理批量插入的结果集。processBatch 方法的逻辑并不是很复杂,主要流程如下:
- 获取主键数组(keyProperties)
- 获取 ResultSet 元数据
- 遍历参数列表,为每个主键属性获取 TypeHandler
- 从 ResultSet 中获取主键数据,并填充到参数中
在上面流程中,第 1~3 步骤都是常规操作,第4个步骤需要分析一下。如下:
private void populateKeys(ResultSet rs, MetaObject metaParam, String[] keyProperties, TypeHandler<?>[] typeHandlers) throws SQLException {
for (int i = 0; i < keyProperties.length; i++) {
String property = keyProperties[i];
TypeHandler<?> th = typeHandlers[i];
if (th != null) {
Object value = th.getResult(rs, i + 1);
metaParam.setValue(property, value);
}
}
}
如上,populateKeys 方法首先是遍历主键数组,然后通过 TypeHandler 从 ResultSet 中获取自增主键的值,最后再通过元信息对象将自增主键的值设置到参数中。
以上就是 Jdbc3KeyGenerator 的原理分析,下面写个示例演示一下。
本次演示所用到的实体类如下:
public class Author {
private Integer id;
private String name;
private Integer age;
private Integer sex;
private String email;
}
Mapper 接口和映射文件内容如下:
public interface AuthorDao {
int insertMany(List<Author> authors);
}
<insert id="insertMany" keyProperty="id" useGeneratedKeys="true">
INSERT INTO
author (`name`, `age`, `sex`, `email`)
VALUES
<foreach item="author" index="index" collection="list" separator=",">
(#{author.name}, #{author.age}, #{author.sex}, #{author.email})
</foreach>
</insert>
测试代码如下:
public class InsertManyTest {
private SqlSessionFactory sqlSessionFactory;
@Before
public void prepare() throws IOException {
String resource = "mybatis-insert-many-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
inputStream.close();
}
@Test
public void testInsertMany() {
SqlSession session = sqlSessionFactory.openSession();
try {
List<Author> authors = new ArrayList<>();
authors.add(new Author("tianxiaobo-1", 20, 0, "coolblog.xyz@outlook.com"));
authors.add(new Author("tianxiaobo-2", 18, 0, "coolblog.xyz@outlook.com"));
System.out.println("\nBefore Insert: ");
authors.forEach(author -> System.out.println(" " + author));
System.out.println();
AuthorDao authorDao = session.getMapper(AuthorDao.class);
authorDao.insertMany(authors);
session.commit();
System.out.println("\nAfter Insert: ");
authors.forEach(author -> System.out.println(" " + author));
} finally {
session.close();
}
}
}
在测试代码中,我创建了一个 Author 集合,并向集合中插入了两个 Author 对象。然后将集合中的元素批量插入到 author 表中,得到如下结果:

如上图,执行插入语句前,列表中元素的 id 字段均为 null。插入数据后,列表元素中的 id 字段均被赋值了。好了,到此,关于 Jdbc3KeyGenerator 的原理与使用就分析完了。
2.3.3 处理更新结果
更新语句的执行结果是一个整型值,表示本次更新所影响的行数。由于返回值类型简单,因此处理逻辑也很简单。下面我们简单看一下,放松放松。
private Object rowCountResult(int rowCount) {
final Object result;
if (method.returnsVoid()) {
result = null;
} else if (Integer.class.equals(method.getReturnType()) || Integer.TYPE.equals(method.getReturnType())) {
result = rowCount;
} else if (Long.class.equals(method.getReturnType()) || Long.TYPE.equals(method.getReturnType())) {
result = (long) rowCount;
} else if (Boolean.class.equals(method.getReturnType()) || Boolean.TYPE.equals(method.getReturnType())) {
result = rowCount > 0;
} else {
throw new BindingException(...);
}
return result;
}
如上,MyBatis 对于更新语句的执行结果处理逻辑足够简单,很容易看懂,我就不多说了。
2.4 小节
经过前面前面的分析,相信大家对 MyBatis 执行 SQL 的过程都有比较深入的理解。本章的最后,用一张图 MyBatis 的执行过程进行一个总结。如下:
在 MyBatis 中,SQL 执行过程的实现代码是有层次的,每层都有相应的功能。比如,SqlSession 是对外接口的接口,因此它提供了各种语义清晰的方法,供使用者调用。Executor 层做的事情较多,比如一二级缓存功能就是嵌入在该层内的。StatementHandler 层主要是与 JDBC 层面的接口打交道。至于 ParameterHandler 和 ResultSetHandler,一个负责向 SQL 中设置运行时参数,另一个负责处理 SQL 执行结果,它们俩可以看做是 StatementHandler 辅助类。最后看一下右边横跨数层的类,Configuration 是一个全局配置类,很多地方都依赖它。MappedStatement 对应 SQL 配置,包含了 SQL 配置的相关信息。BoundSql 中包含了已完成解析的 SQL 语句,以及运行时参数等。
到此,关于 SQL 的执行过程就分析完了。内容比较多,希望大家耐心阅读。
3. 总结
到这里,本文就接近尾声了。本篇文章从本月的1号开始写,一直到16号才写完初稿。内容之多,完全超出我事先的预计。尽管本文篇幅很大,但仍有部分逻辑和细节没有分析到,比如 SelectKeyGenerator。对于这些内容,如果大家能耐心看完本文,并且仔细分析了 MyBatis 执行 SQL 的相关源码,那么对 MyBatis 的原理会有很深的理解。深入理解 MyBatis,对日常工作也会产生积极的影响。比如我现在就以随心所欲的写 SQL 映射文件,把不合理的配置统统删掉。如果遇到 MyBatis 层面的异常,也不用担心无法解决了。好了,一不小心又扯多了。本篇文章篇幅比较大,这其中可能存在这一些错误不妥之处。如果大家发现了,望指明,这里先说声谢谢。
好了,本文到此就结束了。感谢大家的阅读。
参考
- 《MyBatis 技术内幕》- 徐郡明
- MyBatis 官方文档
原文地址:https://www.cnblogs.com/nullllun/p/9503612.html
原文地址:https://blog.csdn.net/u012613251/article/details/137881694
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!