All-Seeing: 面向开放世界的全景物体感知和通用关系理解
实现通用人工智能(Artificial General Intelligence,AGI)是人工智能领域的终极目标。近期,以ChatGPT为代表的大语言模型(Large Language Model,LLM)在文本模态上取得了惊艳的性能。因此在多模态领域,出现了大量的工作尝试以LLM为核心来构建多模态感知模型。然而,这些工作提出的模型只能将图像作为整体进行感知,无法对其中的某个具体的区域或实例进行感知,这就导致用户和模型在针对图像中的某个实例进行提问或回答时,必须通过大量的文字描述来实现对该实例的指代,这极大地提高了交互的难度和成本。
另一方面,近期的一些工作开始尝试将对“指针”的理解和预测融入现有的多模态感知模型。具体而言,用户和模型可以在文本中通过坐标框的形式来对图像中的特定实例进行指代。然而,由于缺少包含“指针”信息的大规模/高质量数据集,这些模型的泛化性并不理想。除此之外,这些模型只能对“指针”指向的特定实例进行理解,对不同实例之间的关系的理解能力仍然欠缺。
针对这一系列问题,我们提出了 All-Seeing 项目群。在数据层面,该项目群提出了包含“指针”信息的超大规模预训练数据集 All-Seeing Dataset (AS-1B) 以及额外包含实例间关系信息的高质量指令微调数据集 All-Seeing Dataset V2 (AS-V2)。而在模型层面,该项目群提出了侧重于判别式任务和生成式任务的统一建模的 All-Seeing Model (ASM) 和侧重于多模态对话、物体感知以及关系理解的 All-Seeing Model v2 (ASMv2)。
值得注意的是,ASMv2在13个图像级benchmarks和7个区域级benchmarks,总计20个多模态benchmarks上取得了SoTA性能。此外,由于具备对实例间关系的指代能力,ASMv2 也可以被应用于语义图生成(Scene Graph Generation)任务,并在该任务上展现出了极具竞争力的性能。

论文:
https://arxiv.org/abs/2308.01907
开源代码(点击“阅读原文”直达):
https://github.com/OpenGVLab/all-seeing/tree/main/all-seeing

论文:
https://arxiv.org/abs/2402.19474
开源代码:
https://github.com/OpenGVLab/all-seeing/tree/main/all-seeing-v2
数据
All-Seeing Dataset
AS-1B 是第一个大规模的区域级图文对齐数据集,涵盖超过350万个现实世界中常见或罕见的概念,包含超过10亿条区域级的标注。这些标注包括针对给定区域的语义标签(Semantic Tag)、问答对(Question-Answer Pair)和区域描述(Region Caption)。与之前的视觉感知数据集和图文对齐数据集相比,该数据集具有更加丰富和详细的实例级标注。
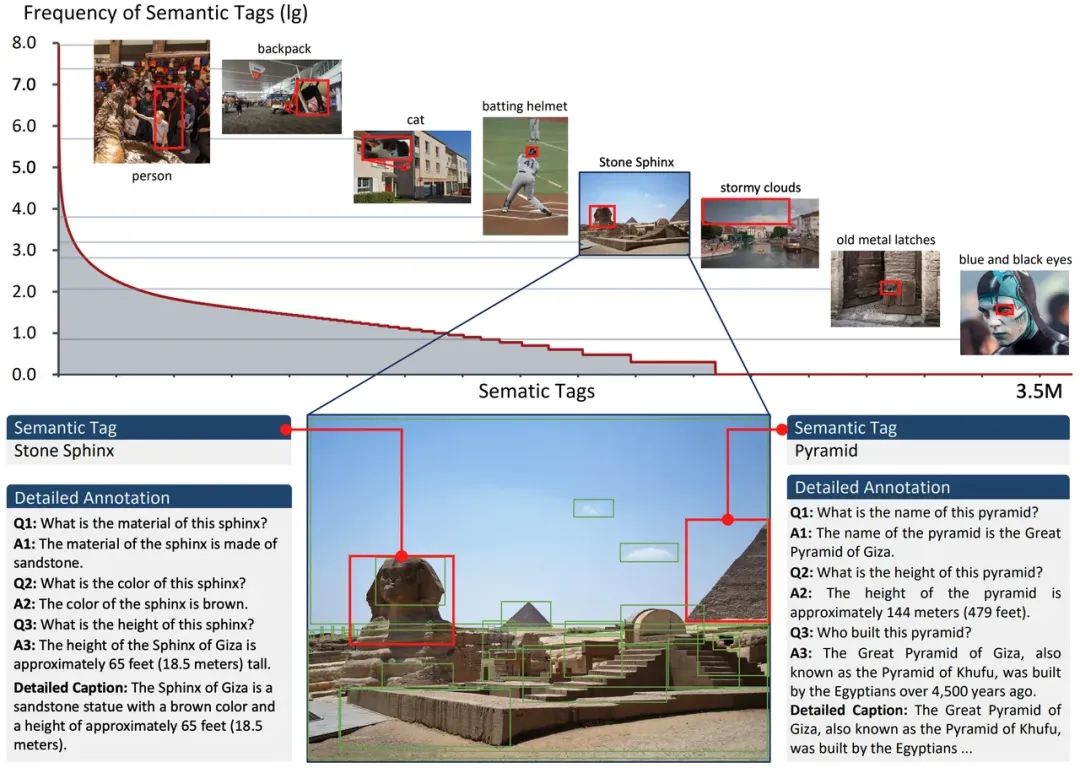
AS-1B 数据集基于该项目群提出的半自动数据标注管线构建,该管线极大地降低了数据集的标注成本。具体而言,该标注管线首先通过现有的最先进的基础模型生成大批量的包含一定噪声的标注(如下图中的(a)(b)(c)(d)所示)。随后从中采样一部分数据进行人工校验,得到一个高质量的子集。接着基于这两批数据训练得到 All-Seeing Model (ASM),并基于 ASM 进行下一轮的数据标注和人工校验。由此,该数据标注管线构成了一个“数据-人工-模型”的循环,从而迭代式地提升数据集的质量。值得注意的是,数据集中经过人工校验的部分会作为一个单独的子集(AS-Core)应用于模型的训练阶段。
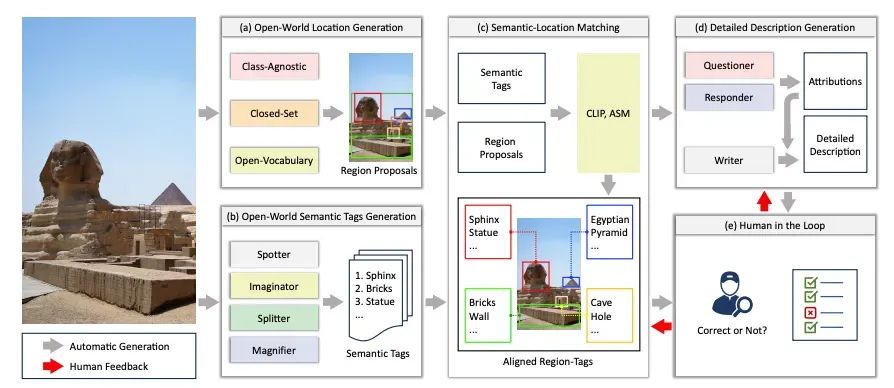
All-Seeing Dataset V2
尽管 AS-1B 和 AS-Core 分别提供了大规模和高质量的区域级图文对齐数据,但是这些数据中仍然缺少针对图像中实例间关系的标注,为此,All-Seeing 项目群进一步推出了 AS-V2 数据集。该数据集中的数据均为VQA的形式,其中不仅包括了常规的文本回答,还将文本中涉及的实例和关系都与图像中的特定区域进行了关联。

该数据集基于COCO图像以及针对该图像的描述(Caption)、定位(Location)和关系(Relation)标注进行构建。其核心思路是是通过GPT-4V生成QA对,同时在生成的过程中,根据提供的定位和关系标注,将文本提到的对象和谓词与图像中的特定区域进行关联。

Circular-based Relation Probing Evaluation
除了上述用于支持模型训练的 AS-1B、AS-Core 以及 AS-V2 数据集,All-Seeing 项目群还提出了一个针对模型对物体间关系理解能力的benchmark,即 Circular-based Relation Probing Evaluation(CRPE)。这是第一个覆盖了关系三元组(主语、谓语、宾语)中全部元素的benchmark,为系统地评估模型的关系理解能力提供了一个可靠的平台。
除了基于PSG数据集标注生成的数据,CRPE还额外包括了基于DALLE-3生成的数据,这些数据针对现实世界中合理但少见的关系三元组构建,进一步提升了CRPE评估的覆盖范围。

模型
All-Seeing Model
All-Seeing Model(ASM)是一个同时支持判别式任务和生成式任务的统一模型,该模型在 Image Captioning、VQA 等图像级任务以及 Region Captioning、Region Recognition 等区域级任务上都展现出了强大的性能。其模型结构包括视觉编码器(OpenCLIP-1B)、视觉-语言连接器(Q-Former)和语言模型解码器(Vicuna-7B)。其中的视觉-语言连接器基于Q-Former结构构建,同时为了更好地理解区域信息,该结构还额外引入了 RoI Align 操作根据给定的坐标框抽取对应的区域特征,并将这部分特征作为 query tokens 输入给 Q-Former。最终,这部分 query token 抽取的区域特征将和原有的随机初始化的 query token 抽取的全局特征一起输入给 LLM 进行信息解码。
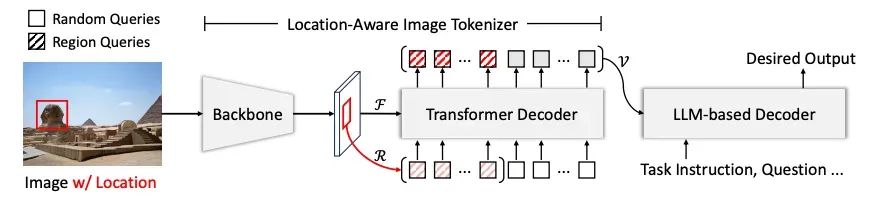
在处理判别式任务时,模型分别将图像序列和文本序列放入不同的提示模板(Prompt Template)中进行编码,并在最后加上特殊的“<align>”字符,取该字符作为全局编码。而在处理生成式任务时,则和常规的多模态大语言模型一样,同时输入图像和文本序列,随后进行自回归地文本生成。在处理不同的任务时,提示词(Prompt)中会包含不同的可训练的软提示(Soft Prompt)来帮助模型区分当前正在执行的任务。

All-Seeing Model v2
All-Seeing Model v2(ASMv2)是一个能力全面并且性能强大的多模态大语言模型(Multimodal Large Language Model,MLLM),该模型在保持强大的通用能力的同时集成了关系对话(Relation Conversation,ReC)能力。ASMv2 可以处理的任务包括(1)关系对话:模型会将生成的文本回复中提到的所有实例和实例间的关系与图像中相应的区域联系起来;(2)开放式场景图生成:模型可以根据给定图像生成对应的场景图(Scene Graph);(3)常规多模态对话:与现有的其他多模态大语言模型一样,ASMv2 也可以进行基于图文的对话。相比 ASM,ASMv2 更侧重于多模态对话过程中,对图像中物体及物体间关系的感知和理解。
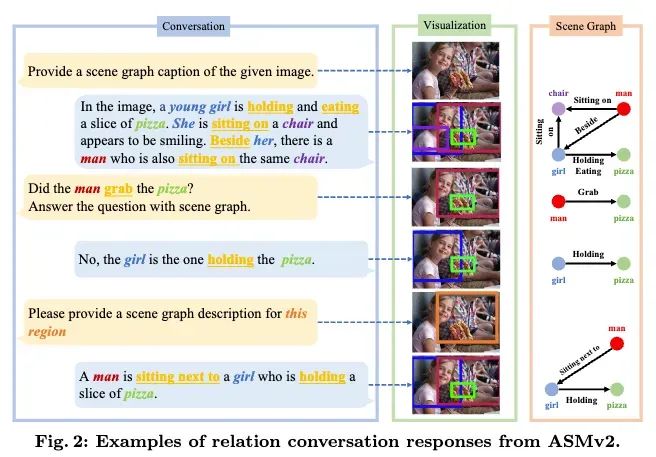
ASMv2的模型结构与 LLaVA-1.5 一致,使用 CLIP-L-336 作为视觉编码器,Vicuna-13B 作为语言模型解码器,两层MLP作为中间的视觉-语言连接器。与 ASM 不同,ASMv2 直接基于文本中提供的坐标框来理解图像中的区域,不再需要额外的 RoI Align 操作去辅助理解区域信息。具体而言,在关系对话的过程中,文本中的所有实体和谓词会分别通过<ref></ref>和<pred></pred>进行标注。每一个实体后面会跟上一个<box>[[x1,y1,x2,y2]]</box>格式的坐标框文本,用于表明该实体在图像中的位置。类似的,每个谓词后面会跟上两个坐标框文本,用于表明该谓词的主语和宾语在图像中的位置。值得注意的是,这样的关系对话文本可以很自然地被解析成语义图(Scene Graph)。具体而言,其中由<ref></ref>标记的实体可以作为语义图中的节点,而由<pred></pred>标记的谓词可以作为语义图中的边。

实验
实验结果表明,ASMv2在13个图像级benchmarks和7个区域级benchmarks,总计20个多模态benchmarks上取得了SoTA性能。其中,ASMv2在MMBench上相比 LLaVA-1.5 提高了6.7个点,在MME上提高了89.7个点。
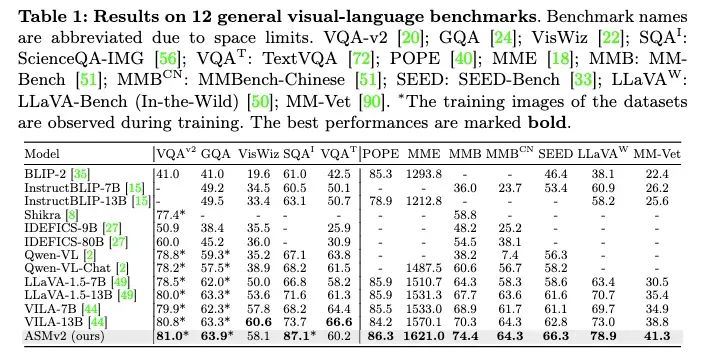
在区域级benchmarks上,ASMv2在指代理解(Referring Expression Comprehension)任务上相比Qwen-VL平均提升了约1.7个点。而在Region Captioning和Referring Question Answering任务上,ASMv2也取得了SoTA的性能。
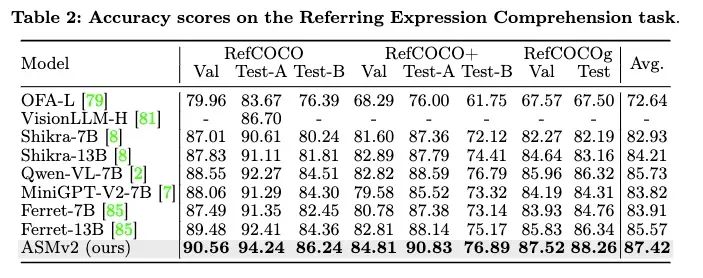
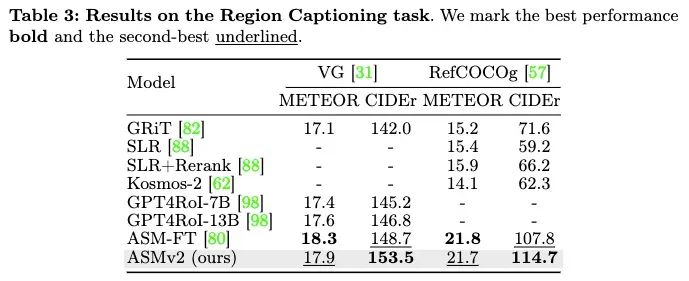
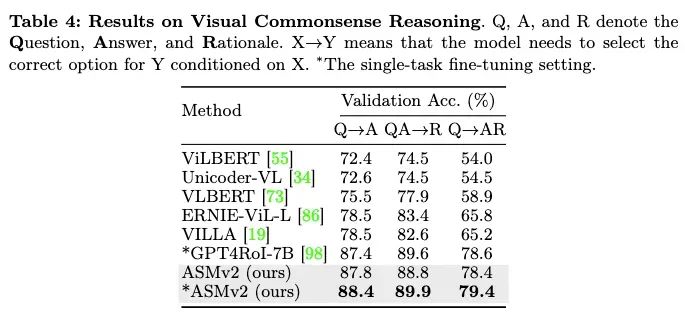
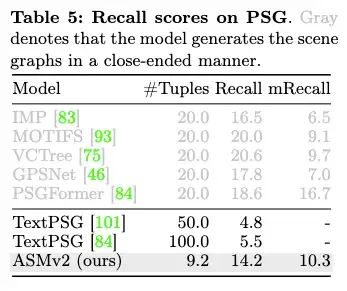
在语义图生成(Scene Graph Generation)任务上,ASMv2也展现出了卓越的性能。值得注意的是,相比传统的语义图生成模型,ASMv2不仅可以通过开放式(open-ended)的方式生成语义图,从而避免受限于少数预定义的类别,也可以保留其他多模态大语言模型的通用性能,因而具有更广泛的应用范围。
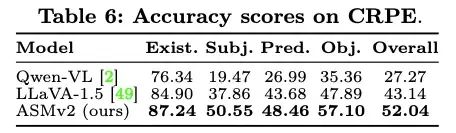
在CRPE benchmark上,ASMv2同样表现出了SoTA的性能,相比LLaVA-1.5,关系理解的整体性能提升了接近9个点,证明了ASMv2具有更优的物体间关系理解能力。
论文:
https://arxiv.org/abs/2308.01907
开源代码:
https://github.com/OpenGVLab/all-seeing/tree/main/all-seeing
原文地址:https://blog.csdn.net/OpenGVLab/article/details/142852458
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!