StyleGAN——定制人脸生成思路
定制人脸生成思路
- 控制生成码 ( Z ) 的分布范围:适合粗略控制生成图像的主要特征(如性别、人种、年龄),方法简单但精度较低。
- 特定维度特征的替换:适用于细致控制图像的特征(如皮肤颜色、发型),实现复杂,需要精确调整生成器内部特征。
- Info-StyleGAN:结合 InfoGAN 和 StyleGAN,能够同时控制图像的多种特征,提供灵活和高质量的图像生成,但实现和训练复杂。
1. 控制生成码 ( Z ) 的分布范围
1.1 方法描述:
-
源头控制生成码 ( Z ) 的分布范围,这种方法涉及对潜在空间的操作,以控制生成图像的粗略特征。
-
通过调整潜在变量 ( Z ) 的范围和分布,可以影响生成图像的主要特征,例如性别、人种、年龄等。
1.2 具体实现
定制人脸生成需要3个神经网络,分别是Z码生成器,图片生成器,和图片分类器。它的主要思想是,针对我们想要的特定类型的图片,首先训练出一个对应的图片分类器出来,然后固定住图片生成器与图片分类器,只训练Z码生成器(C是随机向量),从而找到Z码的范围,使得通过该Z码生成的图片,能满足图片分类器的要求,即:找到z的分布使得对应y的得分值最高。
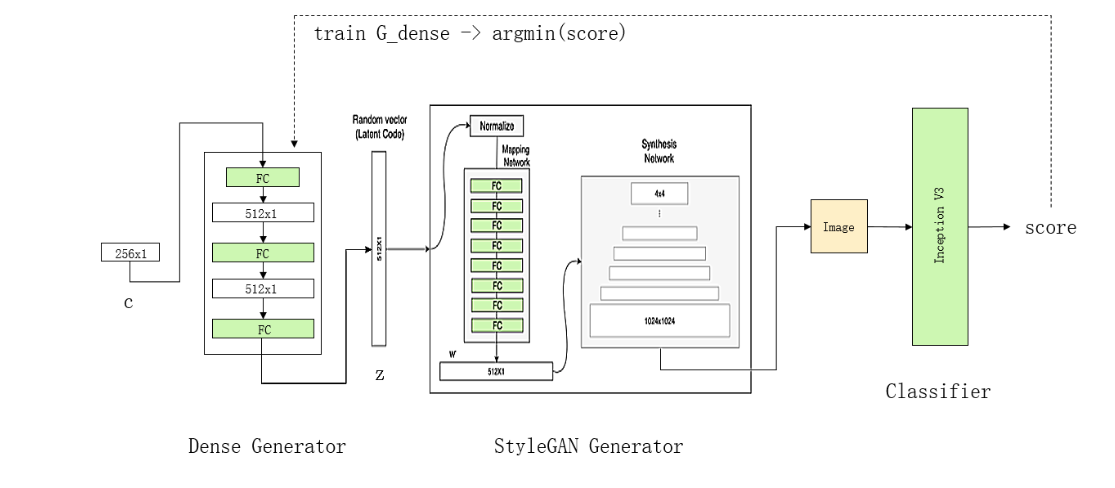
在实际模型搭建中,Z码生成器(Dense Generator)是一个256维到512维的简单全连接网络,图片生成器取用StyleGAN里面的模型,图片分类器是一个已训练好的类型分类器(譬如男/女分类器等,用CNN就能达到比较好的效果)。损失函数方面有两个组成部分,一部分是(找到z)让y的得分值越高越好,另一部分是让z的熵越大越好(即z有多样性)。由于实际的训练只需训练三个全连接层,所以epoch数无需太高。最后,每对应一个不同的图片分类器,就会训练出一个对应的Z码生成器。
1.2.1 方法一优化 取消Z码生成器,改为微调图片生成器
对于某些分类器来说,训练出的Z码生成器是不太稳定的。举一个例子,如果希望指定生成黑种人或者白种人脸,上述方法可以实现,但是如果用同样的方法训练生成黄种人脸,就很难稳定生成。造成这种现象的原因是,黄种人界于白、黑种人之间,它的特点标志不清晰,因此Z码生成器很难找到一个Z码的区域,能够稳定生成黄种人脸。为了改善这一情况,我们可以考虑取消Z码生成器,改为微调图片生成器。
- 使用图片分类器从原始数据集中挑选出目标图片(如黄种人脸),制作成新的训练集(New Dataset)。
- 若数据集数目少,用 ADA 方法做数据增强。
- 以 StyleGAN 的预训练模型参数初始化新数据集下的图片生成器,训练状态回复至第 10000 个 kimg 处,此时进入 1024*1024 分辨率的微调阶段,然后持续训练。
- 展示黄种人脸生成器训练过程中的人脸迁移情况。
优点:
- 可以在生成图像的总体类别或大范围特征上进行控制。
- 实现简单,通常只需调整潜在变量的范围或分布即可。
缺点:
- 控制精度较低,无法细致地调整图像的细节特征。只能从大体上控制生成图片的类型,因为图片分类器的制作成本通常比较高(需要大量含标签数据),所以图片分类器的划分角度一般较为宽泛(譬如男/女,老/少,黑/白等),不宜过细。
2. 从生成过程中控制生成图片,特定维度特征的替换
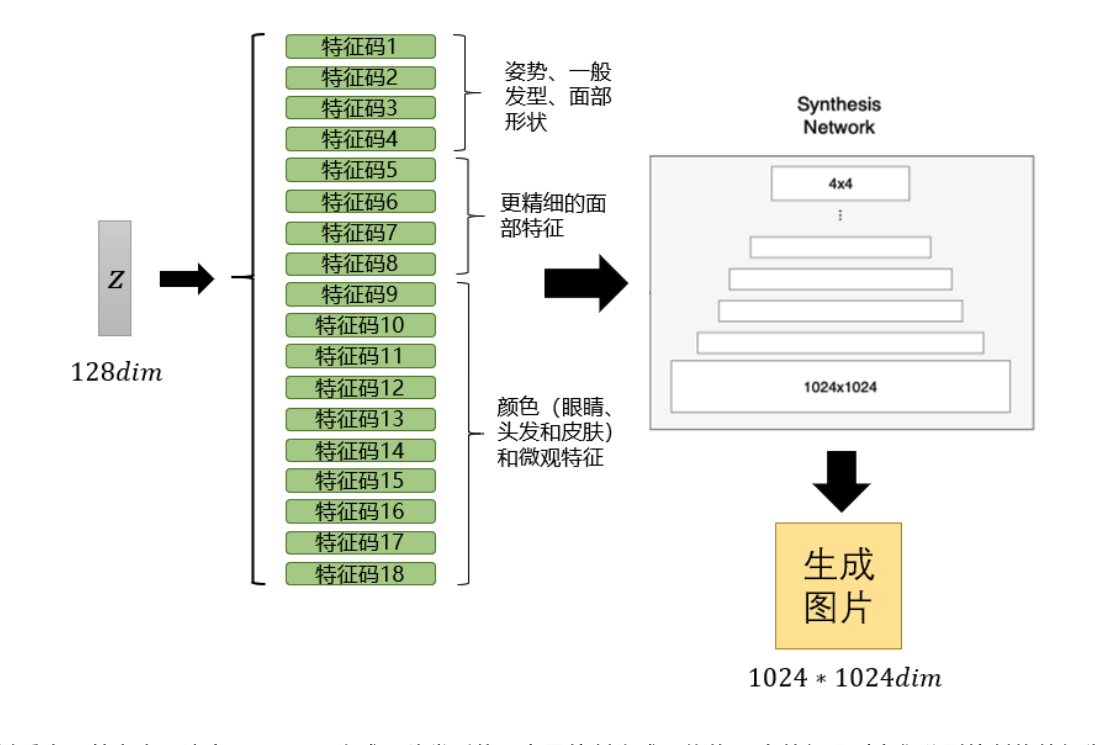
如图,真正决定StyleGAN生成图片类型的,在于控制生成网络的18个特征码(它们分别控制的特征类型已在图中标出)。于是,现在我们希望能更精细控制生成图片的类型,就可以考虑用已有图片的特征码,对其进行替换,从而让其具有被替换图片的特定特征。
一般建议替换5,6,7,8维,因为替换更低的维度会让生成效果不稳定,而替换更高的维度会让生成效果不明显。最终,多做几次尝试就能找到合适的模板以及合适的维度替换方案。
-
方法描述:
- 在图片生成器的内部,对特定维度上的特征进行替换,将目标(模板)人脸的精细风格引入生成图像中。
- 例如,通过调整生成器的某些层或维度,赋予生成图像特定的细节特征,如白皮肤、卷发等。
-
优点:
- 可以控制生成图像的细致风格和特征。
- 适用于对细节有较高要求的任务。
-
缺点:
- 实现较复杂,需要对生成器内部的特征进行精确调整。
- 可能需要对生成器进行大量的实验和调整。
3. Info-StyleGAN(结合 InfoGAN 和 StyleGAN)
构造一个通用模型,它能够实现所有定制化的需求。借助InfoGAN的思想,将Info信息引入StyleGAN的生成器中,构造出新的具有语义限制的生成器。
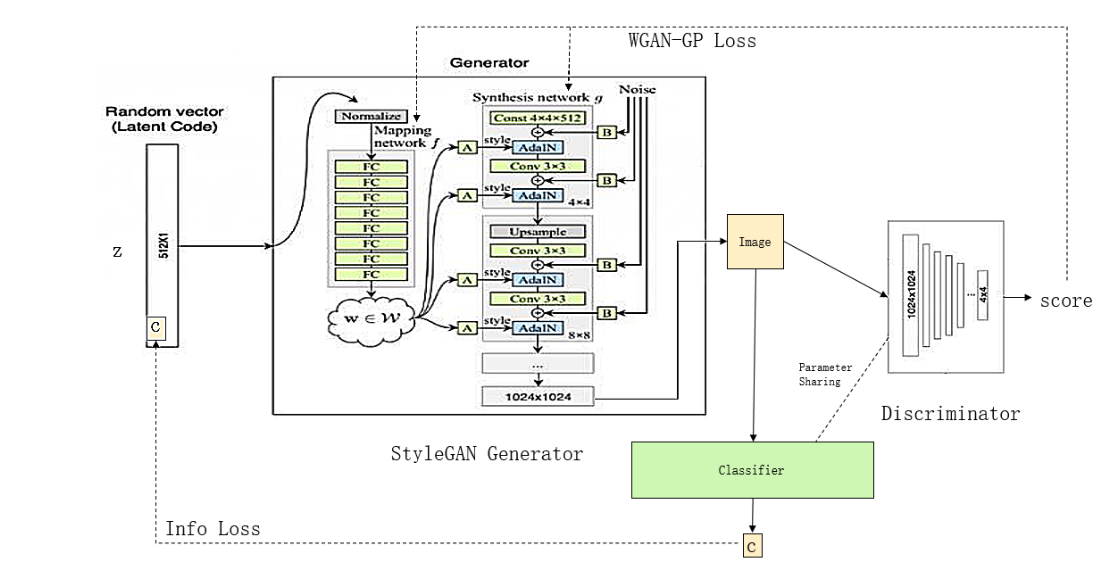
新的生成器输入info向量-c和噪音向量-z,其中c控制人脸类型,而z决定人脸样貌。生成图片X同时被传给判别器和分类器,其中判别器的作用是保证生成图片的清晰与逼真度,分类器的作用是保证生成图片的类别符合向量c的控制——因为它从生成图片中提取出一个新的向量,这个向量要与c尽可能一致,而c包含的信息仅有图像类别,所以只有生成图片也符合图像类别的情况下,提取出的向量才能与c一致,更详细的证明请参阅InfoGAN。最后分类器与判别器共用大部分参数,只保留最后几层参数不一致。
-
方法描述:
- 通过将 InfoGAN 与 StyleGAN 结合,形成一个新的架构——Info-StyleGAN。
- InfoGAN 通过引入信息论的概念(如信息最大化)来增强生成图像的控制能力,而 StyleGAN 提供了高质量的图像生成能力。
- 这种方法允许使用一个模型来实现更灵活的控制,包括生成图像的类型、风格和细节。
-
优点:
- 更通用和灵活,能够同时控制图像的多个特征。
- 提供了细粒度的控制,并能够生成高质量的图像。
-
缺点:
- 实现复杂,需要对两个模型的结合进行深入研究。
- 训练和调优过程可能需要更多的计算资源和时间。
参考笔记
原文地址:https://blog.csdn.net/weixin_42917352/article/details/140586663
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!