GPU 张量核心(Tensor Core)技术解读

一文理解 GPU 张量核心(Tensor Core)
引言
最新一代Nvidia GPU搭载Tensor Core技术,本指南深度解读其卓越性能,为您带来极致体验。
Nvidia最新GPU微架构中的核心技术——Tensor Core,自Volta起每代均获突破,其专门处理子单元在自动混合精度训练的加持下,显著提升了GPU性能,为计算领域带来革新动力。
本文精要概述NVIDIA Volta、Turing及Ampere系列GPU中Tensor Core的卓越能力。深入解析不同GPU核心的功能,揭示Tensor Core在深度学习混合精度训练中的工作原理。我们还将对比各微架构Tensor Core的性能,助您快速识别基于Tensor Core的GPU。一文在手,NVIDIA GPU的Tensor Core能力尽在掌握!
什么是CUDA核心?
深入Tensor Core架构与实用性前,先聚焦CUDA核心。CUDA,即计算统一设备架构,是NVIDIA独家打造的并行处理平台与GPU API。CUDA核心,作为NVIDIA图形卡的标准浮点单元,近十年已成为每款NVIDIA GPU不可或缺的核心特征,更是GPU微架构的标志性元素,引领着计算性能的新纪元。
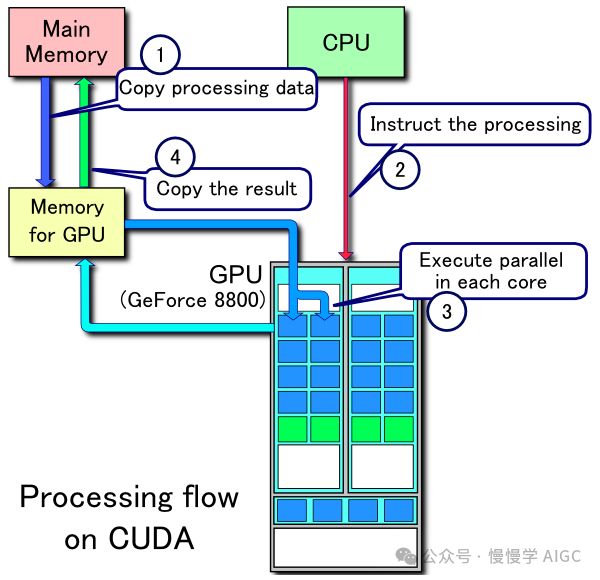
CUDA核心具备计算能力,每核每时钟周期可执行乘加操作。尽管单核性能略逊于CPU,但CUDA核心通过并行执行,在深度学习中显著加速计算过程,实现高效能。
Tensor Core发布前,CUDA核心曾是深度学习加速的基石,但受限于其单一计算能力,GPU性能受限于CUDA核心数量和时钟速度。为打破这一桎梏,NVIDIA创新研发Tensor Core,引领深度学习硬件性能飞跃。
什么是 Tensor Core?
Tensor Core是专为混合精度训练设计的核心,其第一代通过乘加融合计算,实现4x4 FP16矩阵相乘并高效整合至4x4 FP16或FP32矩阵,显著提升计算效率。
混合精度计算得名于其特性:输入矩阵虽为低精度FP16,但输出仍为FP32,精度损失极小。此技术极大加速计算,几乎不影响模型最终效果。更先进的微架构已将其扩展到更低精度数字格式,提升计算效率。
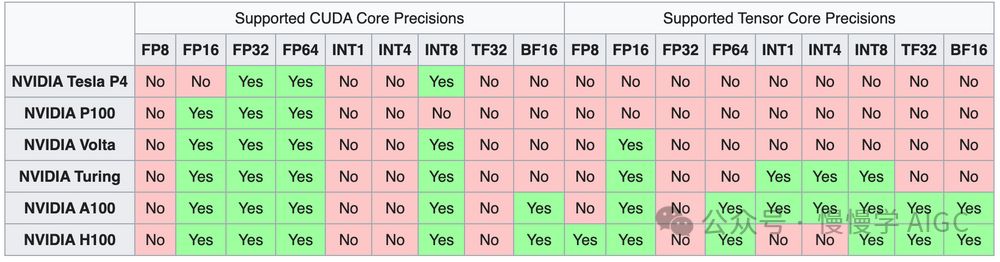
Tensor Core伴随Volta微架构的V100问世,每代更新都激活更多计算机数字精度格式,助力新GPU微架构计算力升级。接下来,我们将深入探讨各代微架构如何不断革新Tensor Core的功能与性能,引领计算新纪元。
Tensor Core如何工作?
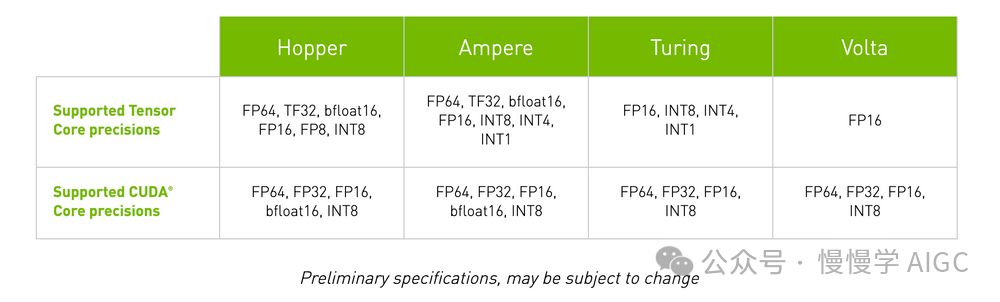
每一代GPU微架构均革新Tensor Core性能,拓展其能力以支持多种计算机数字格式。这一变革显著提升了每代GPU的吞吐量,展现了GPU技术的持续进化与卓越性能。
第一代
Pascal与Volta计算可视化:对比带Tensor Core与不带Tensor Core的性能差异。
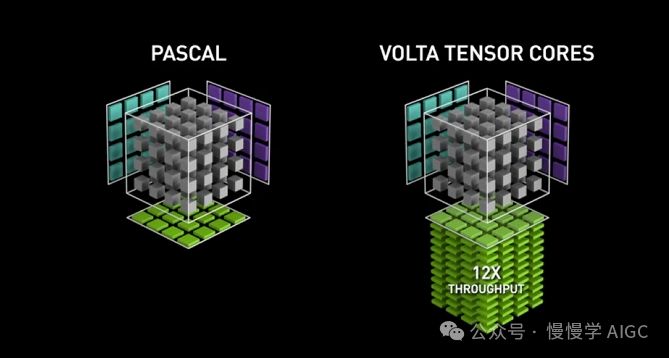
Tensor Core与Volta GPU微架构一同诞生,凭借FP16数字格式实现混合精度训练,其潜在吞吐量较之前提升高达12倍,以teraFLOPs计算。旗舰V100搭载的640个Tensor Core,相较于Pascal GPU,性能飙升5倍,展现出无与伦比的计算优势。
第二代
带有 Pascal 和 Turing 计算的可视化,比较不同精度格式的速度
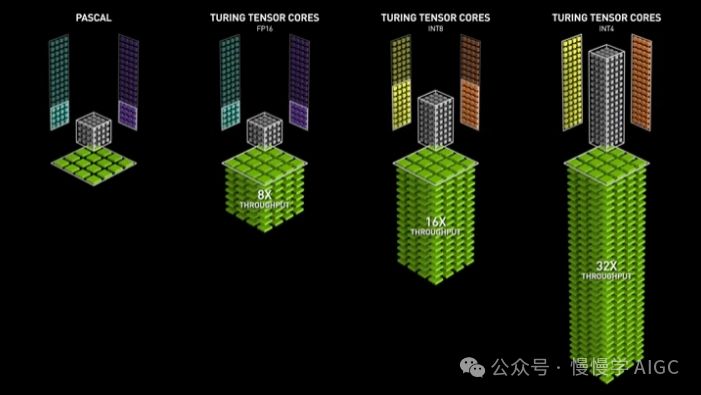
随着Turing GPU的问世,第二代Tensor Core惊艳亮相。它支持FP16、Int8、Int4及Int1等多种精度,为混合精度训练注入了新动力。这一革新使得GPU性能吞吐量飙升,相比Pascal GPU,性能提升高达惊人的32倍!
Turing GPU不仅继承了第二代GPU的卓越性能,更搭载了光线追踪核心,精准计算3D环境中的图形可视化属性。借助Paperspace的RTX Quadro GPU,这些核心将为您的游戏和视频创作带来前所未有的升级体验。
第三代
Ampere系列GPU搭载第三代Tensor Core,相比FP16精度,性能卓越,堪称史上最强版本。
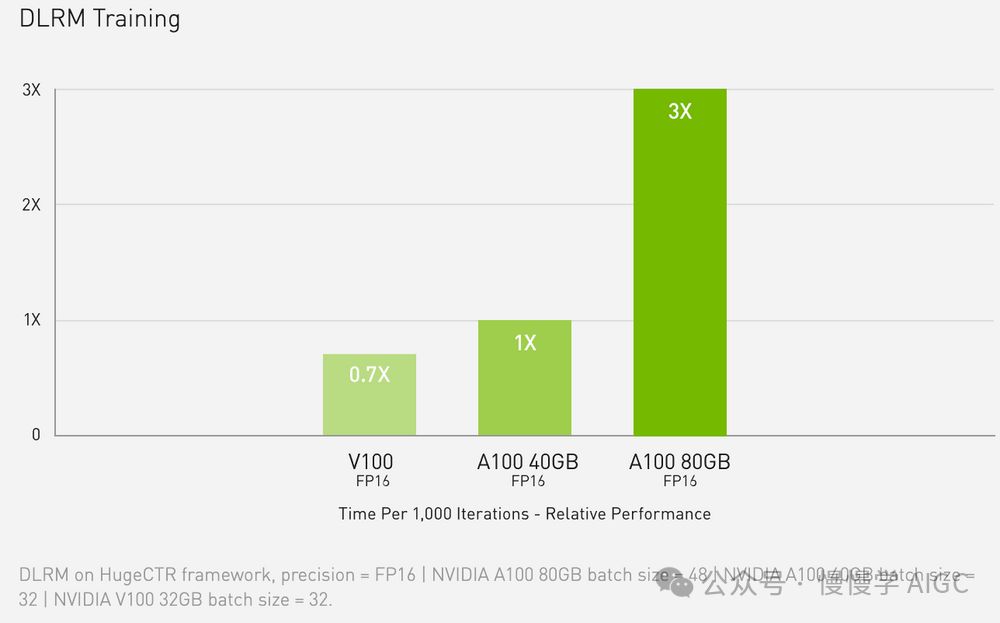
Ampere GPU架构在Volta与Turing微架构的基础上,创新性地支持FP64、TF32和bfloat16精度,显著加速深度学习训练和推断。TF32与FP32相似,却实现高达20倍的速度飞跃,无需代码改动。自动混合精度技术的引入,更使每行代码额外提速2倍,全面释放计算潜能,助力深度学习飞速前行。
第四代
第四代Tensor Core随Hopper微架构发布,H100于2022年3月宣布,新增FP8精度格式处理功能。NVIDIA宣称,这一突破将大幅提升大型语言模型训练速度,较上一代快达30倍,开启AI计算新纪元。
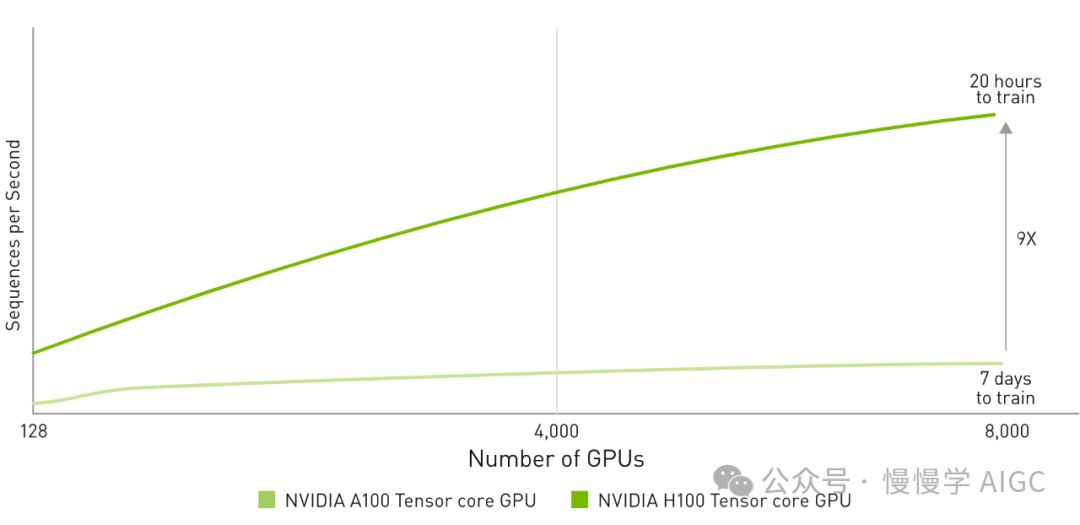
NVIDIA全新NVLink技术可连接高达256个H100 GPU,为数据工作者提供前所未有的计算规模优势,助力其实现更高效的数据处理。
Paperspace GPU云精选五代GPU,涵盖Maxwell、Pascal、Volta、Turing及最新Ampere微架构,满足您不同计算需求,助您轻松驾驭高性能计算时代。
Maxwell与Pascal微架构先于Tensor Core与光线追踪核心问世。深度学习基准测试揭示,在相似规格下(如内存),新型微架构显著优于旧款,这种性能差异在硬件构成上尤为明显,凸显了技术革新的重要性。
V100,Paperspace上独享Tensor Core技术的GPU,虽无光线追踪核心,仍堪称深度学习领域的佼佼者。作为首款搭载Tensor Core的数据中心GPU,V100因设计较旧,在深度学习性能上已略逊于现代工作站GPU如A6000,但其在业界的地位与实力依旧不容忽视。
Paperspace平台推荐工作站GPU RTX4000与RTX5000,为深度学习提供卓越预算方案。特别地,RTX5000凭借第二代Tensor Core的增强功能,在批处理与完成时间上几乎媲美V100,是您深度学习的明智之选。
Ampere GPU系列搭载第三代Tensor Core与第二代光线追踪核心,引领吞吐量飞跃至1555 GB/s的新高度,远超V100的900 GB/s,展现无与伦比的性能提升,为您带来前所未有的计算体验。
Paperspace的Ampere GPU工作站线除A100外,还涵盖A4000、A5000和A6000。这些产品凭借卓越的吞吐量和强大的Ampere微架构,在更经济的价格点上展现了出色的性能。
H100搭载Hopper微架构,将GPU性能提升至A100最大峰值的6倍。据Nvidia CEO黄仁勋在GTC 2022演讲中透露,这款性能卓越的H100将于2022年三季度后正式上市,为科技界带来全新革命。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-
原文地址:https://blog.csdn.net/njbaige/article/details/140262829
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!