Title: 提升大型语言模型在知识图谱完成中的性能

基本信息
-
论文题目: Making Large Language Models Perform Better in Knowledge Graph Completion
-
作者: Yichi Zhang, Wen Zhang
-
机构: College of Computer Science and School of Software Technology, Zhejiang University
-
发表日期: 10 Oct 2023
-
arXiv ID: 2310.06671v1
摘要
本文探讨了如何将有用的知识图谱(KG)结构信息融入大型语言模型(LLM),以实现LLM中的结构感知推理。
研究发现,目前基于LLM的知识图谱补全(KGC)研究有限,它们往往忽视了KG中的重要结构信息。为了解决这个问题,本文首先将LLM转换为结构感知setting,然后提出了一种知识前缀适配器(KoPA)。
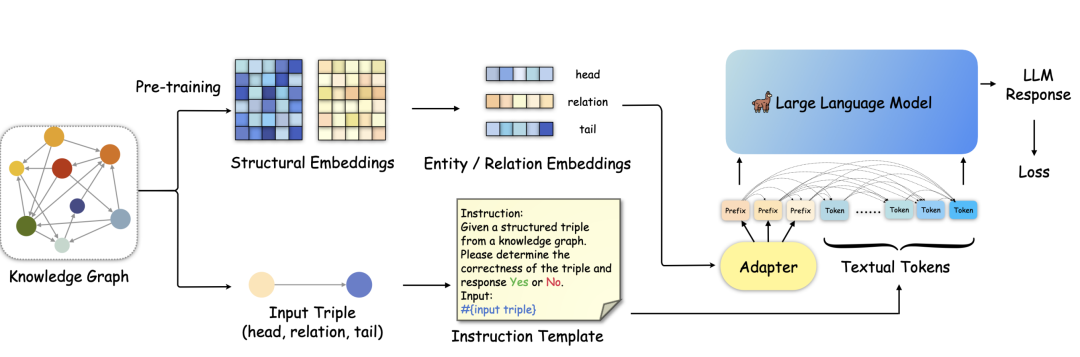
下面的图就是本文KoPA模型框架:一图胜千言,咱们一起来看看。KoPA是一个两阶段的基于LLM的KGC框架。首先对给定的KG中的实体和关系进行结构嵌入预训练(上面的支路)。然后,KoPA采用指令调优来微调LLM(下面支路)。
具体来说:给定输入三元组的结构嵌入将通过适配器投射到LLM的文本token空间,并作为输入提示序列前端的前缀串。通过解码器仅在LLM中的单向注意力机制,这些Token将被后续的文本Token所见,从而允许LLM在结构感知状态下解码指令的答案。
1 引言
Web规模的知识图谱(KGs)[22],如FreeBase [3]、YAGO [39]和WikiData [47],是现代全球网络的智慧精华和基础设施。KGs形成了一个语义网络,包含大量实体和关系,以三元形式(头实体、关系、尾实体)对现实世界的知识进行建模和存储。KGs中的结构化知识三元组为许多基本的基于Web的自动服务提供了重要优势,如推荐系统[42]、问答系统[60]和网络故障分析[11]。
然而,手动编辑或自动提取的KGs通常是不完整的,因为它们只包含观察到的知识,留下许多未发现的缺失三元组。这种现象促使了知识图谱完成(KGC)的研究,旨在预测给定KG中的缺失三元组。研究KGC任务将丰富KGs中包含的语义信息和现实世界知识,并更好地服务于Web系统和Web应用程序。
现有的KGC方法可以分为两类:基于嵌入的方法[4, 43, 46, 56]和预训练语言模型(PLM)[28, 58]。基于嵌入的方法旨在学习实体和关系的结构嵌入,而基于PLM的方法则将文本描述应用于区分三元组的合理性。最近,大型语言模型(LLMs)[31, 64]在广泛的任务中展示出卓越的能力[26, 31, 32]。一些工作[59, 69]迈出了基于LLM的KGC的第一步。这些工作采用现有的LLM范例,如零样本推理[5]和指令调整[32],来完成KGC任务。然而,这种方法将KGC任务转化为对单个三元组的基于文本的预测,导致了一些不可避免的问题。当前的基于LLM的KGC方法,如KGLLaMA [59],构建了简化的提示,并应用了基本的指令调整(IT)来微调LLMs。然而,LLMs对于准确而微妙的事实知识的记忆不足,经常导致幻觉[66]。此外,KGs具有复杂的结构信息,如子图结构、关系模式、相对实体/关系等。将这些结构信息整合到LLMs中对于开发对KG有全面理解的能力非常有利。然而,这被基本的IT所忽略,因为每个输入提示只包含单个输入三元组,无法为LLMs建立KG结构的意识,导致结构信息浪费。
为解决这些问题,我们进一步发展了基于LLM的KGC,旨在探索如何将KG结构信息整合到LLMs中,并实现结构感知的推理。我们首先讨论如何将现有的LLM范例,如上下文学习(ICL)[13]和指令调整(IT)[32],转移到结构感知的设置。我们提出了一种结构感知的ICL方法和一种结构感知的IT方法作为基础模型,重点是通过文本表示将KG结构信息整合到LLMs中。此外,我们提出了一种知识前缀适配器(KoPA)方法,使LLMs成为更好的结构感知知识判别器。该方法利用自监督结构嵌入预训练来捕获KG中的结构信息。然后,KoPA通过知识前缀适配器将结构嵌入转换为文本嵌入空间,并获得几个虚拟知识令牌。结构嵌入到文本形式的映射为输入三元组提供了辅助信息。虚拟知识令牌在输入提示序列中充当前缀,引导指令调整过程。此外,我们进行了全面的分析和实验证明了KoPA的显著性能和可迁移性。总的来说,我们的贡献有三个方面:
• 我们是第一个全面探讨LLMs在KGC中的利用的工作,具体是通过整合KG结构信息以增强LLM推理。这涉及将现有的LLM范例,如ICL和IT,转移到KGC任务的结构感知设置中。
• 我们提出了一种知识前缀适配器(KoPA),有效地将预训练的KG结构嵌入与LLMs整合。KoPA实现了从LLM和KG中文本嵌入的全面交互。使用KoPA进行微调的LLMs能够做出表现出对KGC的结构感知的决策。
• 我们在三个公共基准上进行了广泛的实验,并评估了我们提出的所有结构感知方法在有充分基线比较的情况下的KGC性能。我们比较了不同方法引入结构信息到LLMs中的有效性。
2 相关工作
2.1 知识图谱完成
知识图谱完成(KGC)[52]是知识图谱社区中的一个重要研究领域,旨在挖掘给定不完整知识图谱中的缺失三元组。KGC包含多个子任务,如三元组分类[4]、实体预测[4]和关系预测[50]。KGC任务的共同点是建立一个有效的机制来衡量三元组的合理性。主流的KGC方法可以分为两类:基于嵌入的方法和基于PLM的方法。
基于嵌入的方法[4, 43, 46, 56]旨在将知识图谱中的实体和关系嵌入到一个或多个连续的表示空间中。这些方法充分利用知识图谱中的结构信息,通过精心设计的得分函数建模三元组的合理性,并以自监督的方式学习实体/关系嵌入,应用负采样[4]。此外,根据得分函数的设计,基于嵌入的方法可以分为三个子类别:(1)基于翻译的方法,如TransE [4]和RotatE [43],(2)基于张量分解的方法,如DistMult [56]和ComplEx [46],(3)基于神经网络的方法,如ConvE [38]。基于嵌入的KGC方法学习用于三元组区分的结构嵌入,但忽略了知识图谱中的文本信息。此外,基于PLM的方法将KGC视为基于文本的任务,通过微调预训练的语言模型如BERT [12]。实体和关系的短文本描述被组织成输入序列,并由PLMs编码。KG-BERT [58]是第一个将KGC建模为二进制文本分类任务的基于PLM的方法。随后的工作,如MTL-KGC [21]和StAR [48],通过引入更多的训练任务,如关系分类和三元组排序,以及更复杂的三元组编码策略,进一步改进了KG-BERT。PKGC [28]利用手动提示模板捕捉三元组的语义。其他方法,如KGT5 [37]和KG-S2S [7],采用了生成KGC [61]的一步,在编码器-解码器PLMs(如T5 [35])的序列到序列范式中。基于PLM的方法利用了PLM的强大性能,但将训练过程变成了基于文本的学习,难以捕捉知识图谱中的复杂结构信息。
2.2 LLMs在知识图谱研究中的应用
近年来,大型语言模型(LLMs)[31, 45, 64]取得了迅速的进展,并在大量与文本相关的任务中展示了强大的能力[67]。LLMs通常以自回归的方式进行预训练,通过下一个单词预测任务[5]展现出强大的文本理解和生成能力。一些重要的技术,如指令调整(IT)[32]和人类偏好对齐[54],进一步被应用于指导模型遵循人类指令并生成与人类价值观和偏好一致的响应。
在LLM的研究主题中,整合LLM和知识图谱(KG)[15, 33, 41, 51, 53, 55]是一个受欢迎且重要的方向。一方面,LLMs普遍存在幻觉[57, 66],即LLMs缺乏事实知识且难以解释。存储结构化知识的KG可以通过将事实知识引入LLMs来缓解这种现象[9, 10, 14, 19, 20, 34, 40, 55]。另一方面,LLMs的强大生成能力可以为与KG相关的任务(如KGC [70, 71]、实体对齐 [65]、KGQA [2]等)带来好处。对于LLMs而言,既有针对KG的(KG4LLM),也有针对LLMs的(LLM4KG),两者都非常重要。
我们专注于将LLMs应用于KGC任务(LLM4KGC),这尚未得到仔细研究。KGLLaMA [59]通过朴素的指令调整方法迈出了第一步,但它在如何发挥LLMs和KGs自身的力量,实现结构感知推理以及取得更好的KGC性能方面缺乏深入研究和系统性探讨。在本文中,我们将从更系统的角度以三元组分类任务为例,深入探讨这个问题。
2.3 将非文本模态信息整合到LLMs中
由于LLMs在文本生成方面表现出通用能力,许多其他工作尝试将非文本模态信息整合到其中,如图像[25, 68]、音频[29]和视频[29],这也被称为多模态LLMs [63]。这些方法倾向于通过模态编码器对非文本信息进行编码,然后将其处理为虚拟文本标记。通过在多模态数据集上进行指令调整,非文本标记与单词标记对齐。
上述多模态LLMs通常不包括图谱,这是另一种重要的数据模态。也有一些关于如何将图谱数据整合到LLMs的工作。Drug-Chat [23]建议使用图编码器对药物分子图进行编码,并微调LLMs以预测药物相互作用。其他工作 [16, 24, 49, 62] 探讨了如何通过将图结构信息转化为LLMs来解决图学习任务,如节点分类和图分类。
我们的研究与此主题相关,因为知识图谱除了文本描述外,还具有复杂的图结构。在本文中,我们将探讨如何将知识图谱中的复杂结构信息整合到LLMs中,以实现对知识图谱完成任务更好的推理能力。
方法
3.1 知识前缀适配器(KoPA)
KoPA方法分为两部分:首先通过结构嵌入预训练提取KG中实体和关系的结构信息,然后通过结构前缀适配器将这些信息注入输入序列。这种方法避免了将KG的结构信息以文本形式表示所带来的无效或冗余信息。
3.2 结构嵌入预训练
与基于嵌入的KGC方法相反,KoPA从KG中提取实体和关系的结构信息,并将其适应到LLM的文本表示空间中。使用负采样的自监督预训练目标定义得分函数 ( F(h,r,t) ) 来衡量三元组的合理性。通过最小化这种预训练损失,实体和关系的结构嵌入被优化以适应所有相关的三元组。
3.3 知识前缀适配器
在完成结构嵌入预训练后,通过知识前缀适配器将结构嵌入转换为虚拟知识Token。这些Token作为输入序列的前缀,由于解码器仅在LLM中的单向注意力,所有后续的文本Token都可以看到这些前缀。这样,文本Token可以对输入三元组的结构嵌入进行单向注意,从而在微调和推理期间实现结构感知提示。
实验发现
数据集
实验使用三个公共KG基准测试:UMLS、CoDeX-S 和 FB15K-237N。UMLS是一个经典的医学知识图谱,CoDeX-S是从Wikidata中提取的百科全书式KG,FB15K-237N是从FB15K-237修改而来。
实验设置
实验比较了KoPA方法与三类基线模型:基于嵌入的方法、基于PLM的方法和基于LLM的方法。对于所有基于LLM的方法,使用Alpaca-7B作为LLM的主干。KoPA使用RotatE和结构嵌入预训练的得分函数,适配器是一个512×4096的线性投影层。
主要结果
KoPA在所有三个数据集上的准确率和F1得分均优于现有的16种基线模型。以CoDeX-S为例,KoPA在准确率上提高了1.81%,在F1得分上提高了1.85%。与其他基于LLM的方法相比,KoPA表现出更好的结构信息理解能力,尤其在更大、更具挑战性的数据集上表现突出。
结论
本文提出的知识前缀适配器(KoPA)成功地将KG的结构信息融入到LLM中,从而提高了LLM在KGC任务中的性能。KoPA方法有效地将结构嵌入转换为文本表示,从而在微调和推理过程中提供了结构感知提示。实验结果表明,与现有方法相比,KoPA在KGC任务上取得了显著的性能提升,尤其是在处理大型和复杂的数据集时。这项工作为未来结合结构信息和LLM在KGC任务中的应用提供了新的视角和方法。
原文地址:https://blog.csdn.net/weixin_43564920/article/details/135884556
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!