机器学习笔记(一)初识机器学习
1.定义
机器学习是一门多学科交叉专业,涵盖概率论知识,统计学知识,近似理论知识和复杂算法知识,使用计算机作为工具并致力于真实实时的模拟人类学习方式,并将现有内容进行知识结构划分来有效提高学习效率。
机器学习有下面几种定义:
(1)机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能。
(2)机器学习是对能通过经验自动改进的计算机算法的研究。
(3)机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。
简要概念:让机器具备找一个函式的能力

2.机器学习的三种不同任务
1. Regression(回归分析)
定义:回归分析是研究自变量与因变量之间数量变化关系的一种分析方法。它主要是通过因变量Y与影响它的自变量X(可以是一个或多个)之间的回归模型,衡量自变量X对因变量Y的影响能力,进而可以用来预测因变量Y的发展趋势。
特点:
- 预测目标是一个连续值。
- 损失函数(如均方误差MSE)用于衡量预测值与真实值之间的差异。
- 常见的回归模型包括线性回归、多项式回归等。
应用:
- 预测房价、股票价格等连续数值。
- 在语音识别中预测声音信号的连续特征。
理解:找一个函式的任务

2. Classification(分类)
定义:分类是找一个函数判断输入数据所属的类别。这可以是二类别问题(是/不是),也可以是多类别问题(在多个类别中判断输入数据具体属于哪一个类别)。
特点:
- 预测目标是离散值,即类别标签。
- 损失函数(如交叉熵损失)用于衡量预测类别与实际类别之间的差异。
- 常见的分类算法包括逻辑回归、决策树、支持向量机(SVM)、神经网络等。
应用:
- 邮件分类(垃圾邮件/非垃圾邮件)。
- 人脸识别、语音识别等。
理解:从设定好的选项中选择一个输出的任务

3. Structured Learning(结构化学习)
定义:结构化学习是一种让机器学会从数据中提取结构化信息的强大技术。它能够将输入数据与输出数据之间的结构关系建模,并通过训练模型来学习这种关系,从而实现对新的输入数据进行预测。
特点:
- 输入和输出都是具有结构化的对象(如序列、树、图等)。
- 需要考虑输入与输出之间的复杂结构关系。
- 常见的结构化学习方法包括条件随机场(CRF)、结构化感知机(Structured Perceptron)等。
应用:
- 自然语言处理中的命名实体识别、句法分析。
- 计算机视觉中的图像分割、目标跟踪。
理解:让机器可以创造

3.机器如何找函式(Linear Models)

1.找未知的函式

y是已知的,b,w是未知的
2.定义Loss
是一个关于b,w的函式,可记作L(b,w),用来记录预期与实际值的差值平均数
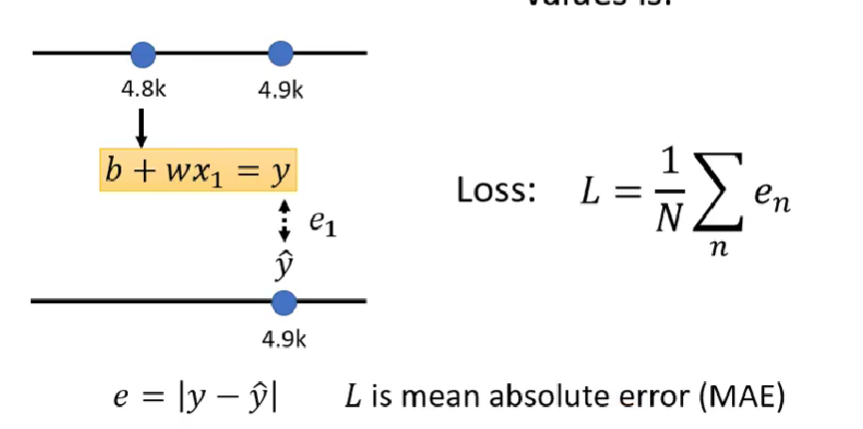
取绝对值计算e的方式叫做MAE,除了这种方式还有如下方式:
![]()
Loss值越大及正确率越低,反之越高
3.找未知函数的最佳值
如下这张图是对不同w值和相同b值下Loss的变化曲线
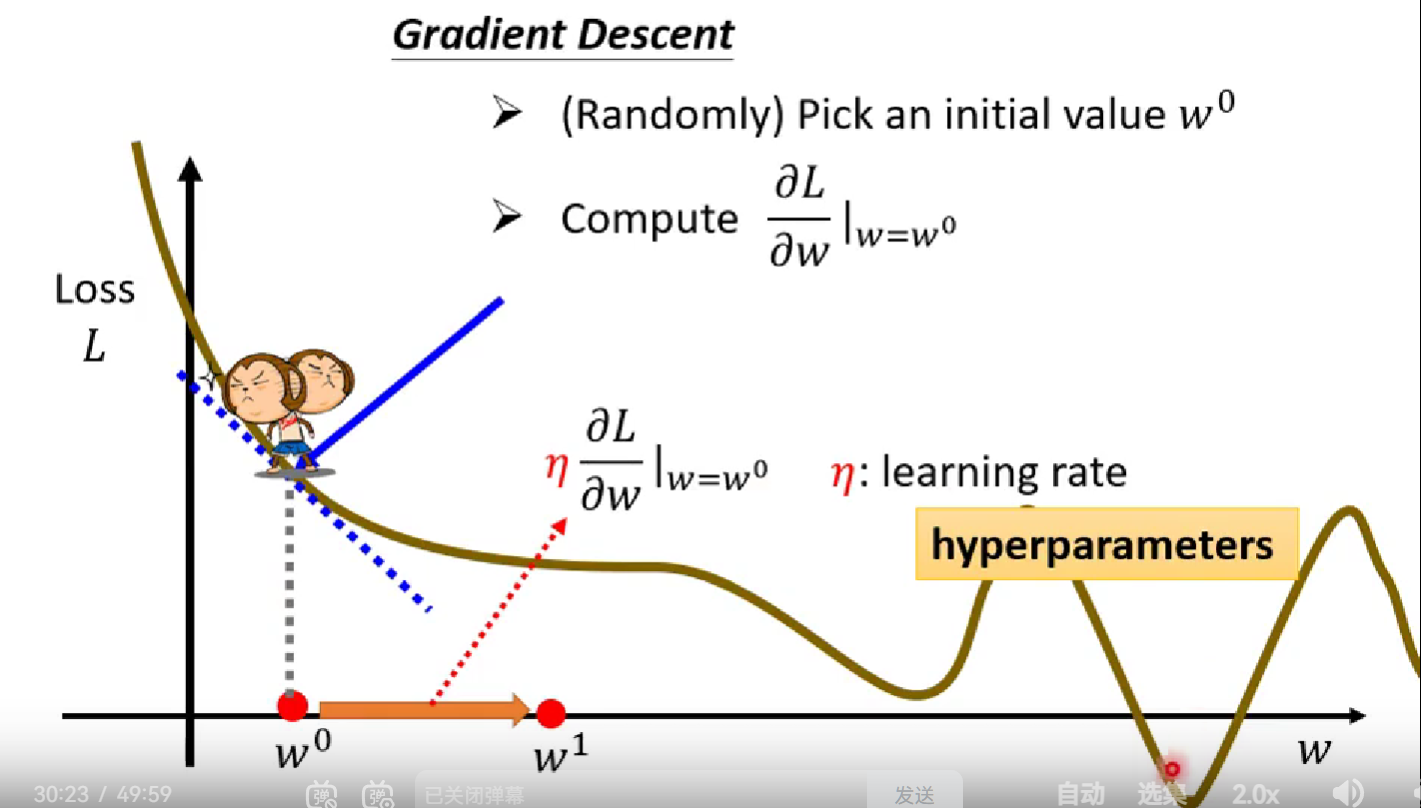
通过观察斜率调整w的值找到函数最佳值,此外w调整的大小不仅仅受斜率大小的影响还受learning rate的影响,learning rate(hyperparameters)是预设的参数。当Loss值最低时即为最佳值。
当然变值一般有多个,此时遇上的不同在于斜率已不能作为观测值,通过微分参数作为观测值。
提升准确值:
通过对有规律周期的多组数据的w和x进行平均值求取提高准确率。

4.突破Linear Models限制
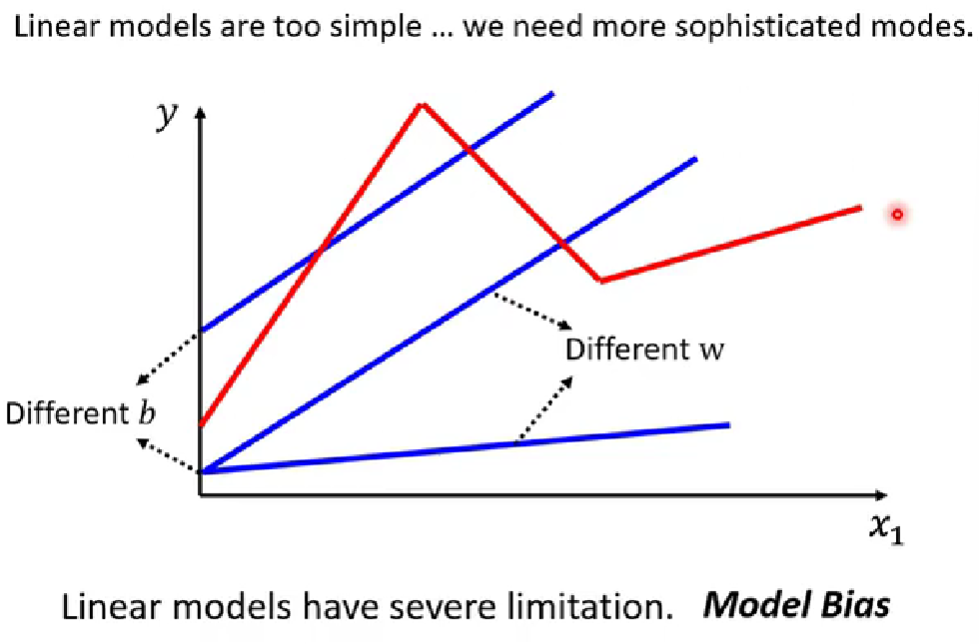
蓝色曲线作为linear models不能模拟实际的情况需要通过多个函式分段模拟,如下:

当然实际情况可能是曲线,这需要通过更多的分段来进行逼近
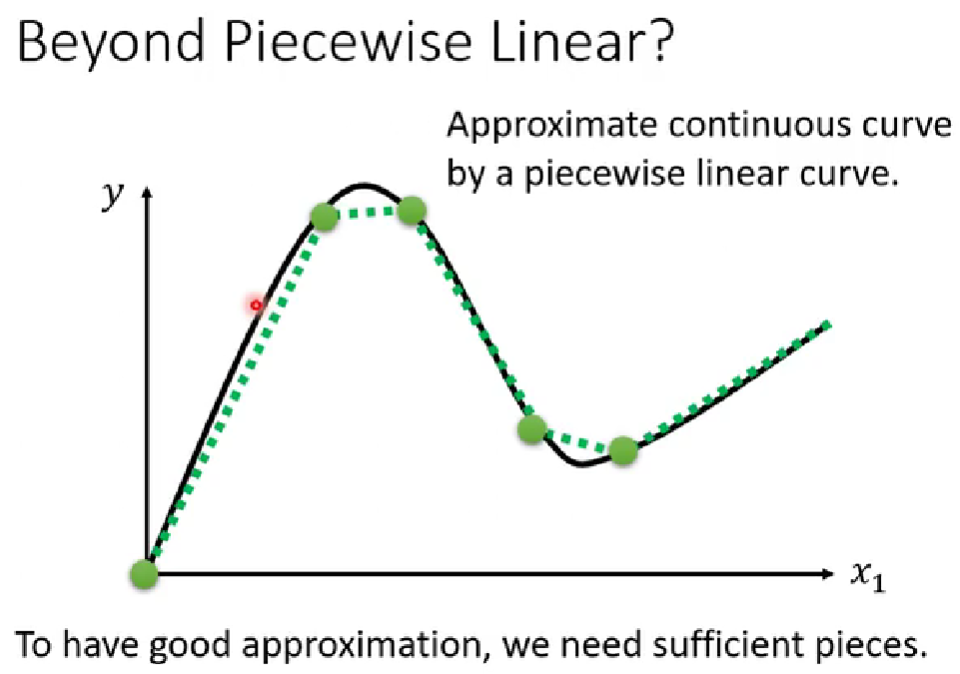
这种折线可通过一种曲线函数更好的表示,这种曲线叫做Sigmoid Function即s型的曲线

调整不同参数可将曲线进行不同方式的调整,如下:
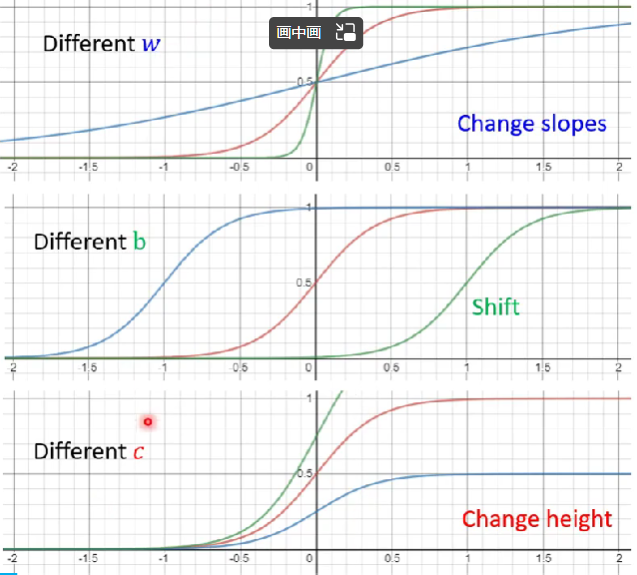
通过以上知识,红色曲线可通过如下进行表示:
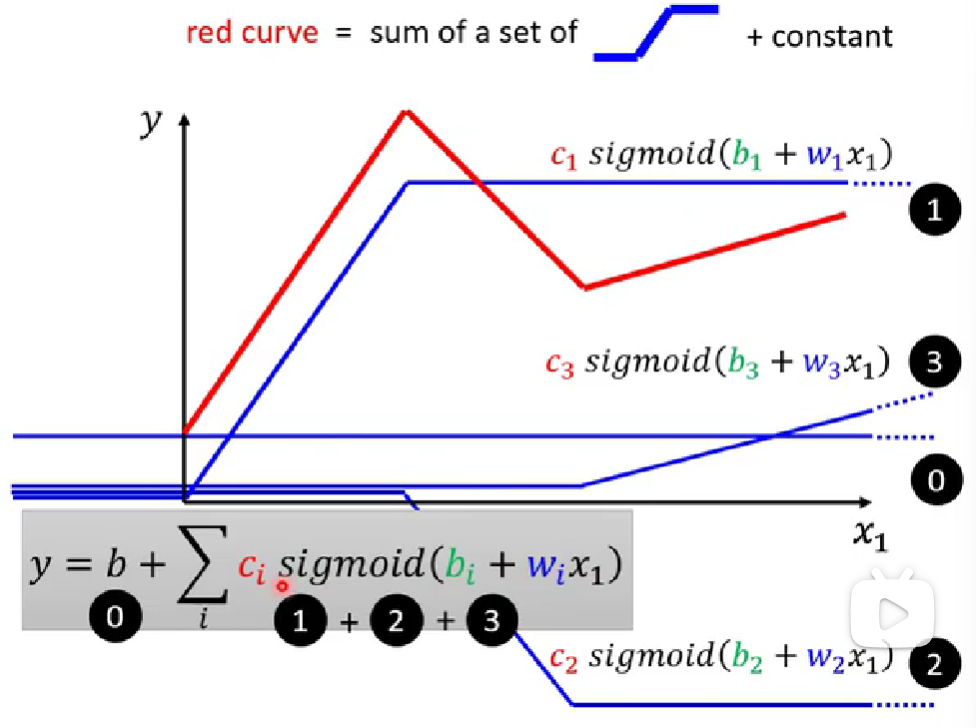
提升模型的准确性

公式的矩阵表示:


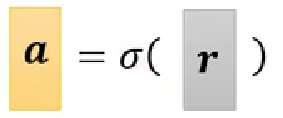
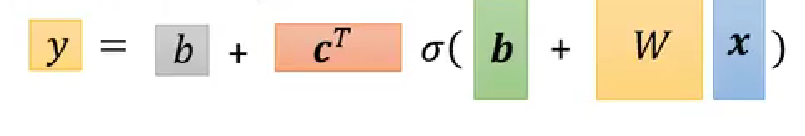
原文地址:https://blog.csdn.net/weixin_53333436/article/details/142398955
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!