使用Python和MediaPipe实现的人脸对齐
目录
- 是什么
- 关键点
- 工具和库
- python
- mediapipe
- 安装何使用
- 安装 `pip install mediapipe`
- 使用
- 特征点提取
- 图片
- 视频
- 特征点提取和变换
- 特征点提取使用[mediapipe](#jump)
- 选取特征点
- 考虑
- 仿射变换
- 图片变换
- 缩放、平移
- 缩放、旋转、平移
是什么
人脸对齐是计算机视觉和图像处理中的一种技术,主要用于标准化人脸图像,使得在图像或视频帧中的面部特征(如眼睛、鼻子和嘴巴)被调整到一致的位置。这个过程对于提高人脸识别系统的准确性和效率至关重要。
关键点
-
特征点检测:人脸对齐涉及识别面部的关键特征点。这些特征点通常包括眼角、鼻尖、嘴角等。
-
图像变换:一旦特征点被识别,接下来就是通过几何变换(如仿射变换)调整整个面部图像,使得这些特征点对齐到一个预定义的模板或标准位置上。
工具和库
python
Python 是一种高级编程语言,以其清晰的语法和易于学习的特点广受欢迎。由于其强大的库支持,Python 在数据科学、机器学习、网络开发、自动化以及多种科学计算领域中被广泛应用。它支持多种编程范式,包括面向对象、命令式、函数式和过程式编程。Python的一个显著优势是其庞大的生态系统,其中包括了大量的库和框架,如NumPy、Pandas、TensorFlow和PyTorch等,这些工具极大地丰富了Python在各个领域的应用能力。
mediapipe
MediaPipe 是由谷歌开发的一个用于构建跨平台的、实时应用程序的多媒体处理库。它提供了面向机器学习和计算机视觉的管道,使得开发者能够轻松地构建复杂的图像处理、视频处理和音频处理应用。MediaPipe 特别适合于处理实时视频流,并能有效地进行人脸检测、手势识别、姿态估计等任务。其核心优势在于高性能的流处理架构,使得多个处理步骤可以高效、灵活地协同工作。
安装何使用
安装 pip install mediapipe
使用
特征点提取
图片
import cv2
import mediapipe as mp
# 初始化MediaPipe的面部网格模块
mp_face_mesh = mp.solutions.face_mesh
face_mesh = mp_face_mesh.FaceMesh()
# 读取图像
image_path = 'image.jpg'
image = cv2.imread(image_path)
# MediaPipe要求RGB图像
rgb_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 使用Face Mesh处理图像
result = face_mesh.process(rgb_image)
# 如果检测到面部特征点
if result.multi_face_landmarks:
for face_landmarks in result.multi_face_landmarks:
# 遍历每一个特征点
for i in range(0, 468):# 这里并不一定是468,还可以是478,需要额外配置face_mesh
pt1 = face_landmarks.landmark[i]
# 计算特征点在原始图像中的坐标
x = int(pt1.x * image.shape[1])
y = int(pt1.y * image.shape[0])
# 在图像上标记特征点
cv2.circle(image, (x, y), 1, (100, 100, 0), -1)
# 显示图像
cv2.imshow('MediaPipe Face Mesh', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
原图

效果图

视频
import cv2
import mediapipe as mp
# 初始化MediaPipe的面部网格模块
mp_face_mesh = mp.solutions.face_mesh
face_mesh = mp_face_mesh.FaceMesh()
# 初始化OpenCV用于读取视频
cap = cv2.VideoCapture('video.mp4')
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# 将BGR图像转换为RGB
rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 使用Face Mesh处理图像
result = face_mesh.process(rgb_frame)
# 如果检测到面部特征点
if result.multi_face_landmarks:
for face_landmarks in result.multi_face_landmarks:
# 遍历每一个特征点
for i in range(0, 468): # 这里并不一定是468,还可以是478,需要额外配置face_mesh
pt1 = face_landmarks.landmark[i]
# 计算特征点在原始图像中的坐标
x = int(pt1.x * frame.shape[1])
y = int(pt1.y * frame.shape[0])
# 在图像上标记特征点
cv2.circle(frame, (x, y), 1, (100, 100, 0), -1)
# 显示带有标记的图像
cv2.imshow('MediaPipe Face Mesh', frame)
# 按下'q'键退出循环
if cv2.waitKey(5) & 0xFF == ord('q'):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()
特征点提取和变换
特征点提取使用mediapipe
选取特征点
-
眼睛:选择眼角(内眼角和外眼角)作为特征点,因为它们在大多数人脸上都是显著且易于识别的。
-
鼻子:通常选取鼻尖,因为它是面部中心线上的一个明显点,有助于确定面部垂直对称。
-
嘴巴:选择嘴角作为特征点,这有助于确定面部下部的位置和姿态。
考虑
- 对称性:选择的特征点应该沿着面部中心线对称分布,以确保对齐后的面部保持对称性。
- 均匀分布:特征点应该均匀分布在面部,包括上、中、下部,以便在对齐过程中考虑到面部的整体结构。
- 面部表情:选择那些不太受表情影响的稳定特征点,尤其是在进行身份验证或人脸识别等任务时。
- 面部姿势:选择即使在不同姿势(如正面或侧面)下也能保持相对稳定的特征点。
相对稳定的特征点是指那些不易受面部表情变化、头部姿势、年龄增长或其他外部因素影响的面部点。
仿射变换
图片变换
import cv2
import mediapipe as mp
import numpy as np
# 初始化MediaPipe的面部网格模块
mp_face_mesh = mp.solutions.face_mesh
face_mesh = mp_face_mesh.FaceMesh()
# 读取图像
image_path = r'C:\Users\wuteng\Desktop\image.jpg'
image = cv2.imread(image_path)
# MediaPipe要求RGB图像
rgb_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 使用Face Mesh处理图像
result = face_mesh.process(rgb_image)
# 检查是否检测到面部特征点
if not result.multi_face_landmarks:
raise ValueError("No face landmarks detected.")
# 假设我们使用左眼外角(左眼第0个标记点), 右眼外角(右眼第3个标记点), 鼻尖, 左嘴角, 右嘴角
# MediaPipe中的对应标记点索引分别为:33, 133, 13, 78, 308
face_landmarks = result.multi_face_landmarks[0].landmark
landmark_indices = [33, 133, 13, 78, 308]
detected_points = np.float32([[face_landmarks[idx].x * image.shape[1], face_landmarks[idx].y * image.shape[0]] for idx in landmark_indices])
# 目标特征点位置,应根据实际情况调整
target_points = np.float32([
[100, 100], # 左眼外角
[200, 100], # 右眼外角
[150, 150], # 鼻尖
[120, 200], # 左嘴角
[180, 200] # 右嘴角
])
# 计算仿射变换矩阵
M, _ = cv2.findHomography(detected_points, target_points)
# 应用仿射变换对齐人脸
aligned_image = cv2.warpPerspective(image, M, (image.shape[1], image.shape[0]))
# 显示结果
cv2.imshow('Original Image', image)
cv2.imshow('Aligned Image', aligned_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
效果图:
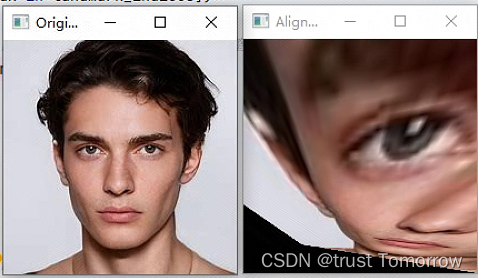
缩放、平移
import cv2
import mediapipe as mp
import numpy as np
# 初始化MediaPipe的面部网格模块
mp_face_mesh = mp.solutions.face_mesh
face_mesh = mp_face_mesh.FaceMesh()
# 读取图像
image_path = r'C:\Users\wuteng\Desktop\image.jpg'
image = cv2.imread(image_path)
# MediaPipe要求RGB图像
rgb_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 使用Face Mesh处理图像
result = face_mesh.process(rgb_image)
# 检查是否检测到面部特征点
if not result.multi_face_landmarks:
raise ValueError("No face landmarks detected.")
# 假设我们使用左眼外角(左眼第0个标记点), 右眼外角(右眼第3个标记点), 鼻尖, 左嘴角, 右嘴角
# MediaPipe中的对应标记点索引分别为:33, 133, 13, 78, 308
face_landmarks = result.multi_face_landmarks[0].landmark
landmark_indices = [33, 133, 13, 78, 308]
detected_points = np.float32([[face_landmarks[idx].x * image.shape[1], face_landmarks[idx].y * image.shape[0]] for idx in landmark_indices])
# 缩放和平移设置
scale_factor = 0.9
translate_x, translate_y = 10, 10
# 构造仿射变换矩阵
transformation_matrix = cv2.getRotationMatrix2D((detected_points[2][0], detected_points[2][1]), 0, scale_factor)
transformation_matrix[:, 2] += [translate_x, translate_y]
# 应用仿射变换对齐人脸
aligned_image = cv2.warpAffine(image, transformation_matrix, (image.shape[1], image.shape[0]))
# 显示结果
cv2.imshow('Original Image', image)
cv2.imshow('Aligned Image', aligned_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
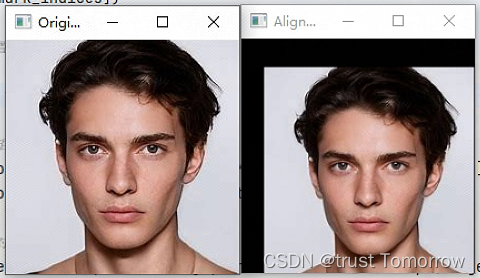
缩放、旋转、平移
import cv2
import mediapipe as mp
import numpy as np
# 初始化MediaPipe的面部网格模块
mp_face_mesh = mp.solutions.face_mesh
face_mesh = mp_face_mesh.FaceMesh()
# 读取图像
image_path = r'C:\Users\wuteng\Desktop\image.jpg'
image = cv2.imread(image_path)
# MediaPipe要求RGB图像
rgb_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 使用Face Mesh处理图像
result = face_mesh.process(rgb_image)
# 检查是否检测到面部特征点
if not result.multi_face_landmarks:
raise ValueError("No face landmarks detected.")
# 假设我们使用左眼外角(左眼第0个标记点), 右眼外角(右眼第3个标记点), 鼻尖, 左嘴角, 右嘴角
# MediaPipe中的对应标记点索引分别为:33, 133, 13, 78, 308
face_landmarks = result.multi_face_landmarks[0].landmark
landmark_indices = [33, 133, 13, 78, 308]
detected_points = np.float32([[face_landmarks[idx].x * image.shape[1], face_landmarks[idx].y * image.shape[0]] for idx in landmark_indices])
# 缩放、平移和旋转设置
scale_factor = 0.9 # 缩放因子
translate_x, translate_y = -10, 10 # 左下平移10像素
rotation_angle = 30 # 旋转角度
# 以鼻尖(detected_points[2])为中心进行旋转和缩放
rotation_center = (detected_points[2][0], detected_points[2][1])
transformation_matrix = cv2.getRotationMatrix2D(rotation_center, rotation_angle, scale_factor)
# 添加平移效果
transformation_matrix[:, 2] += [translate_x, translate_y]
# 应用仿射变换对齐人脸
aligned_image = cv2.warpAffine(image, transformation_matrix, (image.shape[1], image.shape[0]))
# 显示结果
cv2.imshow('Original Image', image)
cv2.imshow('Aligned Image', aligned_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
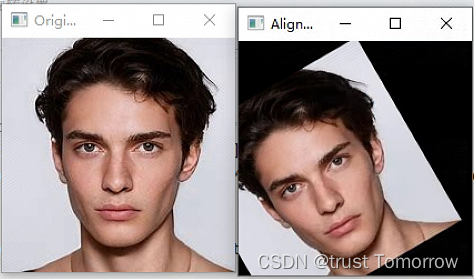
原文地址:https://blog.csdn.net/liudadaxuexi/article/details/135340136
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!