【论文总结】基于深度学习的特征点提取,特征点检测的方法总结
这里写目录标题
- 相关工作
- 1. Discriminative Learning of Deep Convolutional Feature Point Descriptors(2015)
- 2.MatchNet(2015)
- 3.LIFT: Learned Invariant Feature Transform(2016)
- 4. UCN(Universal Correspondence Network)(2016)
- 对于LOSS做实际对比实验测试
- 5. SuperPoint Self-Supervised Interest Point Detection and Description(2018)
- 6. SuperGlue:Learning Feature Matching with Graph Neural Networks
- 6. Key.Net Keypoint Detection by Handcrafted and Learned CNN Filters(2019)
- 7. IF-Net An Illumination-invariant Feature Network(2020)
- 时间轴
- 方法总结
- 数据集总结
- 与传统算法优劣势对比
- 应用
相关工作

1. Discriminative Learning of Deep Convolutional Feature Point Descriptors(2015)
提出一种基于深度学习的特征描述方法能够替代引FT,并且能够很好的应对尺度变化、图像旋转乁透射变换、非刚性变形、光照变化等。使用孪生网络从图块中提取特征信息,并且使用L2距离来描述特征之间的差异。
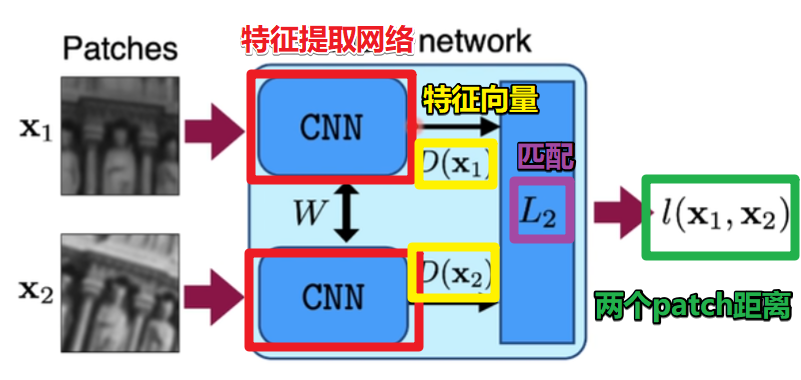
这里距离越大相似度越低,距离越小相似度越高
只拿出CNN部分则是特征提取
网络结构
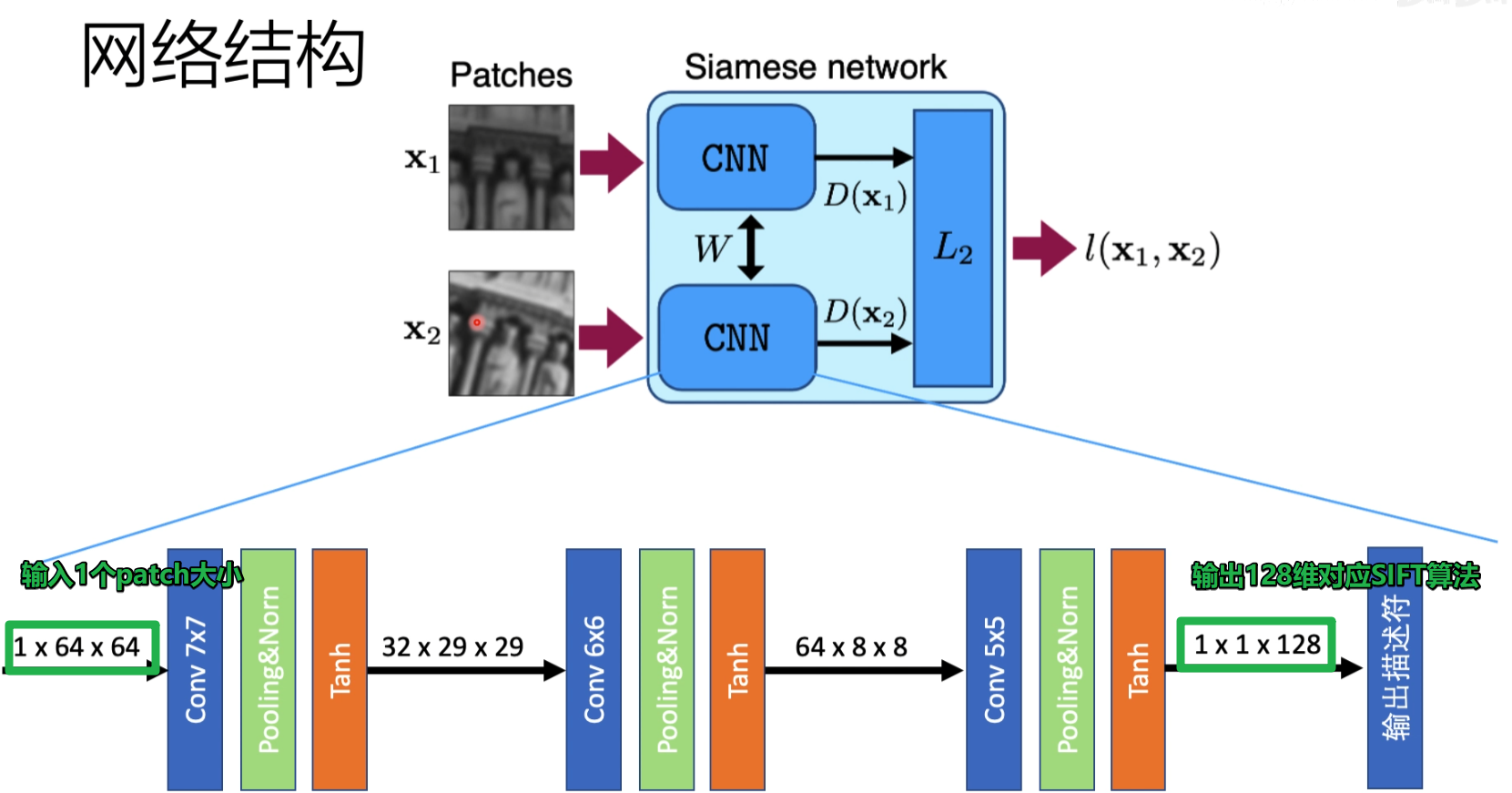
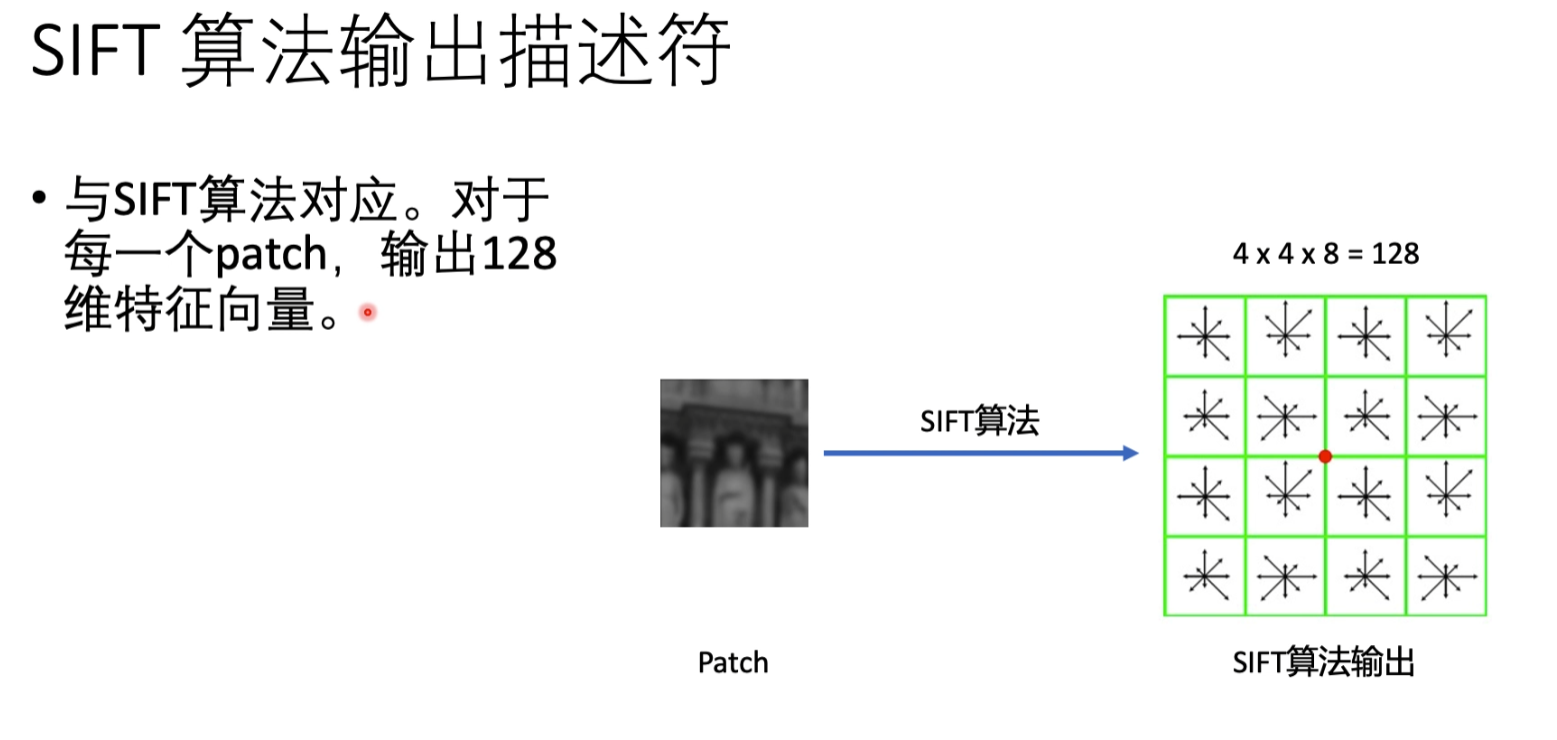
sift算法
损失函数的构建

在两个patch是相等的情况下,用两个patch特征的距离来作为Loss函数,我们希望距离越来越小
在两个patch不相等的情况下,多了,MAX和阈值C,如果两个patch特征的距离>c,LOSS=0,如果两个patch特征的距离<c,则为C-如果两个patch特征的距离
patch不相等希望距离大于C,patch相等希望距离越小越好
这种方法进行训练,可以训练出一个特征提取的CNN网络
2.MatchNet(2015)
网络中的组成部分
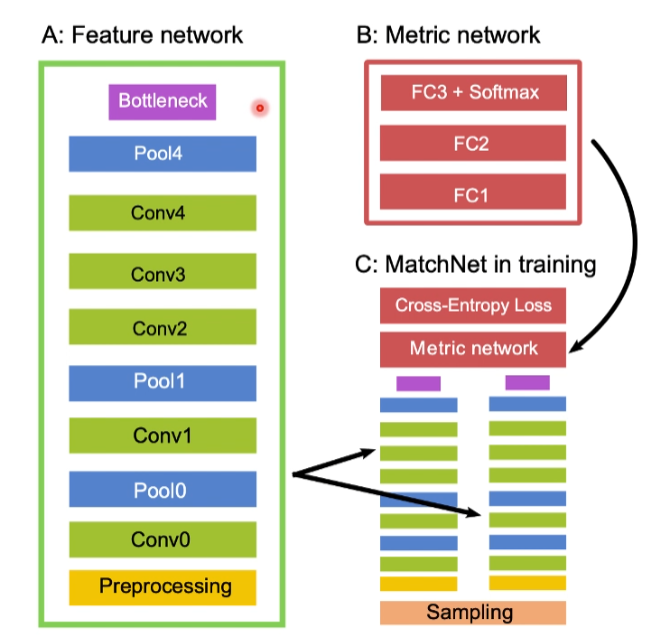
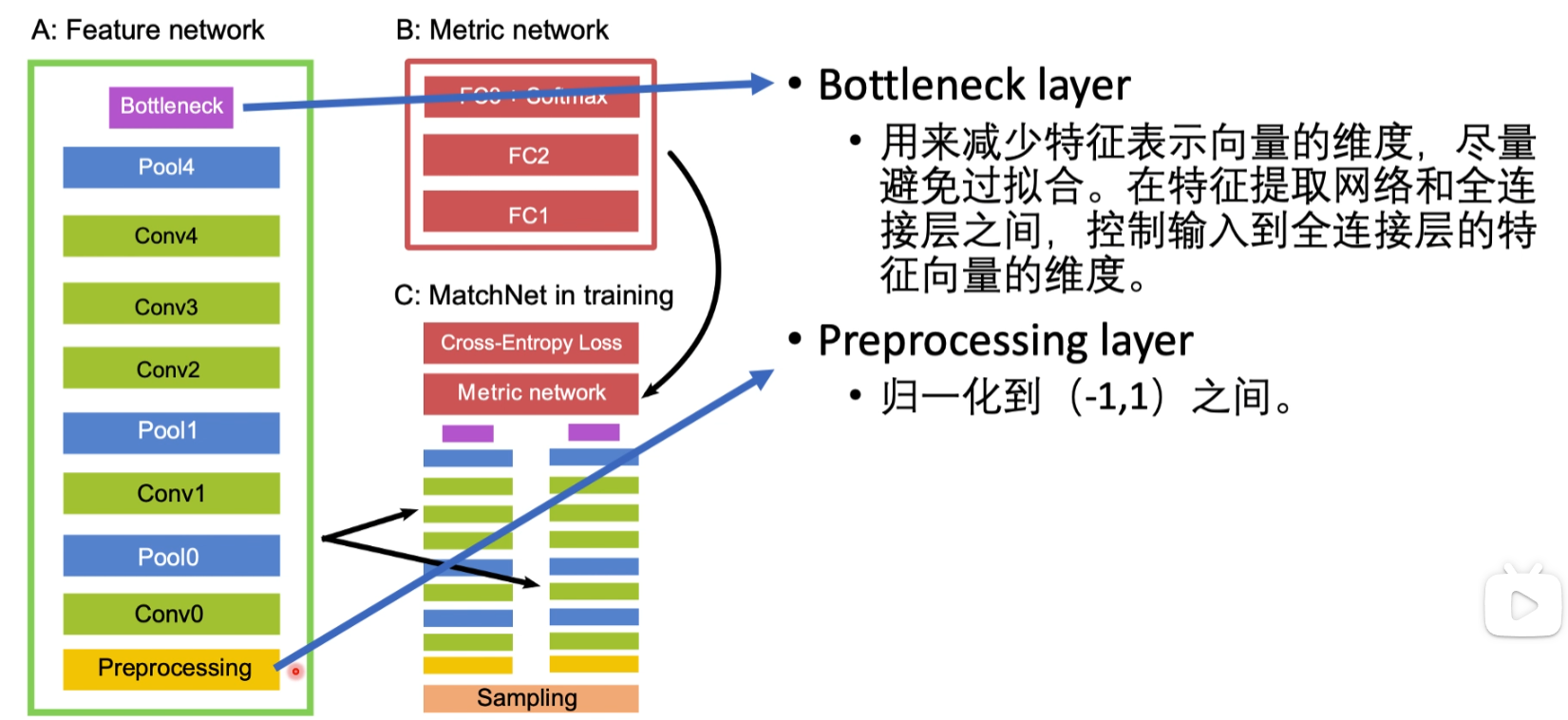
A: Feature network 是双塔结构中的单塔,其中的Bottleneck与Preprocessing层比较重要,是为了防止过拟合加的两个层.
B:Metric network 相当于把特征进行比较,Fully Connected Layer +Softmax层判断两个图像特征之间的距离

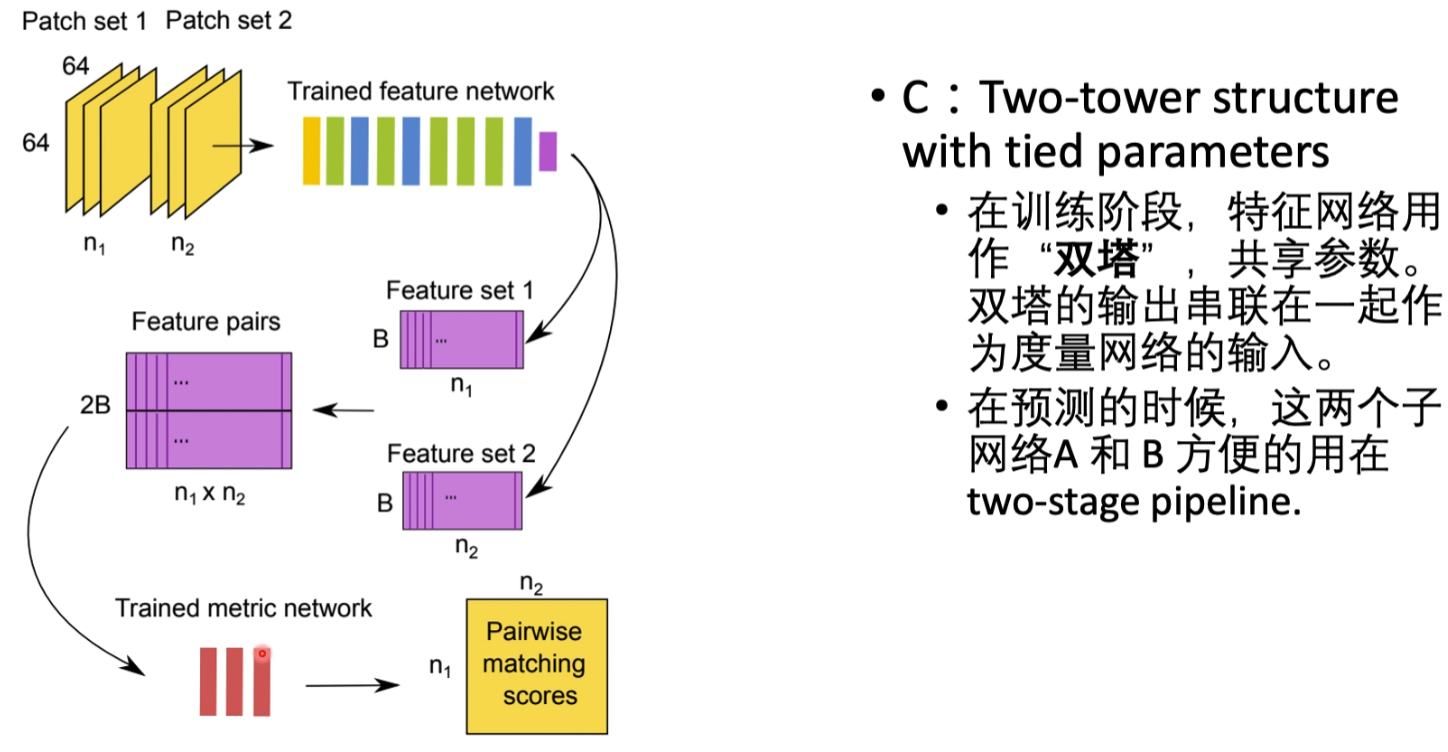
输出把两个塔的输出放到一块,在输出到Metric network
其他组成部分
损失函数
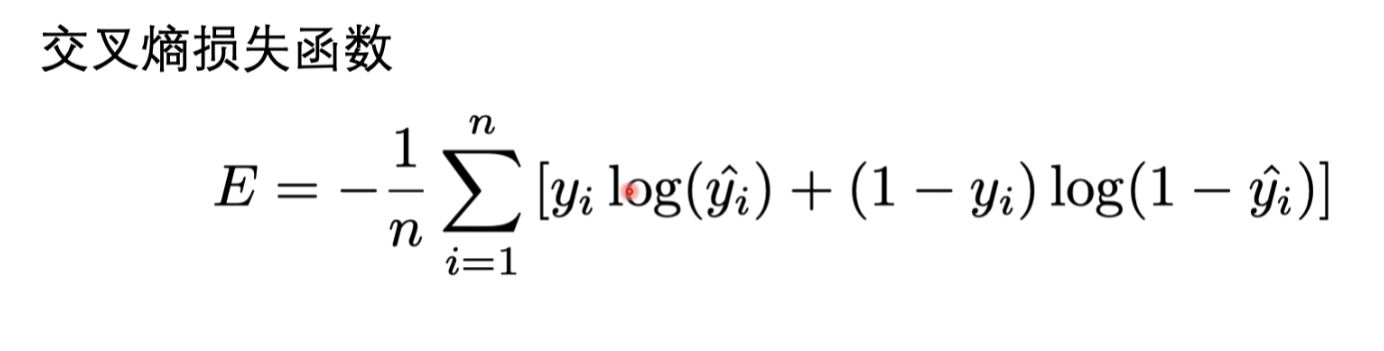
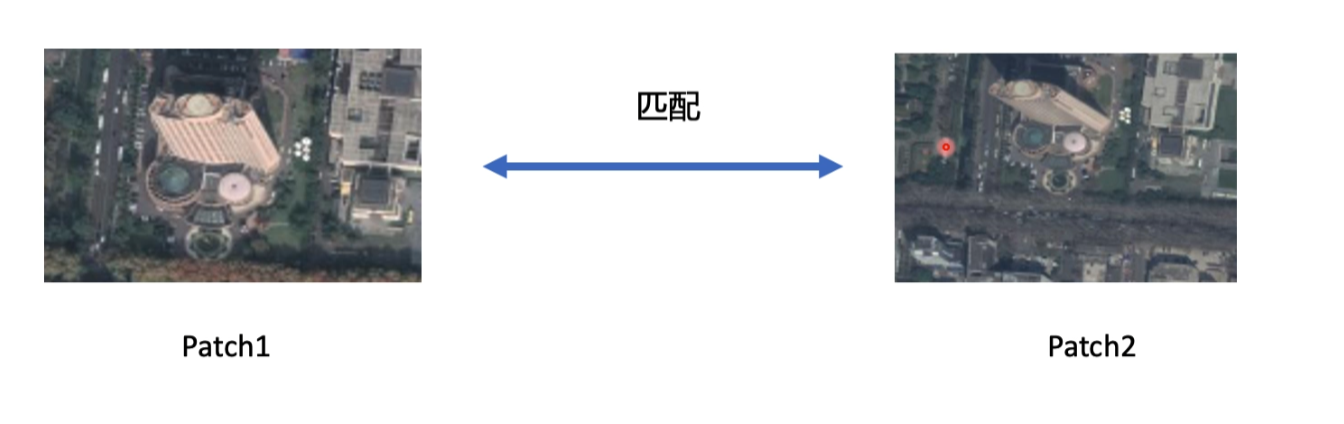
结果
3.LIFT: Learned Invariant Feature Transform(2016)
网络结构
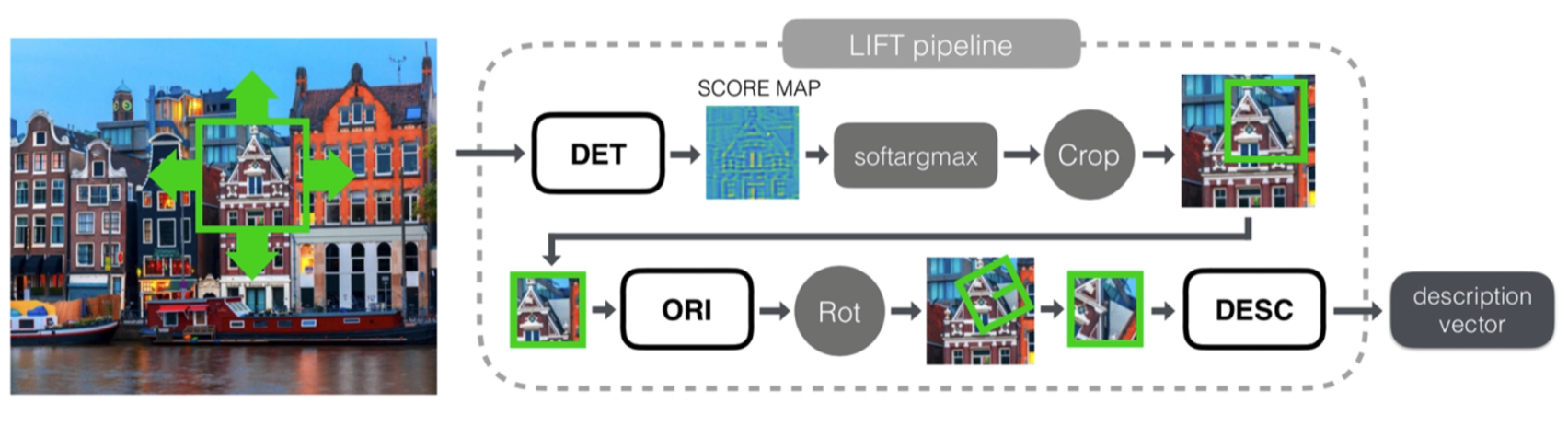
用了三种方法,集合了detector,orientation,descriptor
detector:把图像切割成不同的patch
orientation:对patch做一个旋转
descriptor:做一个描述
这三个方法是三个不同的文章

训练网络结构

训练的时候要先输入4个patch,4个patch要不一样,P1和P2是来自同一个3D点不同视角的图像,相当于P1与P2是匹配的,P3是在不同的3D点回来的一个图像投影,相当于P3,P2,P1是不匹配的,P4是一个不包含任何特征点的特征,是为了防止过拟合去用的
输入的流程就是先进入detector然后对图像进行一个裁剪,紧接着用orientation对图像进行一个旋转,再用descriptor输出图像最终的描述符
损失函数
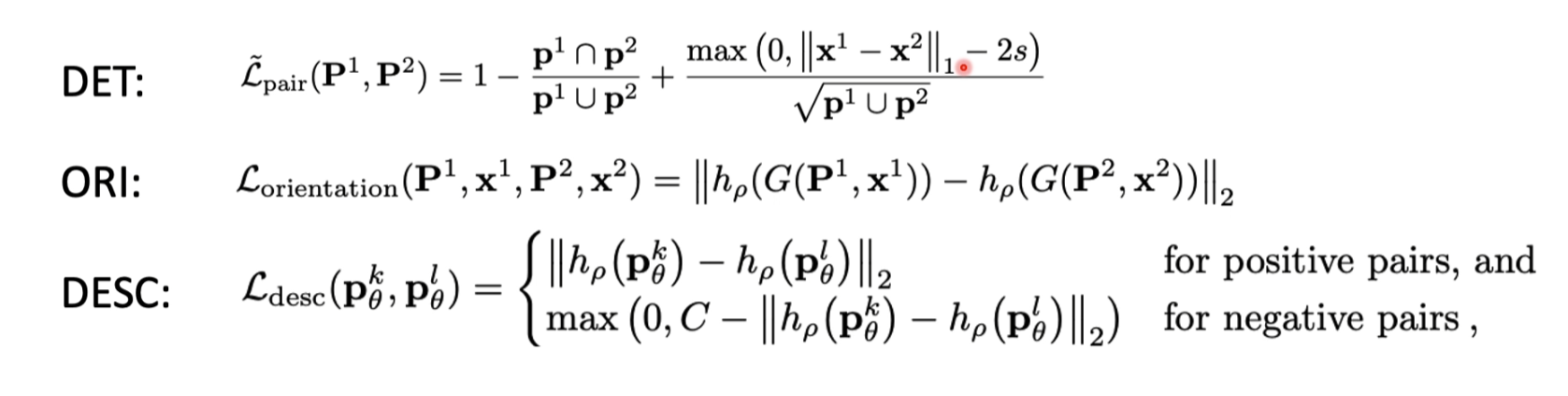
descriptor的损失函数和之前的损失函数几乎是一样的
orientation训练了一个角度
detector网络训练一个有特征的中心点
训练和测试
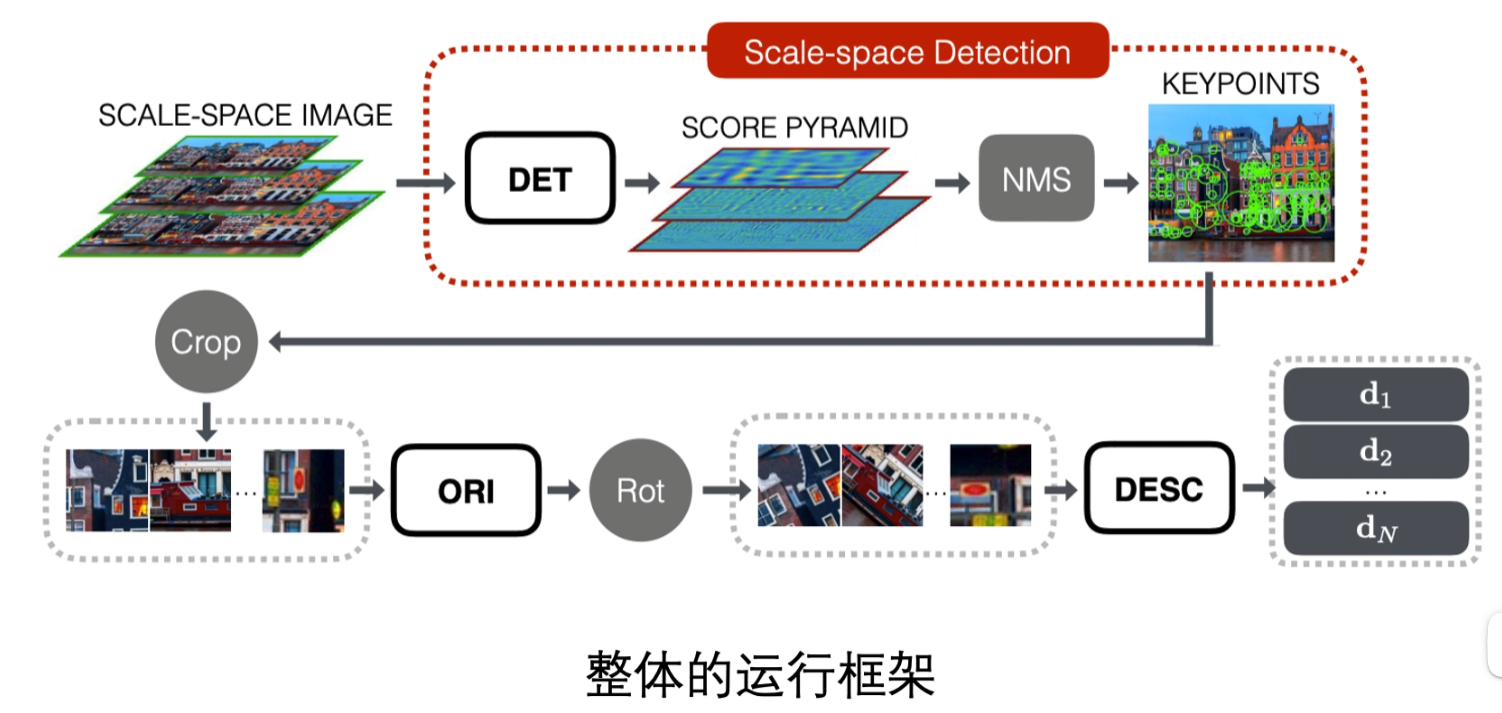
会先输入多张的多尺度图片,最后可以直接输出特征点的特征向量
结果

4. UCN(Universal Correspondence Network)(2016)
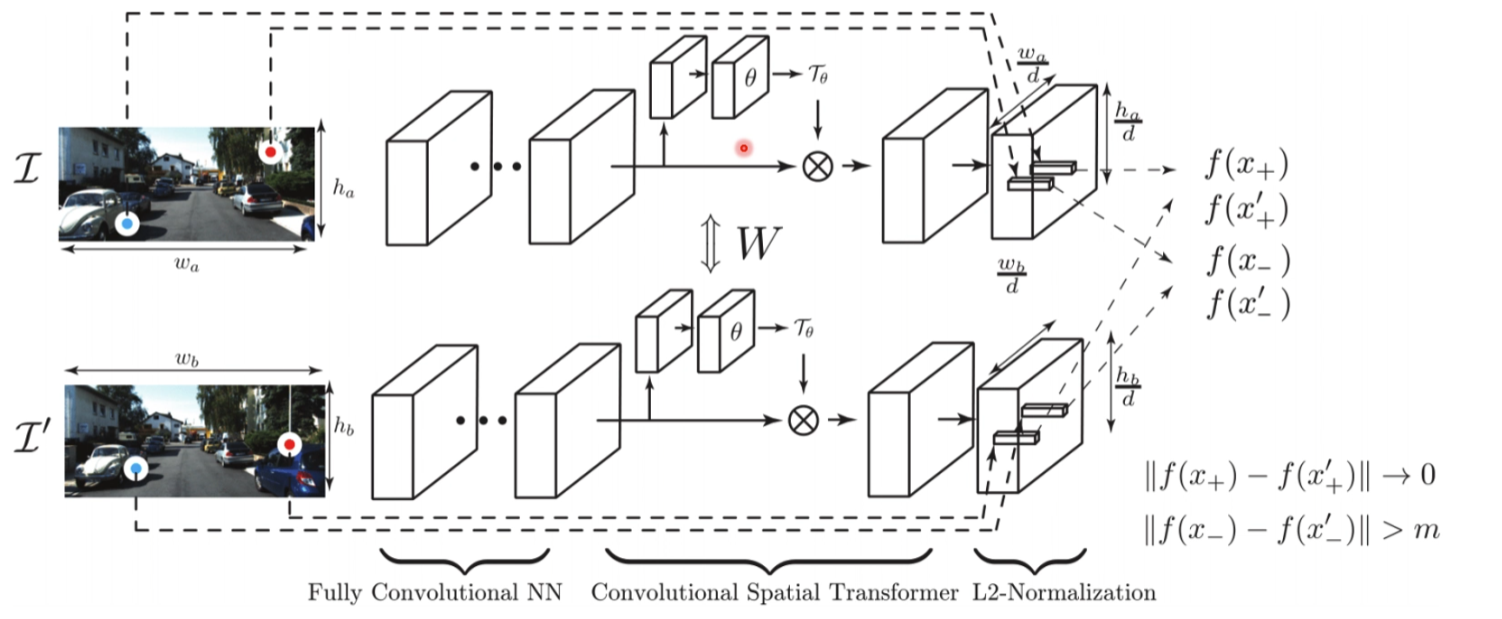
最后会输出一个feature map
网络结构
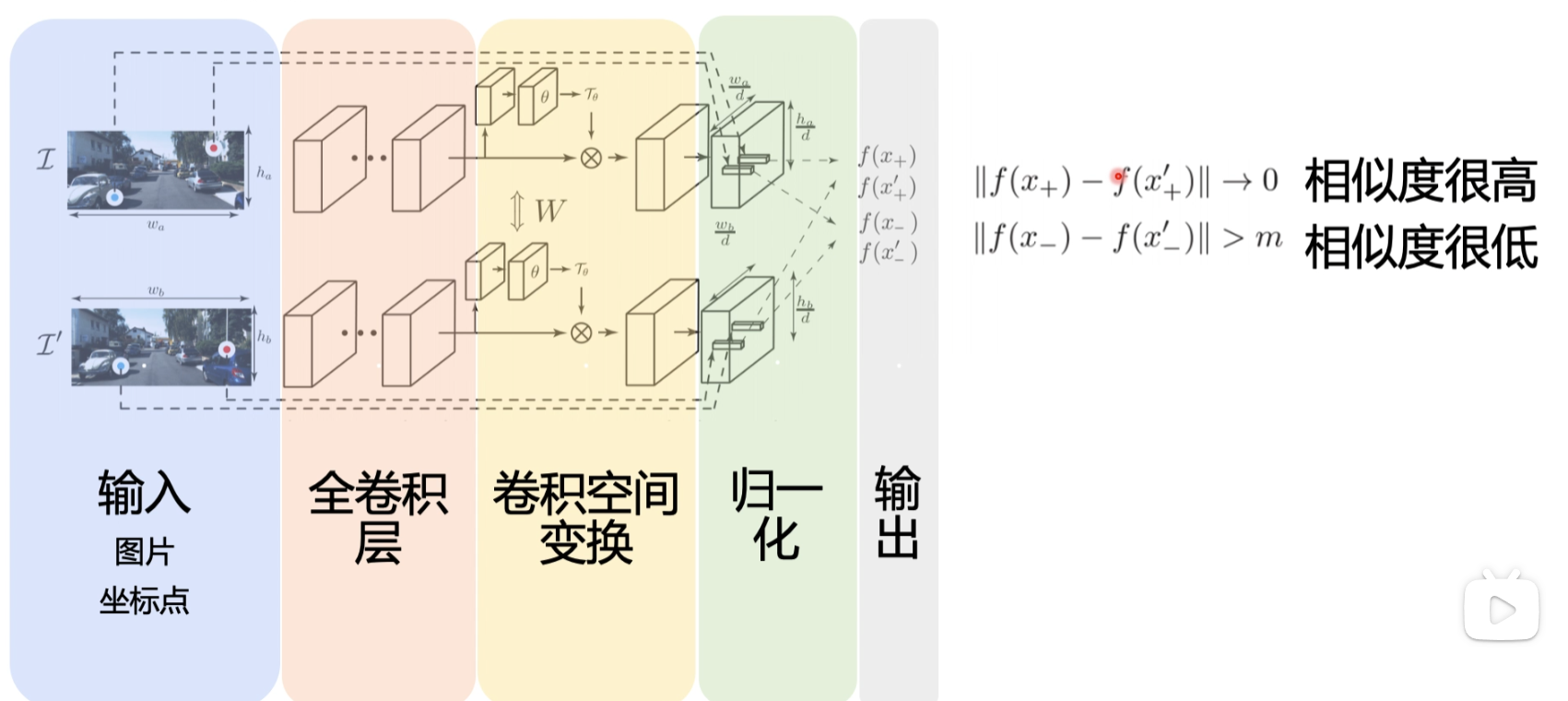
最后会输出两个点的特征描述符,去做一个距离的比较,如果距离大于一个阈值说明像素比较低
输入层
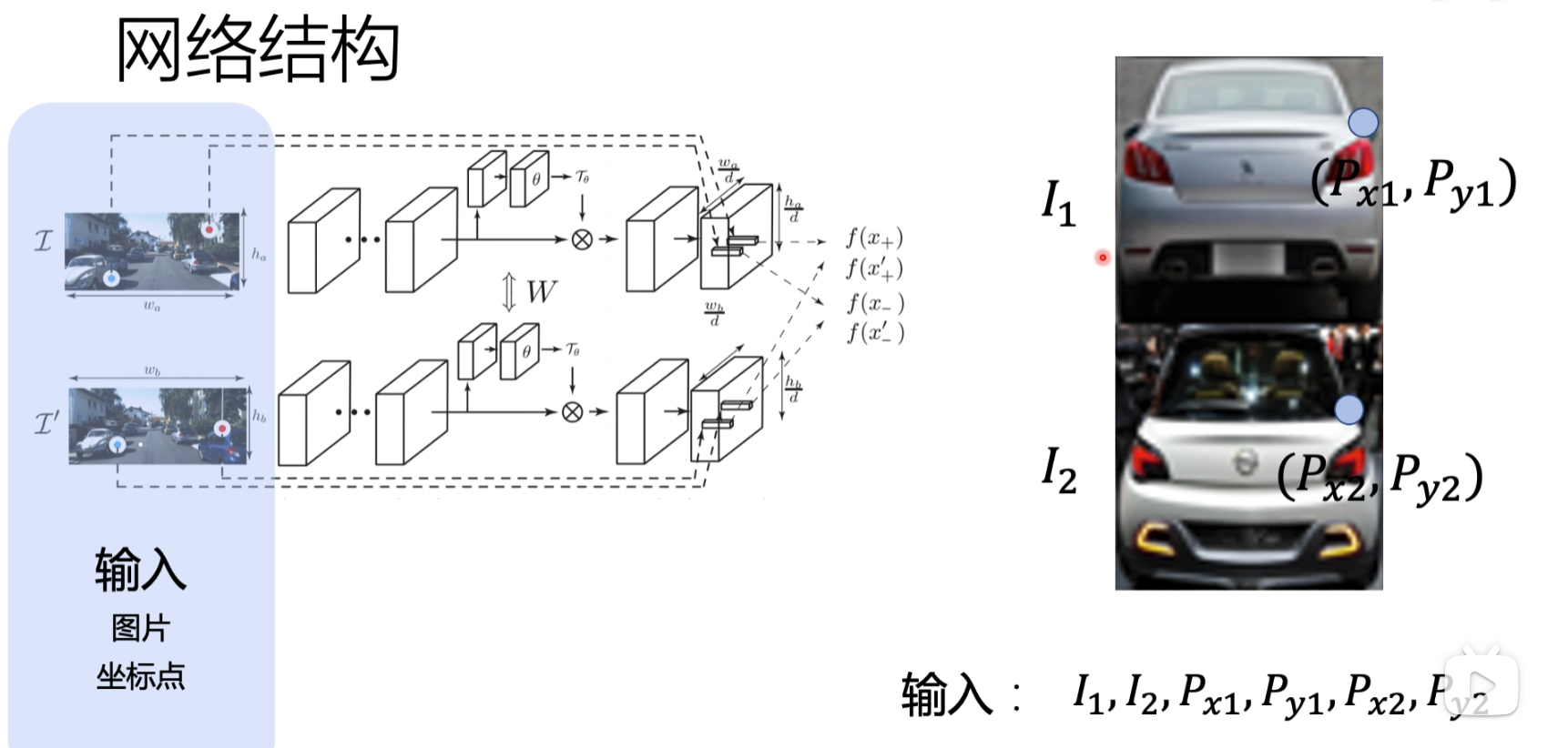
首先输入两张图片,之后输入需要比较图片的坐标点
全卷积层
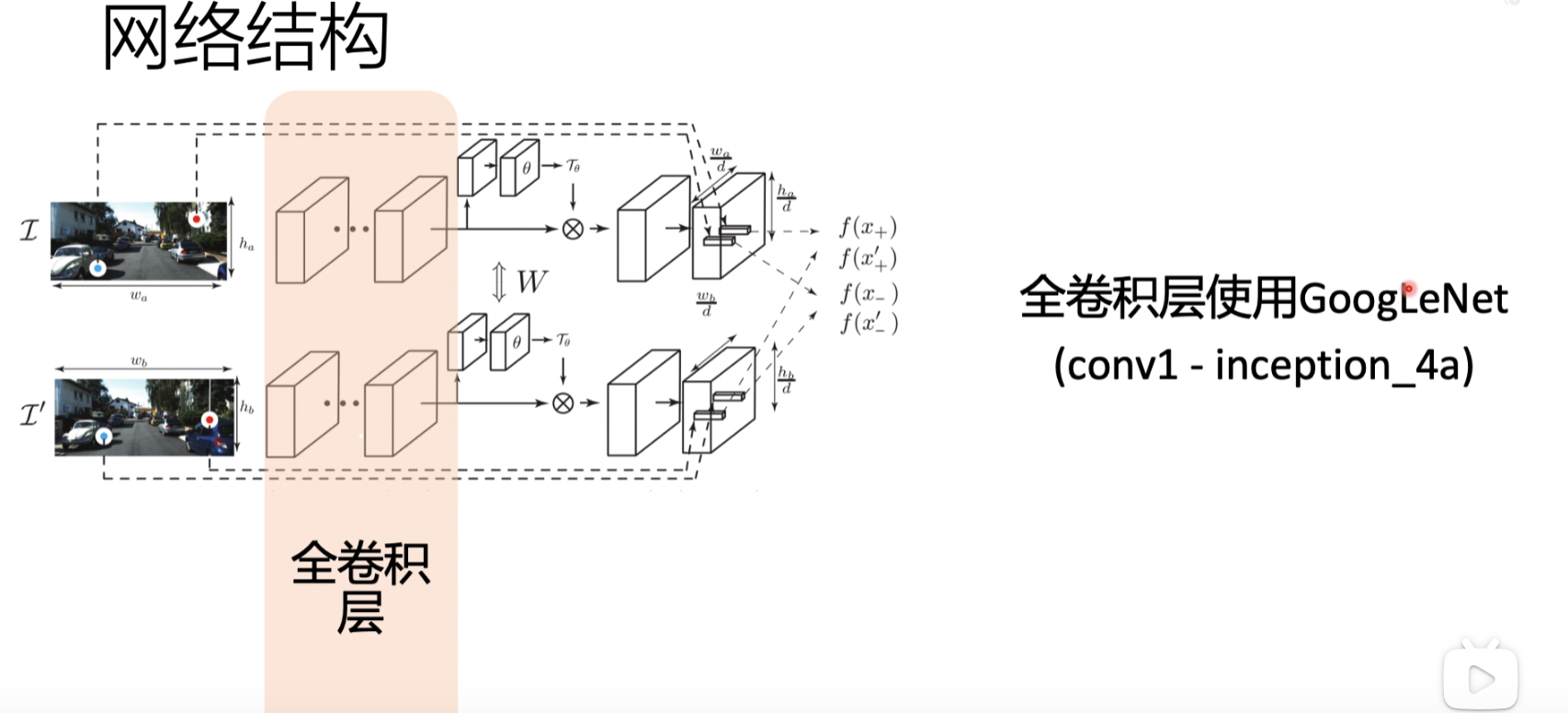
使用googleNet网络做全卷积
卷积空间变换
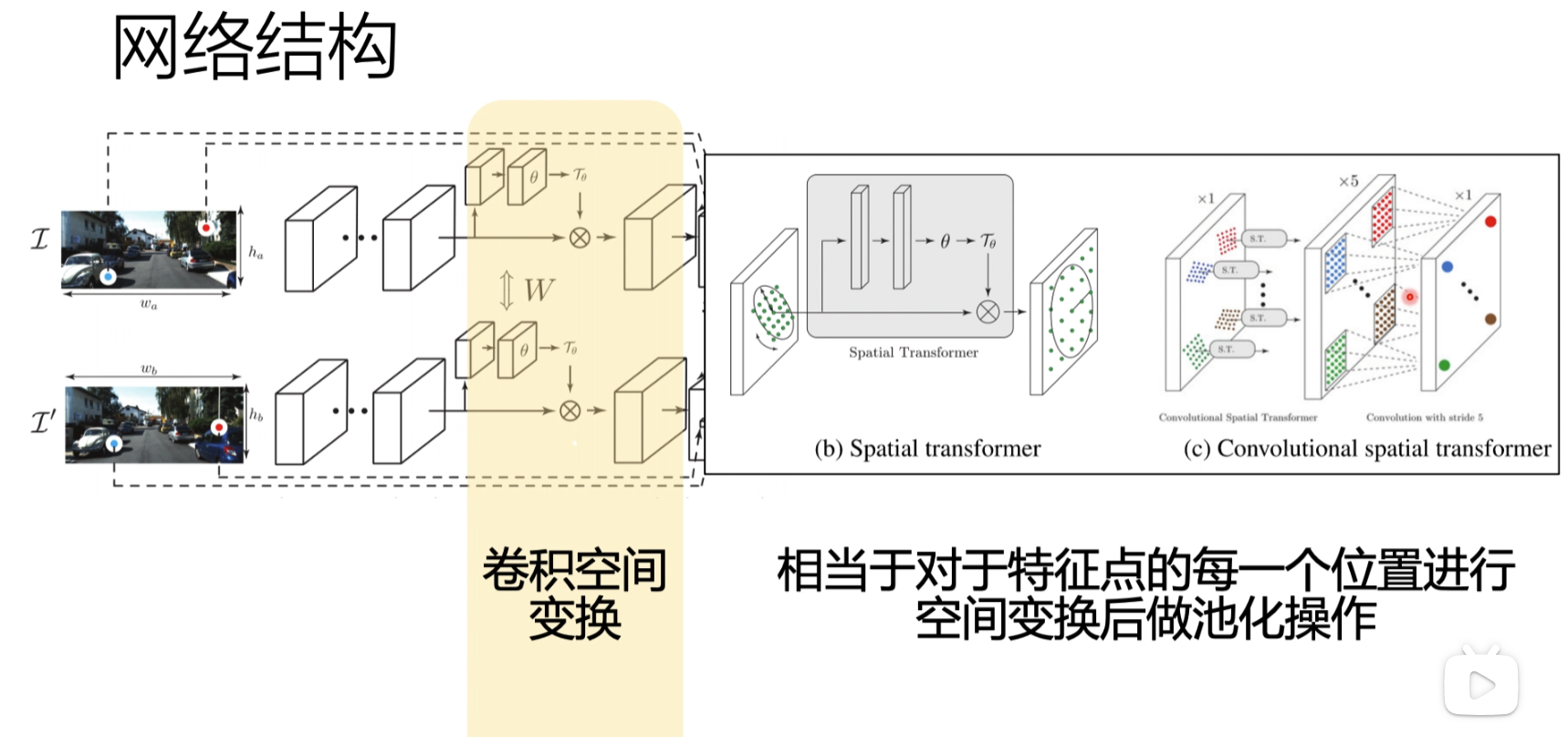
归一化
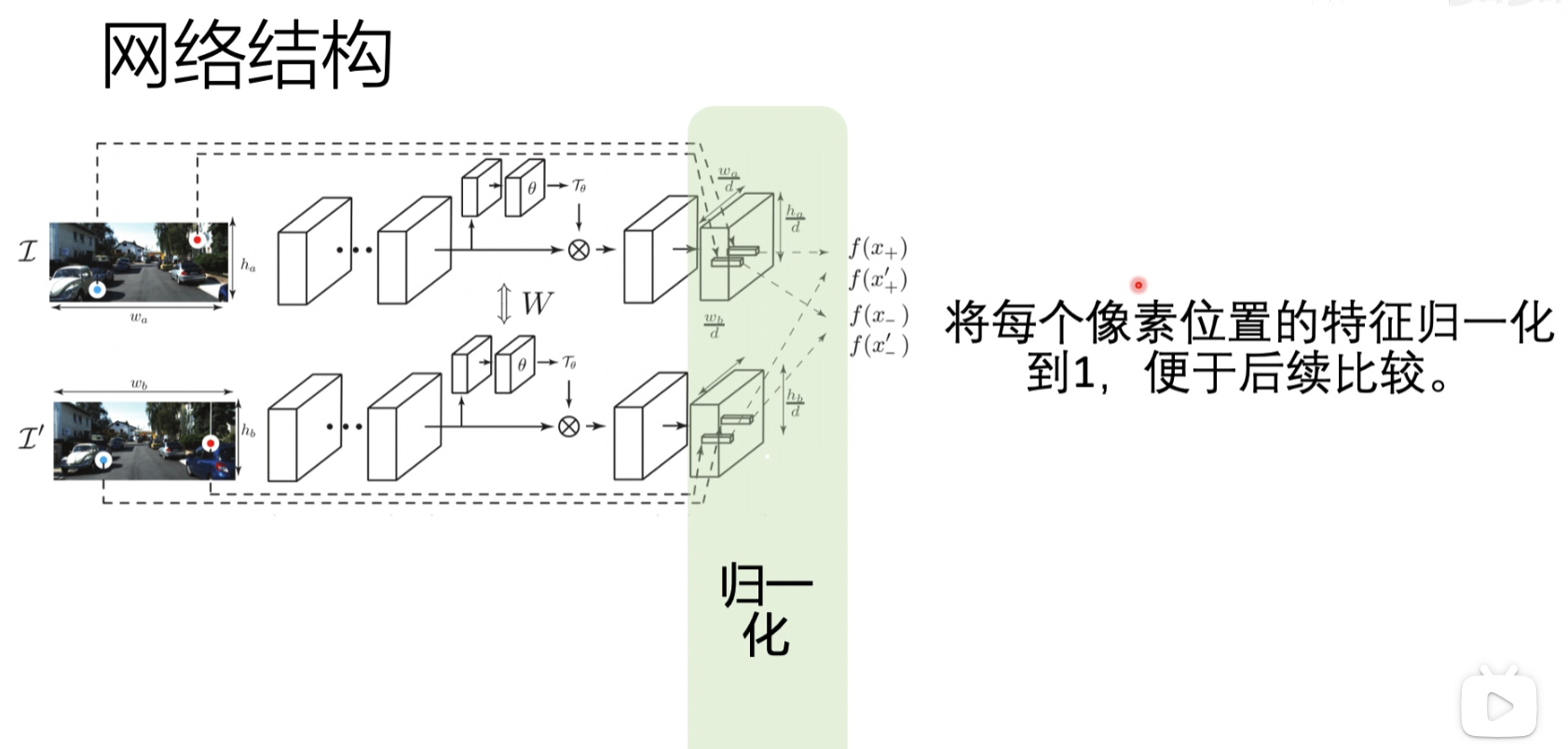
最后会把输入的x,y的点,映射到feature map里面去,输出描述符,然后去做一个比较
损失函数
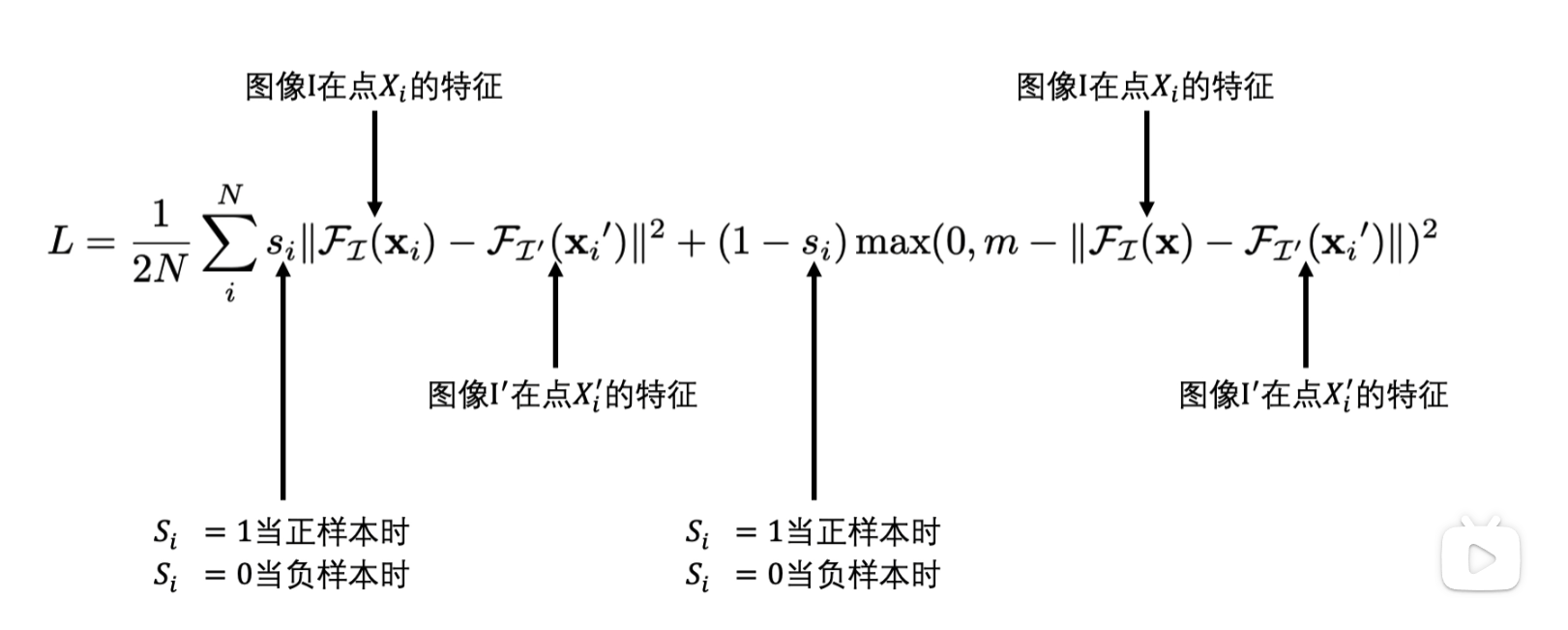
不匹配的时候用阈值卡一个loss
测试

对于LOSS做实际对比实验测试
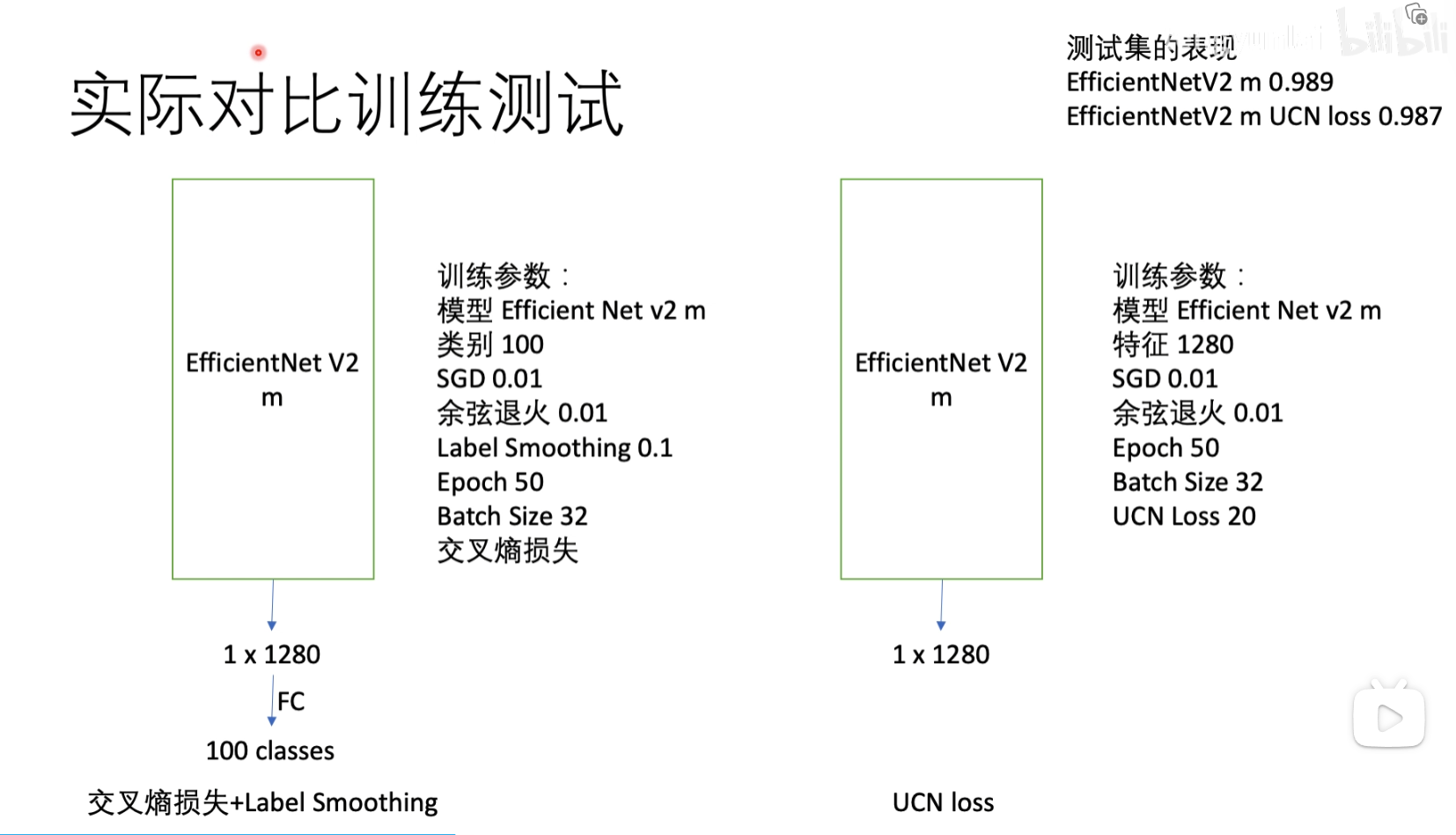
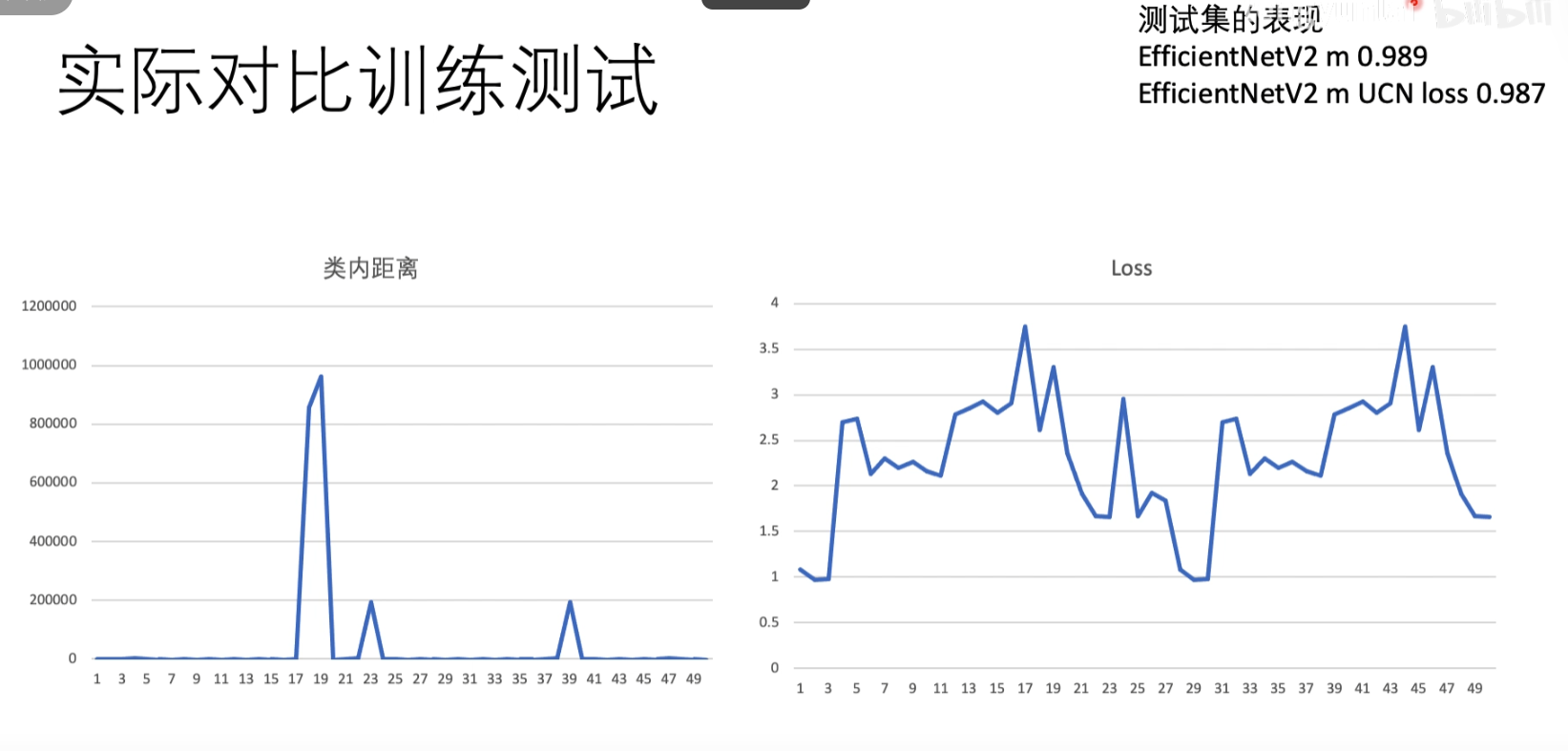
可以看到UCNloss的跳变非常厉害,对图像很敏感
5. SuperPoint Self-Supervised Interest Point Detection and Description(2018)
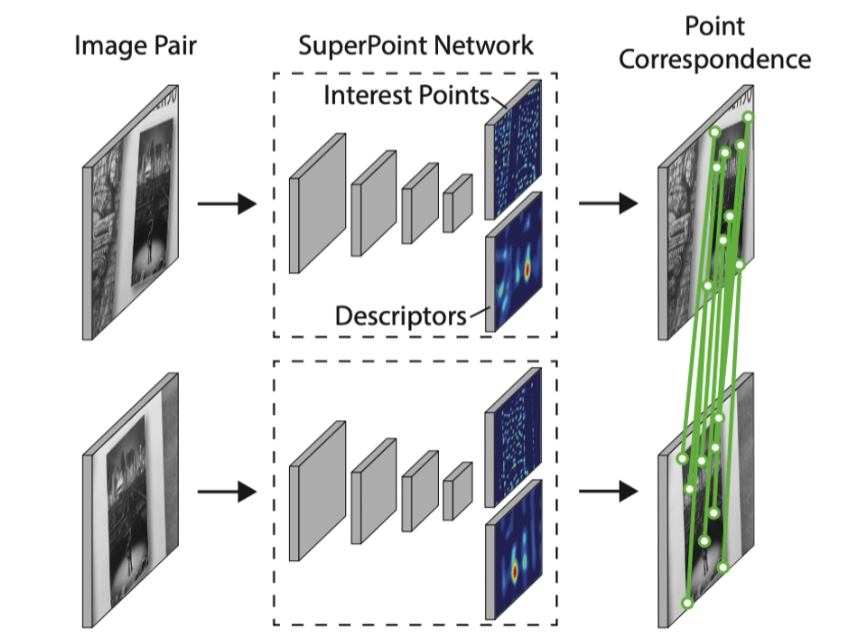
重点在于训练方法
训练网络主体结构

(A)base detector 如何训练
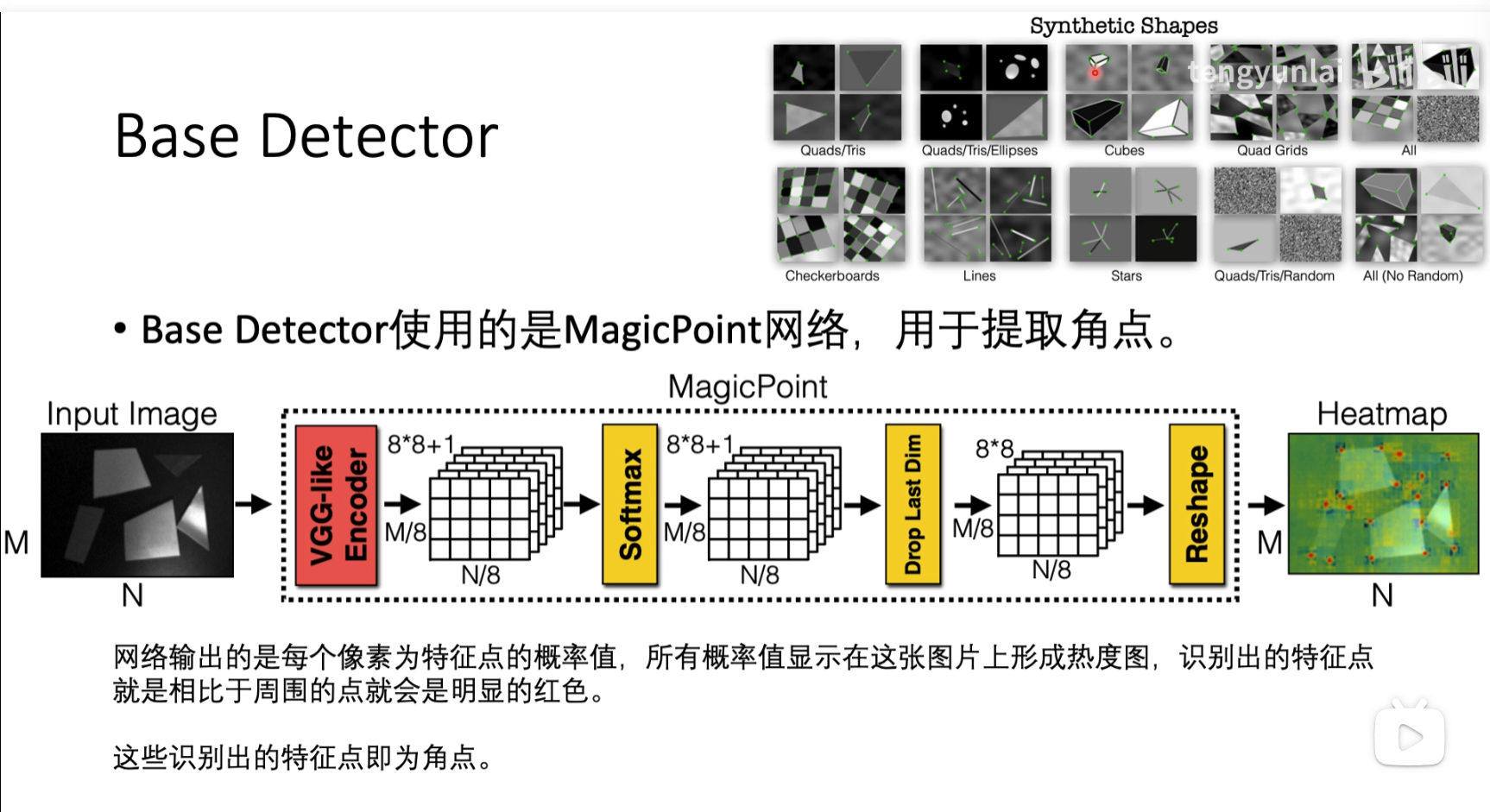
数据集有标注角点的位置,并且有噪声
heatmap中分数比较高的点就是角点,分数比较低的点就不是角点
(B)如何迁移到普通图片

原始图片进行随即变形,再放进刚才的base-detect 提取角点,然后把所有的角点拼到一块生成新的角点,然后重新训练,自我标注技术
(C)joint training
用superpoint提取真正的兴趣点,再对这些兴趣点做loss
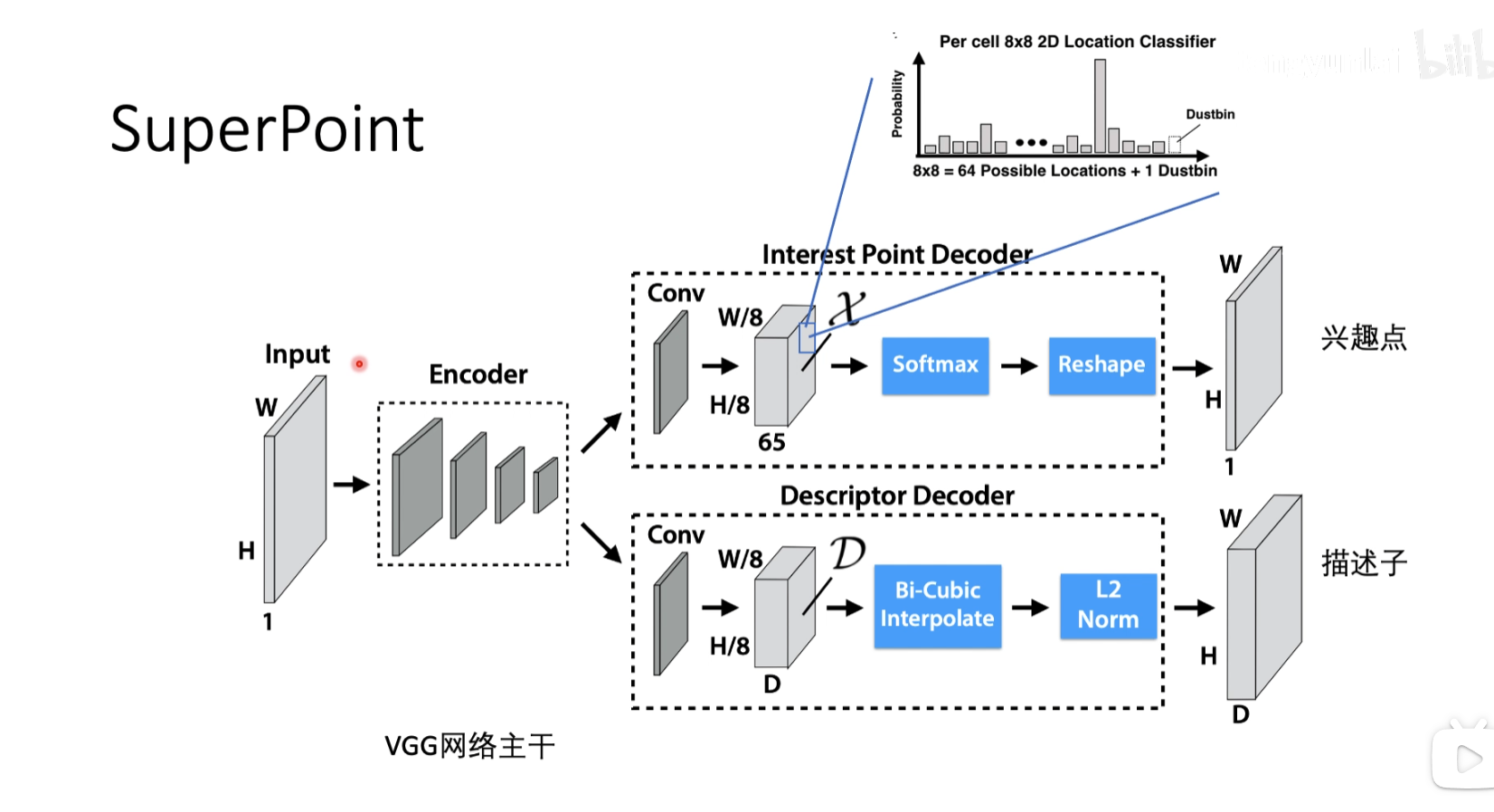
decoder之后会生成这样的矩阵,包含Cell的信息,每一个像素的信息,代表这个坐标点是否能作为兴趣点的信息,值比较高就是能作为兴趣点,值比较低就是不能作为兴趣点,把寻找兴趣点的回归问题换为分类问题
上面是找兴趣点,下面是找描述子,对特征进行一个描述
损失函数

总结
既能提取特征点,又能提取描述子,并且对特征点进行打分
结果

然后这里的比较还是和传统方法比较的
6. SuperGlue:Learning Feature Matching with Graph Neural Networks
在superpoint的匹配方法做了一个改进,不再使用欧式距离方法,做匹配
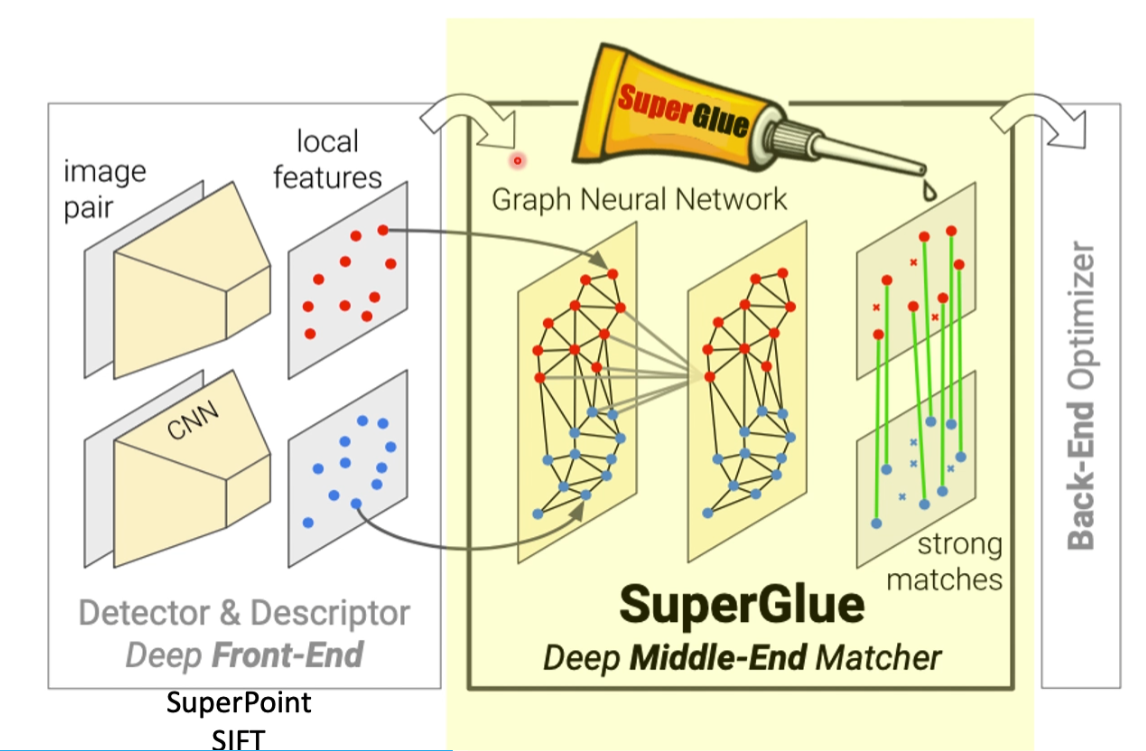
总体框架
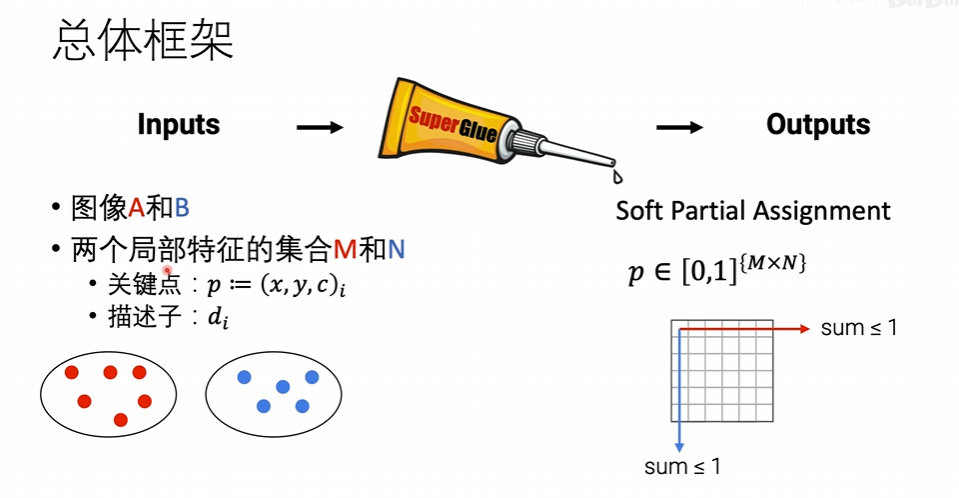
这里的M和N 就是superpoint输出的feature map,P就是对应兴趣点的矩阵,之后会再输出一个矩阵,表示两个点是否是匹配的
网络主体
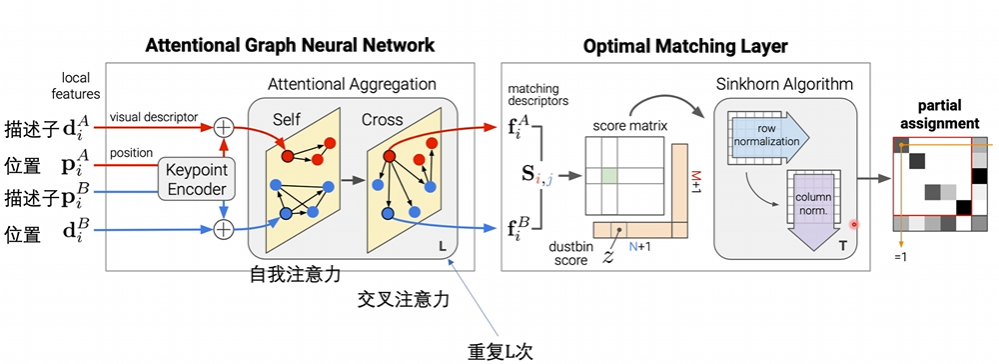
输入部分
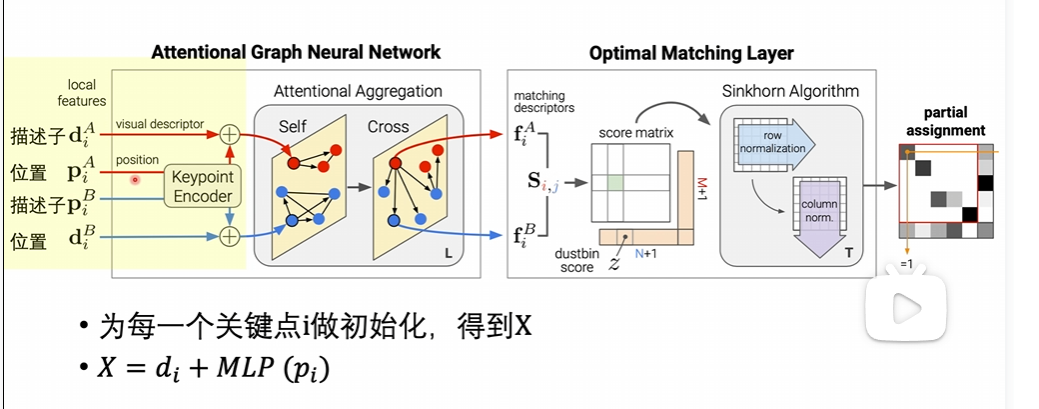
输入部分会输入描述子和位置,会将位置信息encoder到描述子中去,我们的输出是x,
自注意力和交叉注意力
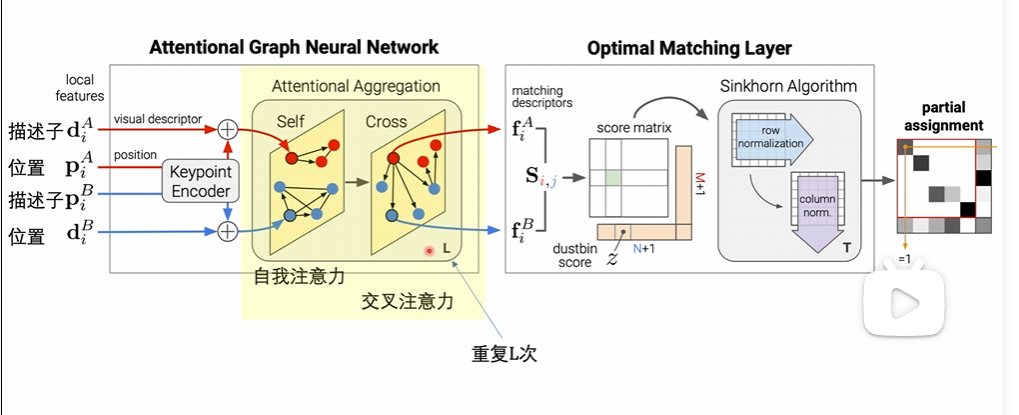

自注意力:单张图的注意力
交叉注意力:两张图一起看的注意力方法
类似于人类反复比较两张图
迭代
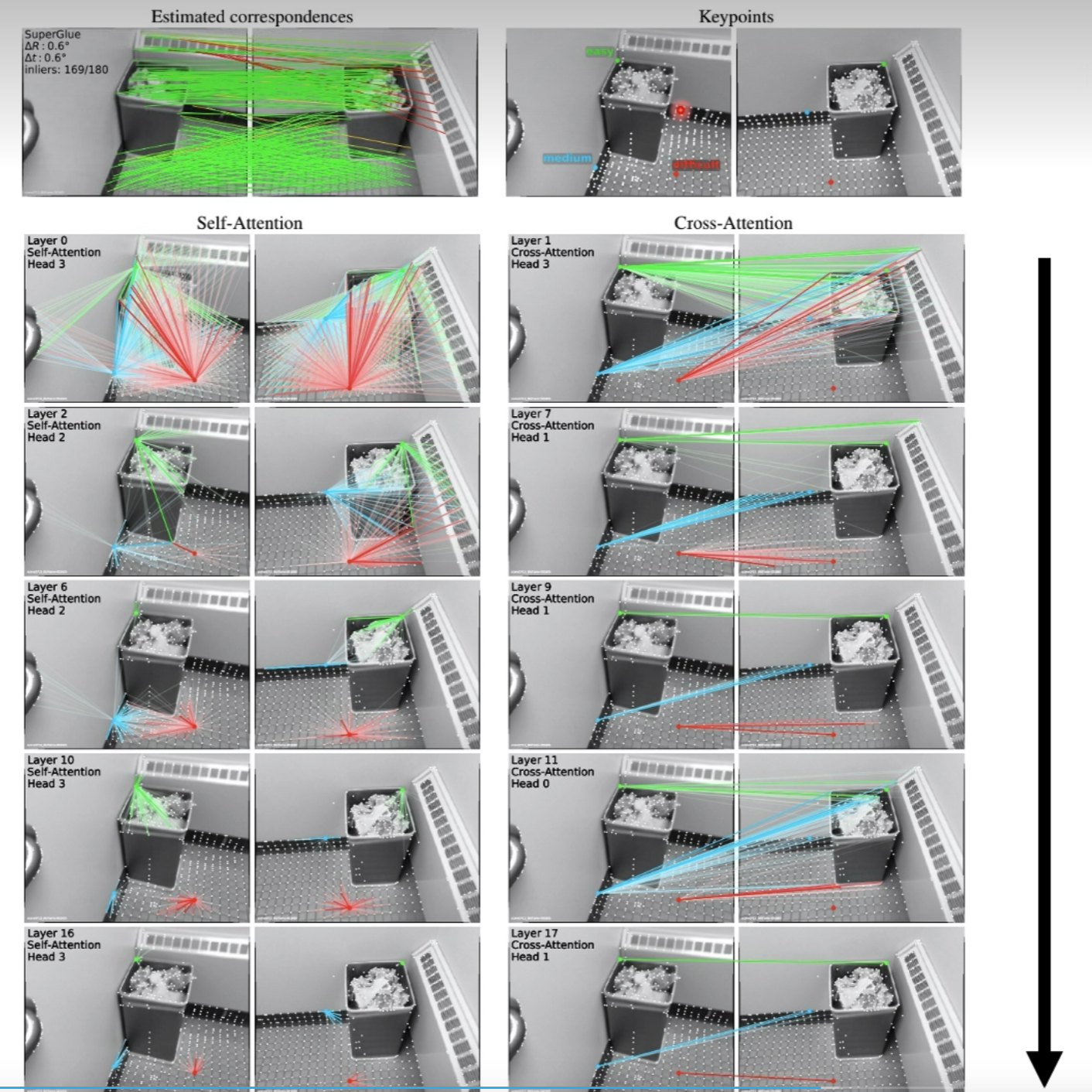
一开始自注意力是发散的,通过迭代,会发生收敛
sinkhorn算法
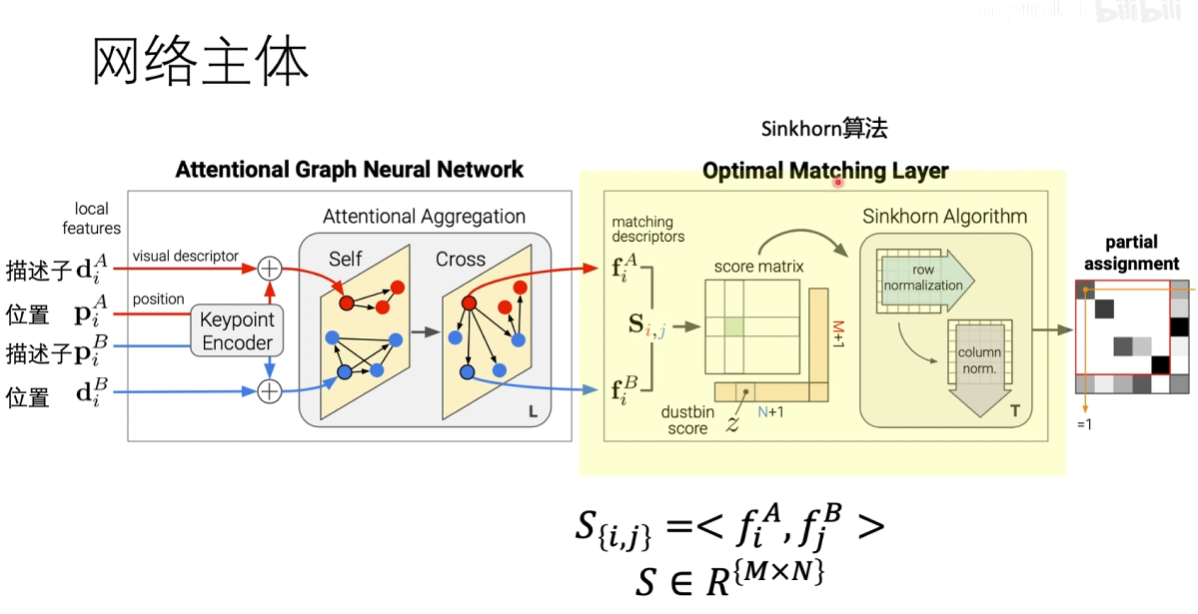
去匹配我们输出的描述符,用的是内积的方法得到一个得分最终放到两个矩阵上
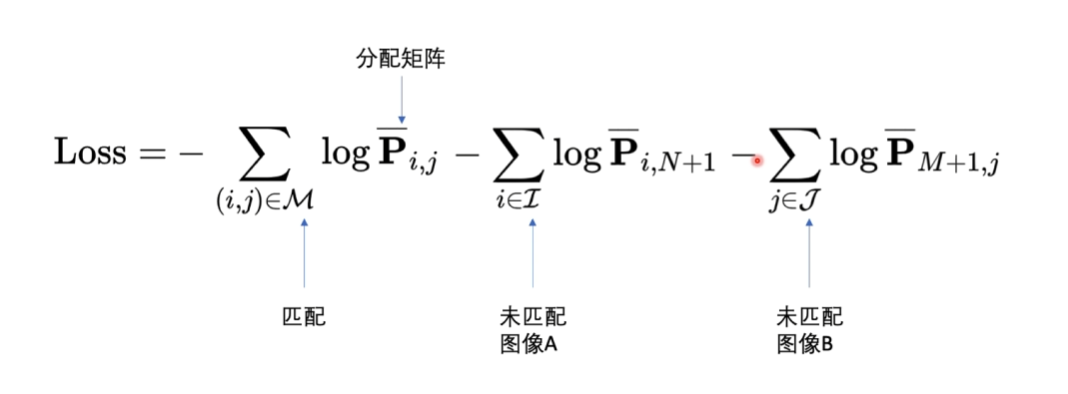
损失函数
结果

绿线代表匹配成功,红线代表错误的匹配
6. Key.Net Keypoint Detection by Handcrafted and Learned CNN Filters(2019)
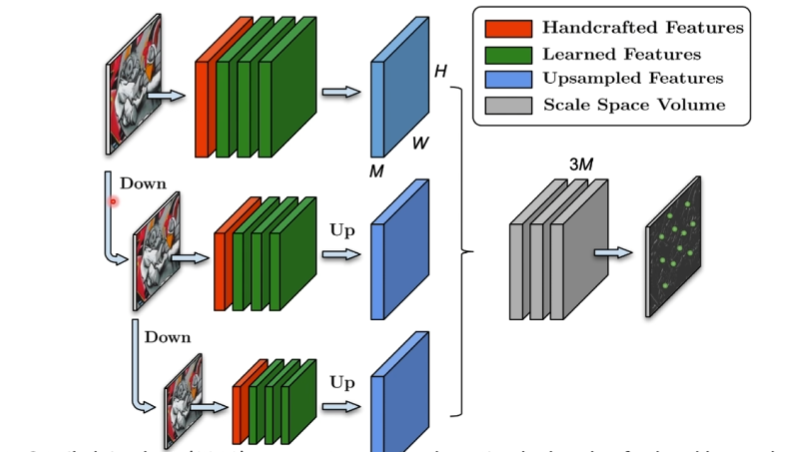
检测关键点的方法,最后的输出并不是提取出的特征而是关键点
主要贡献是用了一阶导数和二阶导数的融合

没有任何的网路结构, 相当于一个手工生成的特征,每一层下采样,用金字塔一样的结构,得到三个相同的feature map (蓝色),三个feature map 放到一块做一个normalization,得到score map,相当于key point
得分比较高的是关键点,得分比较低的是非关键点,得到这样的一个feature map
训练步骤
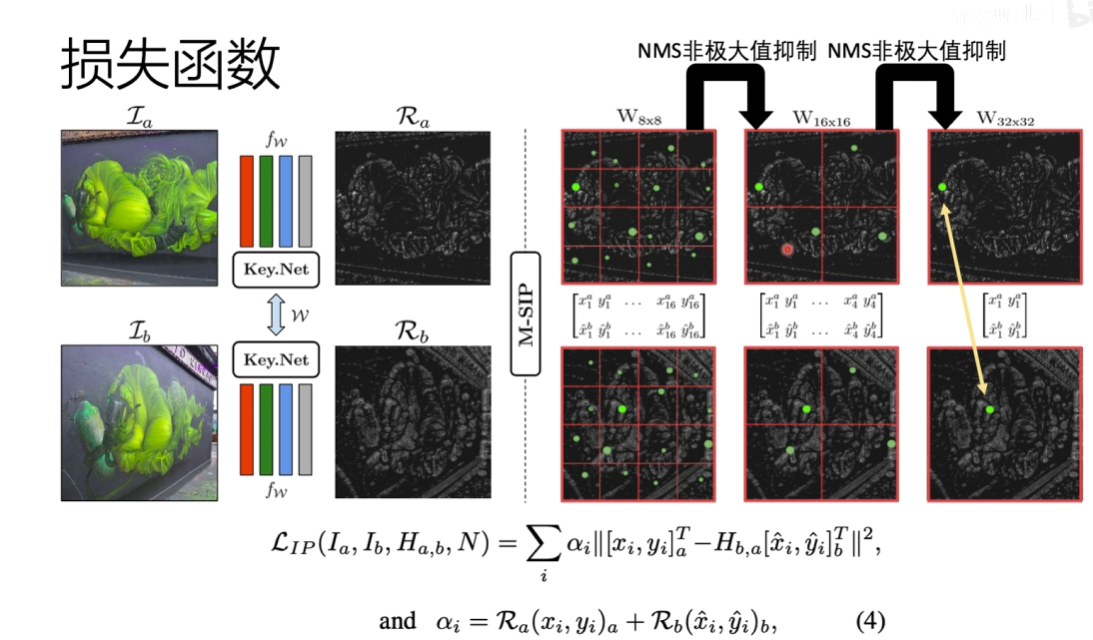
首先会输入两张图片,然后通过刚才的网络,输出分数。先进行分离,对于每一块要通过NMS得到一个得分最高的点,每一块得分最高的点应该是匹配上的
就是看两张图片某个点是比较匹配点,就定为关键点
测试结果

7. IF-Net An Illumination-invariant Feature Network(2020)
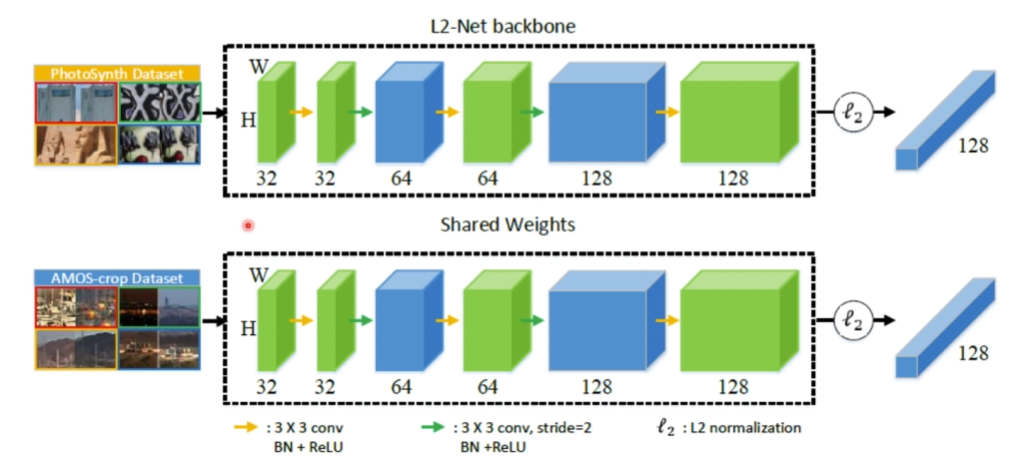
针对光照不变性提出的网络
训练集

特有的顺序:从简单到难
网络结构
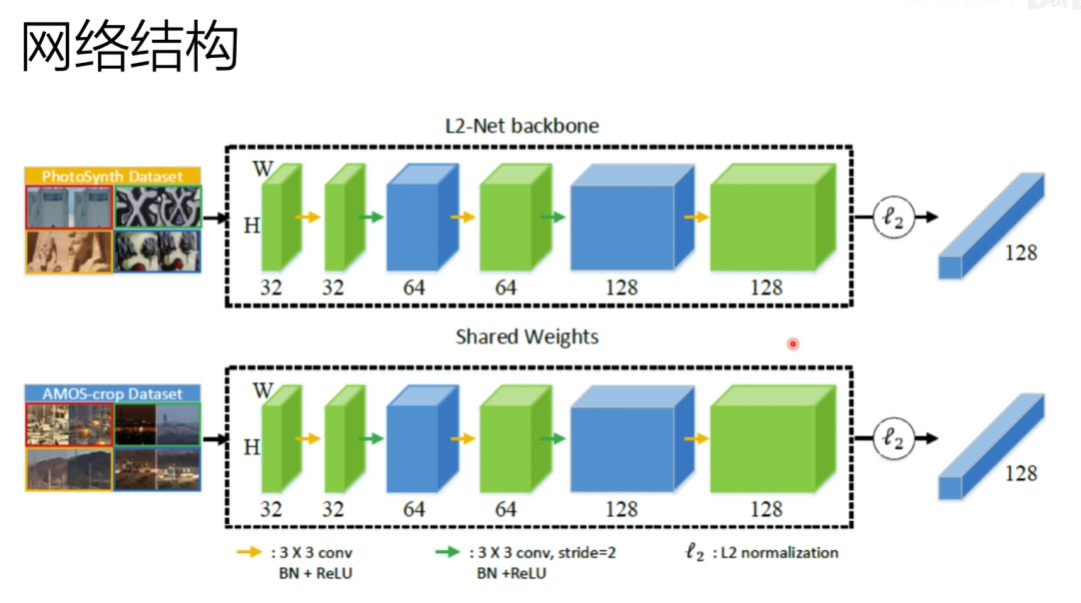
共享权值,双网络训练,上面用ps数据集,下面AMOS数据集,交替训练,取最好的权值进行共享
网络结构用到Lnet
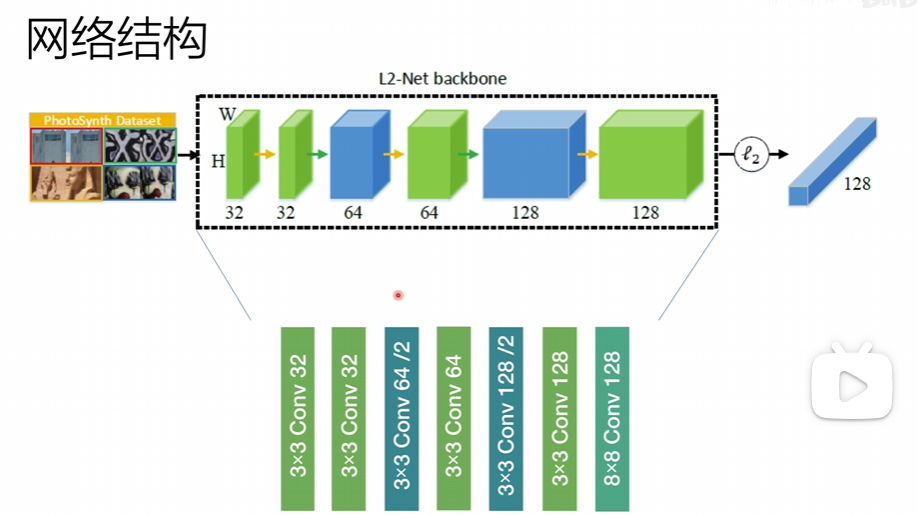
损失函数

最应该被惩罚的值进行一个惩罚
结果

时间轴

方法总结

数据集总结




与传统算法优劣势对比

应用
原文地址:https://blog.csdn.net/weixin_46050242/article/details/135694188
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!